

Smooth operation and maintenance, an iron pot


On June 5, Vipshop released a fault report on March 29, 2023. Due to a fault in the Nansha IDC refrigeration system, the Vipshop online mall stopped serving, causing Hundreds of millions of losses (as a small operation and maintenance person, I tremble).
For Vipshop, the online mall is its core business entrance, and failures are inevitable. However, it cannot be tolerated if the failure is so long. Why does this happen? In the eyes of small operators like us, this kind of accident should not happen in a company of this magnitude. We are all looking for ways to operate and maintain by imitating and learning from their PPTs.
However, PPT is so advanced that it cannot prevent failures from occurring. Why is this?
I personally venture to make some guesses:
- PPT≠ Reality
- Fault drill = going through the motions?
- Live a long life, just talk about it?
- It’s hard for a clever woman to make a meal without rice
PPT≠ Reality
There are now various domestic technology conferences, and then invite CTOs and technologies from some well-known companies The person in charge gave a speech. Judging from the speech, every company is very strong (at least this is how it is shown on the PPT). Every time I listen, I will suddenly become enlightened and benefit a lot. I admire these companies from the bottom of my heart and admire their super strength. Great thinking, great abilities, and a cool team.
However, PPT is only an auxiliary tool after all, it cannot replace the status quo.
Beautiful PPT is only for those who want to see it. Unbeautiful things have to be endured alone.
I have seen Vipshop’s sharing on GOPS before, and the PPT presentation is really great. If you use this to report to the boss, the boss will also feel that our company’s technology is really powerful and our work is really good. It gave the boss the illusion that everything was fine.
If something goes wrong, who will you do if you don’t do it?
The awesomeness that blows out of your own mouth will also come back to your own mouth.
Fault drill = going through the motions?
In the book "SRE: Decryption of Google Operations and Maintenance", fault drills occupy a large space. Through fault drills, the reliability and fault tolerance of the system can be improved, the team can better understand the architecture and working principles of the system, the mutual influence of each module can be better understood, and loopholes and loopholes in the system architecture can be discovered more quickly. Fault.
It can be said that fault drills are the core link of the entire stability guarantee, because it can help the team minimize actual faults and respond to possible problems more efficiently.
But, is this true in practice?
When actually conducting a fault drill, the fault point must be predetermined, specific countermeasures must be organized and outputted, a comprehensive plan must be designated, and each person's job responsibilities and tasks must be accurately described.
These preparatory work alone requires a lot of manpower and material resources. Many teams and many people will streamline steps and measures. They will treat fault drills with the mentality that it will be done and treat faults with the mentality of luck. itself, placing hope on others not having problems.
For example, if you place your hopes on the public cloud, if there is no problem with the public cloud, the entire system will be stable, but the public cloud ≠ is completely reliable. Major accidents have occurred in Google Cloud, Alibaba Cloud, Tencent Cloud, etc. However, paying the bill It’s the users themselves.
Therefore, the operation and maintenance team or the SRE team needs to take fault drills seriously. Not only must they make preparatory work for the drill, they must also pay close attention to the plan during the drill, take timely measures and make corrections if problems are discovered. .
Don’t let the drill become a formality, don’t let the drill become a KPI, otherwise you will be the next optimization target.
It’s just a talk?
The problem with Vipshop on March 29 can be reflected from the side: "Duohuo" may be just talk.
As the business develops, the system architecture will continue to evolve because our requirements for high availability are getting higher and higher.
For example, upgrade from a single-machine architecture in the same computer room to an active-standby architecture, then upgrade to a multi-machine room architecture in the same city, and finally reach the three-center architecture level in two places.
If Vipshop built multiple computer rooms in the same city, even the simplest main and backup systems in the same city would not be down for 12 hours.
