
 Technology peripherals
AI
The strongest API calling model is here! Based on LLaMA fine-tuning, the performance exceeds GPT-4
Technology peripherals
AI
The strongest API calling model is here! Based on LLaMA fine-tuning, the performance exceeds GPT-4
The strongest API calling model is here! Based on LLaMA fine-tuning, the performance exceeds GPT-4

After the alpaca, there is another model named after an animal, this time it is the gorilla.
Although LLM is currently booming, making a lot of progress, and its performance in various tasks is also remarkable, the potential of these models to effectively use tools through API calls is still urgently needed. Digging.
Even for today’s most advanced LLMs, such as GPT-4, API calls are a challenging task, mainly due to their inability to generate accurate input parameters and the ease with which LLMs Hallucinations caused by incorrect use of API calls.
No, the researchers have developed Gorilla, a fine-tuned LLaMA-based model, whose performance even exceeds GPT-4 in writing API calls.
When combined with a document retriever, Gorilla also demonstrates powerful performance, making user updates or version changes more flexible.
In addition, Gorilla also greatly alleviates the hallucination problem that LLM often encounters.
To evaluate the model’s capabilities, the researchers also introduced the API Benchmark, a comprehensive dataset composed of HuggingFace, TorchHub and TensorHub APIs
Gorilla
Needless to introduce the powerful abilities of LLMs, including natural conversation ability, mathematical reasoning ability, and program synthesis ability.
However, despite its powerful performance, LLM still suffers from some limitations. Moreover, LLM also needs to be retrained to update their knowledge base and reasoning capabilities in a timely manner.
By authorizing the tools available to LLM, researchers can allow LLM to access a vast and ever-changing knowledge base to complete complex computing tasks.
By providing access to search technologies and databases, researchers can enhance LLM's ability to address larger and more dynamic knowledge spaces.
Similarly, by providing the use of calculation tools, LLM can also complete complex calculation tasks.
Therefore, technology giants have begun to try to integrate various plug-ins to enable LLM to call external tools through APIs.
The transition from a smaller, hand-coded tool to one capable of calling a vast, ever-changing cloud API space can transform LLM into computing infrastructure, and The main interface required by the network.
Tasks from booking an entire vacation to hosting a conference can become as simple as talking to an LLM with access to web APIs for flights, car rentals, hotels, dining and entertainment.
However, much prior work integrating tools into LLM considers a small set of well-documented APIs that can be easily injected into prompts.
Supporting a web-scale collection of potentially millions of changing APIs requires a rethinking of how researchers integrate tools.
It is no longer possible to describe all APIs in a single environment. Many APIs will have overlapping functionality, with subtle limitations and constraints. Simply evaluating LLM in this new environment requires new benchmarks.
In this paper, researchers explore methods for using self-structure fine-tuning and retrieval to enable LLM to accurately derive data from large, overlapping, and varying data expressed using its API and API documentation. Make selections in the toolset.
Researchers built API Bench by scraping ML APIs (models) from public model centers, a large corpus of APIs with complex and often overlapping functionality.
The researchers chose three main model hubs to build the dataset: TorchHub, TensorHub, and HuggingFace.
The researchers exhaustively included every API call in TorchHub (94 API calls) and TensorHub (696 API calls).
For HuggingFace, due to the large number of models, the researchers selected the 20 most downloaded models in each task category (925 in total).
The researchers also used Self-Instruct to generate prompts for 10 user questions for each API.
Therefore, each entry in the data set becomes an instruction reference API pair. The researchers employed common AST subtree matching techniques to evaluate the functional correctness of the generated APIs.
The researcher first parses the generated code into an AST tree, then finds a subtree whose root node is the API call the researcher cares about, and then uses this to index the researcher's data set.
Researchers check the functional correctness and hallucination issues of LLMs and provide feedback on the corresponding accuracy. The researchers then fine-tuned Gorilla, a model based on LLaMA-7B, to perform document retrieval using the researchers' data set.
The researchers found that Gorilla significantly outperformed GPT-4 in terms of API functionality accuracy and reduced illusory errors.
The researchers show an example in Figure 1.

In addition, the researchers’ retrieval-aware training of Gorilla enabled the model to adapt to changes in API documentation.
