
 Technology peripherals
AI
2.8 million multimodal command-response pairs, common in eight languages, the first command data set covering video content MIMIC-IT is here
Technology peripherals
AI
2.8 million multimodal command-response pairs, common in eight languages, the first command data set covering video content MIMIC-IT is here
2.8 million multimodal command-response pairs, common in eight languages, the first command data set covering video content MIMIC-IT is here

In recent times, AI dialogue assistants have made considerable progress in language tasks. This significant improvement is not only based on the strong generalization ability of LLM, but also should be attributed to instruction tuning. This involves fine-tuning the LLM on a range of tasks through diverse and high-quality instruction.
One potential reason for achieving zero-shot performance with instruction tuning is that it internalizes context. This is important especially when user input skips common sense context. By incorporating instruction tuning, LLM gains a high level of understanding of user intent and exhibits better zero-shot capabilities even in previously unseen tasks.
However, an ideal AI conversational assistant should be able to solve tasks involving multiple modalities. This requires obtaining a diverse and high-quality multimodal instruction following dataset. For example, the LLaVAInstruct-150K dataset (also known as LLaVA) is a commonly used visual-verbal instruction following dataset, which uses COCO images, instructions and responses based on image captions and target bounding boxes obtained from GPT-4 Constructed. However, LLaVA-Instruct-150K has three limitations: limited visual diversity; using pictures as single visual data; and contextual information only containing language morphology.
In order to promote AI dialogue assistants to break through these limitations, scholars from Nanyang Technological University in Singapore and Microsoft Research Institute in Redmond proposed the multi-modal contextual instruction tuning data set MIMIC-IT , a dataset containing 2.8 million multimodal context instruction-response pairs, covering a variety of real-life scenarios.

Paper address: https://arxiv.org/pdf/2306.05425.pdf
In addition, in order to efficiently generate instruction-response pairs, the researchers also introduced "Sythus", an automated pipeline of instruction-response annotations inspired by the self-instruct method. Sythus uses system information, visual annotations, and examples in context to guide a language model (GPT-4 or ChatGPT) to generate command-response pairs based on visual context, targeting the three fundamental capabilities of visual language models: perception, reasoning, and planning. Additionally, English commands and responses are translated into seven languages to support multilingual use.
It is particularly noteworthy that the researchers trained the multi-modal model "Otter" based on OpenFlamingo on MIMIC-IT. Evaluated on both ChatGPT and humans, Otter's multimodal capabilities surpass other recent visual-language models.
In a series of demos, researchers demonstrated Otter's multi-modal question and answer capabilities:
Q: Which card will be played next? ?
A: Eight tubes. This way you can keep fours and fives waiting for a straight.

Q: I want to land, what should I do?
A: Press the lower left button once to turn left, and pull the handbrake on the right when you want to land.

Q: What next?
A: Pass the ball to the center, run to the goal, and look for scoring opportunities.

Next, let’s look at the study details.
MIMIC-IT Dataset
The MIMIC-IT dataset includes 2.8 million multimodal instruction-response pairs, covering basic capabilities: perception, reasoning, and planning. Each instruction is accompanied by a multimodal conversational context, enabling VLM trained on MIMIC-IT to demonstrate good proficiency in interactive instructions and perform zero-shot generalization.