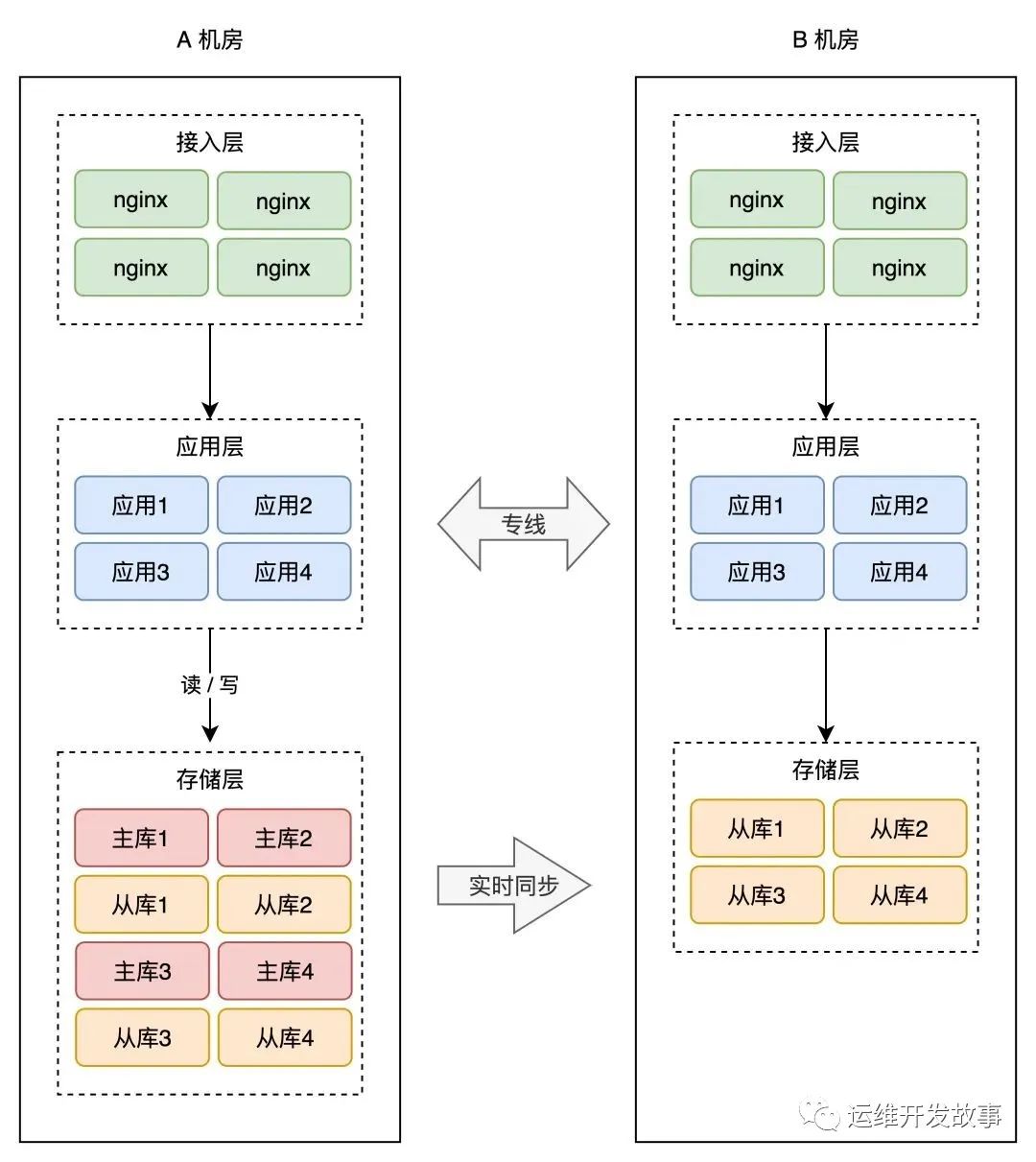
Not to mention if you do dual live in the same city.
