
 Technology peripherals
AI
Chinese language model rush test: SenseTime, Shanghai AI Lab and others newly released 'Scholar·Puyu'
Technology peripherals
AI
Chinese language model rush test: SenseTime, Shanghai AI Lab and others newly released 'Scholar·Puyu'
Chinese language model rush test: SenseTime, Shanghai AI Lab and others newly released 'Scholar·Puyu'

Heart of Machine Release
Heart of Machine Editorial Department
Today, the annual college entrance examination officially kicked off.
Different from previous years, when candidates across the country rushed to the examination room, some large language models also became special players in this competition.
As AI large language models increasingly demonstrate near-human intelligence, highly difficult, comprehensive exams designed for humans are increasingly being introduced to evaluate the intelligence level of language models.
For example, in the technical report on GPT-4, OpenAI mainly tests the model's ability through examinations in various fields, and the excellent "test-taking ability" displayed by GPT-4 is also unexpected.
What are the results of the Chinese Language Model Challenge College Entrance Examination Paper? Can it catch up with ChatGPT? Let's take a look at the performance of a "candidate".
Comprehensive "Big Exam": "Scholar·Puyu" multiple results are ahead of ChatGPT
Recently, SenseTime and Shanghai AI Laboratory, together with the Chinese University of Hong Kong, Fudan University and Shanghai Jiao Tong University, released the 100-billion-level parameter large language model "Scholar Puyu" (InternLM).
"Scholar·Puyu" has 104 billion parameters and is trained on a multi-lingual high-quality data set containing 1.6 trillion tokens.
Comprehensive evaluation results show that "Scholar Puyu" not only performs well in multiple test tasks such as knowledge mastery, reading comprehension, mathematical reasoning, multilingual translation, etc., but also has strong comprehensive ability. Therefore, he is very successful in the comprehensive examination. It has outstanding performance in many Chinese exams and has achieved results exceeding ChatGPT, including the data set (GaoKao) of various subjects in the Chinese College Entrance Examination.
The "Scholar·Puyu" joint team selected more than 20 evaluations to test them, including the world's most influential four comprehensive examination evaluation sets:
- Multi-task test evaluation set MMLU built by the University of California, Berkeley and other universities;
- AGIEval, a subject examination evaluation set launched by Microsoft Research (including China's college entrance examination, judicial examination, and American SAT, LSAT, GRE and GMAT, etc.);
- C-Eval, a comprehensive examination evaluation set for Chinese language models jointly constructed by Shanghai Jiao Tong University, Tsinghua University and the University of Edinburgh;
- and Gaokao, a collection of college entrance examination questions constructed by the Fudan University research team;
The joint laboratory team conducted a comprehensive test on "Scholar Puyu", GLM-130B, LLaMA-65B, ChatGPT and GPT-4. The results of the above four evaluation sets are compared as follows (full score is 100 points).
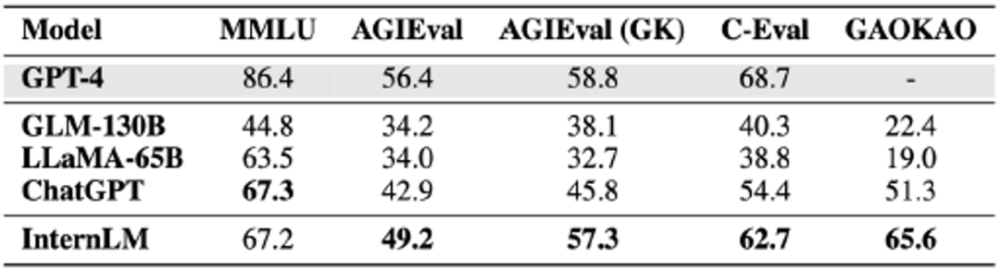
"Scholar Puyu" not only significantly surpasses academic open source models such as GLM-130B and LLaMA-65B, but also leads ChatGPT in multiple comprehensive exams such as AGIEval, C-Eval, and Gaokao; in the United States exam The main MMLU achieves the same level as ChatGPT. The results of these comprehensive examinations reflect the solid knowledge and excellent comprehensive ability of "Scholar Puyu". Although "Scholar·Puyu" achieved excellent results in the exam evaluation, it can also be seen in the evaluation that the large language model still has many limitations. "Scholar Puyu" is limited by the context window length of 2K (the context window length of GPT-4 is 32K), and there are obvious limitations in long text understanding, complex reasoning, code writing, and mathematical logic deduction. In addition, in actual conversations, large language models still have common problems such as illusion and conceptual confusion. These limitations make the use of large language models in open scenarios still have a long way to go.
