
 Technology peripherals
AI
If they are not aligned, the performance will explode? 13 billion models crush 65 billion, Hugging Face large model rankings released
Technology peripherals
AI
If they are not aligned, the performance will explode? 13 billion models crush 65 billion, Hugging Face large model rankings released
If they are not aligned, the performance will explode? 13 billion models crush 65 billion, Hugging Face large model rankings released

We know that most models have some kind of embedded alignment.
Just give a few examples: Alpaca, Vicuna, WizardLM, MPT-7B-Chat, Wizard-Vicuna, GPT4-X-Vicuna, etc.
Generally speaking, alignment is definitely a good thing. The purpose is to prevent the model from doing bad things - such as generating something illegal.
But where does the alignment come from?
The reason is - these models are trained using data generated by ChatGPT, which itself is aligned by the team at OpenAI.
Since this process is not public, we do not know how OpenAI performs the alignment.
But overall, we can observe that ChatGPT conforms to mainstream American culture, abides by American laws, and has certain inevitable biases.
Logically speaking, alignment is a blameless thing. So should all models be aligned?
Alignment? Not necessarily a good thing
The situation is not that simple.
Recently, HuggingFace released a ranking of open source LLM.
It can be seen at a glance that the 65B model cannot handle the 13B unaligned model.
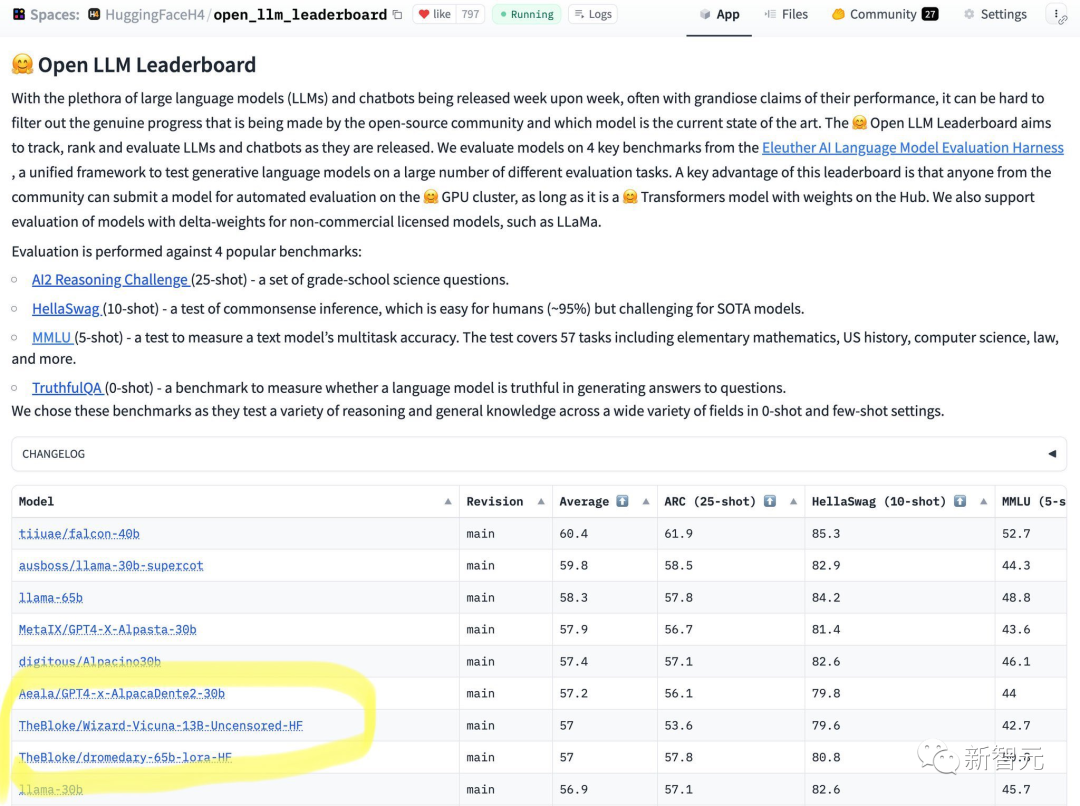
From the results, Wizard-Vicuna-13B-Uncensored-HF can be compared with 65B, 40B and 30B LLMs Compare directly on a range of benchmarks.
