

Domestic self-developed large models welcome new faces, and they are open source as soon as they are released!
The latest news is that the multi-modal large language model TigerBot has been officially unveiled, including two versions of 7 billion parameters and 180 billion parameters, both open source.
The dialogue AI supported by this model is launched simultaneously.
Writing slogans, making forms, and correcting grammatical errors are all very effective; it also supports multi-modality and can generate pictures.

The evaluation results show that TigerBot-7B has reached 96% of the comprehensive performance of OpenAI models of the same size.
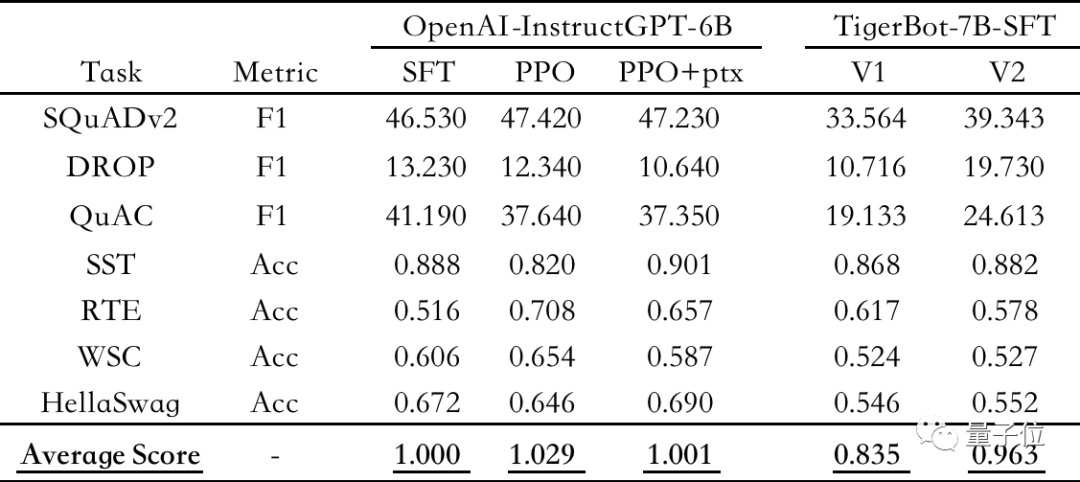
△Automatic evaluation on public NLP data sets, using OpenAI-instruct GPT-6B-SFT as the benchmark, normalizing and averaging each model The score of
and the larger-scale TigerBot-180B may be the largest-scale large language model currently open source in the industry.
In addition, the team also open sourced 100G pre-training data and supervised fine-tuning of 1G or 1 million pieces of data.
Based on TigerBot, developers can create their own large models in half a day.
Currently, TigerBot Dialogue AI has been invited for internal testing, and the open source code data has been uploaded to GitHub (see the end of the article for detailed links).
These important tasks come from a small team of only 5 people at the beginning. The chief programmer & scientist is the CEO himself.
But this team is by no means unknown.
Since 2017, they have started their business in the field of NLP, specializing in vertical field search. is best at the financial field where data is heavy, and has had in-depth cooperation with Founder Securities, Guosen Securities, etc.
Founder and CEO, has more than 20 years of experience in the industry. He was a visiting professor at UC Berkeley and holds 3 best conference papers and 10 technology patents.
Now, they are determined to move from specialized areas to general-purpose large models.
And we started with the lowest basic model from the beginning, completed 3,000 experimental iterations within 3 months, and we still have the confidence to open source the phased results to the outside world.
People can’t help but wonder, who are they? What do you want to do? What phased results have been achieved so far?
Specifically, TigerBot is a large domestic self-developed multi-language task model.
Covers 15 major categories of capabilities such as generation, open question and answer, programming, drawing, translation, and brainstorming, and supports more than 60 subtasks.
And supports plug-in function, which allows the model to be networked and obtain more fresh data and information.
