
 Technology peripherals
AI
Meta open source text generates a large music model. We tried it with the lyrics of 'Qilixiang'
Technology peripherals
AI
Meta open source text generates a large music model. We tried it with the lyrics of 'Qilixiang'
Meta open source text generates a large music model. We tried it with the lyrics of 'Qilixiang'

Before entering the text, let’s listen to two pieces of music generated by MusicGen. We enter the text description "a man walks in the rain, come accross a beautiful girl, and they dance happily"
and then try to enter the first two sentences from the lyrics of Jay Chou's "Qili Xiang" "Out the window" The sparrows are talkative on the telephone poles. What you said makes it feel like summer." (Chinese supported)
Trial address: https://huggingface.co/spaces /facebook/MusicGen
Text-to-music refers to the task of generating musical works given a text description, such as "90s guitar riff rock song." Generating music involves modeling long sequences as a challenging task. Unlike speech, music requires the use of the full spectrum, which means the signal is sampled at a higher rate, i.e. the standard sampling rate for music recordings is 44.1 kHz or 48 kHz, while speech is sampled at 16 kHz.
In addition, music contains the harmony and melody of different instruments, which gives the music a complex structure. But because human listeners are so sensitive to dissonance, they don’t have much tolerance for melodies in generated music. Of course, the ability to control the generation process in multiple ways is essential for music creators, such as keys, instruments, melodies, genres, etc.
Recent advances in self-supervised audio representation learning, sequence modeling, and audio synthesis provide the conditions for developing such models. To make audio modeling easier, recent research proposes to represent audio signals as a stream of discrete tokens that "represent the same signal." This enables high-quality audio generation and efficient audio modeling. However this requires joint modeling of several parallel dependency flows.
Kharitonov et al. [2022], Kreuk et al. [2022] proposed to use a delay method to model multiple streams of speech tokens in parallel, that is, introducing offsets between different streams. Agostinelli et al. [2023] proposed using multiple discrete token sequences of different granularities to represent musical fragments and modeling them using a hierarchy of autoregressive models. Meanwhile, Donahue et al. [2023] adopted a similar approach but targeted the task of singing to accompaniment generation. Recently, Wang et al. [2023] proposed to solve this problem in two stages: restrict modeling to the first token stream. A post-network is then applied to jointly model the remaining flows in a non-autoregressive manner.
In this article, Meta AI researchers propose MUSICGEN, a simple and controllable music generation model that can generate high-quality music given a text description. music.

##Paper address: https: //arxiv.org/pdf/2306.05284.pdf
The researchers proposed a general framework for modeling multiple parallel acoustic token streams as a generalization of previous research ( See Figure 1) below. In order to improve the controllability of generated samples, this paper also introduces unsupervised melody conditions, allowing the model to generate structurally matching music based on given harmony and melody. This paper performs an extensive evaluation of MUSICGEN, and the proposed method outperforms the evaluation baselines by a large margin: MUSICGEN receives a subjective score of 84.8 out of 100, compared to 80.5 for the best baseline. Additionally, this article provides an ablation study that illustrates the importance of each component to overall model performance.
Finally, human evaluation shows that MUSICGEN produces high-quality samples that both conform to the textual description and are also better melodically aligned with the given harmonic structure.