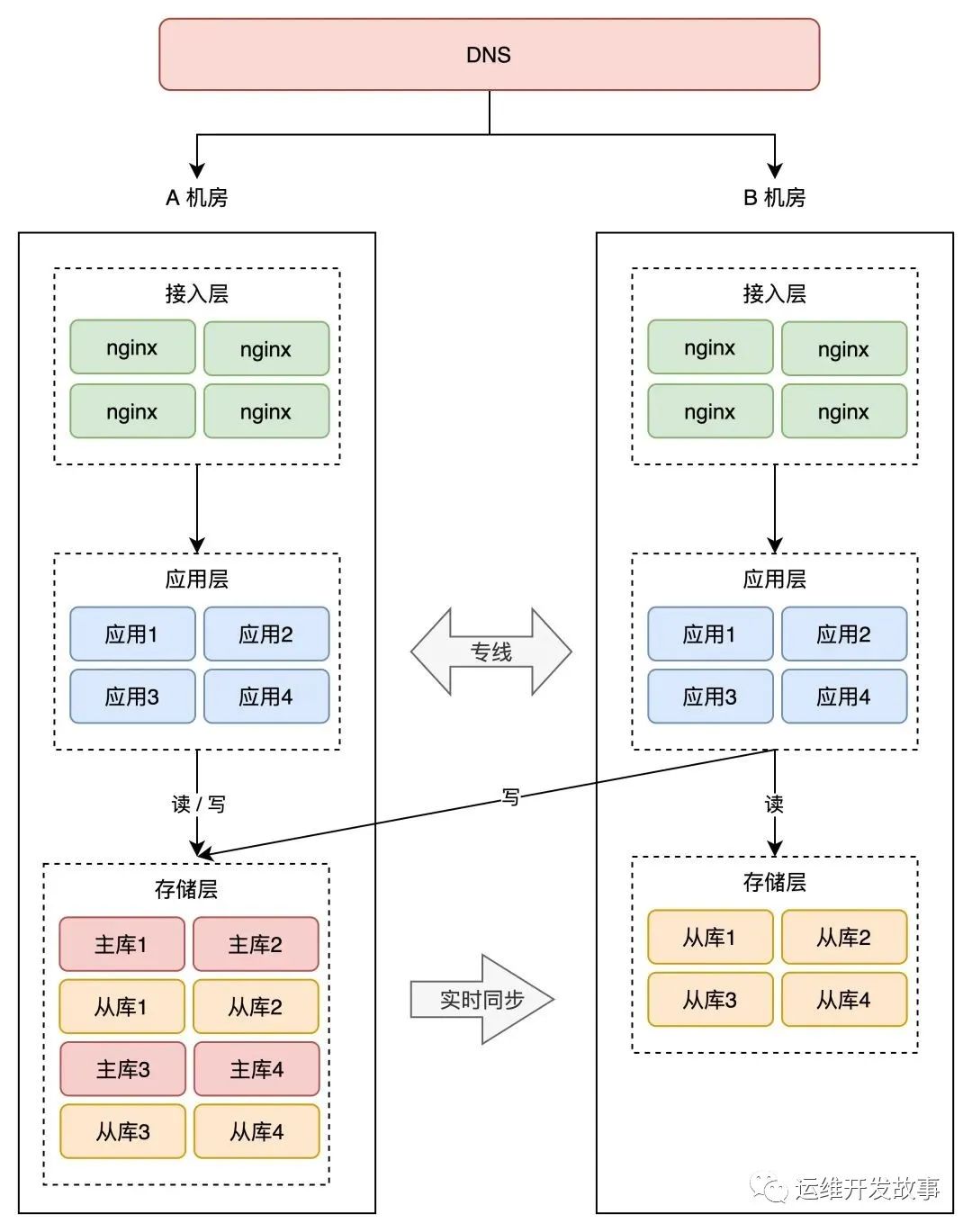
But, I am just guessing from God’s perspective. Maybe they also do a lot of work, but they are just pretending to work a lot.
It’s hard for a clever woman to make a meal without rice
The bosses above will all come up with financial, human and material resources in the end. Take Duohuo as an example, build a city-wide disaster preparedness, The cost of investment is not as simple as dubbo. Whenever the person in charge of SRE reports to apply for funds, if the leaders above do not support it (the money is not earned, but so much is spent), everything is in vain.