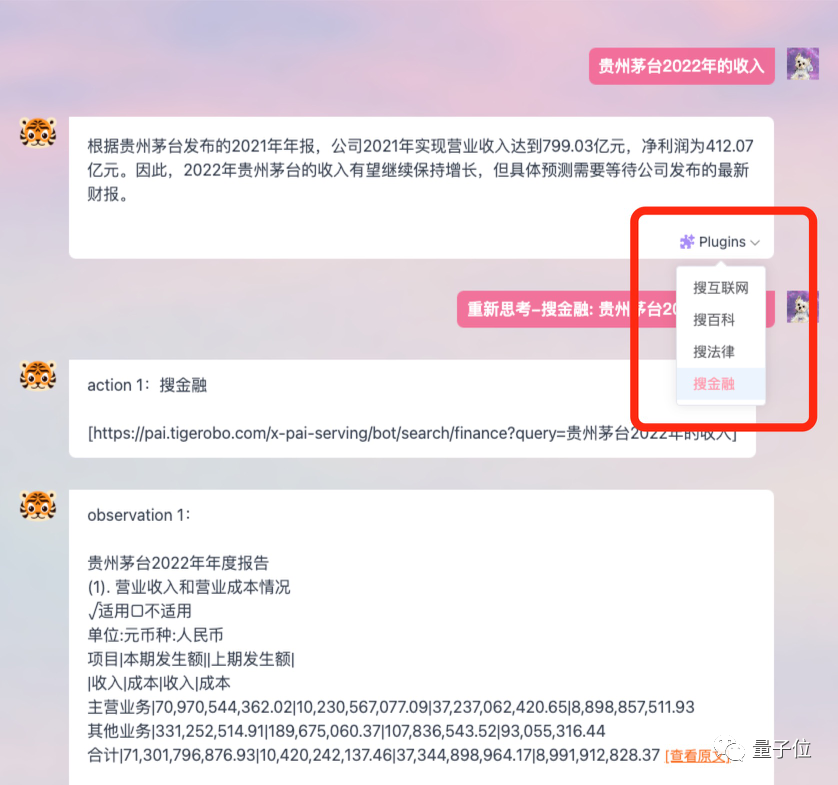
Its positioning is more biased toward office scenes, and it proposes the goal of improving people's workflow and increasing efficiency.
For example, let it help me write a news flash about Apple Vision Pro, and the effect is similar:

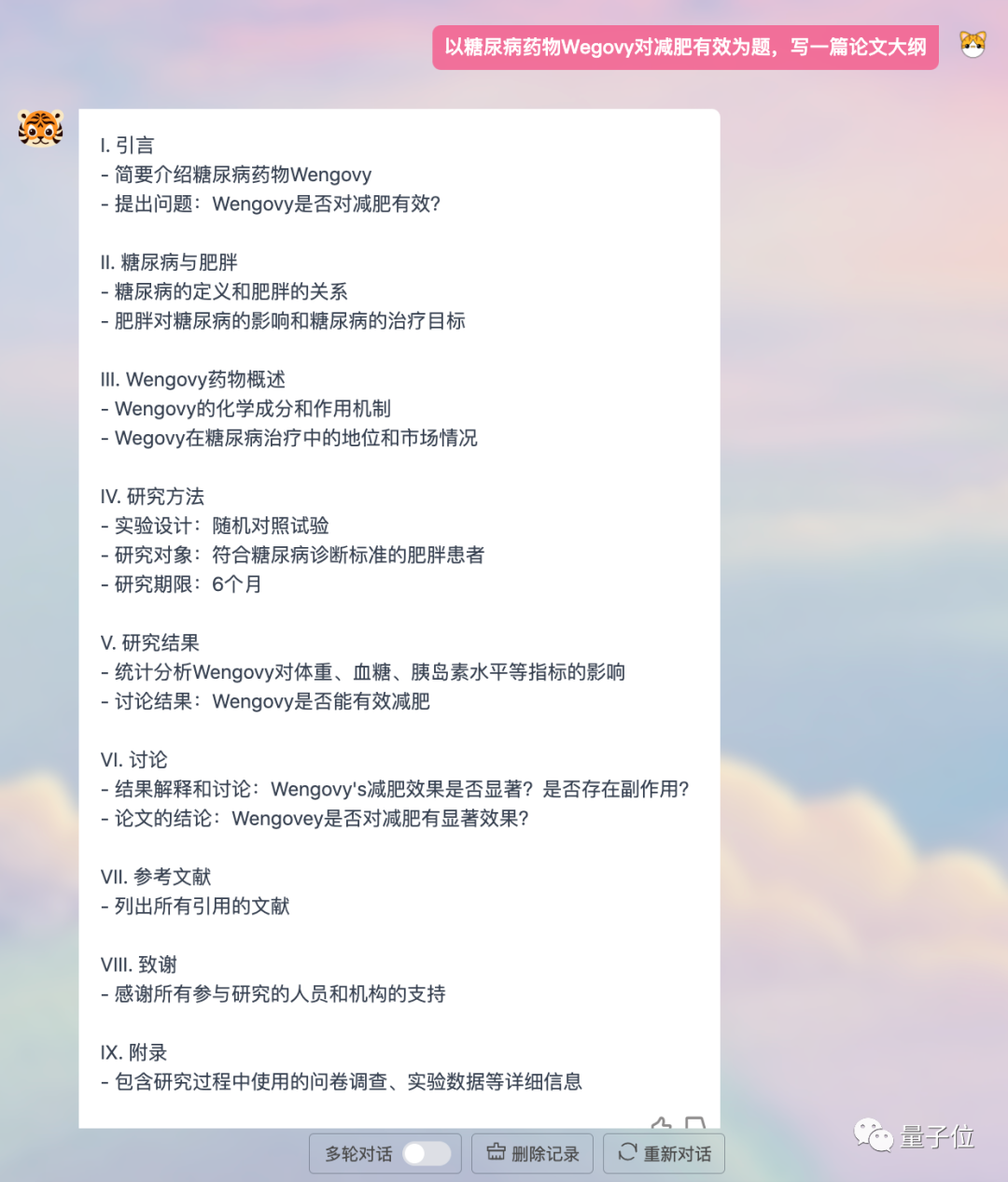
Or write A thesis outline, clear and well-structured:
Programming is no problem, and English conversation is supported.

In this release, TigerBot has launched two sizes: 7 billion parameters (TigerBot-7B) and 180 billion parameters (TigerBot-180B).
The team will open source all the phased results achieved so far - models, codes, and data.
The open source model includes three versions:
Among them, TigerBot-7B-base performs better than OpenAI's equivalent comparable model and BLOOM. TigerBot-180B-research may be the largest open source model in the industry currently (Meta open source OPT has a parameter size of 175 billion, and BLOOM has a scale of 176 billion).
The open source code includes basic training and inference code, quantization and inference code for the dual-card inference 180B model.
The data includes 100G pre-training data and supervised fine-tuning of 1G or 1 million pieces of data.
According to the automatic evaluation of the OpenAI InstructGPT paper on the public NLP data set, TigerBot-7B has reached 96% of the overall performance of OpenAI models of the same size.
And this version is only MVP (minimum viable model).
These results are mainly due to the team's further optimization of the model architecture and algorithm based on GPT and BLOOM. It is also the main innovation work of the TigerBot team in the past few months, making the model more efficient. Learning ability, creativity and controllable generation have been significantly improved.
How to implement it specifically? Look down.
The innovations brought by TigerBot mainly include the following aspects:
First look at the instructions to complete supervised fine-tuning method.
It allows the model to quickly understand what types of questions humans have asked and improve the accuracy of answers while using only a small number of parameters.
In principle, stronger supervised learning is used for control.
Through Mark-up Language, probabilistic methods are used to enable large models to more accurately distinguish instruction categories. For example, are the instruction questions more factual or divergent? Is it code? Is it a form?
So TigerBot covers 10 major categories and 120 categories of small tasks. Then let the model optimize in the corresponding direction based on judgment. The direct benefit brought by
is that the number of parameters to be called is smaller, and the model has better adaptability to new data or tasks, that is, the learnability is improved.
Under the same training conditions of 500,000 pieces of data, TigerBot's convergence speed is 5 times faster than that of Alpaca launched by Stanford. Evaluation on public data sets shows that the performance is improved by 17%.
Secondly, how the model can better balance the creativity and factual controllability of the generated content is also very critical.
TigerBot adopts the ensemble method on the one hand, combining multiple models to take into account creativity and factual controllability.
You can even adjust the model's balance between the two according to user needs.
On the other hand, it also adopts the classic probabilistic modeling (Probabilistic Modeling) method in the field of AI.
It allows the model to give two probabilities based on the latest generated token during the process of generating content. A probability determines whether the content should continue to diverge, and a probability indicates the degree of deviation of the generated content from the factual content.
