
 Technology peripherals
AI
The 'track everything' video algorithm that tracks every pixel anytime, anywhere, and is not even afraid of obstructions is here.
Technology peripherals
AI
The 'track everything' video algorithm that tracks every pixel anytime, anywhere, and is not even afraid of obstructions is here.
The 'track everything' video algorithm that tracks every pixel anytime, anywhere, and is not even afraid of obstructions is here.

Some time ago, Meta released the "Segment Everything (SAM)" AI model, which can generate masks for any object in any image or video, causing researchers in the field of computer vision (CV) to exclaim: "CV does not exist ". After that, there was a wave of "secondary creation" in the field of CV. Some work successively combined functions such as target detection and image generation on the basis of segmentation, but most of the research was based on static images.
Now, a new study called "Tracking Everything" proposes a new method for motion estimation in dynamic videos that can accurately and completely track the movement of objects.

##The research was led by researchers from Cornell University, Google Research and UC Berkeley researchers worked together. They jointly proposed OmniMotion, a complete and globally consistent motion representation, and proposed a new test-time optimization method to perform accurate and complete motion estimation for every pixel in the video.

- ##Paper address: https://arxiv.org/abs/2306.05422
- Project homepage: https://omnimotion.github.io/



 ##You can track the motion trajectory even if the object is blocked. For example, a dog is blocked by a tree while running:
##You can track the motion trajectory even if the object is blocked. For example, a dog is blocked by a tree while running:
#In the field of computer vision, there are two commonly used motion estimation methods: sparse feature tracking and dense optical flow. However, both methods have their own shortcomings. Sparse feature tracking cannot model the motion of all pixels; dense optical flow cannot capture motion trajectories for a long time. 
The OmniMotion proposed in this research uses a quasi-3D canonical volume to characterize the video and tracks each pixel through a bijection between local space and canonical space. This representation enables global consistency, enables motion tracking even when objects are occluded, and models any combination of camera and object motion. This study experimentally demonstrates that the proposed method significantly outperforms existing SOTA methods.
Method Overview
This study takes as input a collection of frames with paired noisy motion estimates (e.g., optical flow fields) to form a complete, globally consistent motion representation of the entire video. The study then added an optimization process that allowed it to query the representation with any pixel in any frame to produce smooth, accurate motion trajectories throughout the video. Notably, this method can identify when points in the frame are occluded and can even track points through occlusions.
OmniMotion characterization
Traditional motion estimation methods (such as pairwise optical flow), when objects are occluded Tracking of objects will be lost. In order to provide accurate and consistent motion trajectories even under occlusion, this study proposes global motion representation OmniMotion.
This research attempts to accurately track real-world motion without explicit dynamic 3D reconstruction. The OmniMotion representation represents the scene in the video as a canonical 3D volume, which is mapped to a local volume in each frame through a local-canonical bijection. Local canonical bijections are parameterized as neural networks and capture camera and scene motion without separating the two. Based on this approach, the video can be viewed as the rendering result from the local volume of a fixed static camera.
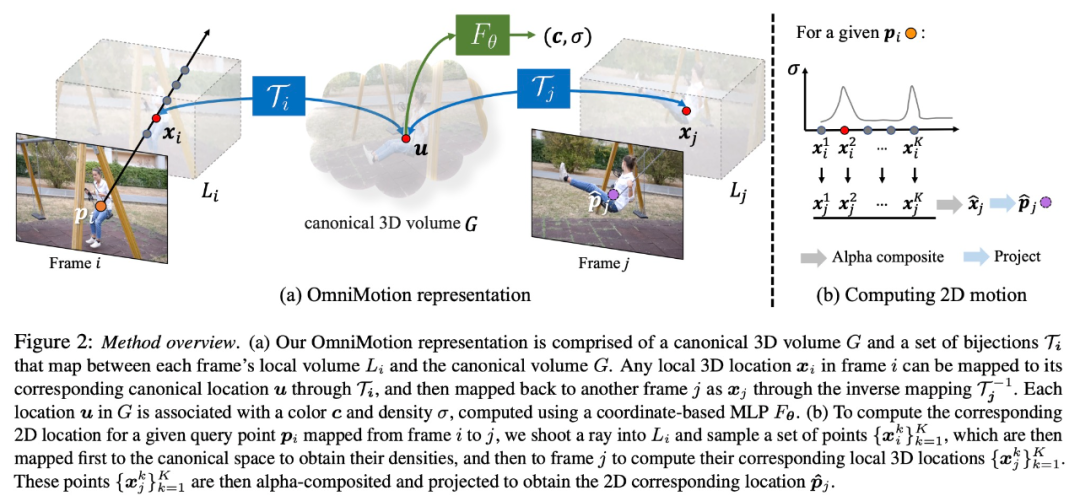
Because OmniMotion does not clearly distinguish between camera and scene motion, the representation formed is not a physically accurate 3D scene reconstruction. Therefore, the study calls it quasi-3D characterization.
OmniMotion retains information about all scene points projected to each pixel, as well as their relative depth order, which allows points in the frame to be moved even if they are temporarily occluded track.