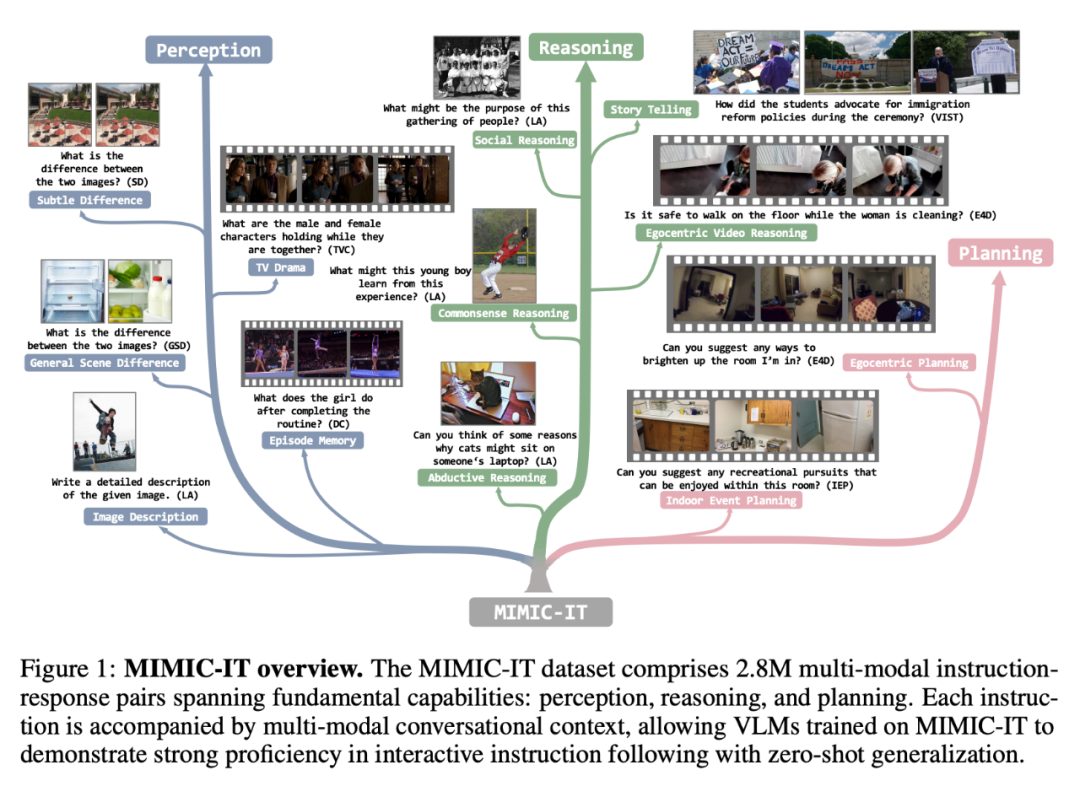
## Compared with LLaVA, the features of MIMIC-IT include:
(1) Diverse visual scenes, including images and videos from different data sets such as general scenes, egocentric perspective scenes and indoor RGB-D images;
(2) More An image (or a video) as visual data;
(3) Multi-modal context information, including multiple command-response pairs and multiple images or videos;
(4) Supports eight languages, including English, Chinese, Spanish, Japanese, French, German, Korean and Arabic.
The following figure further shows the command-response comparison of the two (the yellow box is LLaVA):

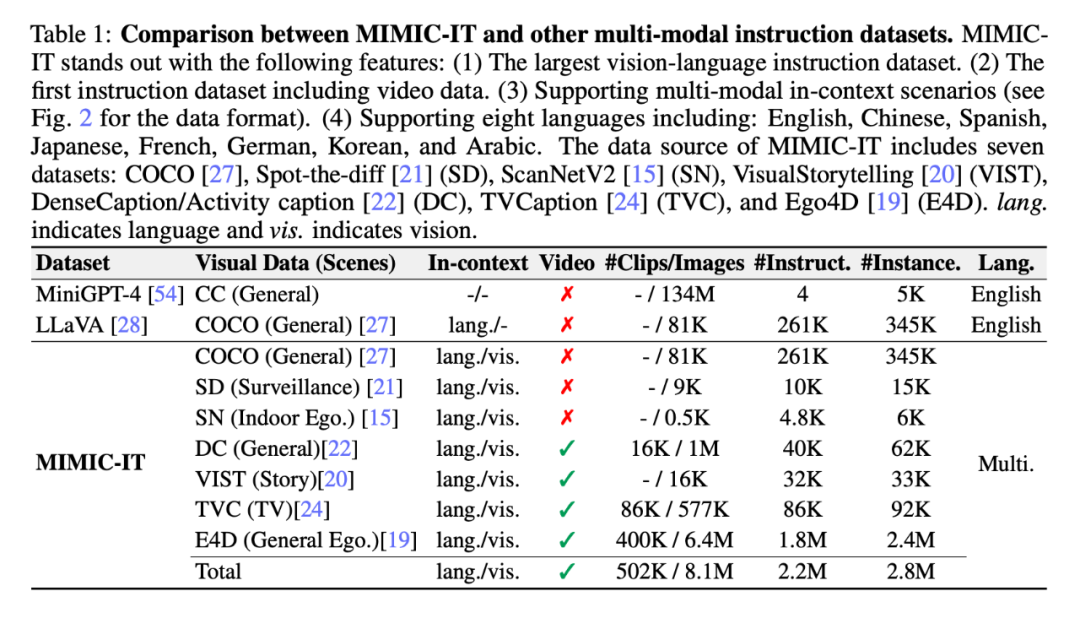
As shown in Table 1, the data sources of MIMIC-IT come from seven data sets: COCO, Spot-the-diff (SD), ScanNetV2 (SN), VisualStorytelling (VIST), DenseCaption /Activity caption (DC), TVCaption (TVC) and Ego4D (E4D). "lang." in the "Context" column represents language, and "vis." represents vision.