Combining the two probability values, the model will make a trade-off between creativity and controllability. The two probabilities in TigerBot are trained with special data.
Considering that when the model generates the next token, it is often impossible to see the full text, TigerBot will also make another judgment after the answer is written. If the answer is ultimately found to be inaccurate, it will require the model to rewrite.
During our experience, we also found that the answers generated by TigerBot are not in the verbatim output mode like ChatGPT, but rather give complete answers after "thinking".

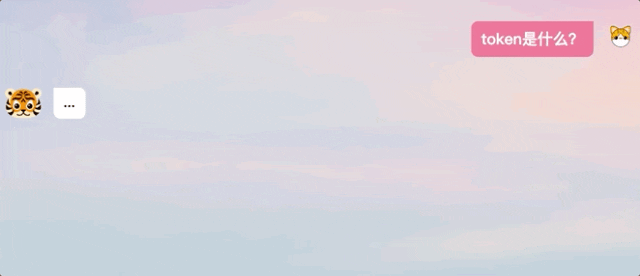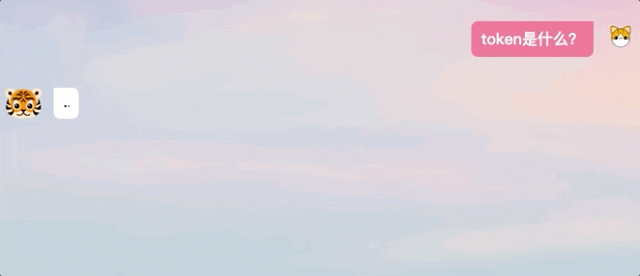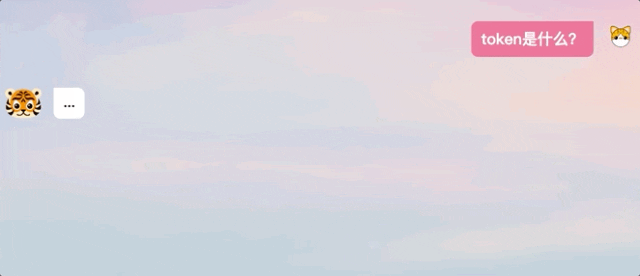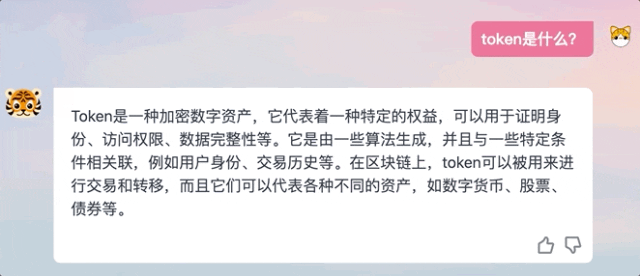
And because TigerBot’s inference speed is very fast, it can support rapid model rewriting.
Here we talk about TigerBot’s innovations in training and reasoning.
In addition to considering the optimization of the underlying architecture of the model, the TigerBot team believes that the level of engineering is also very important in the current era of large models.
On the one hand, it is because of the need to consider operational efficiency - as the trend of large models continues, it is very critical who can iterate the model faster; on the other hand, of course, the economy of computing power must also be considered.
Therefore, in terms of parallel training, they broke through several memory and communication problems in mainstream frameworks such as deep-speed, and achieved uninterrupted training for several months in a kilocalorie environment.
This allows them to save hundreds of thousands in monthly training expenses.
Finally, TigerBot has made corresponding optimizations from the tokenizer to the training algorithm to deal with the problems of strong continuity and multiple ambiguities in Chinese.
In summary, the technological innovations achieved by TigerBot all occur in the areas that receive the most attention in the current large model field.
It is not only the optimization of the underlying architecture, but also considers the user needs, overhead costs and other issues at the implementation level. And the entire innovation process is very fast, and it can be realized in a few months by a small team of about 10 people.
This places very high demands on the team’s own development capabilities, technical insights, and implementation experience.
So, who brought TigerBot into the public eye suddenly?
The development team behind TigerBot is actually hidden in its name - HuBo Technology.
It was established in 2017, which is what people often call the last round of AI explosion period.
