
 Operation and Maintenance
Safety
An article on how to optimize the performance of LLM using local knowledge base
Operation and Maintenance
Safety
An article on how to optimize the performance of LLM using local knowledge base
An article on how to optimize the performance of LLM using local knowledge base

Yesterday, a 220-hour fine-tuning training was completed. The main task was to fine-tune a dialogue model on CHATGLM-6B that can more accurately diagnose database error information.
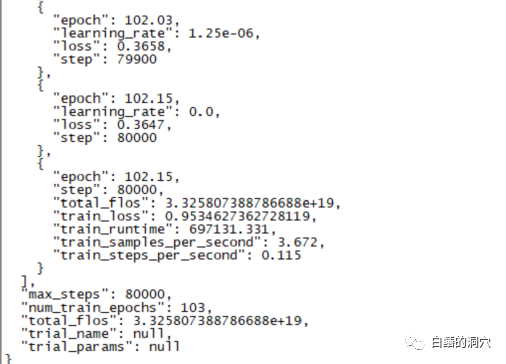
However, the final result of this training that I waited for nearly ten days was disappointing. Compared to the previous training I did with smaller sample coverage, the difference is still quite big.
This result is still a bit disappointing. This model is basically not practical. of value. It seems that the parameters and training set need to be readjusted and the training is performed again. The training of large language models is an arms race, and it is impossible to play without good equipment. It seems that we must also upgrade the laboratory equipment, otherwise there will be few ten days to waste.
Judging from the recent failed fine-tuning training, fine-tuning training is not easy to complete. Different task objectives are mixed together for training. Different task objectives may require different training parameters, making the final training set unable to meet the needs of certain tasks. Therefore, PTUNING is only suitable for a very certain task, and is not necessarily suitable for mixed tasks. Models aimed at mixed tasks may need to use FINETUNE. This is similar to what everyone said when I was communicating with a friend a few days ago.
In fact, because it is difficult to train the model, some people have given up training the model by themselves, and instead vectorize the local knowledge base for more accurate retrieval, and then use AUTOPROMPT to retrieve it The final result generates an automatic prompt to ask the speech model. This goal is easily achieved using langchain.
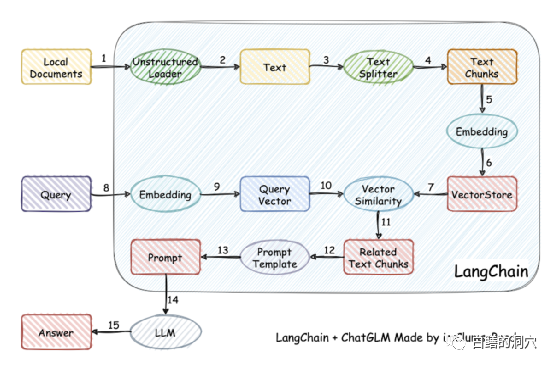
The working principle is to load the local document as text through the loader, and then The text is divided into stroke text fragments, and after encoding, they are written into vector storage and used for query. After the query results come out, prompts for asking questions are automatically formed through the Prompt Template to ask LLM, and LLM generates the final answer.
There is another important point in this work. One is to more accurately search for knowledge in the local knowledge base. This is achieved by vector storage in the search. Currently, it is targeted at Chinese and English local knowledge bases. There are many solutions for vectorization and search of knowledge bases. You can choose a solution that is more friendly to your knowledge base.
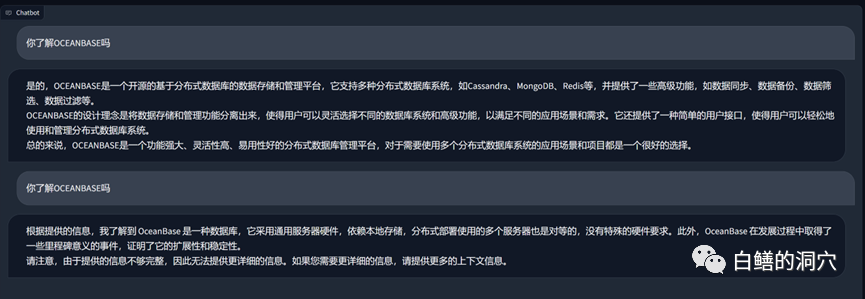
The above is a knowledge base about OB passed on vicuna-13b In the Q&A, the above is the answer using the LLM capability without using the local knowledge base. The following is the answer after loading the local knowledge base. It can be seen that the performance improvement is quite obvious.