Experiments and results
Quantitative comparison
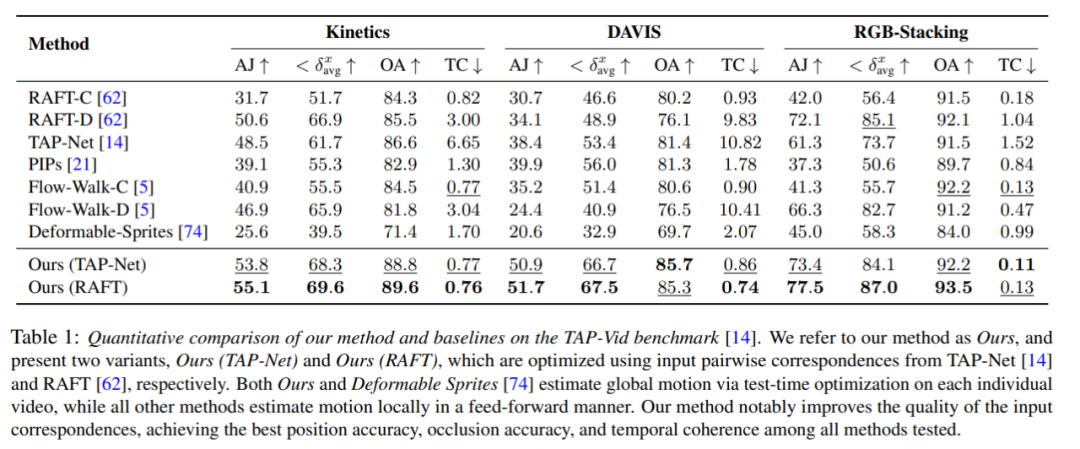
The researchers compared the proposed method with the TAP-Vid benchmark, and the results are shown in Table 1. It can be seen that on different datasets, their method always achieves the best position accuracy, occlusion accuracy and timing consistency. Their method handles well the different pairwise correspondence inputs from RAFT and TAP-Net and provides consistent improvements over both baseline methods.
Qualitative comparison
As shown in Figure 3, the researcher Their method is qualitatively compared with baseline methods. The new method shows excellent recognition and tracking capabilities during (long) occlusion events, while providing reasonable positions for points during occlusions and handling large camera motion parallax.

##Ablation experiment and analysis
Research Researchers used ablation experiments to verify the effectiveness of their design decisions, and the results are shown in Table 2.
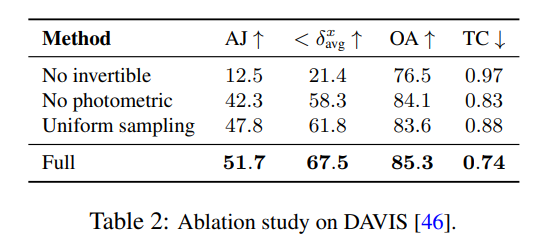
In Figure 4, they show pseudo-depth maps generated by their model to demonstrate the learned Depth sorting.