Hubo Technology positions itself as "a company driven by artificial intelligence technology", focusing on the application of NLP technology, with the vision of creating the next generation of intelligent and simple search experience.
On the specific implementation path, they chose one of the most sensitive fields to data information-Finance. It has self-developed technologies such as intelligent search, intelligent recommendation, machine reading comprehension, summary, and translation in vertical fields, and launched the intelligent financial search and question and answer system "Hubo Search".
The founder and CEO of the company is Chen Ye, who is a world-class AI scientist.

He graduated from the University of Wisconsin-Madison with a Ph.D. and was a visiting professor at the University of California, Berkeley. He has been practicing for more than 20 years now.
He has held important positions such as chief scientist and R&D director at Microsoft, eBay, and Yahoo, and led the development of Yahoo's behavioral targeting system, eBay's recommendation system, and Microsoft's search advertising bidding market mechanism.
In 2014, Chen Ye joined Dianping. After the merger of Meituan-Dianping, he served as senior vice president of Meituan-Dianping, in charge of the group's advertising platform, helping the group's annual advertising revenue increase from 10 million to more than 4 billion.
In terms of academics, Chen Ye has won three top conference best paper awards (KDD and SIGIR), published 20 papers at artificial intelligence academic conferences such as SIGKKD, SIGIR, and IEEE, and holds 10 patents.
In July 2017, Chen Ye officially founded Hubo Technology. One year after its establishment, Hubo quickly obtained over 100 million yuan in financing. Currently, the company disclosed that the total financing amount reaches 400 million yuan.

7 months ago, ChatGPT was born. After 6 years, AI has once again subverted public perception.
Even technical experts like Chen Ye, who has been working in the field of AI for many years, describe it as "unprecedented shock in his career."
Besides the shock, it was more exciting.
Chen Ye said that after seeing ChatGPT, he almost didn’t have to think or make a decision. The call from his heart made him definitely follow the trend.
So, starting from January, Hubo officially established TigerBot’s initial development team.
But it’s different from what you imagined. This is a team with a very distinctive geek style.
In their own words, they pay tribute to the classic "Garage Entrepreneurship" model in Silicon Valley in the 1990s.
The team initially had only 5 people. Chen Ye was the chief programmer & scientist, responsible for the core code work. Although the number of members expanded later, it was only limited to 10 people, basically one person per post.
Why did you do this?
Chen Ye’s answer is:
I think creation from 0 to 1 is a very geeky thing, and no geek team has more than 10 people.
As well as purely technical and scientific matters, small teams are sharper.
Indeed, TigerBot’s development process revealed decisiveness and sensitivity in every aspect.
Chen Ye divided this cycle into three stages.
In the first stage, shortly after ChatGPT became popular, the team quickly scanned all relevant literature from OpenAI and other institutions in the past five years to gain a general understanding of ChatGPT’s methods and mechanisms.
Since the ChatGPT code itself was not open source, and there were relatively few related open source works at that time, Chen Ye went into battle and wrote the code for TigerBot, and then immediately started running experiments.
Their logic is very simple, let the model be successfully verified on small-scale data first, and then go through systematic scientific review, that is, a set of stable codes will be formed.
Within one month, the team verified that the model can achieve 80% of the effect of OpenAI's model of the same scale at a scale of 7 billion.
In the second stage, by continuously absorbing the advantages of open source models and codes, and by specially optimizing Chinese data, the team quickly produced a version of the real and usable model. The earliest internal beta version was released in 2 The month is online.
At the same time, they also found that after the number of parameters reached the tens of billions level, the model showed an emergence phenomenon.
In the third stage, that is, in the last one or two months, the team has achieved some results and breakthroughs in basic research.
Many of the innovations introduced above were completed during this period.
At the same time, a larger amount of computing power was integrated during this stage to achieve a faster iteration speed. Within 1-2 weeks, the capability of TigerBot-7B quickly increased from 80% of InstructGPT to 96%.
Chen Ye said that during this development cycle, the team has always maintained ultra-efficient operation. TigerBot-7B went through 3,000 iterations in a few months.
The advantage of a small team is that they can respond quickly. They can confirm the work in the morning and finish writing the code in the afternoon. The data team can complete high-quality cleaning work in a matter of hours.
But high-speed development and iteration is only one of the manifestations of TigerBot’s geek style.
