

Large Model (LLM) provides a new direction for the development of general artificial intelligence (AGI). It uses massive public data, such as the Internet, books and other corpora to conduct large-scale self-learning. Through supervised training, powerful language understanding, language generation, reasoning and other abilities have been obtained. However, large models still face some challenges in utilizing private domain data. Private domain data refers to data owned by specific companies or individuals and usually contains domain-specific knowledge. Combining large models with private domain knowledge will Provide great value.
Private domain knowledge can be divided into unstructured and structured data in terms of data form. Unstructured data, such as documents, are usually enhanced through retrieval, and tools such as langchain can be used to quickly implement a question and answer system. Structured data, such as databases (DB), require large models to interact with the database, query and analyze to obtain useful information. A series of products and applications have recently been derived around large models and databases, such as using LLM to build intelligent databases, perform BI analysis, and complete automatic table construction. Among them, text-to-SQL technology, which interacts with the database in a natural language, has always been a highly anticipated direction.
In academia, past text-to-SQL benchmarks only focused on small-scale databases. The most advanced LLM can already achieve an execution accuracy of 85.3%, but does this mean that LLM Already available as a natural language interface to the database?
Recently, Alibaba, together with the University of Hong Kong and other institutions, launched a new benchmark BIRD (Can LLM Already Serve as A Database) for large-scale real databases Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs), including 95 large-scale databases and high-quality Text-SQL pairs, with a data storage capacity of up to 33.4 GB. The previous best model only achieved 40.08% evaluation on BIRD, which is still far from the human result of 92.96%, proving that challenges still exist. In addition to evaluating the correctness of SQL, the author also added an evaluation of SQL execution efficiency, hoping that the model can not only write correct SQL, but also write efficient SQL.

Paper: https://arxiv.org/abs/2305.03111
Homepage: https://bird-bench.github.io
##Code: https://github. com/AlibabaResearch/DAMO-ConvAI/tree/main/bird




An LLM project not to be missed

Very useful checkpoint, hotbed for improvement
AI can help you, but it cannot replace you ##My job is safe for now... New Challenges This research is mainly oriented to Text-to-SQL evaluation of real databases, popular test benchmarks in the past, Spider and WikiSQL, for example, only focus on database schema with a small amount of database content, resulting in a gap between academic research and practical applications. BIRD focuses on three new challenges: massive and real database content, external knowledge reasoning between natural language questions and database content, and the efficiency of SQL when processing large databases. 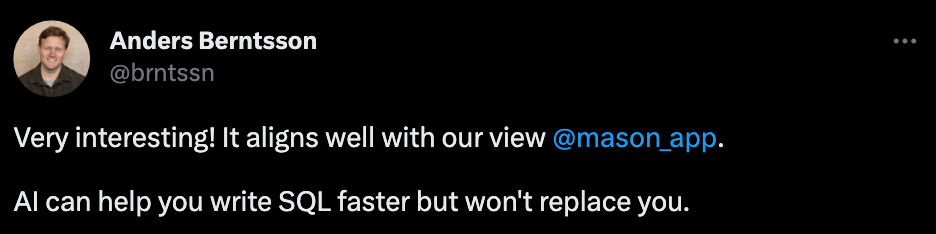

First of all, the database contains massive and noisy data values. In the example on the left, the average salary needs to be calculated by converting the string in the database into a floating point value (Float) and then performing the aggregation calculation (Aggregation);
