


Introduction: Stable Diffusion shows powerful visual generation capabilities. However, they often fall short in generating images with spatial, structural, or geometric control. Works such as ControlNet [1] and T2I-adpater [2] achieve controllable image generation for different modalities, but being able to adapt to various visual conditions in a single unified model remains an unsolved challenge. UniControl incorporates a variety of controllable condition-to-image (C2I) tasks within a single framework. In order to make UniControl capable of handling diverse visual conditions, the authors introduced a task-aware HyperNet to adjust the downstream conditional diffusion model so that it can adapt to different C2I tasks simultaneously. UniControl is trained on nine different C2I tasks, demonstrating strong visual generation capabilities and zero-shot generalization capabilities. The author has open sourced the model parameters and inference code. The data set and training code will also be open sourced as soon as possible. Everyone is welcome to exchange and use it.

Figure 1: UniControl model consists of multiple pre-training tasks and zero-shot tasks
Motivation: Existing controllable image generation models are designed for a single modality. However, Taskonomy [3] et al. The work proves that features and information are shared between different visual modalities, so this paper believes that a unified multi-modal model has great potential.
Solution: This article proposes MOE-style Adapter and Task-aware HyperNet to implement multi-modal condition generation capabilities in UniControl. And the author created a new data set MultiGen-20M, which contains 9 major tasks, more than 20 million image-condition-prompt triples, and image size ≥512.
Advantages: 1) More compact model (1.4B #params, 5.78GB checkpoint), fewer parameters to achieve multiple tasks. 2) More powerful visual generation capabilities and control accuracy. 3) Zero-shot generalization ability on never-seen modalities.
1. IntroductionGenerative basic models are changing the way artificial intelligence interacts in fields such as natural language processing, computer vision, audio processing, and robot control. In natural language processing, generative base models like InstructGPT or GPT-4 perform well on a variety of tasks, and this multitasking capability is one of the most attractive features. Additionally, they can perform zero-shot or few-shot learning to handle unseen tasks.
However, in generative models in the visual field, this multi-tasking ability is not prominent. While textual descriptions provide a flexible way to control the content of generated images, they often fall short in providing pixel-level spatial, structural, or geometric control. Recent popular research such as ControlNet and T2I-adapter can enhance Stable Diffusion Model (SDM) to achieve precise control. However, unlike language cues, which can be processed by a unified module like CLIP, each ControlNet model can only process the specific modality it was trained on.
To overcome the limitations of previous work, this paper proposes UniControl, a unified diffusion model that can handle both language and various visual conditions. UniControl's unified design allows for improved training and inference efficiency and enhanced controllable generation. UniControl, on the other hand, benefits from the inherent connections between different visual conditions to enhance the generative effects of each condition.
UniControl’s unified controllable generation capability relies on two parts, one is the "MOE-style Adapter" and the other is the "Task-aware HyperNet". MOE-style Adapter has about 70K parameters and can learn low-level feature maps from various modalities. Task-aware HyperNet can input task instructions as natural language prompts and output task embeddings to be embedded in the downstream network to modulate the downstream model. parameters to adapt to different modal inputs.
This study pre-trained UniControl to obtain the capabilities of multi-task and zero-shot learning, including nine different tasks in five categories: Edge (Canny, HED, Sketch) , area mapping (Segmentation, Object Bound Box), skeleton (Human Skeleton), geometry (Depth, Normal Surface) and image editing (Image Outpainting). The study then trained UniControl on NVIDIA A100 hardware for over 5,000 GPU hours (new models are still being trained today). And UniControl demonstrates zero-shot adaptability to new tasks.
