
 Technology peripherals
AI
Video generation with controllable time and space has become a reality, and Alibaba's new large-scale model VideoComposer has become popular
Technology peripherals
AI
Video generation with controllable time and space has become a reality, and Alibaba's new large-scale model VideoComposer has become popular
Video generation with controllable time and space has become a reality, and Alibaba's new large-scale model VideoComposer has become popular

In the field of AI painting, Composer proposed by Alibaba and ControlNet based on Stable diffusion proposed by Stanford have led the theoretical development of controllable image generation. However, the industry's exploration of controllable video generation is still relatively blank.
Compared with image generation, controllable video is more complex, because in addition to the controllability of the space of the video content, it also needs to meet the controllability of the time dimension. Based on this, the research teams of Alibaba and Ant Group took the lead in making an attempt and proposed VideoComposer, which simultaneously achieves video controllability in both time and space dimensions through a combined generation paradigm.

- Paper address: https://arxiv.org/abs/2306.02018
- Project homepage: https://videocomposer.github.io
Some time ago, Alibaba The Wensheng video model was low-key and open sourced in the MoDa community and Hugging Face. It unexpectedly attracted widespread attention from developers at home and abroad. The video generated by the model even received a response from Musk himself. The model received orders for many days in a row on the MoDa community. Tens of thousands of international visits per day.
#Text-to-Video on Twitter
VideoComposer As the latest achievement of the research team, it has once again received widespread attention from the international community focus on.


##VideoComposer on Twitter In fact, controllability has become a higher benchmark for visual content creation, which has made significant progress in customized image generation, but there are still three problems in the field of video generation. Big Challenge:
- Complex data structure, the generated video needs to satisfy both the diversity of dynamic changes in the time dimension and the content consistency in the spatio-temporal dimension;
- Complex Guidance conditions, existing controllable video generation requires complex conditions that cannot be constructed manually. For example, Gen-1/2 proposed by Runway needs to rely on depth sequences as conditions, which can better achieve structural migration between videos, but cannot solve the controllability problem well;
- Lack of motion controllability. Motion pattern is a complex and abstract attribute of video. Motion controllability is a necessary condition to solve the controllability of video generation.
Prior to this, Composer proposed by Alibaba has proven that compositionality is extremely helpful in improving the controllability of image generation, and this study on VideoComposer is also Based on the combined generation paradigm, it improves the flexibility of video generation while solving the above three major challenges. Specifically, the video is decomposed into three guiding conditions, namely text conditions, spatial conditions, and video-specific timing conditions, and then the Video LDM (Video Latent Diffusion Model) is trained based on this. In particular, it uses efficient Motion Vector as an important explicit timing condition to learn the motion pattern of videos, and designs a simple and effective spatiotemporal condition encoder STC-encoder to ensure the spatiotemporal continuity of condition-driven videos. In the inference stage, different conditions can be randomly combined to control the video content.
Experimental results show that VideoComposer can flexibly control the time and space patterns of videos, such as generating specific videos through single pictures, hand-drawn drawings, etc., and can even easily use simple hand-drawn directions. Control the target's movement style. This study directly tested the performance of VideoComposer on 9 different classic tasks, and all achieved satisfactory results, proving the versatility of VideoComposer.