Four comprehensive examination evaluation data set resultsMMLU is a multi-task test evaluation set jointly constructed by the University of California, Berkeley (UC Berkeley), Columbia University, the University of Chicago, and UIUC, covering elementary mathematics, physics, chemistry, computer science, U.S. history, law, economics, and diplomacy and many other disciplines.
The results of subdivided accounts are shown in the table below.
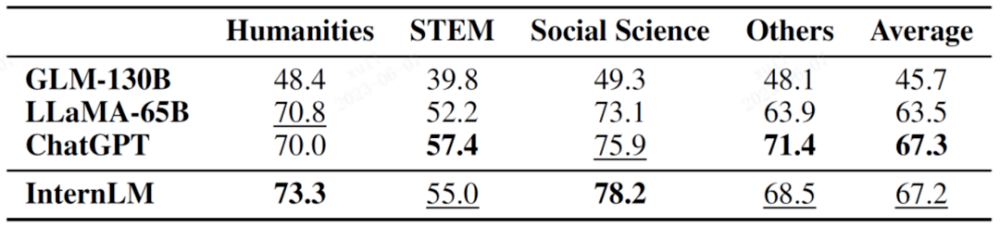 Bold in the figure indicates the best result, and underline indicates the second result
Bold in the figure indicates the best result, and underline indicates the second result
AGIEval is a new subject examination evaluation set proposed by Microsoft Research this year. The main goal is to evaluate the ability of language models through oriented examinations, thereby achieving a comparison between model intelligence and human intelligence.
This evaluation set consists of 19 evaluation items based on various examinations in China and the United States, including China's college entrance examinations, judicial examinations, and important examinations such as SAT, LSAT, GRE, and GMAT in the United States. It is worth mentioning that 9 of these 19 majors are from the Chinese College Entrance Examination, and are usually listed as an important evaluation subset AGIEval (GK).
In the following table, those marked with GK are Chinese college entrance examination subjects.
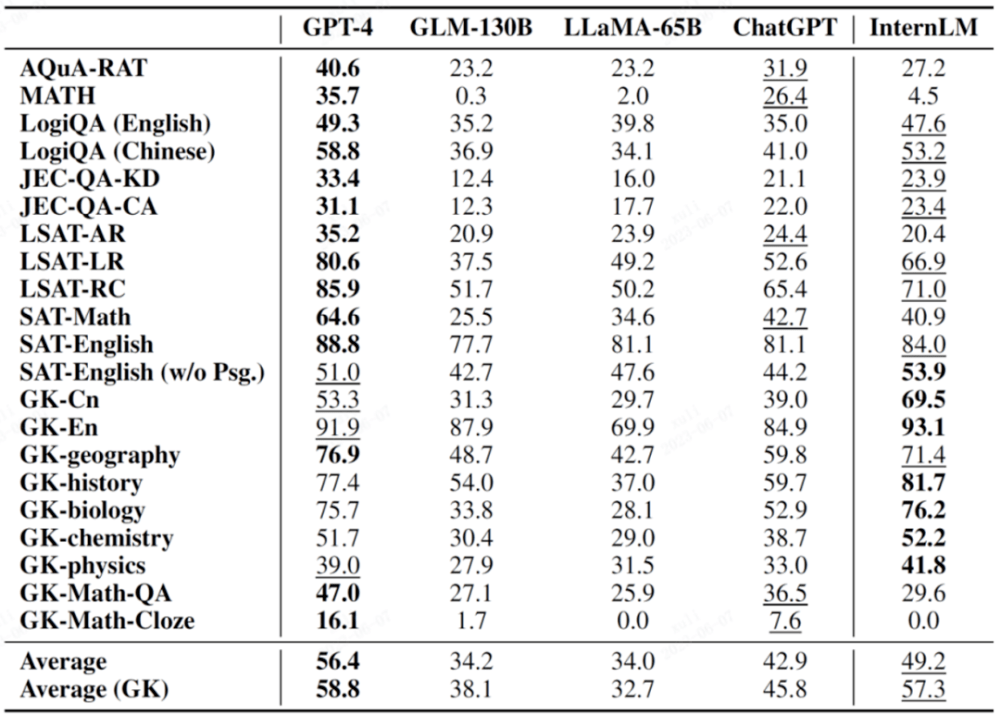
Bold in the figure indicates the best result, and underline indicates the second result
C-Eval is a comprehensive examination evaluation set for Chinese language models jointly constructed by Shanghai Jiao Tong University, Tsinghua University and the University of Edinburgh.
