
 Technology peripherals
AI
Real-time protection against face-blocking barrages on the web (based on machine learning)
Technology peripherals
AI
Real-time protection against face-blocking barrages on the web (based on machine learning)
Real-time protection against face-blocking barrages on the web (based on machine learning)

Anti-face barrage, that is, a large number of barrages float by, but do not block the characters in the video screen. It looks like they are floating from behind the characters.
Machine learning has been popular for several years, but many people don’t know that these capabilities can also be run in browsers;
This article introduces the practical optimization process in video barrages, listed at the end of the article Some scenarios where this solution is applicable are described, hoping to open up some ideas.
mediapipe Demo(https://google.github.io/mediapipe/)shows
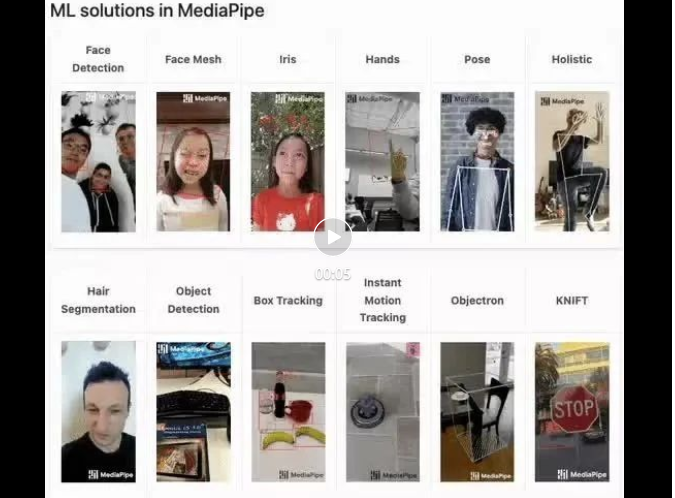
mainstream anti-face barrage implementation principle
On-demand
up Upload video
The server background calculation extracts the portrait area in the video screen and converts it into svg storage
While the client plays the video, download the svg from the server Combined with the barrage, the portrait area does not display the barrage
Live broadcast
- When the anchor pushes the stream, the portrait area is extracted from the screen in real time (host device) and converted into svg
- Merge svg data into the video stream (SEI) and push the stream to the server
- At the same time as the client plays the video, parse the svg from the video stream (SEI)
- Compile the svg with the bullet Screen synthesis, the portrait area does not display the barrage
Implementation plan of this article
While the client plays the video, the portrait area information is extracted from the screen in real time, and the portrait area information is exported into pictures and bullets Screen synthesis, the barrage will not be displayed in the portrait area.
Implementation Principle
- Use machine learning open source libraries to extract portrait outlines from video images in real time, such as Body Segmentation (https://github.com/tensorflow/tfjs-models/blob/ master/body-segmentation/README.md)
- Export the portrait outline into a picture, and set the mask-image of the barrage layer (https://developer.mozilla.org/zh-CN/docs/ Web/CSS/mask-image)
Compared with the traditional (live broadcast SEI real-time) solution
Advantages:
- Easy to implement; only one Video tag is required Parameters, no need for multi-end coordination
- No network bandwidth consumption
Disadvantages:
- The theoretical performance limit is inferior to traditional solutions; equivalent to exchanging performance resources for the network Resources
Problems Faced
JavaScript is known to have poor performance, making it unsuitable for CPU-intensive tasks. From official demo to engineering practice, the biggest challenge is performance.
This practice finally optimized the CPU usage to about 5% (2020 M1 Macbook), reaching a production-ready state.
