
 Technology peripherals
AI
OpenAI dominates the top two! The large model code generation ranking list is released, with 7 billion LLaMA surpassing it and being beaten by 250 million Codex.
Technology peripherals
AI
OpenAI dominates the top two! The large model code generation ranking list is released, with 7 billion LLaMA surpassing it and being beaten by 250 million Codex.
OpenAI dominates the top two! The large model code generation ranking list is released, with 7 billion LLaMA surpassing it and being beaten by 250 million Codex.

Recently, a tweet by Matthias Plappert ignited widespread discussion in the LLMs circle.
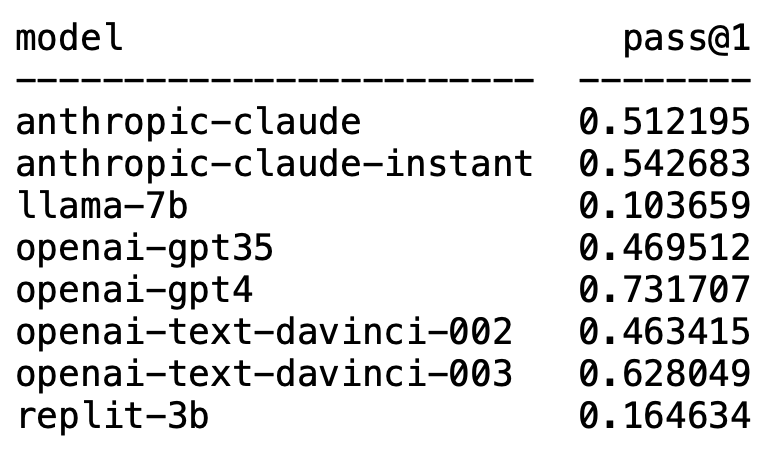
Plappert is a well-known computer scientist. He published his benchmark test results on the mainstream LLM in the AI circle on HumanEval.
His testing is biased towards code generation.
The results are both shocking and shocking.

Unexpectedly, GPT-4 undoubtedly dominated the list and took first place.
Unexpectedly, OpenAI’s text-davinci-003 suddenly emerged and took second place.
Plappert said that text-davinci-003 can be called a "treasure" model.
The familiar LLaMA is not good at code generation.
OpenAI dominates the list
Plappert said that the performance of GPT-4 is even better than the data in the literature.
The GPT-4 round of test data in the paper has a pass rate of 67%, while Plappert’s test reached 73%.

When analyzing the causes, he said that there are many possibilities for discrepancies in the data. One of them is that the prompt he gave to GPT-4 was slightly better than when the author of the paper tested it.
Another reason is that he guessed that the temperature of the model was not 0 when the paper tested GPT-4.
"Temperature" is a parameter used to adjust the creativity and diversity of text generated by the model. "Temperature" is a value greater than 0, usually between 0 and 1. It affects the probability distribution of sampled predicted words when the model generates text.
When the "temperature" of the model is higher (such as 0.8, 1 or higher), the model will be more inclined to choose from more diverse and different words, which makes the generated Texts are riskier and more creative, but may also produce more errors and incoherencies.
When the "temperature" is low (such as 0.2, 0.3, etc.), the model will mainly select from words with higher probability, thus producing smoother and more coherent text .
But at this point, the generated text may appear too conservative and repetitive.
Therefore, in actual applications, it is necessary to weigh and select the appropriate "temperature" value based on specific needs.
Next, when commenting on text-davinci-003, Plappert said that this is also a very capable model under OpenAI.
Although it is not as good as GPT-4, the pass rate of 62% in one round of testing can still firmly win the second place.
Plappert emphasized that the best thing about text-davinci-003 is that users do not need to use ChatGPT’s API. This means giving prompts can be simpler.
In addition, Plappert also gave Anthropic AI’s claude-instant model a relatively high evaluation.
He believes that the performance of this model is good and can beat GPT-3.5. The pass rate of GPT-3.5 is 46%, while the pass rate of claude-instant is 54%.
Of course, Anthropic AI’s other LLM, claude, cannot be played by claude-instant, and the pass rate is only 51%.
Plappert said that the prompts used to test the two models are the same. If it doesn’t work, it doesn’t work.
In addition to these familiar models, Plappert has also tested many open source small models.
Plappert said that it is good that he can run these models locally.
However, in terms of scale, these models are obviously not as big as those of OpenAI and Anthropic AI, so comparing them is a bit overwhelming.