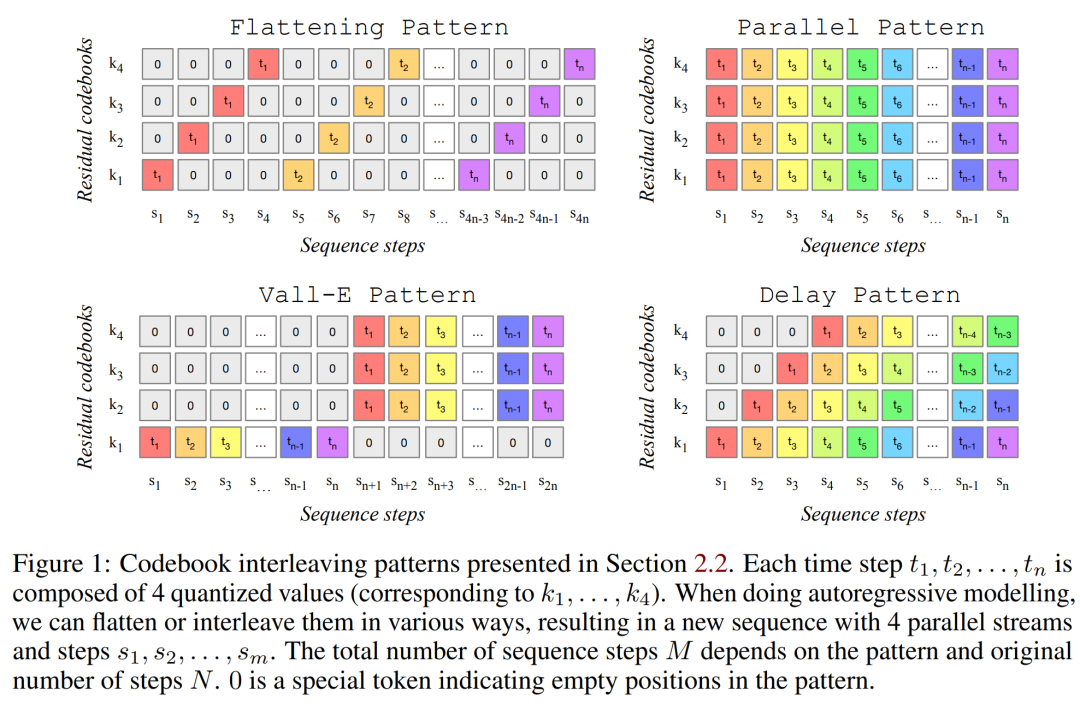
The main contributions of this article are as follows:
- Proposed a simple and efficient model: can produce high-quality music at 32khz. MUSICGEN can generate consistent music with a single-stage language model through an effective codebook interleaving strategy;
- proposes a single model for text and melody conditional generation, and the generated audio is consistent with The melodies provided are consistent and consistent with the textual condition information;
- An extensive objective and manual evaluation of key design choices of the proposed approach was performed.
Method Overview
MUSICGEN contains a decoder based on an autoregressive transformer and is conditioned on a text or melody representation. The (language) model is based on the quantization unit of the EnCodec audio tokenizer, which provides high-fidelity reconstruction from low-frame discrete representations. In addition, compression models deploying residual vector quantization (RVQ) will generate multiple parallel streams. In this setting, each stream consists of discrete tokens from different learned codebooks.
Previous work proposed some modeling strategies to solve this problem. The researchers proposed a novel modeling framework that can be generalized to various codebook interleaving modes. There are also several variations of this framework. Based on patterns, they can take advantage of the internal structure of quantized audio tokens. Finally MUSICGEN supports conditional generation based on text or melody.
Audio tokenization
The researchers used EnCodec, which is a convolutional autoencoder that uses RVQ quantified latent space and adversarial reconstruction losses. Given a reference audio random variable X ∈ R^d·f_s, where d represents the audio duration and f_s represents the sampling rate. EnCodec encodes this variable into a continuous tensor with frame rate f_r ≪ f_s, and then the representation is quantized as Q ∈ {1, . . . , N}^K×d・f_r, where K represents the codebook used in RVQ Quantity, N represents the codebook size.
Codebook interleaved mode
Exact flattened autoregressive decomposition. The autoregressive model requires a discrete random sequence U ∈ {1, . . . , N}^S and sequence length S. By convention, researchers will use U_0 = 0, which is a deterministic special token that represents the beginning of the sequence. They can then model the distribution.
Inexact autoregressive decomposition. Another possibility is to consider autoregressive decomposition, where some codebooks require parallel predictions. For example, define another sequence, V_0 = 0, and t∈ {1, . . . , N}, k ∈ {1, . . . , K}, V_t,k = Q_t,k. When codebook index k is removed (e.g. V_t), this represents the concatenation of all codebooks at time t.