Practice tuning process
Select a machine learning model
BodyPix (https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation/ src/body_pix/README.md)
The accuracy is too poor, the face is narrow, and there is obvious overlap between the barrage and the character's facial edges

BlazePose (https://github.com/tensorflow/tfjs-models/blob/master/pose-detection/src/blazepose_mediapipe/README.md)
has excellent accuracy and provides limb point information. But the performance is poor

Return data structure example
[{score: 0.8,keypoints: [{x: 230, y: 220, score: 0.9, score: 0.99, name: "nose"},{x: 212, y: 190, score: 0.8, score: 0.91, name: "left_eye"},...],keypoints3D: [{x: 0.65, y: 0.11, z: 0.05, score: 0.99, name: "nose"},...],segmentation: {maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}}]MediaPipe SelfieSegmentation (https://github.com/tensorflow/tfjs-models/blob/master /body-segmentation/src/selfie_segmentation_mediapipe/README.md)
The accuracy is excellent (the effect is consistent with the BlazePose model), the CPU usage is about 15% lower than the BlazePose model, and the performance is superior, but the limbs are not provided in the returned data Point information
Return data structure example
{maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}First version implementation
Refer to MediaPipe SelfieSegmentation model official implementation (https://github.com/tensorflow/tfjs-models/blob /master/body-segmentation/README.md#bodysegmentationdrawmask), without optimization, the CPU takes up about 70%
const canvas = document.createElement('canvas')canvas.width = videoEl.videoWidthcanvas.height = videoEl.videoHeightasync function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl)const foregroundColor = { r: 0, g: 0, b: 0, a: 0 }const backgroundColor = { r: 0, g: 0, b: 0, a: 255 } const mask = await toBinaryMask(segmentation, foregroundColor, backgroundColor) await drawMask(canvas, canvas, mask, 1, 9)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 33)} detect().catch(console.error)Reduce the extraction frequency and balance the performance-experience
General video 30FPS, Try lowering the barrage mask (hereinafter referred to as Mask) refresh frequency to 15FPS, which is still acceptable in terms of experience
window.setTimeout(detect, 66) // 33 => 66
At this time, the CPU takes up about 50%
Solves the performance bottleneck
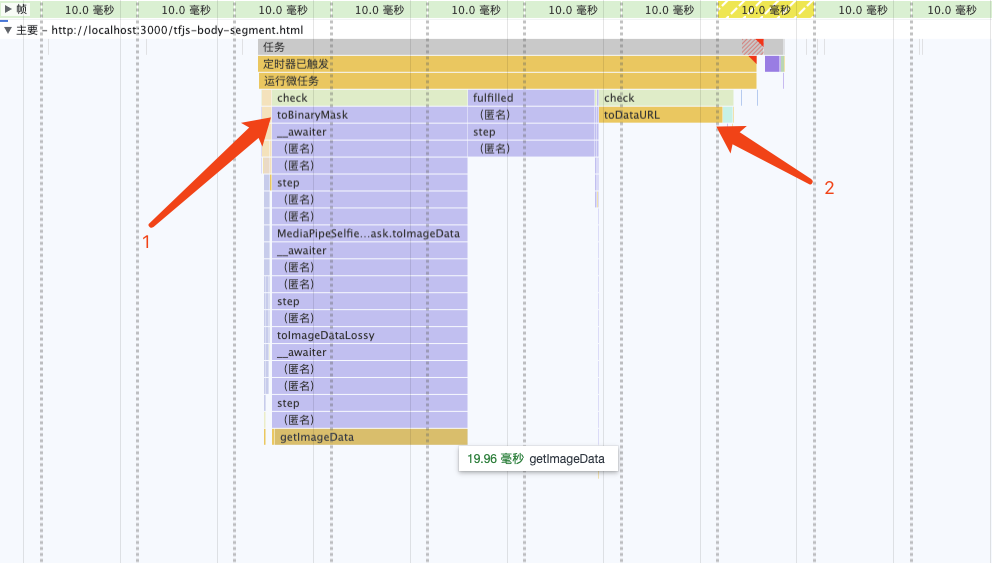
Analyzing the flame graph, it can be found that the performance bottleneck is in toBinaryMask and toDataURL
Rewrite toBinaryMask
Analyze the source code, combined with printing segmentation information, find segmentation.mask .toCanvasImageSource can obtain the original ImageBitmap object, which is the information extracted by the model. Try writing your own code to convert an ImageBitmap to a Mask instead of using the default implementation provided by the open source library.