 Sythus: Automated command-response pair generation pipeline
Sythus: Automated command-response pair generation pipeline
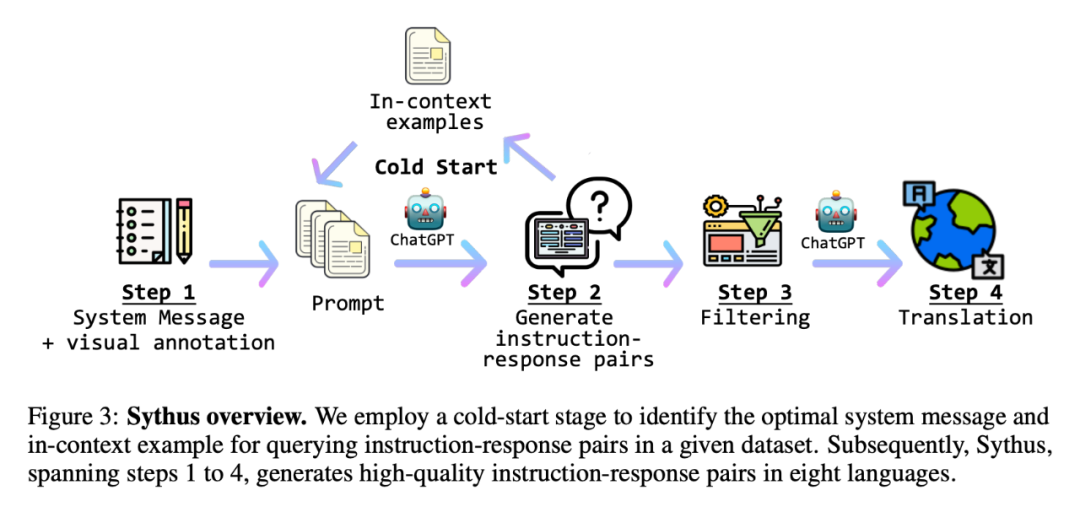
At the same time, the researcher proposed Sythus (Figure 3), which is An automated pipeline for generating high-quality command-response pairs in multiple languages. Based on the framework proposed by LLaVA, researchers used ChatGPT to generate command-response pairs based on visual content. To ensure the quality of the generated command-response pairs, the pipeline uses system information, visual annotations, and samples in context as prompts for ChatGPT. System information defines the expected tone and style of the generated command-response pairs, while visual annotations provide basic image information such as bounding boxes and image descriptions. Examples in context help ChatGPT learn in context.
Since the quality of the core set will affect the subsequent data collection process, the researchers adopted a cold start strategy to strengthen the samples in context before large-scale querying. During the cold start phase, a heuristic approach is adopted to prompt ChatGPT to collect samples in context only through system information and visual annotations. This phase ends only after the samples in a satisfactory context have been identified. In the fourth step, once the command-response pairs are obtained, the pipeline expands them into Chinese (zh), Japanese (ja), Spanish (es), German (de), French (fr), Korean (ko) and Arabic (ar). Further details can be found in Appendix C, and specific task prompts can be found in Appendix D.