Arbitrary codebook interleaving mode. To experiment with such decompositions and accurately measure the impact of using imprecise decompositions, the researchers introduced a codebook interleaving mode. First consider Ω = {(t, k) : {1, . . . , d・f_r}, k ∈ {1, . . . , K}}, which is the set of all time step and codebook index pairs. The codebook pattern is the sequence P=(P_0, P_1, P_2, . . . , P_S), where P_0 = ∅, and 0
Model conditionalization
Text conditionalization. Given a textual description that matches an input audio
Melody conditioning. While text is the dominant approach to conditional generative models today, a more natural approach to music is to condition on a melodic structure from another audio track or even whistling or humming. This approach also allows for iterative optimization of model outputs. To support this, we attempted to control melodic structure by jointly modulating the input chromatogram and text description. In initial experiments, they observed that conditioning on the original chromatogram often reconstructed the original sample, leading to overfitting. To this end, researchers select major time-frequency bins in each time step to introduce information bottlenecks.
Model architecture
Codebook projection and position embedding. Given a codebook pattern, only some codebooks exist in each pattern step P_s. The researcher retrieves the value from Q corresponding to the index in P_s. Each codebook appears in P_s at most once or not at all.
Transformer decoder. The input is fed into a transformer with L layers and D dimensions, each layer consisting of a causal self-attention block. A cross-attention block is then used, which is provided by the conditioning signal C. When using melodic conditioning, the researcher prefixes the conditional tensor C to the transformer input.
Logits prediction. At pattern step P_s, the output of the transformer decoder is converted into a logits prediction of Q values. Each codebook appears at most once in P_s 1. If the codebook exists, a codebook-specific linear layer is applied from the D channel to N to obtain the logits prediction.
Experimental results
Audio tokenization model. The study uses a non-causal five-layer EnCodec model for 32 kHz mono audio with a stride of 640, a frame rate of 50 Hz, and an initial hidden size of 64 that is doubled for each of the five layers of the model.
Transformer model, studied and trained autoregressive Transformer models of different sizes: 300M, 1.5B, 3.3B parameters.
Training data set. Study using 20,000 hours of licensed music to train MUSICGEN. In detail, the study used an in-house dataset containing 10K high-quality tracks, as well as the ShutterStock and Pond5 music datasets containing 25K and 365K instrumental-only tracks respectively.
Evaluation dataset. The study evaluates the proposed method on the MusicCaps benchmark and compares it with previous work. MusicCaps are composed of 5.5K samples (10 seconds long) prepared by expert musicians and 1K subsets balanced across genres.
Table 1 below gives the comparison of the proposed method with Mousai, Riffusion, MusicLM and Noise2Music. Results show that MUSICGEN outperforms baselines evaluated by human listeners in terms of audio quality and consistency with the provided text description. Noise2Music performs best on FAD on MusicCaps, followed by MUSICGEN trained with text conditions. Interestingly, adding the melody condition degraded the objective metrics, but did not significantly affect the human ratings and was still better than the evaluated baseline.
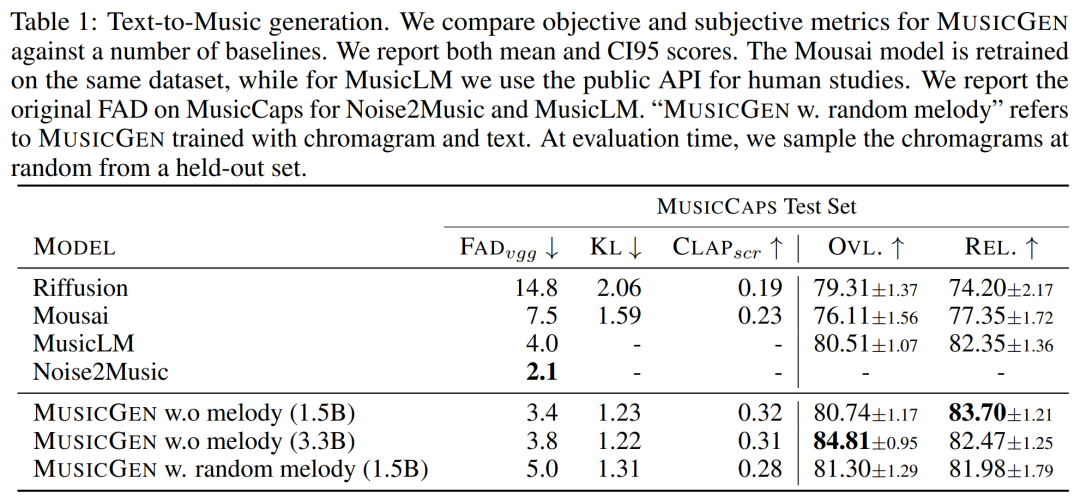
The researcher uses objective and subjective measures on the given evaluation set, in the text MUSICGEN was evaluated under the same conditions as melody representation. The results are shown in Table 2 below. The results show that MUSICGEN trained with chromatogram conditionalization successfully generates music that follows a given melody, allowing for better control over the generated output. MUSICGEN is robust to dropping chroma at inference time using OVL and REL.
