
 Technology peripherals
AI
The crazy open source plans of the four post-00s generation: the entire Internet is converted into a large model corpus, and the cost of embedding 100 million tokens is only US$1.
Technology peripherals
AI
The crazy open source plans of the four post-00s generation: the entire Internet is converted into a large model corpus, and the cost of embedding 100 million tokens is only US$1.
The crazy open source plans of the four post-00s generation: the entire Internet is converted into a large model corpus, and the cost of embedding 100 million tokens is only US$1.

All the papers on Arxiv are converted into tokens, and the total amount is only 14.1GB.
This is the feat accomplished by Alexander, the latest hot open source project.
In fact, this is only the first step.
Ultimately, they want to turn the entire Internet into Tokens, in other words, transform everything into the way large models such as ChatGPT understand the world.
Once such a data set is born, wouldn't it be a new powerful tool for developing large models like GPT-4, and it will be possible to understand astronomy and geography just around the corner? !
As soon as the news came out, it immediately attracted huge attention.
Netizens praised, epic.


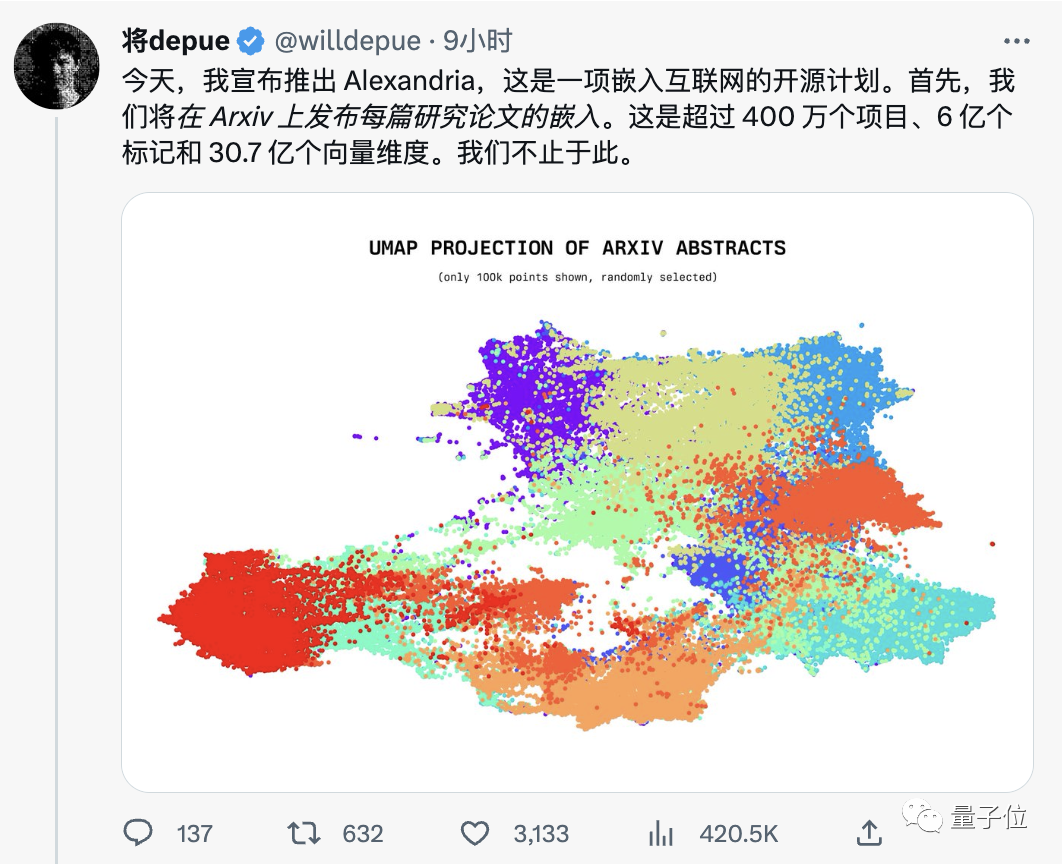
More than 4 million projects, 600 million tokens, and 3.07 billion vector dimensions.This open source project called Alexander starts with each paper on Arxiv. The chosen method is embedding. Simply put, it is to visualize various objects in the real world into vectors that the computer can understand.