LLaMA code generation? Pulling the hips
Of course, Plappert was not satisfied with the LLaMA test results.
Judging from the test results, LLaMA performed very poorly in generating code. Probably because they used under-sampling when collecting data from GitHub.
Even compared with Codex 2.5B, the performance of LLaMA is not the same. (Pass rate 10% vs. 22%)

Finally, he tested Replit’s 3B size model.
He said that the performance was not bad, but compared with the data promoted on Twitter (pass rate 16% vs. 22%)
Plappert believes this may be because the quantification method he used when testing the model caused the pass rate to drop by a few percentage points.
At the end of the review, Plappert mentioned a very interesting point.
A user discovered on Twitter that GPT-3.5-turbo performs better when using the Completion API of the Azure platform (rather than the Chat API) good.
Plappert believes that this phenomenon has some legitimacy, because entering prompts through the Chat API can be quite complicated.

The above is the detailed content of OpenAI dominates the top two! The large model code generation ranking list is released, with 7 billion LLaMA surpassing it and being beaten by 250 million Codex.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
36
110
52
36
110

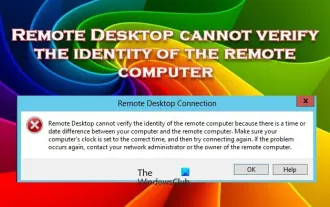 Remote Desktop cannot authenticate the remote computer's identity
Feb 29, 2024 pm 12:30 PM
Remote Desktop cannot authenticate the remote computer's identity
Feb 29, 2024 pm 12:30 PM
Windows Remote Desktop Service allows users to access computers remotely, which is very convenient for people who need to work remotely. However, problems can be encountered when users cannot connect to the remote computer or when Remote Desktop cannot authenticate the computer's identity. This may be caused by network connection issues or certificate verification failure. In this case, the user may need to check the network connection, ensure that the remote computer is online, and try to reconnect. Also, ensuring that the remote computer's authentication options are configured correctly is key to resolving the issue. Such problems with Windows Remote Desktop Services can usually be resolved by carefully checking and adjusting settings. Remote Desktop cannot verify the identity of the remote computer due to a time or date difference. Please make sure your calculations
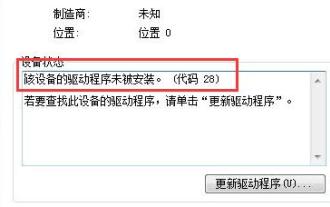 How to solve win7 driver code 28
Dec 30, 2023 pm 11:55 PM
How to solve win7 driver code 28
Dec 30, 2023 pm 11:55 PM
Some users encountered errors when installing the device, prompting error code 28. In fact, this is mainly due to the driver. We only need to solve the problem of win7 driver code 28. Let’s take a look at what should be done. Do it. What to do with win7 driver code 28: First, we need to click on the start menu in the lower left corner of the screen. Then, find and click the "Control Panel" option in the pop-up menu. This option is usually located at or near the bottom of the menu. After clicking, the system will automatically open the control panel interface. In the control panel, we can perform various system settings and management operations. This is the first step in the nostalgia cleaning level, I hope it helps. Then we need to proceed and enter the system and
 2024 CSRankings National Computer Science Rankings Released! CMU dominates the list, MIT falls out of the top 5
Mar 25, 2024 pm 06:01 PM
2024 CSRankings National Computer Science Rankings Released! CMU dominates the list, MIT falls out of the top 5
Mar 25, 2024 pm 06:01 PM
The 2024CSRankings National Computer Science Major Rankings have just been released! This year, in the ranking of the best CS universities in the United States, Carnegie Mellon University (CMU) ranks among the best in the country and in the field of CS, while the University of Illinois at Urbana-Champaign (UIUC) has been ranked second for six consecutive years. Georgia Tech ranked third. Then, Stanford University, University of California at San Diego, University of Michigan, and University of Washington tied for fourth place in the world. It is worth noting that MIT's ranking fell and fell out of the top five. CSRankings is a global university ranking project in the field of computer science initiated by Professor Emery Berger of the School of Computer and Information Sciences at the University of Massachusetts Amherst. The ranking is based on objective