It should be noted that these figures do not correspond to physical depth, however, they demonstrate that the new method can effectively determine the relative order between different surfaces when using only photometric and optical flow signals, which is useful for Tracking in occlusion is critical. More ablation experiments and analytical results can be found in the supplementary material.
The above is the detailed content of The 'track everything' video algorithm that tracks every pixel anytime, anywhere, and is not even afraid of obstructions is here.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Where are video files stored in browser cache?
Feb 19, 2024 pm 05:09 PM
Where are video files stored in browser cache?
Feb 19, 2024 pm 05:09 PM
Which folder does the browser cache the video in? When we use the Internet browser every day, we often watch various online videos, such as watching music videos on YouTube or watching movies on Netflix. These videos will be cached by the browser during the loading process so that they can be loaded quickly when played again in the future. So the question is, in which folder are these cached videos actually stored? Different browsers store cached video folders in different locations. Below we will introduce several common browsers and their
 Is it infringing to post other people's videos on Douyin? How does it edit videos without infringement?
Mar 21, 2024 pm 05:57 PM
Is it infringing to post other people's videos on Douyin? How does it edit videos without infringement?
Mar 21, 2024 pm 05:57 PM
With the rise of short video platforms, Douyin has become an indispensable part of everyone's daily life. On TikTok, we can see interesting videos from all over the world. Some people like to post other people’s videos, which raises a question: Is Douyin infringing upon posting other people’s videos? This article will discuss this issue and tell you how to edit videos without infringement and how to avoid infringement issues. 1. Is it infringing upon Douyin’s posting of other people’s videos? According to the provisions of my country's Copyright Law, unauthorized use of the copyright owner's works without the permission of the copyright owner is an infringement. Therefore, posting other people’s videos on Douyin without the permission of the original author or copyright owner is an infringement. 2. How to edit a video without infringement? 1. Use of public domain or licensed content: Public
 How to remove video watermark in Wink
Feb 23, 2024 pm 07:22 PM
How to remove video watermark in Wink
Feb 23, 2024 pm 07:22 PM
How to remove watermarks from videos in Wink? There is a tool to remove watermarks from videos in winkAPP, but most friends don’t know how to remove watermarks from videos in wink. Next is the picture of how to remove watermarks from videos in Wink brought by the editor. Text tutorial, interested users come and take a look! How to remove video watermarks in Wink 1. First open wink APP and select the [Remove Watermark] function in the homepage area; 2. Then select the video you want to remove the watermark in the album; 3. Then select the video and click the upper right corner after editing the video. [√]; 4. Finally, click [One-click Print] as shown in the figure below and then click [Process].
 How to make money from posting videos on Douyin? How can a newbie make money on Douyin?
Mar 21, 2024 pm 08:17 PM
How to make money from posting videos on Douyin? How can a newbie make money on Douyin?
Mar 21, 2024 pm 08:17 PM
Douyin, the national short video platform, not only allows us to enjoy a variety of interesting and novel short videos in our free time, but also gives us a stage to show ourselves and realize our values. So, how to make money by posting videos on Douyin? This article will answer this question in detail and help you make more money on TikTok. 1. How to make money from posting videos on Douyin? After posting a video and gaining a certain amount of views on Douyin, you will have the opportunity to participate in the advertising sharing plan. This income method is one of the most familiar to Douyin users and is also the main source of income for many creators. Douyin decides whether to provide advertising sharing opportunities based on various factors such as account weight, video content, and audience feedback. The TikTok platform allows viewers to support their favorite creators by sending gifts,
 How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
1. First open Weibo on your mobile phone and click [Me] in the lower right corner (as shown in the picture). 2. Then click [Gear] in the upper right corner to open settings (as shown in the picture). 3. Then find and open [General Settings] (as shown in the picture). 4. Then enter the [Video Follow] option (as shown in the picture). 5. Then open the [Video Upload Resolution] setting (as shown in the picture). 6. Finally, select [Original Image Quality] to avoid compression (as shown in the picture).
 2 Ways to Remove Slow Motion from Videos on iPhone
Mar 04, 2024 am 10:46 AM
2 Ways to Remove Slow Motion from Videos on iPhone
Mar 04, 2024 am 10:46 AM
On iOS devices, the Camera app allows you to shoot slow-motion video, or even 240 frames per second if you have the latest iPhone. This capability allows you to capture high-speed action in rich detail. But sometimes, you may want to play slow-motion videos at normal speed so you can better appreciate the details and action in the video. In this article, we will explain all the methods to remove slow motion from existing videos on iPhone. How to Remove Slow Motion from Videos on iPhone [2 Methods] You can use Photos App or iMovie App to remove slow motion from videos on your device. Method 1: Open on iPhone using Photos app
 How to publish Xiaohongshu video works? What should I pay attention to when posting videos?
Mar 23, 2024 pm 08:50 PM
How to publish Xiaohongshu video works? What should I pay attention to when posting videos?
Mar 23, 2024 pm 08:50 PM
With the rise of short video platforms, Xiaohongshu has become a platform for many people to share their lives, express themselves, and gain traffic. On this platform, publishing video works is a very popular way of interaction. So, how to publish Xiaohongshu video works? 1. How to publish Xiaohongshu video works? First, make sure you have a video content ready to share. You can use your mobile phone or other camera equipment to shoot, but you need to pay attention to the image quality and sound clarity. 2. Edit the video: In order to make the work more attractive, you can edit the video. You can use professional video editing software, such as Douyin, Kuaishou, etc., to add filters, music, subtitles and other elements. 3. Choose a cover: The cover is the key to attracting users to click. Choose a clear and interesting picture as the cover to attract users to click on it.
 How to convert videos downloaded by uc browser into local videos
Feb 29, 2024 pm 10:19 PM
How to convert videos downloaded by uc browser into local videos
Feb 29, 2024 pm 10:19 PM
How to turn videos downloaded by UC browser into local videos? Many mobile phone users like to use UC Browser. They can not only browse the web, but also watch various videos and TV programs online, and download their favorite videos to their mobile phones. Actually, we can convert downloaded videos to local videos, but many people don't know how to do it. Therefore, the editor specially brings you a method to convert the videos cached by UC browser into local videos. I hope it can help you. Method to convert uc browser cached videos to local videos 1. Open uc browser and click the "Menu" option. 2. Click "Download/Video". 3. Click "Cached Video". 4. Long press any video, when the options pop up, click "Open Directory". 5. Check the ones you want to download