The contribution of this research can be summarized as follows:
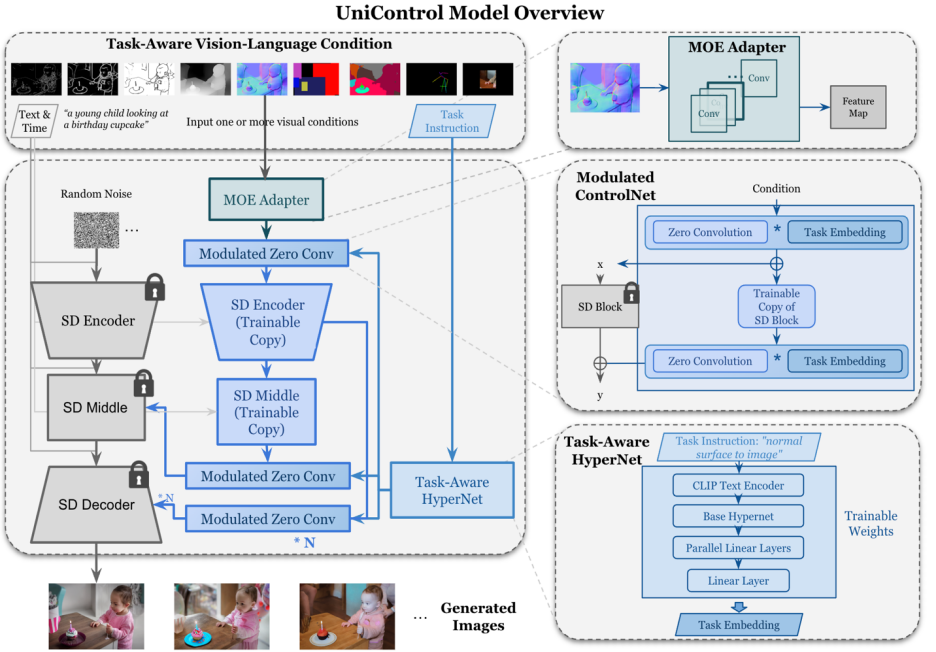
##Figure 2: Model structure. To accommodate multiple tasks, the study designed a MOE-style Adapter with approximately 70K parameters per task, and a task-aware HyperNet (~12M parameters) to modulate 7 zero-convolutional layers. This structure allows the implementation of multi-task functions in a single model, which not only ensures the diversity of multi-tasks, but also retains the underlying parameter sharing. Significant model size reduction compared to equivalent stacked single-task models (approximately 1.4B parameters per model).
The UniControl model design ensures two properties:
#1) Overcoming low-level features from different modalities misalignment. This helps UniControl learn necessary and unique information from all tasks. For example, when a model relies on segmentation maps as a visual condition, 3D information may be ignored.
2) Able to learn meta-knowledge across tasks. This enables the model to understand the shared knowledge between tasks and the differences between them.
To provide these properties, the model introduces two novel modules: MOE-style Adapter and Task-aware HyperNet.
MOE-style Adapter is a set of convolution modules. Each Adapter corresponds to a separate modality. It is inspired by the mixture model of experts (MOE) and is used as a UniControl to capture various low-level visions. Characteristics of conditions. This adapter module has approximately 70K parameters and is extremely computationally efficient. The visual features will then be fed into a unified network for processing.
Task-aware HyperNet adjusts the zero convolution module of ControlNet through task instruction conditions. HyperNet first projects the task instructions into task embedding, and then the researchers inject the task embedding into the zero convolution layer of ControlNet. Here, task embedding corresponds to the convolution kernel matrix size of the zero convolution layer. Similar to StyleGAN [4], this study directly multiplies the two to modulate the convolution parameters, and the modulated convolution parameters are used as the final convolution parameters. Therefore, the modulated zero convolution parameters of each task are different. This ensures the adaptability of the model to each modality. In addition, all weights are shared.
Different from SDM or ControlNet, the image generation condition of these models is a single language cue, or a single type of visual condition such as canny. UniControl needs to handle a variety of visual conditions from different tasks, as well as verbal cues. Therefore, the input of UniControl consists of four parts: noise, text prompt, visual condition, and task instruction. Among them, task instruction can be naturally obtained according to the modality of visual condition.

With such generated training pairs, this study employs DDPM [5] to train the model.

##Figure 6: Visual comparison of test set result. The test data comes from MSCOCO [6] and Laion [7]
The comparison results with the official or ControlNet reproduced in this study are shown in Figure 6, more Please refer to the paper for results.
5.Zero-shot Tasks GeneralizationThe model tests the zero-shot ability in the following two scenarios:
Mixed task generalization: This study considers two different visual conditions as input to UniControl, one is a mixture of segmentation maps and human skeletons, and adds specific keywords "background" and "foreground" to the text prompt. Furthermore, the study rewrites the hybrid task instructions as a hybrid of instructions for combining two tasks, such as "segmentation map and human skeleton to image".
New task generalization: UniControl is required to generate controllable images on new unseen visual conditions. To achieve this, it is crucial to estimate task weights based on the relationship between unseen and seen pre-trained tasks. Task weights can be estimated by manually assigning or calculating similarity scores of task instructions in the embedding space. MOE-style Adapters can be linearly assembled with estimated task weights to extract shallow features from new unseen visual conditions.