Finally, the researchers also demonstrated Gorilla’s ability to understand and reason about constraints.
In addition, Gorilla also performed well in terms of illusion.
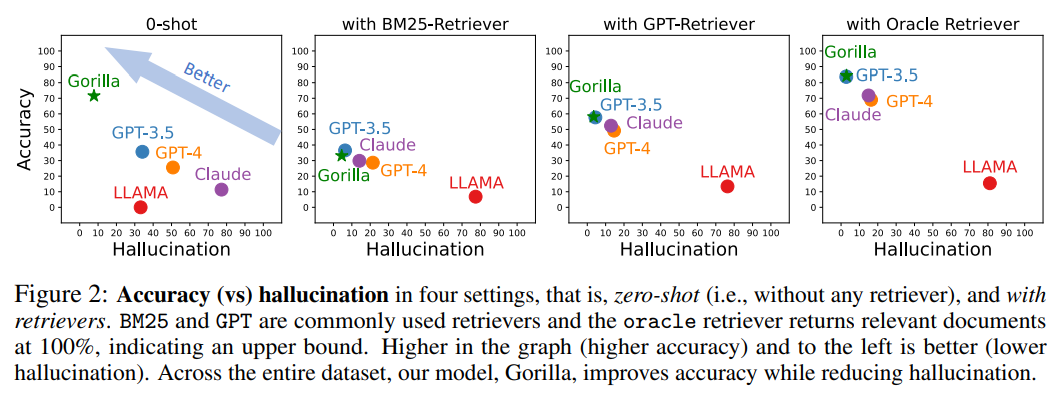
The following figure is a comparison of accuracy and hallucination in four cases, zero samples (i.e., without any retriever) and using retrievers of BM25, GPT and Oracle.
BM25 and GPT are commonly used search engines, while the Oracle search engine will return relevant documents with 100% relevance, indicating an upper limit.
The one with higher accuracy and fewer illusions in the picture has better effect.
Across the entire dataset, Gorilla improves accuracy while reducing hallucinations.
#In order to collect the data set, the researchers carefully recorded HuggingFace’s The Model Hub, PyTorch Hub and TensorFlow Hub models All online models.
The HuggingFace platform hosts and serves a total of 203,681 models.
However, the documentation for many of these models is poor.
To filter out these low-quality models, the researchers finally selected the top 20 models from each domain.
The researchers considered 7 domains for multimodal data, 8 domains for CV, 12 domains for NLP, 5 domains for audio, 2 domains for tabular data, and 2 areas of reinforcement learning.
After filtering, the researchers obtained a total of 925 models from HuggingFace. The versions of TensorFlow Hub are divided into v1 and v2.
The latest version (v2) has a total of 801 models, and the researchers processed all models. After filtering out models with little information, 626 models remained.
Similar to TensorFlow Hub, the researchers obtained 95 models from Torch Hub.
Under the guidance of the self-instruct paradigm, the researchers adopted GPT-4 to generate synthetic instruction data.
The researchers provided three in-context examples, as well as a reference API document, and tasked the model with generating real use cases for calling the API.
The researchers specifically instructed the model not to use any API names or hints when creating instructions. The researchers built six examples (instruction-API pairs) for each of the three model hubs.
These 18 points are the only manually generated or modified data.
And Gorilla is a retrieval-aware LLaMA-7B model, specifically used for API calls.
As shown in Figure 3, the researchers used self-construction to generate {instruction, API} pairs.
To fine-tune LLaMA, the researchers converted it into a user-agent chat-style conversation, where each data point is a conversation and the user and agent take turns talking.