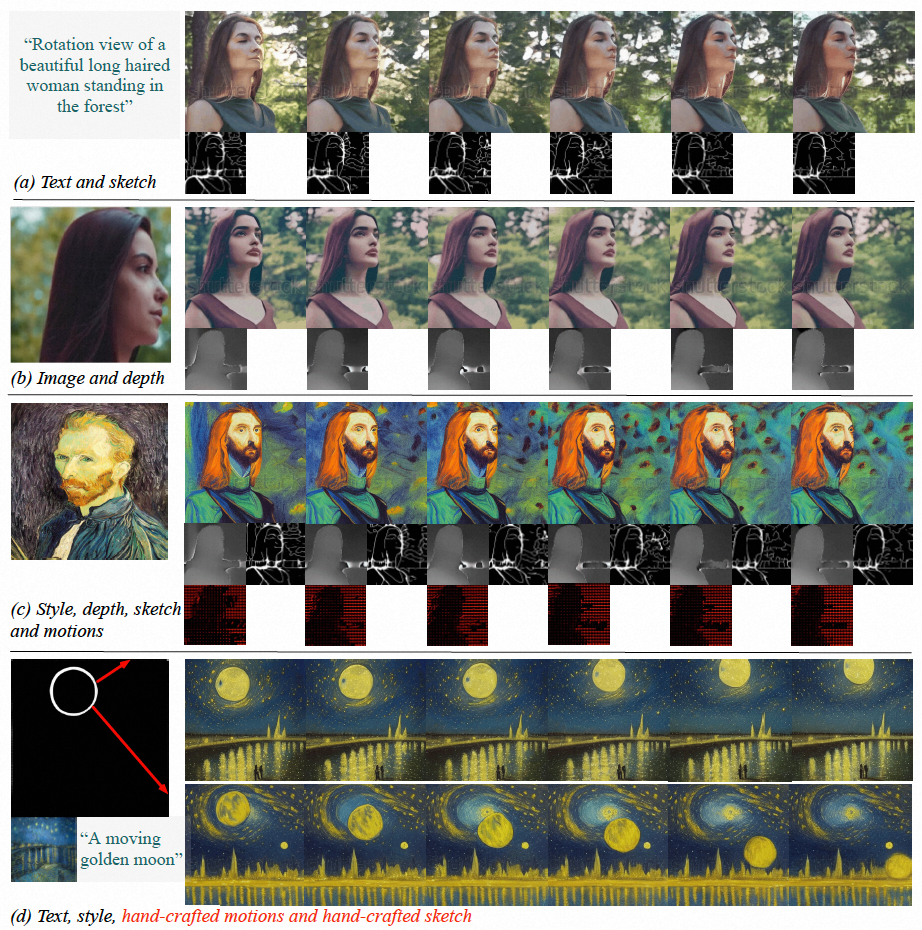
Figure (a-c) VideoComposer is able to generate videos that meet text, spatial and temporal conditions or a subset thereof; (d ) VideoComposer can use only two strokes to generate a video that satisfies Van Gogh's style, while satisfying the expected movement mode (red strokes) and shape mode (white strokes)
Method introduction
Video LDM ## Hidden space. Video LDM first introduces a pre-trained encoder to map the input video . Then, the pre-trained decoder D is used to map the latent space to the pixel space . In VideoComposer, the parameters are set to Diffusion model. To learn the actual video content distribution , the diffusion model learns to gradually denoise from the normal distribution noise to restore the real visual content. This process is actually simulating a reversible Markov chain with a length of T=1000. In order to perform a reversible process in the latent space, Video LDM injects noise into 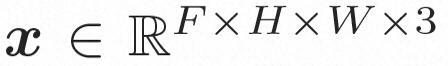 to a latent space expression, where
to a latent space expression, where 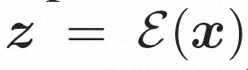
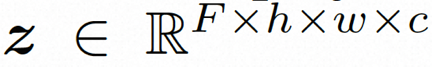
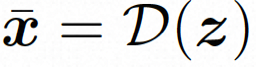
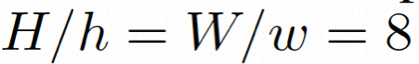 .