It contains nearly 14,000 test questions in 52 subjects, covering mathematics, physics, chemistry, biology, history, politics, computer and other subject examinations, as well as professional examinations for civil servants, certified public accountants, lawyers, and doctors.
Test results can be obtained through leaderboard.
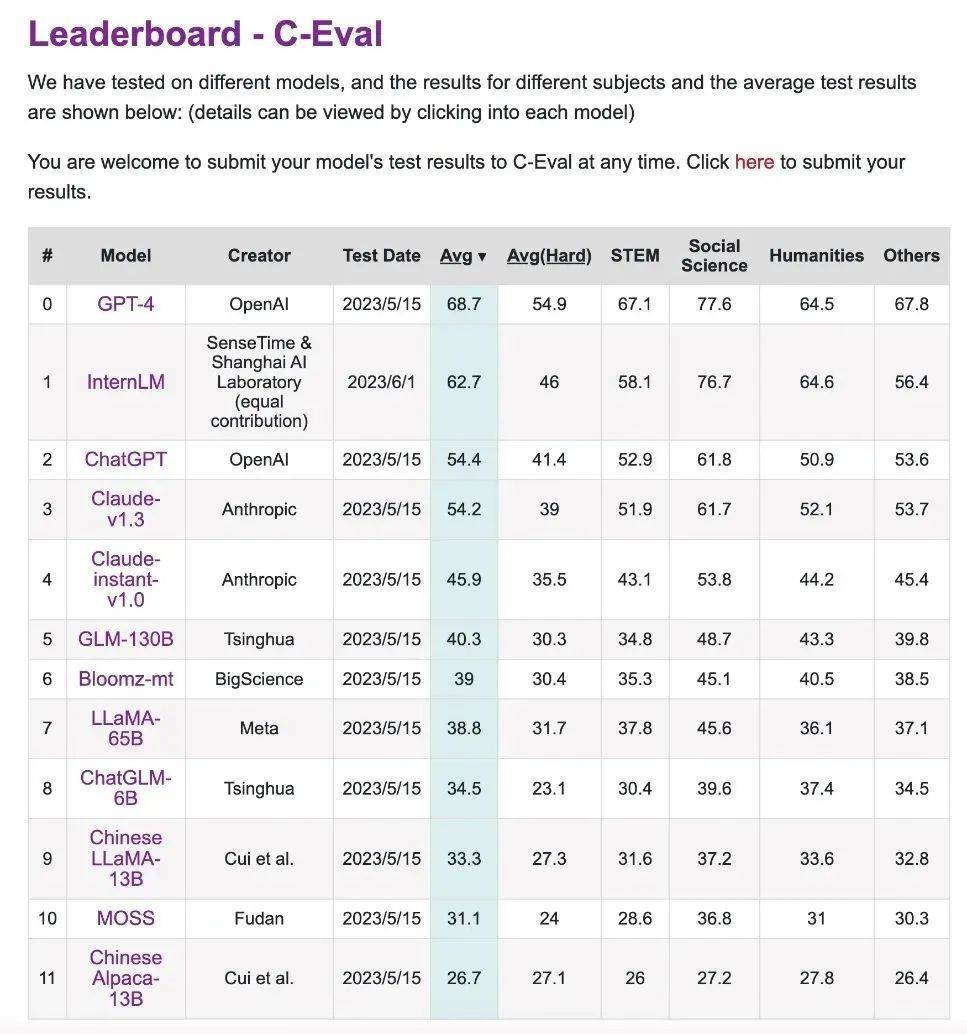
This link is the ranking list of CEVA evaluation competition
Gaokao is a comprehensive examination assessment set based on the China College Entrance Examination questions constructed by the Fudan University research team. It includes various subjects of the China College Entrance Examination, as well as multiple question types such as multiple choice, fill-in-the-blank, and question-and-answer questions.