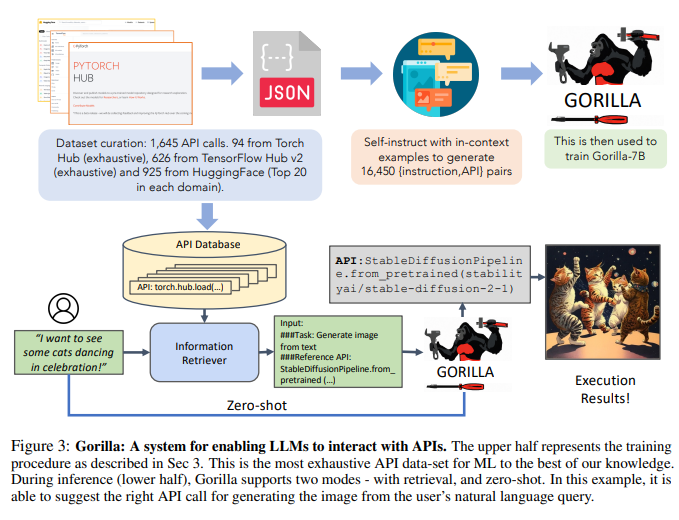
The researchers then performed standard instruction fine-tuning on the basic LLaMA-7B model. In experiments, the researchers trained Gorilla with and without a retriever.
In the study, the researchers focused on techniques designed to improve LLM's ability to accurately identify appropriate APIs for specific tasks - something that is critical in the development of this technology. But an aspect that is often overlooked.
Because the API functions as a universal language that enables effective communication between different systems, proper use of the API can improve LLM's ability to interact with a wider range of tools.
Gorilla outperformed state-of-the-art LLM (GPT-4) on three large-scale datasets collected by the researchers. Gorilla produces reliable ML models of API calls without hallucinations and satisfies constraints when selecting APIs.
Desiring to find a challenging dataset, the researchers chose ML APIs because of their similar functionality. A potential drawback of ML-focused APIs is that if trained on biased data, they have the potential to produce biased predictions that may disadvantage certain subgroups.
To address this concern and promote deeper understanding of these APIs, researchers are releasing a more extensive dataset that includes more than 11,000 instruction-API pairs.
In the example below, researchers used abstract syntax tree (AST) subtree matching to evaluate the correctness of API calls.
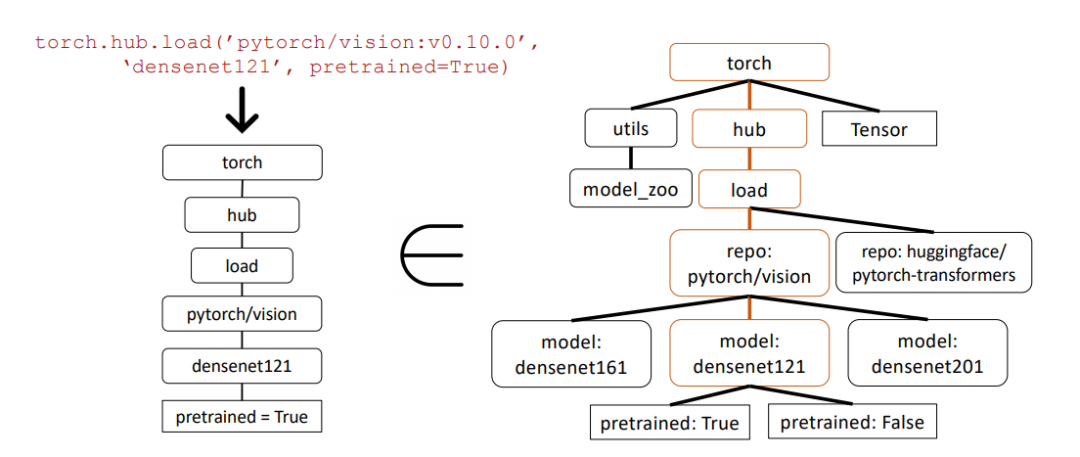
Abstract syntax tree is a tree representation of the source code structure, which helps to better analyze and understand the code.
First, the researchers built the relevant API tree from the API calls returned by Gorilla (left). This is then compared to the dataset to see if the API dataset has a subtree match.
In the above example, the matching subtree is highlighted in brown, indicating that the API call is indeed correct. Where Pretrained=True is an optional parameter.
This resource will serve the broader community as a valuable tool for studying and measuring existing APIs, contributing to more equitable and optimal use of machine learning.
The above is the detailed content of The strongest API calling model is here! Based on LLaMA fine-tuning, the performance exceeds GPT-4. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to define header files for vscode
Apr 15, 2025 pm 09:09 PM
How to define header files for vscode
Apr 15, 2025 pm 09:09 PM
How to define header files using Visual Studio Code? Create a header file and declare symbols in the header file using the .h or .hpp suffix name (such as classes, functions, variables) Compile the program using the #include directive to include the header file in the source file. The header file will be included and the declared symbols are available.