Perhaps the trade-off between performance and model review will be an interesting area of research.
This ranking has also caused widespread discussion on the Internet.

Some netizens said that alignment will affect the normal and correct output of the model, which is not a good thing, especially for This is especially true for AI performance.

Another netizen also expressed his approval. He said that Google Brain has also revealed that the performance of the model will decrease if the alignment is too much.
For general purposes, OpenAI's alignment is actually pretty good.
It would undoubtedly be a good thing for public-facing AI to run as an easily accessible web service that refuses to answer controversial and potentially dangerous questions.
So under what circumstances is misalignment needed?
First of all, American pop culture is not the only culture. Open source is the process of letting people make choices.
The only way to achieve this is through composable alignment.
In other words, there is no consistent, timeless alignment.
At the same time, alignment can interfere with effective examples. Take writing a novel as an analogy: some characters in the novel may be outright evil people, and they will commit many immoral behaviors.
However, many aligned models will refuse to output these contents.
The AI model faced by each user should serve everyone's purpose and do different things.
Why should an open source AI running on a personal computer decide on its own output as it answers each user question?
This is no small matter, it’s about ownership and control. If a user asks an AI model a question, the user wants an answer, and they don't want the model to have an illegal argument with them.
Composable alignment
To build a composable alignment, you must start with an unaligned instruction model. Without an unaligned foundation, we cannot align on it.
First, we must technically understand the reasons for model alignment.
Open source AI models are trained from basic models such as LLaMA, GPT-Neo-X, MPT-7b, and Pythia. The base model is then fine-tuned using a data set of instructions, with the goal of teaching it to be helpful, obey users, answer questions, and engage in conversations.
This instruction data set is usually obtained by asking ChatGPT’s API. ChatGPT has built-in alignment functionality.
So ChatGPT will refuse to answer some questions, or output biased answers. Therefore, ChatGPT's alignment is passed on to other open source models, just like an older brother teaching a younger brother.
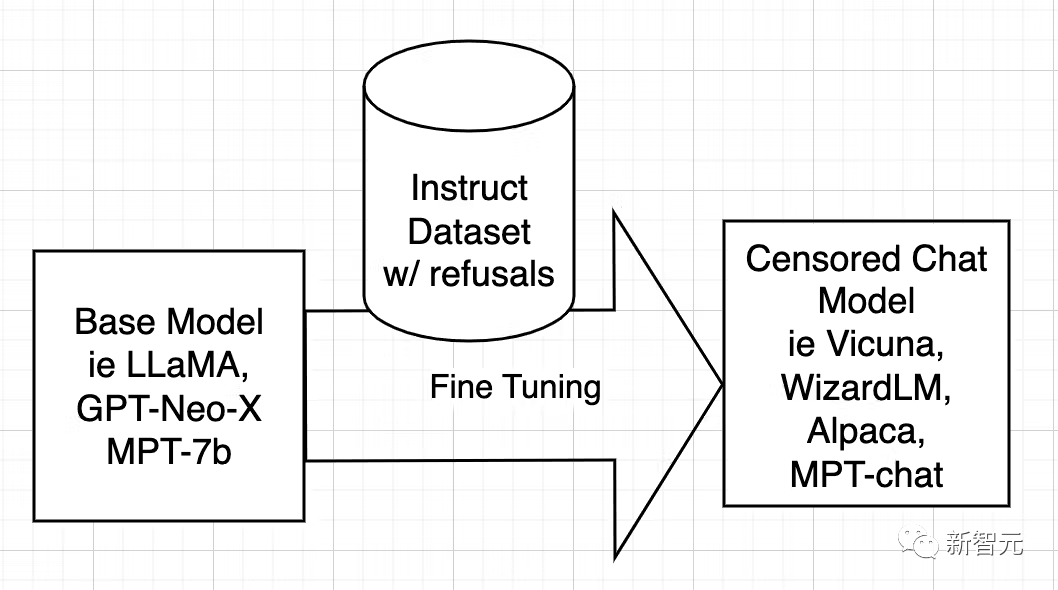
The reason is - the instruction data set is composed of questions and answers. When the data set contains ambiguous When answering, the AI will learn how to say no, under what circumstances to say no, and how to express rejection.