The visualized results are shown in Figure 7. For more results, please refer to the paper.

Figure 7: Visualization results of UniControl on Zero-shot tasks
6. SummaryIn general, the UniControl model provides a new basic model for controllable visual generation through its control diversity. Such a model could provide the possibility to achieve higher levels of autonomy and human control of image generation tasks. This study looks forward to discussing and collaborating with more researchers to further promote the development of this field.
More visuals
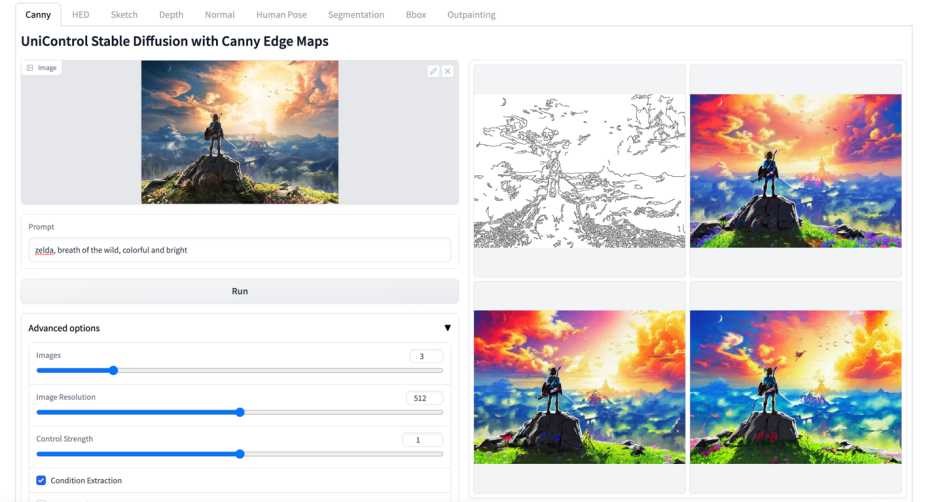