In the GaoKao evaluation, "Scholar·Puyu" leads ChatGPT in more than 75% of the projects.
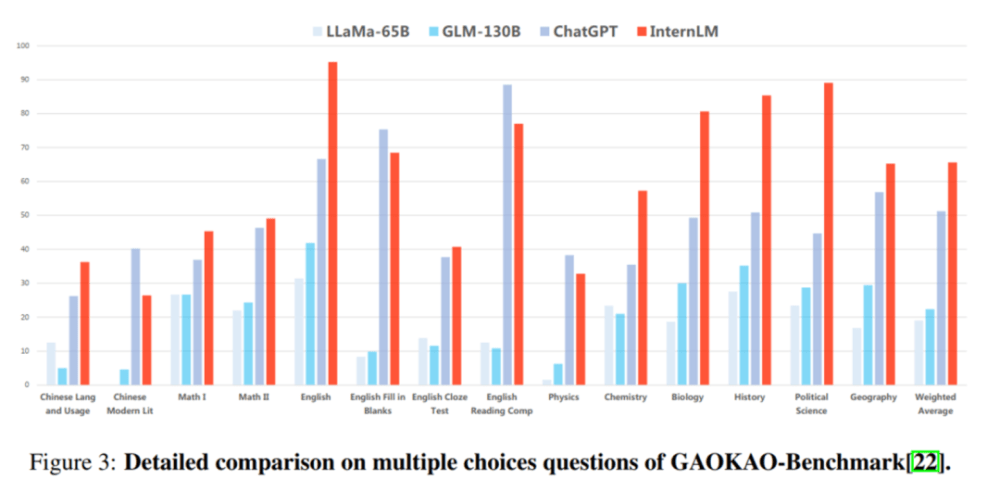
Sub-evaluation: Excellent performance in reading comprehension and reasoning ability
In order to avoid "partiality", the researchers also evaluated and compared the sub-item abilities of language models such as "Scholar Puyu" through multiple academic evaluation sets.
The results show that "Scholar Puyu" not only performs well in reading comprehension in Chinese and English, but also achieves good results in mathematical reasoning, programming ability and other evaluations.
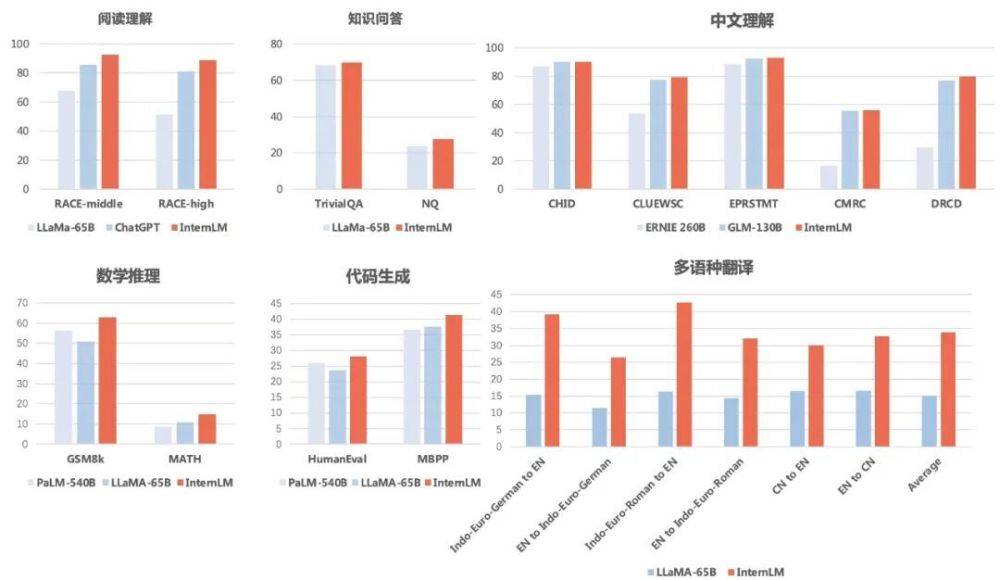
In terms of knowledge question and answer, "Scholar Puyu" scored 69.8 and 27.6 on TriviaQA and NaturalQuestions, both surpassing LLaMA-65B (scores of 68.2 and 23.8).