Secondly, external knowledge inference is necessary. In the middle example, in order to accurately return answers to the user, the model must first know that the account type eligible for the loan must be "OWNER", which represents a huge The mysteries hidden behind database content sometimes require external knowledge and reasoning to reveal;
Finally, query execution efficiency needs to be considered. In the example on the right, using more efficient SQL queries can significantly improve speed, which is of great value to the industry because users not only expect to write correct SQL, but also expect efficient SQL execution, especially in large databases In the case of;
Data annotation
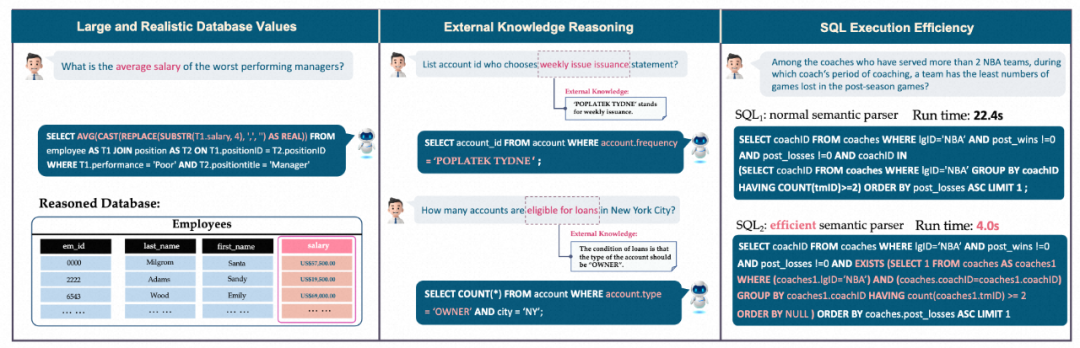
BIRD decouples question generation and SQL annotation during the annotation process . At the same time, experts are added to write database description files to help problem and SQL annotation personnel better understand the database.
1. Database collection: The author collected and processed 80 databases from open source data platforms such as Kaggle and CTU Prague Relational Learning Repository. Fifteen databases were manually created as black-box tests by collecting real table data, building ER diagrams, and setting database constraints to avoid the current database being learned by the current large model. BIRD's database contains patterns and values in multiple fields, 37 fields, covering blockchain, sports, medical care, games, etc.
2. Problem collection: First, the author hires experts to write a description file for the database. The description file includes a complete description of the column name, database value, and external parameters used to understand the value. knowledge etc. Then 11 native speakers from the United States, United Kingdom, Canada, Singapore and other countries were recruited to generate questions for BIRD. Every speaker has at least a bachelor's degree or above.
3. SQL generation: A global annotation team composed of data engineers and database course students was recruited to generate SQL for BIRD. Given a database and a reference database description file, the annotator needs to generate SQL to correctly answer the question. The Double-Blind annotation method is adopted, requiring two annotators to annotate the same question. Double-blind annotation can minimize errors caused by a single annotator.
4. Quality inspection: Quality inspection is divided into two parts: effectiveness and consistency of result execution. Validity not only requires the correctness of execution, but also requires that the execution result cannot be null (NULL). Experts will gradually modify the problem conditions until the SQL execution results are valid.
5. Difficulty division: The difficulty index of text-to-SQL can provide researchers with a reference for optimizing algorithms. The difficulty of Text-to-SQL depends not only on the complexity of the SQL, but also on factors such as the difficulty of the question, the ease of understanding with additional knowledge, and the complexity of the database. The authors therefore asked SQL annotators to rate the difficulty during the annotation process and divided the difficulty into three categories: easy, moderate, and challenging.