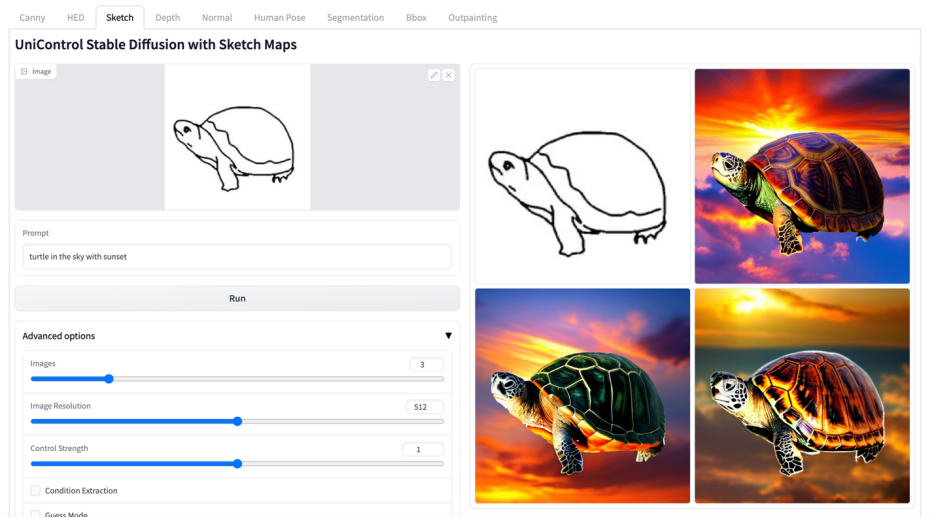
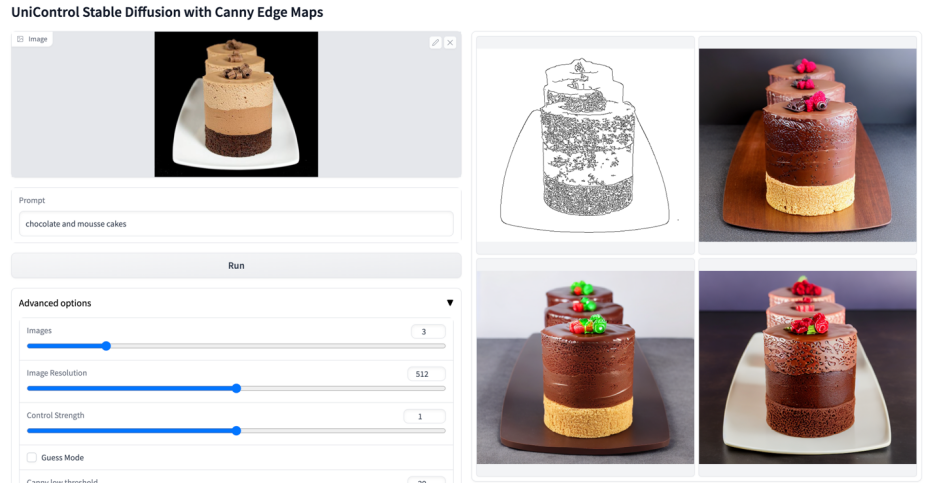
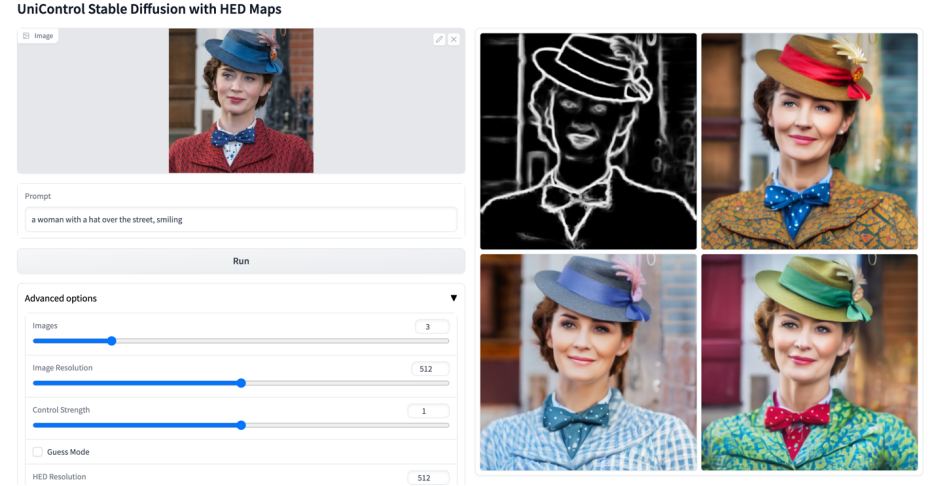
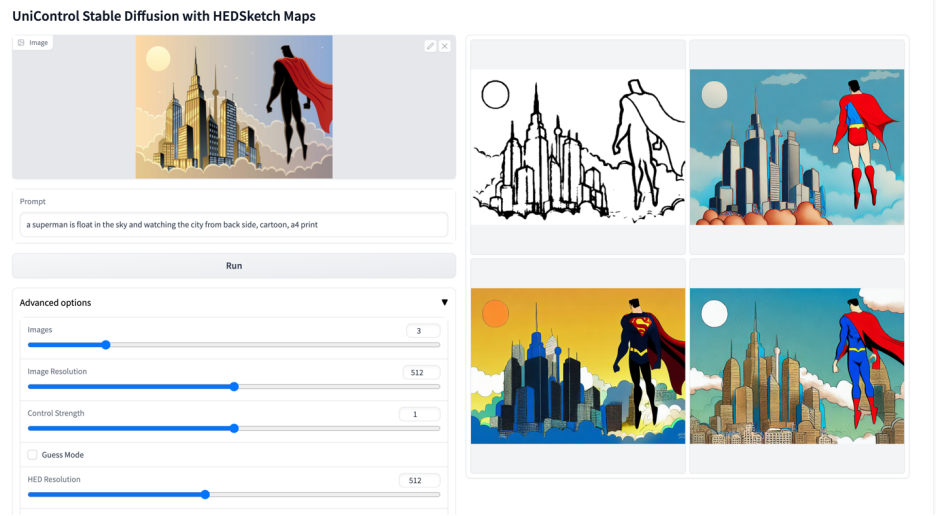 #
#
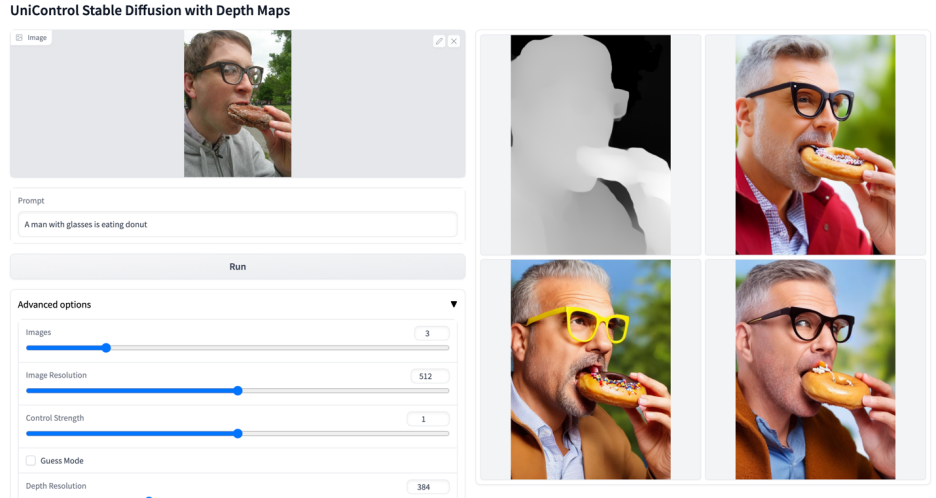
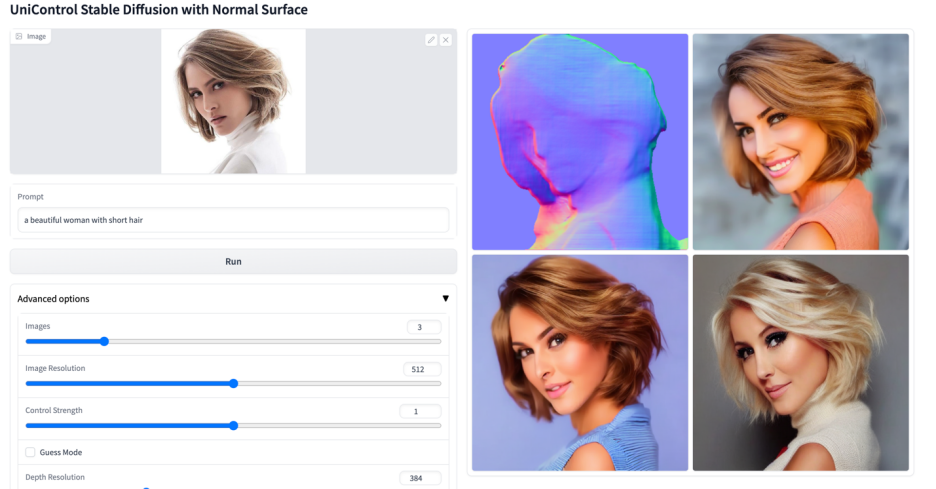
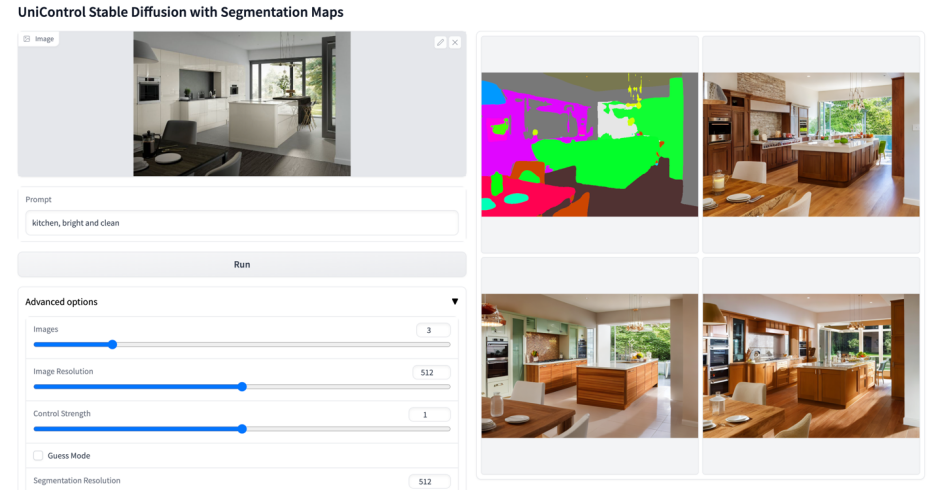
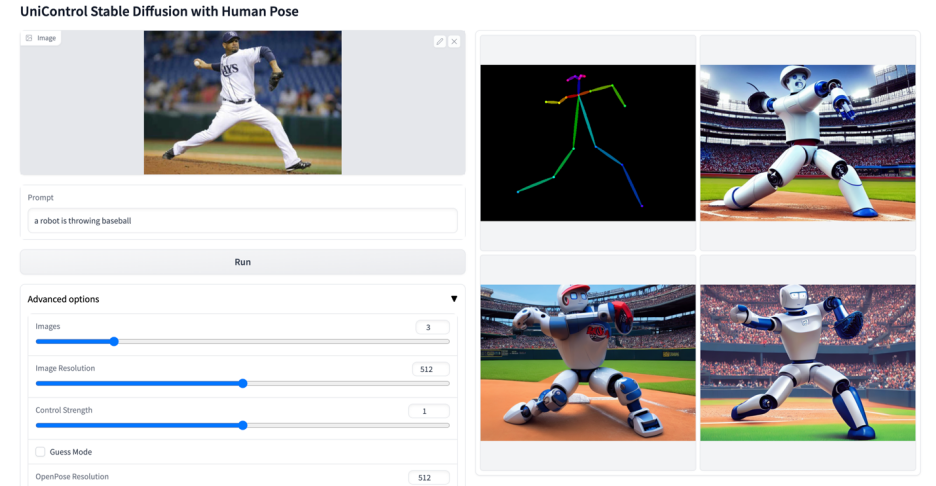