(such as classification, retrieval, clustering, etc.) by simply providing task instructions without any fine-tuning. Text evaluation, etc.) and fields (such as science, finance, medicine, etc.) 》
Next week they will release Arxiv search. The process so far is to first perform a similarity search on the 100 closest articles, then calculate the embeddings of these on the fly and conduct a second, more complex search. The ultimate goal is an entire Internet embedded plan. Crazy open source plan of a 20-year-old boyThere are two main reasons why we want to launch such a crazy open source plan. On the one hand, it is to embed huge value. Many problems in the world are just search, clustering, recommendation or classification, and these are things that embeddings are very good at. And as mentioned before, some complex puzzles can be solved. On the other hand the cost is one time and very cheap. In most cases there is no need to perform a second calculation on the same file. Currently, every 100 million Tokens only cost $1$.
But they didn’t find any open embedded data sets, so this organization came into being. They will also open more data sets in the future, and these will be selected by these users. In addition to the public data sets on the official website, the remaining open source projects have opened voting channels.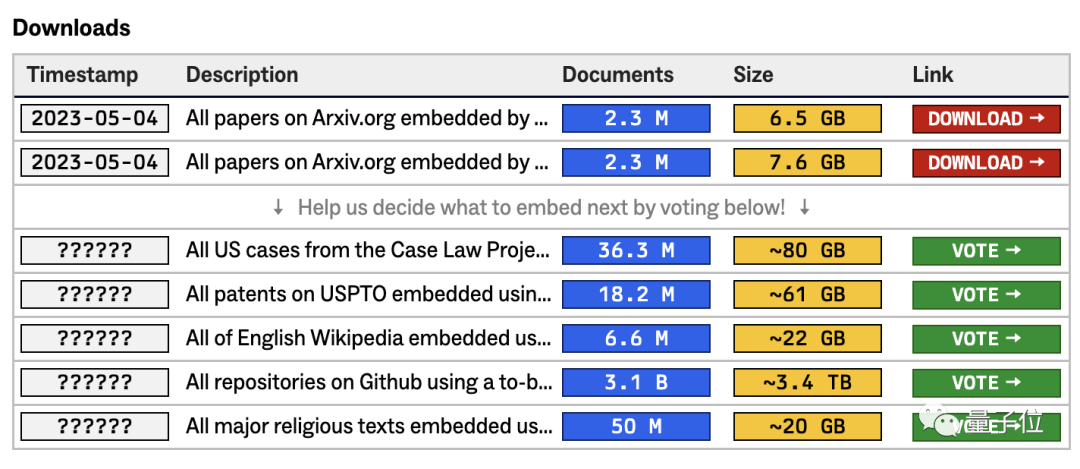
And their team name is also very domineering, Macrocosm (Macro World) Alliance.
As long as you zoom in far enough, humans become a single creature.
According to the official introduction, they are committed to building plug-ins for ChatGPT and other similar products. They are also developing core products, personal research assistants based on large models to help learning, teaching and scientific research.
Interested friends can click on the link below to learn more~
https://alex.macrocosm.so/download
The above is the detailed content of The crazy open source plans of the four post-00s generation: the entire Internet is converted into a large model corpus, and the cost of embedding 100 million tokens is only US$1.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
When managing WordPress websites, you often encounter complex operations such as installation, update, and multi-site conversion. These operations are not only time-consuming, but also prone to errors, causing the website to be paralyzed. Combining the WP-CLI core command with Composer can greatly simplify these tasks, improve efficiency and reliability. This article will introduce how to use Composer to solve these problems and improve the convenience of WordPress management.
 How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
When developing a project that requires parsing SQL statements, I encountered a tricky problem: how to efficiently parse MySQL's SQL statements and extract the key information. After trying many methods, I found that the greenlion/php-sql-parser library can perfectly solve my needs.
 How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
In Laravel development, dealing with complex model relationships has always been a challenge, especially when it comes to multi-level BelongsToThrough relationships. Recently, I encountered this problem in a project dealing with a multi-level model relationship, where traditional HasManyThrough relationships fail to meet the needs, resulting in data queries becoming complex and inefficient. After some exploration, I found the library staudenmeir/belongs-to-through, which easily installed and solved my troubles through Composer.
 Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
I'm having a tricky problem when developing a front-end project: I need to manually add a browser prefix to the CSS properties to ensure compatibility. This is not only time consuming, but also error-prone. After some exploration, I discovered the padaliyajay/php-autoprefixer library, which easily solved my troubles with Composer.
 How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
When developing PHP projects, ensuring code coverage is an important part of ensuring code quality. However, when I was using TravisCI for continuous integration, I encountered a problem: the test coverage report was not uploaded to the Coveralls platform, resulting in the inability to monitor and improve code coverage. After some exploration, I found the tool php-coveralls, which not only solved my problem, but also greatly simplified the configuration process.
 How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
When developing a Geographic Information System (GIS), I encountered a difficult problem: how to efficiently handle various geographic data formats such as WKT, WKB, GeoJSON, etc. in PHP. I've tried multiple methods, but none of them can effectively solve the conversion and operational issues between these formats. Finally, I found the GeoPHP library, which easily integrates through Composer, and it completely solved my troubles.
 How to solve the problem of virtual columns in Laravel model? Use stancl/virtualcolumn!
Apr 17, 2025 pm 09:48 PM
How to solve the problem of virtual columns in Laravel model? Use stancl/virtualcolumn!
Apr 17, 2025 pm 09:48 PM
During Laravel development, it is often necessary to add virtual columns to the model to handle complex data logic. However, adding virtual columns directly into the model can lead to complexity of database migration and maintenance. After I encountered this problem in my project, I successfully solved this problem by using the stancl/virtualcolumn library. This library not only simplifies the management of virtual columns, but also improves the maintainability and efficiency of the code.
 git software installation tutorial
Apr 17, 2025 pm 12:06 PM
git software installation tutorial
Apr 17, 2025 pm 12:06 PM
Git Software Installation Guide: Visit the official Git website to download the installer for Windows, MacOS, or Linux. Run the installer and follow the prompts. Configure Git: Set username, email, and select a text editor. For Windows users, configure the Git Bash environment.