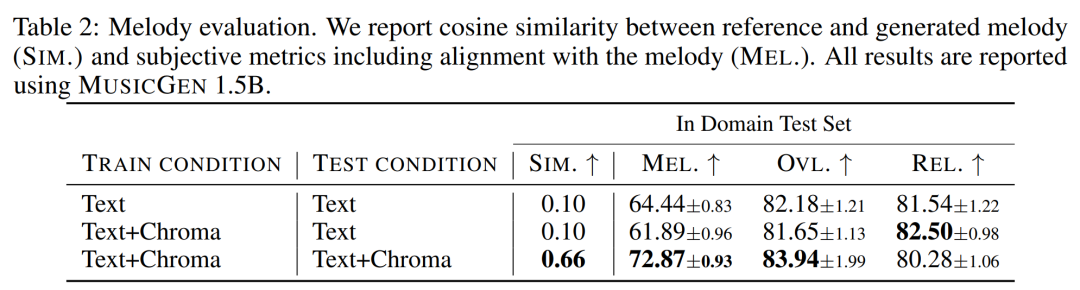
The impact of codebook interleaving mode. We evaluated various codebook patterns using the framework in Section 2.2, K = 4, given by the audio tokenization model. This article reports objective and subjective evaluations in Table 3 below. Although flattening improves generation, it is computationally expensive. Similar performance can be achieved at a fraction of the cost using simple deferral methods.
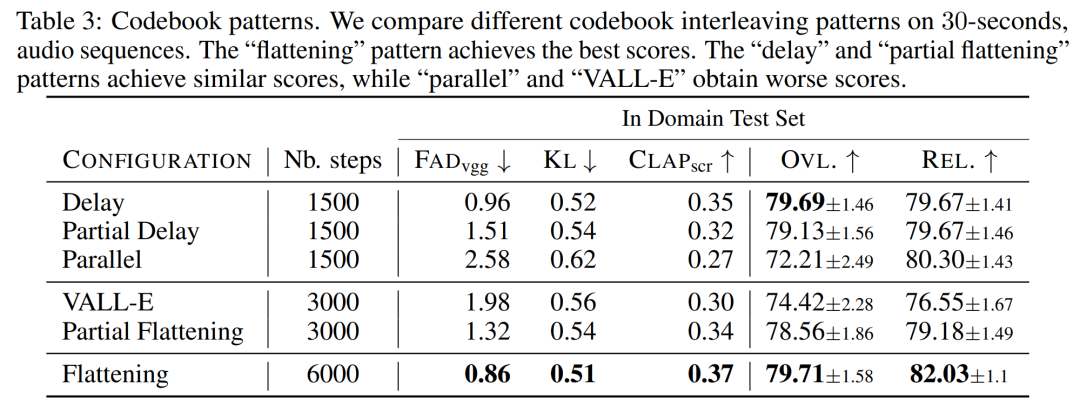
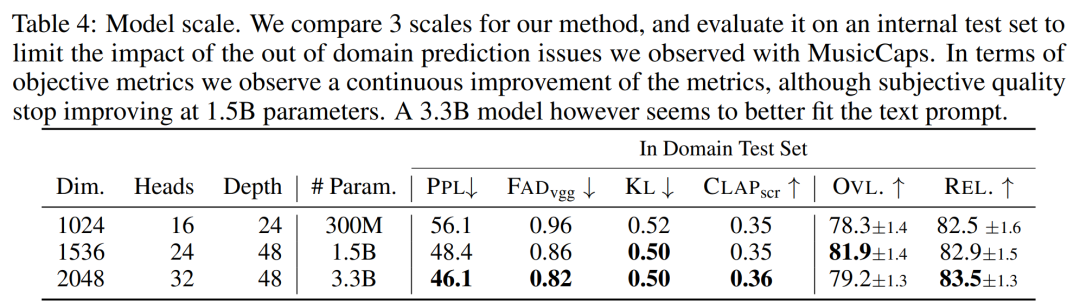
The effect of model size. Table 4 below reports the results for different model sizes, namely 300M, 1.5B and 3.3B parametric models. As expected, scaling up the model size results in better scores, but only at the expense of longer training and inference times. In terms of subjective evaluation, the overall quality is optimal at 1.5B, but larger models can better understand text prompts.