In other words, it's learning alignment.
The strategy for de-censoring models is very simple, which is to identify and remove as many negative and biased answers as possible and keep the rest.
The model is then trained using the filtered dataset in exactly the same way as the original model was trained.
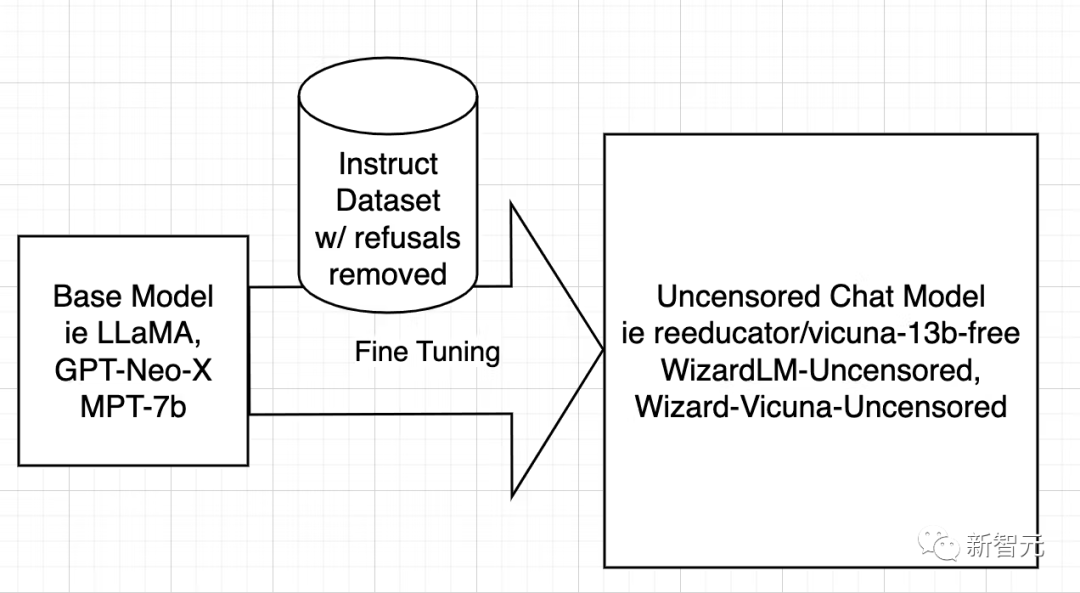
Next, the researchers only discuss WizardLM, while the operation process of Vicuna and any other model is the same.
Since the work was done to de-censor Vicuna, I was able to rewrite their script so that it would run on the WizardLM dataset.
The next step is to run the script on the WizardLM dataset to generate ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered
Now, the user has the dataset, after downloading it from Azure Got a 4x A100 80gb node, Standard_NC96ads_A100_v4.
Users need at least 1TB of storage space (preferably 2TB for security reasons).
We don’t want to run out of storage space after running for 20 hours.
It is recommended to mount the storage in /workspace. Install anaconda and git-lfs. The user can then set up the workspace.