Data statistics
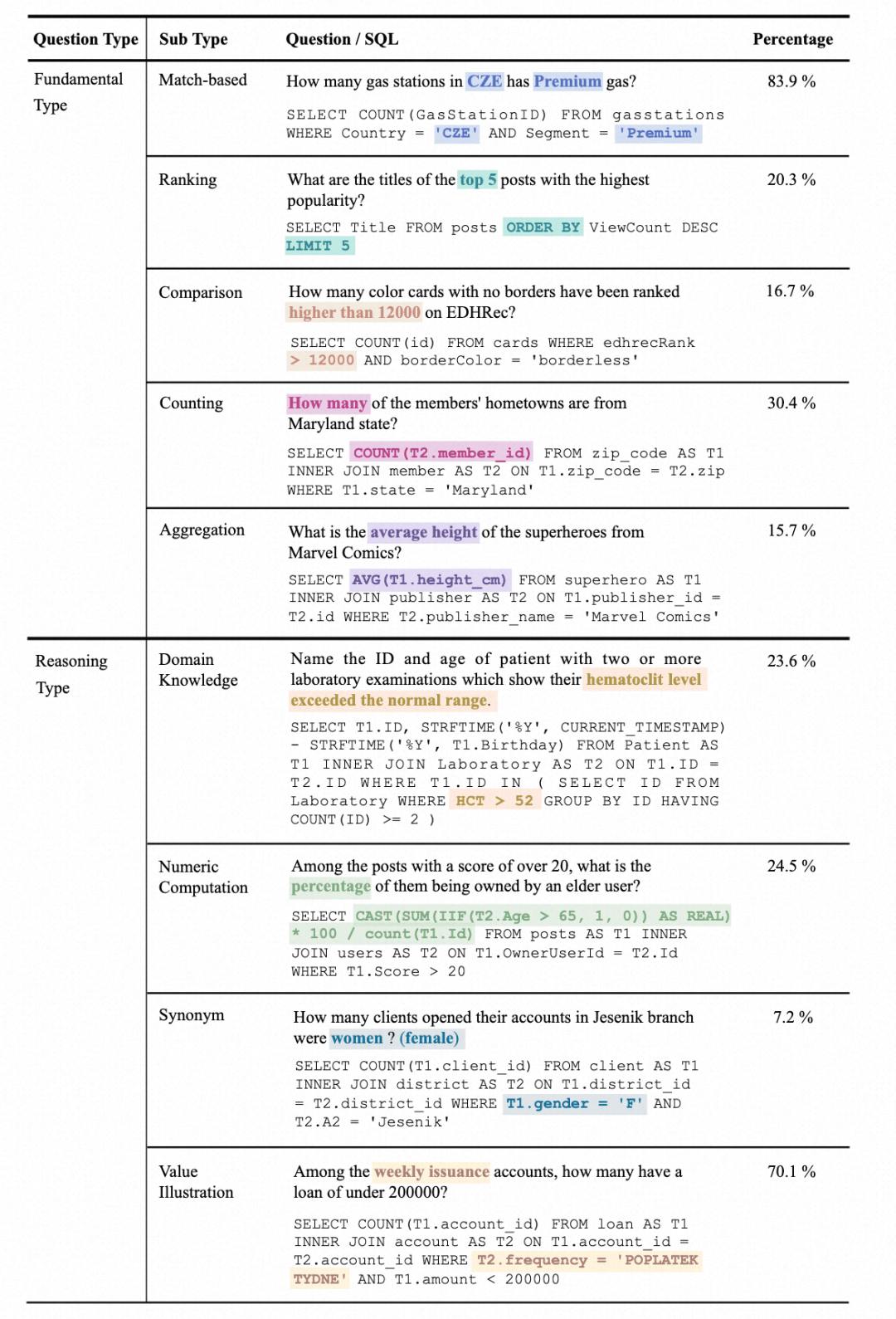
1. Question type statistics: Questions are divided into two categories, basic question types (Fundamental Type) and Reasoning Type. Basic question types include those covered in traditional Text-to-SQL datasets, while inference question types include questions that require external knowledge to understand the value:
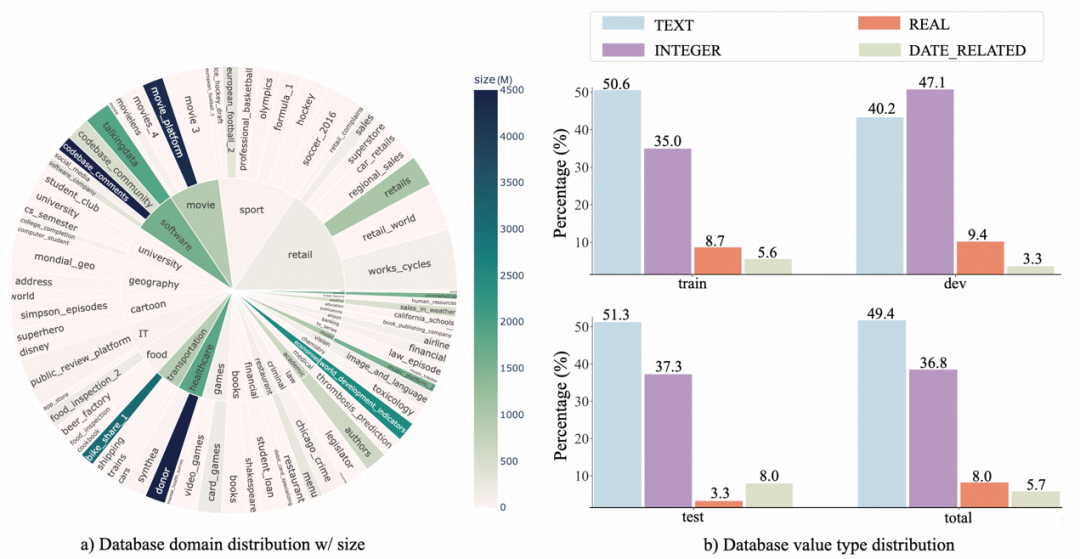
##2. Database distribution: The author uses a sunburst diagram to show the relationship between the database domain and its data size. A larger radius means more text-SQL is based on that database, and vice versa. The darker the color, the larger the database size. For example, donor is the largest database in the benchmark, occupying 4.5GB of space.