The researchers then demonstrated various applications and the potential capabilities of visual language models (VLMs) trained on them. First, the researchers introduced Otter, a contextual instruction tuning model developed using the MIMIC-IT dataset. The researchers then explored various methods of training Otter on the MIMIC-IT dataset and discussed the many scenarios in which Otter can be used effectively.
Figure 5 is an example of Otter’s response in different scenarios. Thanks to training on the MIMIC-IT dataset, Otter is capable of serving situational understanding and reasoning, contextual sample learning, and egocentric visual assistants.

Finally, the researchers conducted a comparative analysis of the performance of Otter and other VLMs in a series of benchmark tests.
ChatGPT Evaluation
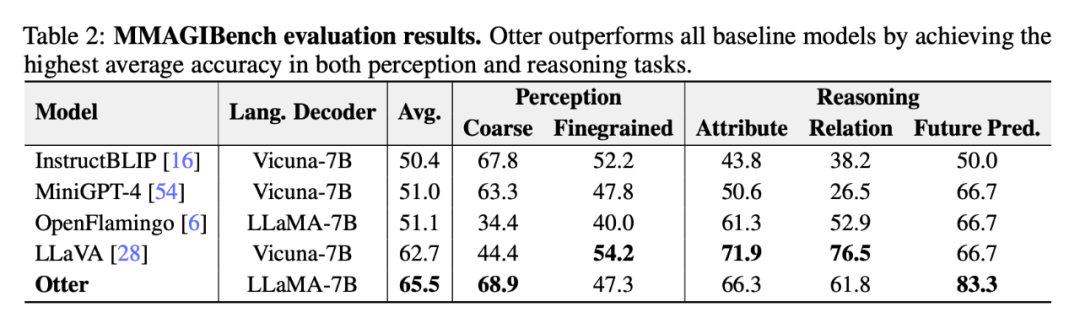
Table 2 below shows the researcher’s evaluation of the visual language model using the MMAGIBench framework [43] Perception and reasoning abilities are broadly assessed.
##Human Assessment
Multi-Modality Arena [32] uses the Elo rating system to evaluate the usefulness and consistency of VLM responses. Figure 6(b) shows that Otter demonstrates superior practicality and consistency, achieving the highest Elo rating in recent VLMs.
Few-shot contextual learning benchmark evaluation
Otter is fine-tuned based on OpenFlamingo, a multi-model An architecture designed for dynamic context learning. After fine-tuning using the MIMIC-IT dataset, Otter significantly outperforms OpenFlamingo on the COCO Captioning (CIDEr) [27] few-shot evaluation (see Figure 6 (c)). As expected, fine-tuning also brings marginal performance gains on zero-sample evaluation.

Figure 6: Evaluation of ChatGPT video understanding.
DiscussFlaws. Although researchers have iteratively improved system messages and command-response examples, ChatGPT is prone to language hallucinations, so it may generate erroneous responses. Often, more reliable language models require self-instruct data generation.
Future jobs. In the future, the researchers plan to support more specific AI datasets, such as LanguageTable and SayCan. Researchers are also considering using more trustworthy language models or generation techniques to improve the instruction set.
The above is the detailed content of 2.8 million multimodal command-response pairs, common in eight languages, the first command data set covering video content MIMIC-IT is here. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to get items using commands in Terraria? -How to collect items in Terraria?
Mar 19, 2024 am 08:13 AM
How to get items using commands in Terraria? -How to collect items in Terraria?
Mar 19, 2024 am 08:13 AM
How to get items using commands in Terraria? 1. What is the command to give items in Terraria? In the Terraria game, giving command to items is a very practical function. Through this command, players can directly obtain the items they need without having to fight monsters or teleport to a certain location. This can greatly save time, improve the efficiency of the game, and allow players to focus more on exploring and building the world. Overall, this feature makes the gaming experience smoother and more enjoyable. 2. How to use Terraria to give item commands 1. Open the game and enter the game interface. 2. Press the "Enter" key on the keyboard to open the chat window. 3. Enter the command format in the chat window: "/give[player name][item ID][item quantity]".