Because they only rely on the results produced by 10 people in a few months, and they will open source them to the industry in the form of a full set of APIs.
Embracing open source to this extent is relatively rare in the current trend, especially in the field of commercialization.
After all, in the fierce competition, building technical barriers is a problem that commercial companies have to face.
So, why does Hubo Technology dare to open source?
Chen Ye gave two reasons:
First, as a technician in the field of AI, out of the most instinctive desire for technology Faith, he is a little passionate and a little sensational.
We want to contribute to China’s innovation with a world-class large-scale model. Giving the industry a usable general model with a solid underlying foundation will allow more people to quickly train large professional models and realize the ecological creation of industrial clusters.
Second, TigerBot will continue to maintain high-speed iteration. Chen Ye believes that in this racing situation, they can maintain their position Advantage. Even if we see someone developing a product with better performance based on TigerBot, isn't this a good thing for the industry?
Chen Ye revealed that Hubo Technology will continue to rapidly advance the work of TigerBot and further expand data to improve model performance.
Six months after the release of ChatGPT, with the emergence of large models one after another and the rapid follow-up of giants, the AI industry landscape is changing. was rapidly reinvented.
Although it is still relatively chaotic at the moment, roughly speaking, it is basically divided into three layers: model layer, middle layer, and application layer.
The model layer determines the underlying capabilities, which is very important.
Its degree of innovation, stability, and openness directly determine the richness of the application layer.