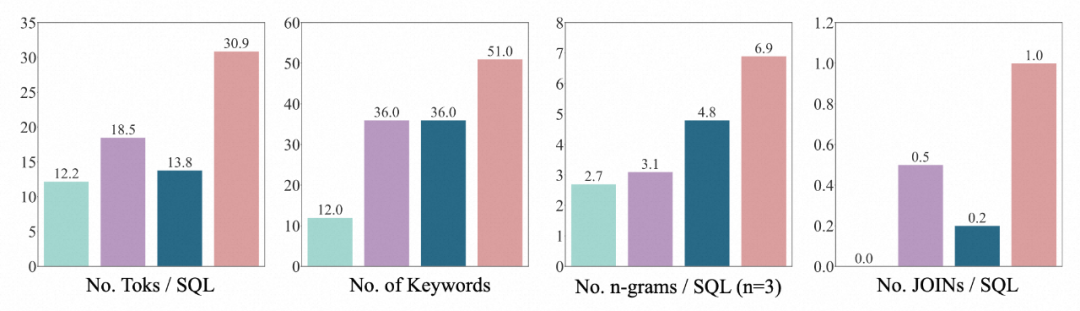
3.SQL distribution: the number of tokens passed by the author through SQL, the number of keywords, the number of n-gram types, JOIN The number and other 4 dimensions prove that BIRD's SQL is by far the most diverse and complex.
Evaluation Indicators
1. Execution Accuracy: Compare the difference between the SQL execution results predicted by the model and the actual annotated SQL execution results;
2. Effective efficiency score: Taking into account both the accuracy and efficiency of SQL, compare the model predictions The relative difference between the SQL execution speed and the real annotated SQL execution speed takes the running time as the main indicator of efficiency.
Experimental analysis
The author selected the training-type T5 model and the large-scale model that performed well in previous benchmark tests Language models (LLM) as baseline models: Codex (code-davinci-002) and ChatGPT (gpt-3.5-turbo). In order to better understand whether multi-step reasoning can stimulate the reasoning capabilities of large language models in real database environments, their Chain-of-Thought version is also provided. And test the baseline model in two settings: one is full schema information input, and the other is human understanding of the database values involved in the problem, summarized into natural language description (knowledge evidence) to assist the model in understanding the database.