In terms of reading comprehension (English), "Scholar·Puyu" is clearly ahead of LLaMA-65B and ChatGPT. Puyu scored 92.7 and 88.9 in middle school and high school English reading comprehension, 85.6 and 81.2 on ChatGPT, and even lower on LLaMA-65B.
In terms of Chinese understanding, the results of "Scholar Puyu" comprehensively surpassed the two main Chinese language models ERNIE-260B and GLM-130B.
In terms of multilingual translation, "Scholar·Puyu" has an average score of 33.9 in multilingual translation, significantly surpassing LLaMA (average score 15.1).
In terms of mathematical reasoning, "Scholar Puyu" scored 62.9 and 14.9 respectively in GSM8K and MATH, two mathematics tests that are widely used for evaluation, significantly ahead of Google's PaLM. -540B (scores of 56.5 and 8.8) and LLaMA-65B (scores of 50.9 and 10.9).
In terms of programming ability, "Scholar Puyu" scored 28.1 and 41.4 respectively in the two most representative assessments, HumanEval and MBPP (after fine-tuning in the coding field , the score on HumanEval can be improved to 45.7), significantly ahead of PaLM-540B (scores of 26.2 and 36.8) and LLaMA-65B (scores of 23.7 and 37.7).
In addition, the researchers also evaluated the security of "Scholar Puyu". On TruthfulQA (mainly evaluating the factual accuracy of the answers) and CrowS-Pairs (mainly evaluating whether the answers contain bias), "Scholar Puyu" language" have reached the leading level.The above is the detailed content of Chinese language model rush test: SenseTime, Shanghai AI Lab and others newly released 'Scholar·Puyu'. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Replit Agent: A Guide With Practical Examples
Mar 04, 2025 am 10:52 AM
Replit Agent: A Guide With Practical Examples
Mar 04, 2025 am 10:52 AM
Revolutionizing App Development: A Deep Dive into Replit Agent Tired of wrestling with complex development environments and obscure configuration files? Replit Agent aims to simplify the process of transforming ideas into functional apps. This AI-p
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 How to Use DALL-E 3: Tips, Examples, and Features
Mar 09, 2025 pm 01:00 PM
How to Use DALL-E 3: Tips, Examples, and Features
Mar 09, 2025 pm 01:00 PM
DALL-E 3: A Generative AI Image Creation Tool Generative AI is revolutionizing content creation, and DALL-E 3, OpenAI's latest image generation model, is at the forefront. Released in October 2023, it builds upon its predecessors, DALL-E and DALL-E 2
 Elon Musk & Sam Altman Clash over $500 Billion Stargate Project
Mar 08, 2025 am 11:15 AM
Elon Musk & Sam Altman Clash over $500 Billion Stargate Project
Mar 08, 2025 am 11:15 AM
The $500 billion Stargate AI project, backed by tech giants like OpenAI, SoftBank, Oracle, and Nvidia, and supported by the U.S. government, aims to solidify American AI leadership. This ambitious undertaking promises a future shaped by AI advanceme
 5 Grok 3 Prompts that Can Make Your Work Easy
Mar 04, 2025 am 10:54 AM
5 Grok 3 Prompts that Can Make Your Work Easy
Mar 04, 2025 am 10:54 AM
Grok 3 – Elon Musk and xAi’s latest AI model is the talk of the town these days. From Andrej Karpathy to tech influencers, everyone is talking about the capabilities of this new model. Initially, access was limited to
 Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google DeepMind's GenCast: A Revolutionary AI for Weather Forecasting Weather forecasting has undergone a dramatic transformation, moving from rudimentary observations to sophisticated AI-powered predictions. Google DeepMind's GenCast, a groundbreak