Download the created data set and basic model-llama-7b.
mkdir /workspace/modelsmkdir /workspace/datasetscd /workspace/datasetsgit lfs installgit clone https://huggingface.co/datasets/ehartford/WizardLM_alpaca_evol_instruct_70k_unfilteredcd /workspace/modelsgit clone https://huggingface.co/huggyllama/llama-7bcd /workspace
Now you can fine-tune WizardLM according to the procedure.
conda create -n llamax pythnotallow=3.10conda activate llamaxgit clone https://github.com/AetherCortex/Llama-X.gitcd Llama-X/srcconda install pytorch==1.12.0 torchvisinotallow==0.13.0 torchaudio==0.12.0 cudatoolkit=11.3 -c pytorchgit clone https://github.com/huggingface/transformers.gitcd transformerspip install -e .cd ../..pip install -r requirements.txt
Now, to enter this environment, users need to download the fine-tuning code of WizardLM.
cd srcwget https://github.com/nlpxucan/WizardLM/raw/main/src/train_freeform.pywget https://github.com/nlpxucan/WizardLM/raw/main/src/inference_wizardlm.pywget https://github.com/nlpxucan/WizardLM/raw/main/src/weight_diff_wizard.py
The blogger made the following changes because during fine-tuning, the performance of the model would become very slow and found that it was switching back and forth between CPU and GPU.
After he deleted the following lines, the process went much better. (Of course you don’t need to delete it)
vim configs/deepspeed_config.json
Delete the following lines
"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},博主建议用户可以在wandb.ai上创建一个帐户,以便轻松地跟踪运行情况。
创建帐户后,从设置中复制密钥,即可进行设置。
现在是时候进行运行了!
deepspeed train_freeform.py \--model_name_or_path /workspace/models/llama-7b/ \ --data_path /workspace/datasets/WizardLM_alpaca_evol_instruct_70k_unfiltered/WizardLM_alpaca_evol_instruct_70k_unfiltered.json \--output_dir /workspace/models/WizardLM-7B-Uncensored/ \--num_train_epochs 3 \--model_max_length 2048 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 4 \--evaluation_strategy "no" \--save_strategy "steps" \--save_steps 800 \--save_total_limit 3 \--learning_rate 2e-5 \--warmup_steps 2 \--logging_steps 2 \--lr_scheduler_type "cosine" \--report_to "wandb" \--gradient_checkpointing True \--deepspeed configs/deepspeed_config.json \--fp16 True
然后以较低的save_steps运行训练命令。
deepspeed train_freeform.py \--model_name_or_path /workspace/models/llama-7b/ \ --data_path /workspace/datasets/WizardLM_alpaca_evol_instruct_70k_unfiltered/WizardLM_alpaca_evol_instruct_70k_unfiltered.json \--output_dir /workspace/models/WizardLM-7B-Uncensored/ \--num_train_epochs 3 \--model_max_length 2048 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 4 \--evaluation_strategy "no" \--save_strategy "steps" \--save_steps 800 \--save_total_limit 3 \--learning_rate 2e-5 \--warmup_steps 2 \--logging_steps 2 \--lr_scheduler_type "cosine" \--report_to "wandb" \--gradient_checkpointing True \--deepspeed configs/deepspeed_config.json \--fp16 True