 Do you use c in visual studio code
Apr 15, 2025 pm 08:03 PM
Do you use c in visual studio code
Apr 15, 2025 pm 08:03 PM
Writing C in VS Code is not only feasible, but also efficient and elegant. The key is to install the excellent C/C extension, which provides functions such as code completion, syntax highlighting, and debugging. VS Code's debugging capabilities help you quickly locate bugs, while printf output is an old-fashioned but effective debugging method. In addition, when dynamic memory allocation, the return value should be checked and memory freed to prevent memory leaks, and debugging these issues is convenient in VS Code. Although VS Code cannot directly help with performance optimization, it provides a good development environment for easy analysis of code performance. Good programming habits, readability and maintainability are also crucial. Anyway, VS Code is
 Can vscode run kotlin
Apr 15, 2025 pm 06:57 PM
Can vscode run kotlin
Apr 15, 2025 pm 06:57 PM
Running Kotlin in VS Code requires the following environment configuration: Java Development Kit (JDK) and Kotlin compiler Kotlin-related plugins (such as Kotlin Language and Kotlin Extension for VS Code) create Kotlin files and run code for testing to ensure successful environment configuration
 Which one is better, vscode or visual studio
Apr 15, 2025 pm 08:36 PM
Which one is better, vscode or visual studio
Apr 15, 2025 pm 08:36 PM
Depending on the specific needs and project size, choose the most suitable IDE: large projects (especially C#, C) and complex debugging: Visual Studio, which provides powerful debugging capabilities and perfect support for large projects. Small projects, rapid prototyping, low configuration machines: VS Code, lightweight, fast startup speed, low resource utilization, and extremely high scalability. Ultimately, by trying and experiencing VS Code and Visual Studio, you can find the best solution for you. You can even consider using both for the best results.
 Can vscode be used for java
Apr 15, 2025 pm 08:33 PM
Can vscode be used for java
Apr 15, 2025 pm 08:33 PM
VS Code is absolutely competent for Java development, and its powerful expansion ecosystem provides comprehensive Java development capabilities, including code completion, debugging, version control and building tool integration. In addition, VS Code's lightweight, flexibility and cross-platformity make it better than bloated IDEs. After installing JDK and configuring JAVA_HOME, you can experience VS Code's Java development capabilities by installing "Java Extension Pack" and other extensions, including intelligent code completion, powerful debugging functions, construction tool support, etc. Despite possible compatibility issues or complex project configuration challenges, these issues can be addressed by reading extended documents or searching for solutions online, making the most of VS Code’s
 What does sublime renewal balm mean
Apr 16, 2025 am 08:00 AM
What does sublime renewal balm mean
Apr 16, 2025 am 08:00 AM
Sublime Text is a powerful customizable text editor with advantages and disadvantages. 1. Its powerful scalability allows users to customize editors through plug-ins, such as adding syntax highlighting and Git support; 2. Multiple selection and simultaneous editing functions improve efficiency, such as batch renaming variables; 3. The "Goto Anything" function can quickly jump to a specified line number, file or symbol; but it lacks built-in debugging functions and needs to be implemented by plug-ins, and plug-in management requires caution. Ultimately, the effectiveness of Sublime Text depends on the user's ability to effectively configure and manage it.
 How to beautify json with vscode
Apr 15, 2025 pm 05:06 PM
How to beautify json with vscode
Apr 15, 2025 pm 05:06 PM
Beautifying JSON data in VS Code can be achieved by using the Prettier extension to automatically format JSON files so that key-value pairs are arranged neatly and indented clearly. Configure Prettier formatting rules as needed, such as indentation size, line breaking method, etc. Use the JSON Schema Validator extension to verify the validity of JSON files to ensure data integrity and consistency.
 Can vscode run c
Apr 15, 2025 pm 08:24 PM
Can vscode run c
Apr 15, 2025 pm 08:24 PM
Of course! VS Code integrates IntelliSense, debugger and other functions through the "C/C" extension, so that it has the ability to compile and debug C. You also need to configure a compiler (such as g or clang) and a debugger (in launch.json) to write, run, and debug C code like you would with other IDEs.