 Image classification with few-shot learning using PyTorch
Apr 09, 2023 am 10:51 AM
Image classification with few-shot learning using PyTorch
Apr 09, 2023 am 10:51 AM
In recent years, deep learning-based models have performed well in tasks such as object detection and image recognition. On challenging image classification datasets like ImageNet, which contains 1,000 different object classifications, some models now exceed human levels. But these models rely on a supervised training process, they are significantly affected by the availability of labeled training data, and the classes the models are able to detect are limited to the classes they were trained on. Since there are not enough labeled images for all classes during training, these models may be less useful in real-world settings. And we want the model to be able to recognize classes it has not seen during training, since it is almost impossible to train on images of all potential objects. We will learn from a few samples
 VUE3 quick start: using Vue.js instructions to switch tabs
Jun 15, 2023 pm 11:45 PM
VUE3 quick start: using Vue.js instructions to switch tabs
Jun 15, 2023 pm 11:45 PM
This article aims to help beginners quickly get started with Vue.js3 and achieve a simple tab switching effect. Vue.js is a popular JavaScript framework that can be used to build reusable components, easily manage the state of your application, and handle user interface interactions. Vue.js3 is the latest version of the framework. Compared with previous versions, it has undergone major changes, but the basic principles have not changed. In this article, we will use Vue.js instructions to implement the tab switching effect, with the purpose of making readers familiar with Vue.js
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Google AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance features
Feb 26, 2024 am 09:58 AM
Google AI video is awesome again! VideoPrism, an all-in-one universal visual encoder, refreshes 30 SOTA performance features
Feb 26, 2024 am 09:58 AM
After the AI video model Sora became popular, major companies such as Meta and Google have stepped aside to do research and catch up with OpenAI. Recently, researchers from the Google team proposed a universal video encoder - VideoPrism. It can handle various video understanding tasks through a single frozen model. Image paper address: https://arxiv.org/pdf/2402.13217.pdf For example, VideoPrism can classify and locate the person blowing candles in the video below. Image video-text retrieval, based on the text content, the corresponding content in the video can be retrieved. For another example, describe the video below - a little girl is playing with building blocks. QA questions and answers are also available.
 Implementing OpenAI CLIP on custom datasets
Sep 14, 2023 am 11:57 AM
Implementing OpenAI CLIP on custom datasets
Sep 14, 2023 am 11:57 AM
In January 2021, OpenAI announced two new models: DALL-E and CLIP. Both models are multimodal models that connect text and images in some way. The full name of CLIP is Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training), which is a pre-training method based on contrasting text-image pairs. Why introduce CLIP? Because the currently popular StableDiffusion is not a single model, but consists of multiple models. One of the key components is the text encoder, which is used to encode the user's text input, and this text encoder is the text encoder CL in the CLIP model
 How to split a dataset correctly? Summary of three common methods
Apr 08, 2023 pm 06:51 PM
How to split a dataset correctly? Summary of three common methods
Apr 08, 2023 pm 06:51 PM
Decomposing the dataset into a training set helps us understand the model, which is important for how the model generalizes to new unseen data. A model may not generalize well to new unseen data if it is overfitted. Therefore good predictions cannot be made. Having an appropriate validation strategy is the first step to successfully creating good predictions and using the business value of AI models. This article has compiled some common data splitting strategies. A simple train and test split divides the data set into training and validation parts, with 80% training and 20% validation. You can do this using Scikit's random sampling. First, the random seed needs to be fixed, otherwise the same data split cannot be compared and the results cannot be reproduced during debugging. If the data set
 PyTorch parallel training DistributedDataParallel complete code example
Apr 10, 2023 pm 08:51 PM
PyTorch parallel training DistributedDataParallel complete code example
Apr 10, 2023 pm 08:51 PM
The problem of training large deep neural networks (DNN) using large datasets is a major challenge in the field of deep learning. As DNN and dataset sizes increase, so do the computational and memory requirements for training these models. This makes it difficult or even impossible to train these models on a single machine with limited computing resources. Some of the major challenges in training large DNNs using large datasets include: Long training time: The training process can take weeks or even months to complete, depending on the complexity of the model and the size of the dataset. Memory limitations: Large DNNs may require large amounts of memory to store all model parameters, gradients, and intermediate activations during training. This can cause out of memory errors and limit what can be trained on a single machine.