Leaders need to control costs, and subordinates need money to do things. Insufficient costs lead to inability to make ends meet, and there will be a situation where the PPT is beautiful, but the reality is terrible.
Even if you have ambition, it is useless.
If something goes wrong, I will sacrifice you to heaven.
Finally
The above is purely fictitious. If there are any similarities, please like it~
In many companies, operation and maintenance have a strong say Low, ridiculously low, which makes it difficult for operation and maintenance to do things or advance things.
However, once a problem occurs, operation and maintenance are the first to be pushed out, so the "scapegoat" has always been blamed on operation and maintenance.
So what should we do as an operation and maintenance officer?
- Go out - don’t be limited to the operation and maintenance team, go out and let the business departments know the value of operation and maintenance.
- Go inside - the operation and maintenance knowledge system is complex and ever-changing. You need to go inside the knowledge, deeply understand the principles behind it, and use your expertise to serve the team.
- Go up - to improve the influence of operation and maintenance, win more trust and support through professional ability and positive attitude, change the status quo and enhance the status.
Finally, let’s talk about it, don’t make fun of production.
The above is the detailed content of Smooth operation and maintenance, an iron pot. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Having worked in operation and maintenance for more than ten years, there have been countless moments when I felt like I was still a novice...
Jun 09, 2023 pm 09:53 PM
Having worked in operation and maintenance for more than ten years, there have been countless moments when I felt like I was still a novice...
Jun 09, 2023 pm 09:53 PM
Once upon a time, when I was a fresh graduate majoring in computer science, I browsed many job postings on recruitment websites. I was confused by the dazzling technical positions: R&D engineer, operation and maintenance engineer, test engineer... During college, my professional courses were so-so, not to mention having any technical vision, and I had no clear ideas about which technical direction to pursue. Until a senior student said to me: "Do operation and maintenance. You don't have to write code every day to do operation and maintenance. You just need to be able to play Liunx! It's much easier than doing development!" I chose to believe... I have been in the industry for more than ten years , I have suffered a lot, shouldered a lot of blame, killed servers, and experienced department layoffs. If someone tells me now that operation and maintenance is easier than development, then I will
 Spring Boot Actuator Endpoint Revealed: Easily Monitor Your Application
Jun 09, 2023 pm 10:56 PM
Spring Boot Actuator Endpoint Revealed: Easily Monitor Your Application
Jun 09, 2023 pm 10:56 PM
1. Introduction to SpringBootActuator endpoint 1.1 What is Actuator endpoint SpringBootActuator is a sub-project used to monitor and manage SpringBoot applications. It provides a series of built-in endpoints (Endpoints) that can be used to view the status, operation status and operation indicators of the application. Actuator endpoints can be exposed to external systems in HTTP, JMX or other forms to facilitate operation and maintenance personnel to monitor, diagnose and manage applications. 1.2 The role and function of the endpoint The Actuator endpoint is mainly used to implement the following functions: providing health check of the application, including database connection, caching,
 Spring Cloud microservice architecture deployment and operation
Jun 23, 2023 am 08:19 AM
Spring Cloud microservice architecture deployment and operation
Jun 23, 2023 am 08:19 AM
With the rapid development of the Internet, the complexity of enterprise-level applications is increasing day by day. In response to this situation, the microservice architecture came into being. With its modularity, independent deployment, and high scalability, it has become the first choice for enterprise-level application development today. As an excellent microservice architecture, Spring Cloud has shown great advantages in practical applications. This article will introduce the deployment and operation and maintenance of SpringCloud microservice architecture. 1. Deploy SpringCloud microservice architecture SpringCloud
 What capabilities should PG database operation and maintenance tools cover?
Jun 08, 2023 pm 06:56 PM
What capabilities should PG database operation and maintenance tools cover?