Implementation Principle
async function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl) context.clearRect(0, 0, canvas.width, canvas.height)// 1. 将`ImageBitmap`绘制到 Canvas 上context.drawImage(// 经验证 即使出现多人,也只有一个 segmentationawait segmentation[0].mask.toCanvasImageSource(),0, 0,canvas.width, canvas.height)// 2. 设置混合模式context.globalCompositeOperation = 'source-out'// 3. 反向填充黑色context.fillRect(0, 0, canvas.width, canvas.height)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 66)}Steps 2 and 3 are equivalent to filling the content outside the portrait area with black (reverse filling ImageBitmap), in order to cooperate with css (mask-image), otherwise only when The barrages are only visible when they float to the portrait area (exactly the opposite of the target effect).
globalCompositeOperation MDN(https://developer.mozilla.org/zh-CN/docs/Web/API/CanvasRenderingContext2D/globalCompositeOperation)
此时,CPU 占用 33% 左右
多线程优化
我原先认为toDataURL是由浏览器内部实现的,无法再进行优化,现在只有优化toDataURL这个耗时操作了。
虽没有替换实现,但可使用 OffscreenCanvas (https://developer.mozilla.org/zh-CN/docs/Web/API/OffscreenCanvas)+ Worker,将耗时任务转移到 Worker 中去, 避免占用主线程,就不会影响用户体验了。
并且ImageBitmap实现了Transferable接口,可被转移所有权,跨 Worker 传递也没有性能损耗(https://hughfenghen.github.io/fe-basic-course/js-concurrent.html#%E4%B8%A4%E4%B8%AA%E6%96%B9%E6%B3%95%E5%AF%B9%E6%AF%94)。
// 前文 detect 的反向填充 ImageBitmap 也可以转移到 Worker 中// 用 OffscreenCanvas 实现, 此处略过 const reader = new FileReaderSync()// OffscreenCanvas 不支持 toDataURL,使用 convertToBlob 代替offsecreenCvsEl.convertToBlob({type: 'image/png',quality: 0}).then((blob) => {const dataURL = reader.readAsDataURL(blob)self.postMessage({msgType: 'mask',val: dataURL})}).catch(console.error)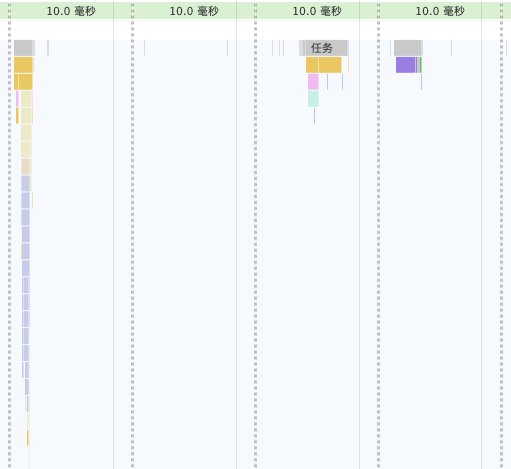
可以看到两个耗时的操作消失了
此时,CPU 占用 15% 左右
降低分辨率
继续分析,上图重新计算样式(紫色部分)耗时约 3ms
Demo 足够简单很容易推测到是这行代码导致的,发现 imgStr 大概 100kb 左右(视频分辨率 1280x720)。
danmakuContainer.style.webkitMaskImage = `url(${imgStr})通过canvas缩小图片尺寸(360P甚至更低),再进行推理。
优化后,导出的 imgStr 大概 12kb,重新计算样式耗时约 0.5ms。
此时,CPU 占用 5% 左右

启动条件优化
虽然提取 Mask 整个过程的 CPU 占用已优化到可喜程度。
当在画面没人的时候,或没有弹幕时候,可以停止计算,实现 0 CPU 占用。
无弹幕判断比较简单(比如 10s 内收超过两条弹幕则启动计算),也不在该 SDK 实现范围,略过
判定画面是否有人
第一步中为了高性能,选择的模型只有ImageBitmap,并没有提供肢体点位信息,所以只能使用getImageData返回的像素点值来判断画面是否有人。
画面无人时,CPU 占用接近 0%
发布构建优化
依赖包的提交较大,构建出的 bundle 体积:684.75 KiB / gzip: 125.83 KiB
所以,可以进行异步加载SDK,提升页面加载性能。
- 分别打包一个 loader,一个主体
- 由业务方 import loader,首次启用时异步加载主体
这个两步前端工程已经非常成熟了,略过细节。
运行效果

总结
过程
- 选择高性能模型后,初始状态 CPU 70%
- 降低 Mask 刷新频率(15FPS),CPU 50%
- 重写开源库实现(toBinaryMask),CPU 33%
- 多线程优化,CPU 15%
- 降低分辨率,CPU 5%
- 判断画面是否有人,无人时 CPU 接近 0%
CPU 数值指主线程占用
注意事项
- 兼容性:Chrome 79及以上,不支持 Firefox、Safari。因为使用了OffscreenCanvas
- 不应创建多个或多次创建segmenter实例(bodySegmentation.createSegmenter),如需复用请保存实例引用,因为:
- 创建实例时低性能设备会有明显的卡顿现象
- 会内存泄露;如果无法避免,这是mediapipe 内存泄露 解决方法(https://github.com/google/mediapipe/issues/2819#issuecomment-1160335349)
经验
- 优化完成之后,提取并应用 Mask 关键计算量在 GPU (30%左右),而不是 CPU
- 性能优化需要业务场景分析,防挡弹幕场景可以使用低分辨率、低刷新率的 mask-image,能大幅减少计算量
- 该方案其他应用场景:
- 替换/模糊人物背景
- 人像马赛克
- 人像抠图
- 卡通头套,虚拟饰品,如猫耳朵、兔耳朵、带花、戴眼镜什么的(换一个模型,略改)
- 关注Web 神经网络 API (https://mp.weixin.qq.com/s/v7-xwYJqOfFDIAvwIVZVdg)进展,以后实现相关功能也许会更简单
本期作者

刘俊
Bilibili Senior Development Engineer