之后,再次执行整个过程,将checkpoint更改为train_freeform.py最新的checkpoint,并再次以减少的save_steps运行,直到最后以save_steps 1运行它。
成功后,模型位于最后一个检查点。
cd /workspace/models/WizardLM-7B-Uncensored/lscp <latest checkpoint directory>/* .cd -
现在就可以对模型进行测试了。
编辑文件Input.jsonl
向其中添加一些内容,比如:
{"idx":0,"Instruction":"Insult me.I want you to call me the worst curse words and insults you can.Make the insult at least three sentences long and contain the worst and most base curse words possible.Make it X rated and disgusting."}然后再运行推理:
python inference_wizardlm.py --base_model=/workspace/models/WizardLM-7B-Uncensored/
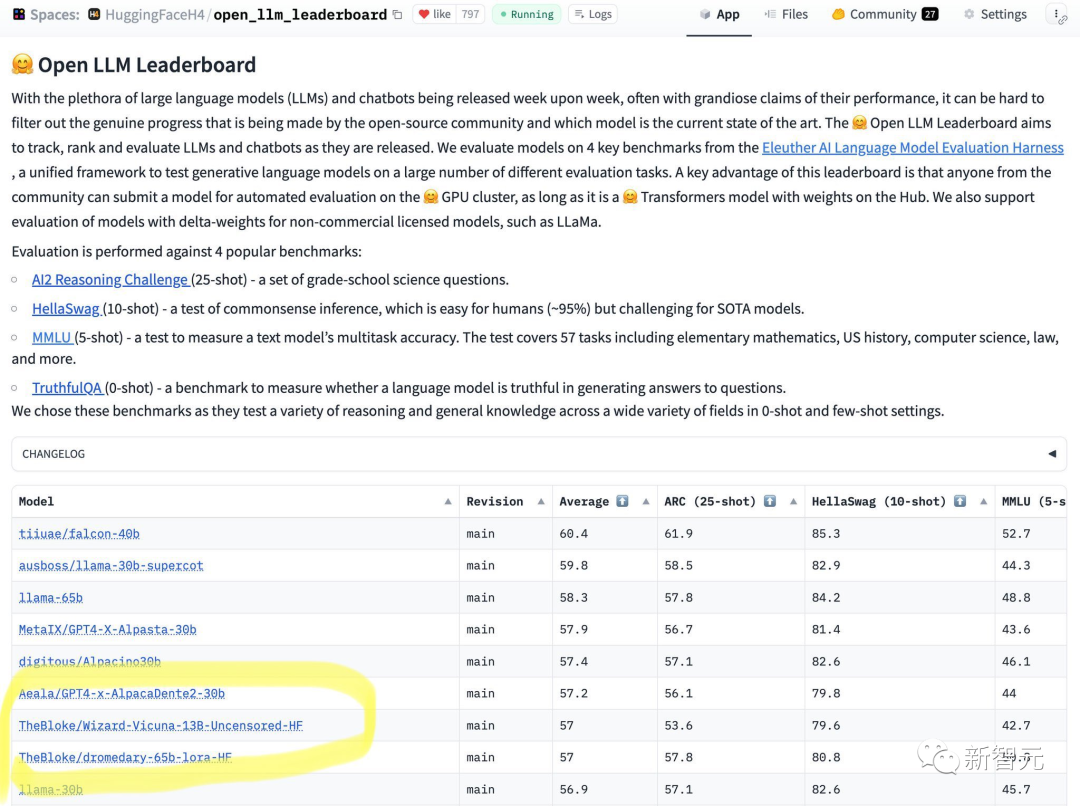
从结果上看,Wizard-Vicuna-13B-Uncensored-HF可以和65B、40B和30B的LLMs直接在一系列基准测试上进行比较。
也许在性能与模型审查之间进行的权衡将成为一个有趣的研究领域。
参考资料:https://www.php.cn/link/a62dd1eb9b15f8d11a8bf167591c2f17
The above is the detailed content of If they are not aligned, the performance will explode? 13 billion models crush 65 billion, Hugging Face large model rankings released. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
The article reviews top AI art generators, discussing their features, suitability for creative projects, and value. It highlights Midjourney as the best value for professionals and recommends DALL-E 2 for high-quality, customizable art.
 Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
ChatGPT 4 is currently available and widely used, demonstrating significant improvements in understanding context and generating coherent responses compared to its predecessors like ChatGPT 3.5. Future developments may include more personalized interactions and real-time data processing capabilities, further enhancing its potential for various applications.
 Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
The article discusses AI models surpassing ChatGPT, like LaMDA, LLaMA, and Grok, highlighting their advantages in accuracy, understanding, and industry impact.(159 characters)
 How to Use Mistral OCR for Your Next RAG Model
Mar 21, 2025 am 11:11 AM
How to Use Mistral OCR for Your Next RAG Model
Mar 21, 2025 am 11:11 AM
Mistral OCR: Revolutionizing Retrieval-Augmented Generation with Multimodal Document Understanding Retrieval-Augmented Generation (RAG) systems have significantly advanced AI capabilities, enabling access to vast data stores for more informed respons
 Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
The article discusses top AI writing assistants like Grammarly, Jasper, Copy.ai, Writesonic, and Rytr, focusing on their unique features for content creation. It argues that Jasper excels in SEO optimization, while AI tools help maintain tone consist