Jun 08, 2023 pm 06:56 PM
Before the holidays, I collaborated with the PG China community to conduct an online live broadcast on how to use D-SMART to operate and maintain the PG database. It happened that one of my clients in the financial industry listened to my introduction and called over to chat. They are selecting database Xinchuang and have tried several domestic databases. Finally, they are going to choose TDSQL. I felt a little surprised at the time. They had been selecting domestic databases since 2020, but it seemed that the initial experience after using TDSQL was not very good. Later, after communication, I learned that they had just started using TDSQL's distributed database and found that the research and development requirements were too high, so they all chose TDSQL's centralized MYSQL instance. After using it, they found that it was very easy to use. The entire database cloud
 What is observability? Everything a beginner needs to know
Jun 08, 2023 pm 02:42 PM
What is observability? Everything a beginner needs to know
Jun 08, 2023 pm 02:42 PM
The term observability originates from the engineering field and has become increasingly popular in the software development field in recent years. Simply put, observability is the ability to understand the internal state of a system based on external outputs. IBM defines observability as: Generally, observability refers to the degree to which the internal state or condition of a complex system can be understood based on knowledge of its external output. The more observable the system is, the faster and more accurate the process of locating the root cause of a performance issue can be without the need for additional testing or coding. In cloud computing, observability also refers to software tools and practices that aggregate, correlate, and analyze data from distributed application systems and the infrastructure that supports their operation in order to more effectively monitor, troubleshoot, and debug application systems. , thereby achieving customer experience optimization and service level agreement
 Tuyou Zou Yi: How to operate and maintain small and medium-sized companies?
Jun 09, 2023 pm 01:56 PM
Tuyou Zou Yi: How to operate and maintain small and medium-sized companies?
Jun 09, 2023 pm 01:56 PM
Through interviews and submissions, veterans in the field of operation and maintenance are invited to provide profound insights and collide together, with a view to forming some advanced consensus and promoting the industry to move forward better. In this issue, we invite Zou Yi, the operation and maintenance director of Tuyou Games. Mr. Zou often jokingly calls himself the operation and maintenance representative of the world's top 5 million companies. It can be seen that in his heart, he feels that the operation and maintenance construction ideas of small and medium-sized companies are different from those of large enterprises. There are differences. Today we have a few questions and ask Mr. Zou to share his journey of integrating research and operations for small and medium-sized companies. This is the 6th issue of the down-to-earth and high-level "Operation and Maintenance Forum", starting now! Question Preview Tuyou is a game company. What do you think are the unique features of game operation and maintenance? What are the biggest operational challenges you face? How did you solve these challenges? Game operation and maintenance people
 Do you need to learn golang for operation and maintenance?
Jul 17, 2023 pm 01:27 PM
Do you need to learn golang for operation and maintenance?
Jul 17, 2023 pm 01:27 PM
Don’t learn golang for operation and maintenance. The reasons are: 1. Golang is mainly used to develop applications with high performance and concurrent performance requirements; 2. The tools and scripting languages commonly used by operation and maintenance engineers can already meet most management and Maintenance requirements; 3. Learning golang requires a certain programming foundation and experience; 4. The main goal of the operation and maintenance engineer is to ensure the stability and high availability of the system, not to develop applications.
 Du Xiaoman and Chen Cunli: 20-year-old 'commander' talks about operation and maintenance, performance and growth
Jun 09, 2023 am 09:56 AM
Du Xiaoman and Chen Cunli: 20-year-old 'commander' talks about operation and maintenance, performance and growth
Jun 09, 2023 am 09:56 AM
Through interviews and submissions, veterans in the field of operation and maintenance are invited to provide profound insights and collide together, with a view to forming some advanced consensus and promoting the industry to move forward better. In this issue, we invite Chen Cunli, general manager of Du Xiaoman System Operation and Maintenance Department. He has spent most of his 20-year career in the Internet field. During his time in the Baidu Operations and Maintenance Department, his team members called him "Commander Chen" due to his excellent leadership style. Today we invite "Commander Chen" to talk about his views. This is the 5th issue of the down-to-earth and high-level "Operation and Maintenance Forum", starting now! Question preview: You joined Baidu very early and later became independent with Du Xiaoman. We understand that many employees around you have been following you for a long time and have experienced many business operation and maintenance tests. I believe everyone is very interested.