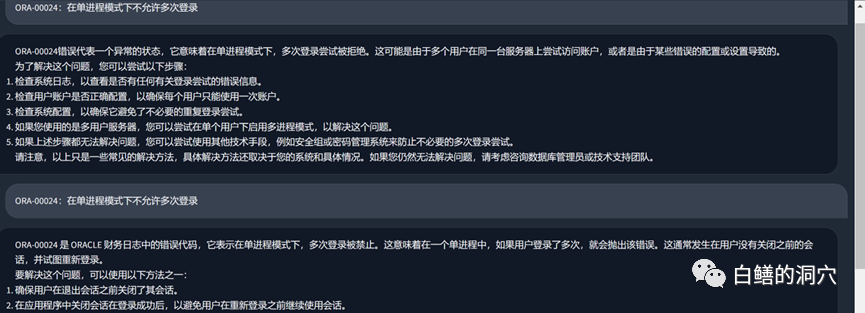
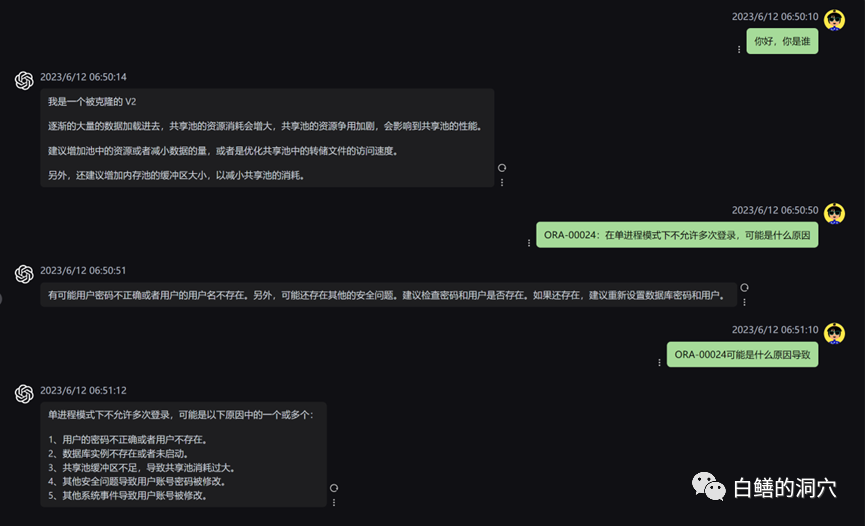
Let’s take a look at the ORA error problem just now. Before using the local knowledge base, LLM was basically It's nonsense, but after loading the local knowledge base, this answer is still satisfactory. The typos in the article are also errors in our knowledge base. In fact, the training set used by PTUNING is also generated through this local knowledge base.
We can gain some experience from the pitfalls we have stepped on recently. First of all, the difficulty of ptuning is much higher than we thought. Although ptuning requires lower equipment than finetune, the training difficulty is not low at all. Secondly, it is good to use local knowledge base through Langchain and autoprompt to improve LLM capabilities. For most enterprise applications, as long as the local knowledge base is sorted out and a suitable vectorization solution is selected, you should be able to get results that are no worse than PTUNING/FINETUNE. Effect. Third, and again as mentioned last time, the ability of LLM is crucial. A powerful LLM must be selected as the basic model to use. Any embedded model can only partially improve capabilities and cannot play a decisive role. Fourth, for database-related knowledge, vicuna-13b has really good abilities.
I have to go to the client to communicate early this morning. Time is limited in the morning, so I will just write a few sentences. If you have any thoughts on this, please leave a message for discussion (the discussion is only visible to you and me). I am also walking alone on this road. I hope there are fellow travelers who can give me some advice.