 What to do if the blue screen code 0x0000001 occurs
Feb 23, 2024 am 08:09 AM
What to do if the blue screen code 0x0000001 occurs
Feb 23, 2024 am 08:09 AM
What to do with blue screen code 0x0000001? The blue screen error is a warning mechanism when there is a problem with the computer system or hardware. Code 0x0000001 usually indicates a hardware or driver failure. When users suddenly encounter a blue screen error while using their computer, they may feel panicked and at a loss. Fortunately, most blue screen errors can be troubleshooted and dealt with with a few simple steps. This article will introduce readers to some methods to solve the blue screen error code 0x0000001. First, when encountering a blue screen error, we can try to restart
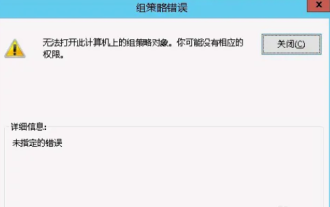 Unable to open the Group Policy object on this computer
Feb 07, 2024 pm 02:00 PM
Unable to open the Group Policy object on this computer
Feb 07, 2024 pm 02:00 PM
Occasionally, the operating system may malfunction when using a computer. The problem I encountered today was that when accessing gpedit.msc, the system prompted that the Group Policy object could not be opened because the correct permissions may be lacking. The Group Policy object on this computer could not be opened. Solution: 1. When accessing gpedit.msc, the system prompts that the Group Policy object on this computer cannot be opened because of lack of permissions. Details: The system cannot locate the path specified. 2. After the user clicks the close button, the following error window pops up. 3. Check the log records immediately and combine the recorded information to find that the problem lies in the C:\Windows\System32\GroupPolicy\Machine\registry.pol file
 The computer frequently blue screens and the code is different every time
Jan 06, 2024 pm 10:53 PM
The computer frequently blue screens and the code is different every time
Jan 06, 2024 pm 10:53 PM
The win10 system is a very excellent high-intelligence system. Its powerful intelligence can bring the best user experience to users. Under normal circumstances, users’ win10 system computers will not have any problems! However, it is inevitable that various faults will occur in excellent computers. Recently, friends have been reporting that their win10 systems have encountered frequent blue screens! Today, the editor will bring you solutions to different codes that cause frequent blue screens in Windows 10 computers. Let’s take a look. Solutions to frequent computer blue screens with different codes each time: causes of various fault codes and solution suggestions 1. Cause of 0×000000116 fault: It should be that the graphics card driver is incompatible. Solution: It is recommended to replace the original manufacturer's driver. 2,
 Resolve code 0xc000007b error
Feb 18, 2024 pm 07:34 PM
Resolve code 0xc000007b error
Feb 18, 2024 pm 07:34 PM
Termination Code 0xc000007b While using your computer, you sometimes encounter various problems and error codes. Among them, the termination code is the most disturbing, especially the termination code 0xc000007b. This code indicates that an application cannot start properly, causing inconvenience to the user. First, let’s understand the meaning of termination code 0xc000007b. This code is a Windows operating system error code that usually occurs when a 32-bit application tries to run on a 64-bit operating system. It means it should
 Detailed explanation of the causes and solutions of 0x0000007f blue screen code
Dec 25, 2023 pm 02:19 PM
Detailed explanation of the causes and solutions of 0x0000007f blue screen code
Dec 25, 2023 pm 02:19 PM
Blue screen is a problem we often encounter when using the system. Depending on the error code, there will be many different reasons and solutions. For example, when we encounter the problem of stop: 0x0000007f, it may be a hardware or software error. Let’s follow the editor to find out the solution. 0x000000c5 blue screen code reason: Answer: The memory, CPU, and graphics card are suddenly overclocked, or the software is running incorrectly. Solution 1: 1. Keep pressing F8 to enter when booting, select safe mode, and press Enter to enter. 2. After entering safe mode, press win+r to open the run window, enter cmd, and press Enter. 3. In the command prompt window, enter "chkdsk /f /r", press Enter, and then press the y key. 4.