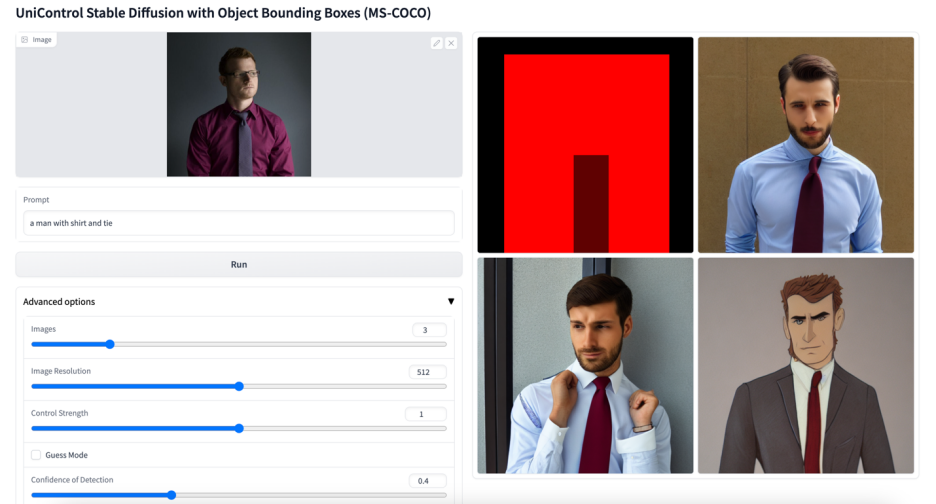
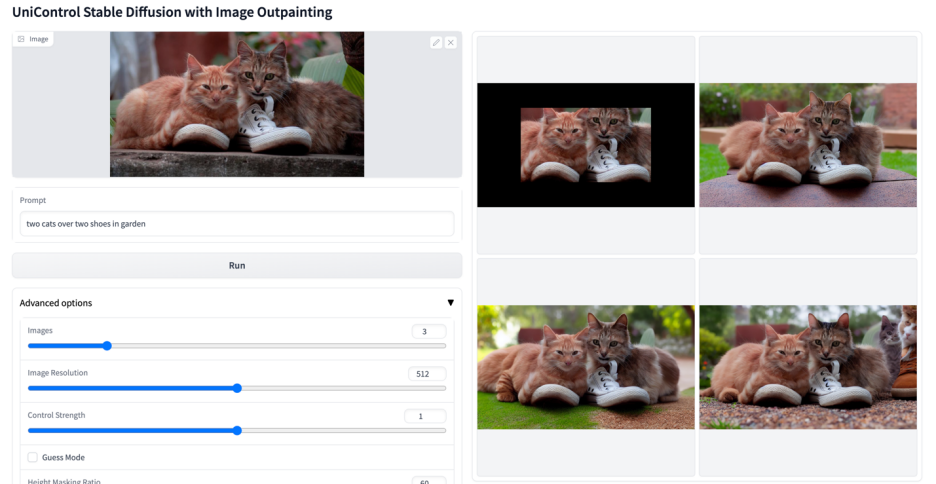
The above is the detailed content of A unified model for multi-modal controllable image generation is here, and all model parameters and inference codes are open source. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