The above is the detailed content of An article on how to optimize the performance of LLM using local knowledge base. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Performance comparison of different Java frameworks
Jun 05, 2024 pm 07:14 PM
Performance comparison of different Java frameworks
Jun 05, 2024 pm 07:14 PM
Performance comparison of different Java frameworks: REST API request processing: Vert.x is the best, with a request rate of 2 times SpringBoot and 3 times Dropwizard. Database query: SpringBoot's HibernateORM is better than Vert.x and Dropwizard's ORM. Caching operations: Vert.x's Hazelcast client is superior to SpringBoot and Dropwizard's caching mechanisms. Suitable framework: Choose according to application requirements. Vert.x is suitable for high-performance web services, SpringBoot is suitable for data-intensive applications, and Dropwizard is suitable for microservice architecture.
 PHP array key value flipping: Comparative performance analysis of different methods
May 03, 2024 pm 09:03 PM
PHP array key value flipping: Comparative performance analysis of different methods
May 03, 2024 pm 09:03 PM
The performance comparison of PHP array key value flipping methods shows that the array_flip() function performs better than the for loop in large arrays (more than 1 million elements) and takes less time. The for loop method of manually flipping key values takes a relatively long time.
 C++ program optimization: time complexity reduction techniques
Jun 01, 2024 am 11:19 AM
C++ program optimization: time complexity reduction techniques
Jun 01, 2024 am 11:19 AM
Time complexity measures the execution time of an algorithm relative to the size of the input. Tips for reducing the time complexity of C++ programs include: choosing appropriate containers (such as vector, list) to optimize data storage and management. Utilize efficient algorithms such as quick sort to reduce computation time. Eliminate multiple operations to reduce double counting. Use conditional branches to avoid unnecessary calculations. Optimize linear search by using faster algorithms such as binary search.
 How to optimize the performance of multi-threaded programs in C++?
Jun 05, 2024 pm 02:04 PM
How to optimize the performance of multi-threaded programs in C++?
Jun 05, 2024 pm 02:04 PM
Effective techniques for optimizing C++ multi-threaded performance include limiting the number of threads to avoid resource contention. Use lightweight mutex locks to reduce contention. Optimize the scope of the lock and minimize the waiting time. Use lock-free data structures to improve concurrency. Avoid busy waiting and notify threads of resource availability through events.
 How to use benchmarks to evaluate the performance of Java functions?
Apr 19, 2024 pm 10:18 PM
How to use benchmarks to evaluate the performance of Java functions?
Apr 19, 2024 pm 10:18 PM
A way to benchmark the performance of Java functions is to use the Java Microbenchmark Suite (JMH). Specific steps include: Adding JMH dependencies to the project. Create a new Java class and annotate it with @State to represent the benchmark method. Write the benchmark method in the class and annotate it with @Benchmark. Run the benchmark using the JMH command line tool.
 What is the performance impact of converting PHP arrays to objects?
Apr 30, 2024 am 08:39 AM
What is the performance impact of converting PHP arrays to objects?
Apr 30, 2024 am 08:39 AM
In PHP, the conversion of arrays to objects will have an impact on performance, mainly affected by factors such as array size, complexity, object class, etc. To optimize performance, consider using custom iterators, avoiding unnecessary conversions, batch converting arrays, and other techniques.
 Performance comparison of C++ with other languages
Jun 01, 2024 pm 10:04 PM
Performance comparison of C++ with other languages
Jun 01, 2024 pm 10:04 PM
When developing high-performance applications, C++ outperforms other languages, especially in micro-benchmarks. In macro benchmarks, the convenience and optimization mechanisms of other languages such as Java and C# may perform better. In practical cases, C++ performs well in image processing, numerical calculations and game development, and its direct control of memory management and hardware access brings obvious performance advantages.
 What are some ways to resolve inefficiencies in PHP functions?
May 02, 2024 pm 01:48 PM
What are some ways to resolve inefficiencies in PHP functions?
May 02, 2024 pm 01:48 PM
Five ways to optimize PHP function efficiency: avoid unnecessary copying of variables. Use references to avoid variable copying. Avoid repeated function calls. Inline simple functions. Optimizing loops using arrays.