The above is the detailed content of Meta open source text generates a large music model. We tried it with the lyrics of 'Qilixiang'. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to comment deepseek
Feb 19, 2025 pm 05:42 PM
How to comment deepseek
Feb 19, 2025 pm 05:42 PM
DeepSeek is a powerful information retrieval tool. Its advantage is that it can deeply mine information, but its disadvantages are that it is slow, the result presentation method is simple, and the database coverage is limited. It needs to be weighed according to specific needs.
 How to search deepseek
Feb 19, 2025 pm 05:39 PM
How to search deepseek
Feb 19, 2025 pm 05:39 PM
DeepSeek is a proprietary search engine that only searches in a specific database or system, faster and more accurate. When using it, users are advised to read the document, try different search strategies, seek help and feedback on the user experience in order to make the most of their advantages.
 Sesame Open Door Exchange Web Page Registration Link Gate Trading App Registration Website Latest
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Page Registration Link Gate Trading App Registration Website Latest
Feb 28, 2025 am 11:06 AM
This article introduces the registration process of the Sesame Open Exchange (Gate.io) web version and the Gate trading app in detail. Whether it is web registration or app registration, you need to visit the official website or app store to download the genuine app, then fill in the user name, password, email, mobile phone number and other information, and complete email or mobile phone verification.
 Why can't the Bybit exchange link be directly downloaded and installed?
Feb 21, 2025 pm 10:57 PM
Why can't the Bybit exchange link be directly downloaded and installed?
Feb 21, 2025 pm 10:57 PM
Why can’t the Bybit exchange link be directly downloaded and installed? Bybit is a cryptocurrency exchange that provides trading services to users. The exchange's mobile apps cannot be downloaded directly through AppStore or GooglePlay for the following reasons: 1. App Store policy restricts Apple and Google from having strict requirements on the types of applications allowed in the app store. Cryptocurrency exchange applications often do not meet these requirements because they involve financial services and require specific regulations and security standards. 2. Laws and regulations Compliance In many countries, activities related to cryptocurrency transactions are regulated or restricted. To comply with these regulations, Bybit Application can only be used through official websites or other authorized channels
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download Address
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download Address
Feb 28, 2025 am 10:51 AM
It is crucial to choose a formal channel to download the app and ensure the safety of your account.
 Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
A detailed introduction to the login operation of the Sesame Open Exchange web version, including login steps and password recovery process. It also provides solutions to common problems such as login failure, unable to open the page, and unable to receive verification codes to help you log in to the platform smoothly.
 Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
This article recommends the top ten cryptocurrency trading platforms worth paying attention to, including Binance, OKX, Gate.io, BitFlyer, KuCoin, Bybit, Coinbase Pro, Kraken, BYDFi and XBIT decentralized exchanges. These platforms have their own advantages in terms of transaction currency quantity, transaction type, security, compliance, and special features. For example, Binance is known for its largest transaction volume and abundant functions in the world, while BitFlyer attracts Asian users with its Japanese Financial Hall license and high security. Choosing a suitable platform requires comprehensive consideration based on your own trading experience, risk tolerance and investment preferences. Hope this article helps you find the best suit for yourself
 Binance binance official website latest version login portal
Feb 21, 2025 pm 05:42 PM
Binance binance official website latest version login portal
Feb 21, 2025 pm 05:42 PM
To access the latest version of Binance website login portal, just follow these simple steps. Go to the official website and click the "Login" button in the upper right corner. Select your existing login method. If you are a new user, please "Register". Enter your registered mobile number or email and password and complete authentication (such as mobile verification code or Google Authenticator). After successful verification, you can access the latest version of Binance official website login portal.