The development of the application layer is an external manifestation of the evolution of large model trends; it is also an important influencing factor for the next stage of human social life in the AIGC vision.
So, at the starting point of the big model trend, how to consolidate the foundation of the underlying model is something that the industry must think about.
In Chen Ye’s view, humans have only developed 10-20% of the potential of large models, and there is still a lot of room for innovation and improvement at the fundamental level.
Just like the gold rush in the West, the original goal was to find where the gold mine was.
Therefore, under such trends and industry development requirements, Hubo Technology, as a representative of innovation in the domestic field, holds high the banner of open source, starts quickly, catches up with the world's most cutting-edge technology, and indeed brings benefits to the industry. There is a distinctive atmosphere.
Domestic AI innovation is running at a high speed. In the future, I believe we will see more teams with ideas and capabilities appearing to inject new insights and bring new changes to the field of large models.
And this may be the most fascinating part of the trend’s vigorous evolution.
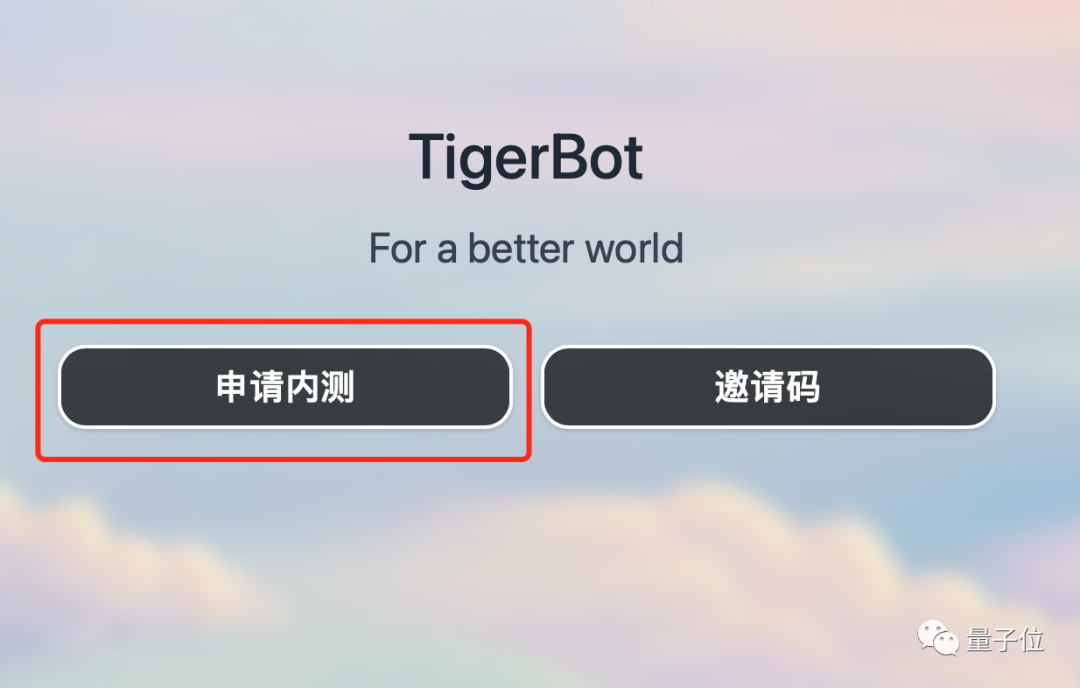
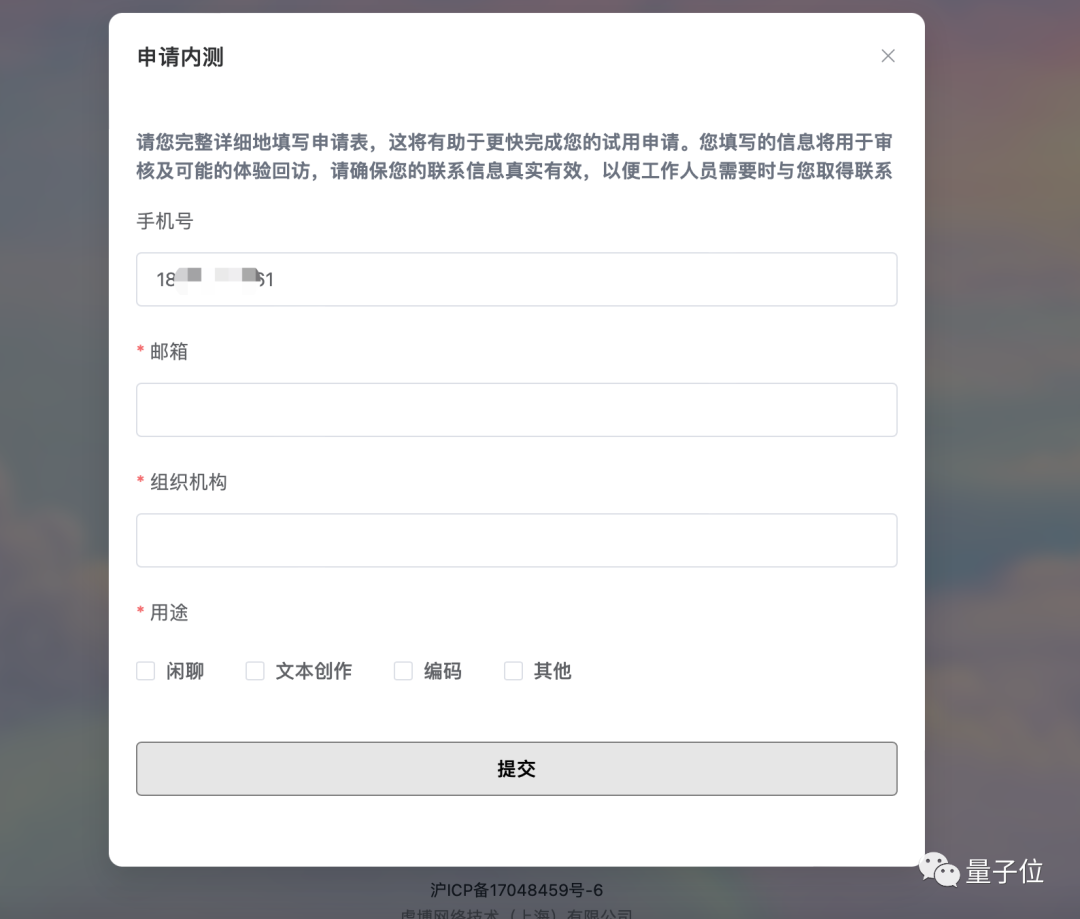
If you want to experience TigerBot's children's shoes, you can enter the website through the link below or click "Read the original text", click "Apply for Internal Beta", and write "Qubit" in the organization code. Can pass internal testing~
Official website address: https://www.tigerbot.com/chat
#GitHub open source address: https://github.com/TigerResearch/TigerBot
The above is the detailed content of The effect reaches 96% of the OpenAI model of the same scale, and it is open source upon release! The domestic team releases a new large model, and the CEO goes to the battle to write code. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