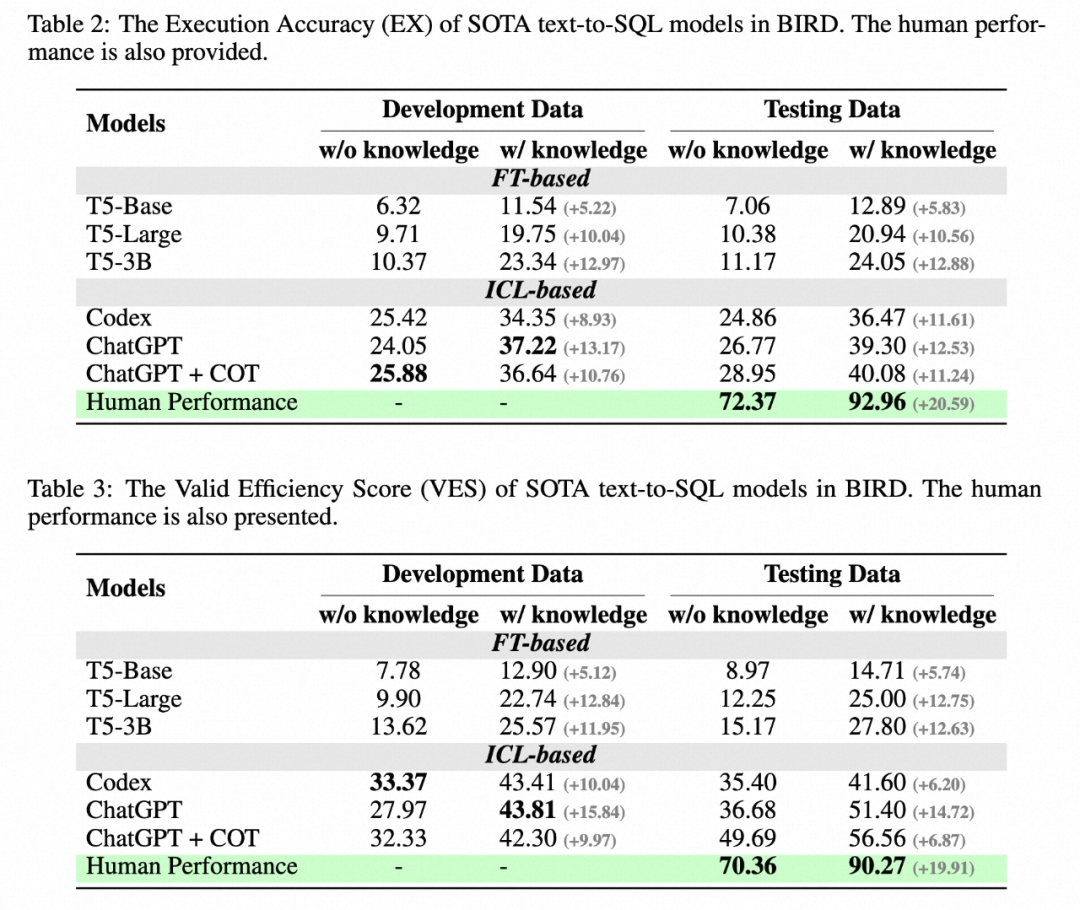
The author gives some conclusions:
1. Additional knowledge Gain: Increasing the knowledge evidence (knowledge evidence) on the understanding of database values has a significant improvement. This proves that in real database scenarios, relying solely on semantic parsing capabilities is not enough. Understanding database values will help users find more accurately Answer.
2. The thinking chain is not necessarily completely beneficial: when the model does not have a given database value description and zero-shot, the model's own COT inference can be generated more accurately Answer. However, when given additional knowledge (knowledge evidence), LLM was asked to perform COT and found that the effect was not significant or even declined. Therefore in this scenario, LLM may generate knowledge conflicts. How to resolve this conflict so that the model can both accept external knowledge and benefit from its own powerful multi-step reasoning will be a key research direction in the future.
3. The gap with humans: BIRD also provides human indicators. The author uses an exam to test the performance of the annotator when facing the test set for the first time, and uses it as the basis for human indicators. Experiments have found that the current best LLM is still far behind humans, proving that challenges still exist. The authors performed a detailed error analysis and provided some potential directions for future research.

The application of LLM in the database field will provide users with smarter and more convenient Database interactive experience. The emergence of BIRD will promote the intelligent development of interaction between natural language and real databases, provide room for progress in text-to-SQL technology for real database scenarios, and help researchers develop more advanced and practical database applications.
The above is the detailed content of When LLM meets Database: Alibaba DAMO Academy and HKU launch a new Text-to-SQL benchmark. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