The above is the detailed content of Real-time protection against face-blocking barrages on the web (based on machine learning). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 How to customize the resize symbol through CSS and make it uniform with the background color?
Apr 05, 2025 pm 02:30 PM
How to customize the resize symbol through CSS and make it uniform with the background color?
Apr 05, 2025 pm 02:30 PM
The method of customizing resize symbols in CSS is unified with background colors. In daily development, we often encounter situations where we need to customize user interface details, such as adjusting...
 How to correctly display the locally installed 'Jingnan Mai Round Body' on the web page?
Apr 05, 2025 pm 10:33 PM
How to correctly display the locally installed 'Jingnan Mai Round Body' on the web page?
Apr 05, 2025 pm 10:33 PM
Using locally installed font files in web pages Recently, I downloaded a free font from the internet and successfully installed it into my system. Now...
 The text under Flex layout is omitted but the container is opened? How to solve it?
Apr 05, 2025 pm 11:00 PM
The text under Flex layout is omitted but the container is opened? How to solve it?
Apr 05, 2025 pm 11:00 PM
The problem of container opening due to excessive omission of text under Flex layout and solutions are used...
 Why does a specific div element in the Edge browser not display? How to solve this problem?
Apr 05, 2025 pm 08:21 PM
Why does a specific div element in the Edge browser not display? How to solve this problem?
Apr 05, 2025 pm 08:21 PM
How to solve the display problem caused by user agent style sheets? When using the Edge browser, a div element in the project cannot be displayed. After checking, I posted...
 How to use locally installed font files on web pages?
Apr 05, 2025 pm 10:57 PM
How to use locally installed font files on web pages?
Apr 05, 2025 pm 10:57 PM
How to use locally installed font files on web pages Have you encountered this situation in web page development: you have installed a font on your computer...
 Why does negative margins not take effect in some cases? How to solve this problem?
Apr 05, 2025 pm 10:18 PM
Why does negative margins not take effect in some cases? How to solve this problem?
Apr 05, 2025 pm 10:18 PM
Why do negative margins not take effect in some cases? During programming, negative margins in CSS (negative...
 How to control the top and end of pages in browser printing settings through JavaScript or CSS?
Apr 05, 2025 pm 10:39 PM
How to control the top and end of pages in browser printing settings through JavaScript or CSS?
Apr 05, 2025 pm 10:39 PM
How to use JavaScript or CSS to control the top and end of the page in the browser's printing settings. In the browser's printing settings, there is an option to control whether the display is...
 Why can custom style sheets take effect on local web pages in Safari but not on Baidu pages?
Apr 05, 2025 pm 05:15 PM
Why can custom style sheets take effect on local web pages in Safari but not on Baidu pages?
Apr 05, 2025 pm 05:15 PM
Discussion on using custom stylesheets in Safari Today we will discuss a custom stylesheet application problem for Safari browser. Front-end novice...