. 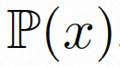
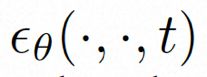
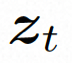
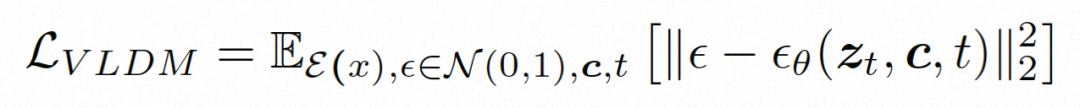
In order to fully explore the use of spatial local inductive bias and sequence temporal inductive bias for denoising, VideoComposer will 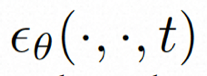
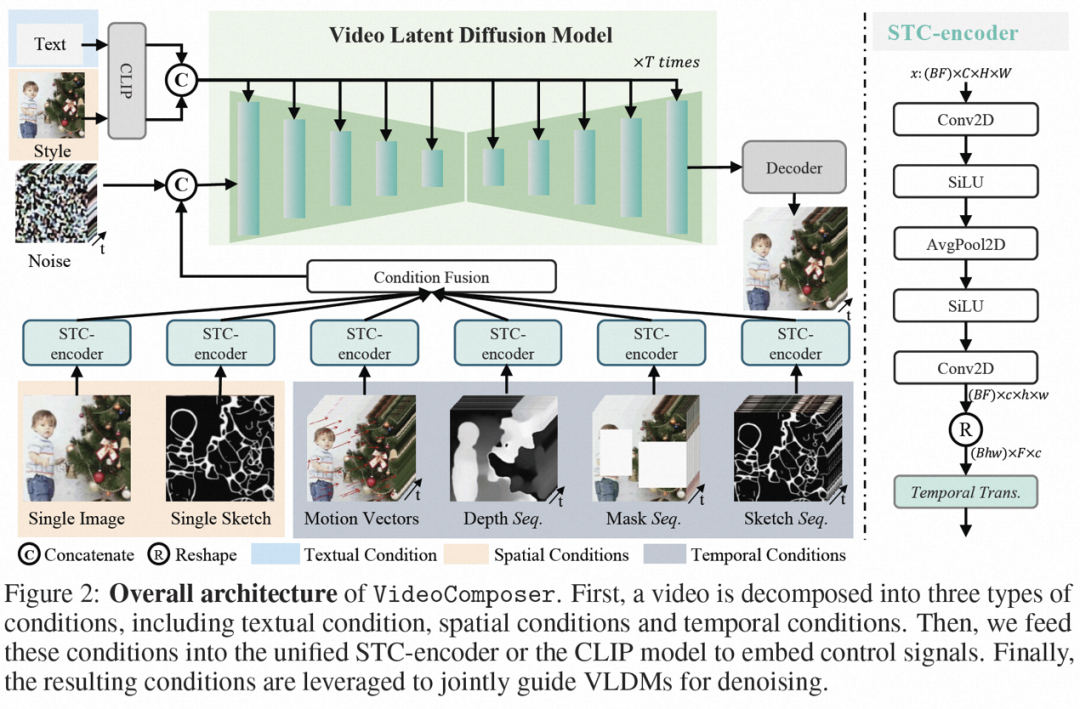
##VideoComposer
combination condition. VideoComposer decomposes video into three different types of conditions, namely textual conditions, spatial conditions, and critical timing conditions, which together determine spatial and temporal patterns in the video. VideoComposer is a general composable video generation framework, so more customized conditions can be incorporated into VideoComposer based on the downstream application, not limited to those listed below:
- Text conditions: Text description provides visual instructions for the video with rough visual content and motion aspects. This is also a commonly used condition for T2V;
- Spatial conditions:
- Single Image, select the first frame of a given video as the spatial condition to generate image to video , to express the content and structure of the video;
- Single Sketch, use PiDiNet to extract the sketch of the first video frame as the second spatial condition;
- Style (Style), in order to further transfer the style of a single image to the synthesized video, select image embedding as a style guide;
##
- Timing conditions:
- Motion Vector (Motion Vector), motion vector as a unique element of video is expressed as a two-dimensional vector, that is, horizontal and vertical directions. It explicitly encodes pixel-by-pixel movement between two adjacent frames. Due to the natural properties of motion vectors, this condition is treated as a temporally smooth synthesized motion control signal, which extracts motion vectors in standard MPEG-4 format from compressed video;
- depth sequence ( Depth Sequence), in order to introduce video-level depth information, use the pre-trained model in PiDiNet to extract the depth map of the video frame;
- Mask Sequence (Mask Sequence), introduce the tubular mask to mask local spatiotemporal content and force the model to predict the masked area based on observable information;
- Sketch Sequnce, compared with a single sketch, a sketch sequence can provide More control over details for precise, custom compositions.
# Spatiotemporal conditional encoder. Sequence conditions contain rich and complex spatiotemporal dependencies, which pose a great challenge to controllable instructions. To enhance the temporal perception of input conditions, this study designed a spatiotemporal condition encoder (STC-encoder) to incorporate spatiotemporal relationships. Specifically, a lightweight spatial structure is first applied, including two 2D convolutions and an avgPooling, to extract local spatial information, and then the resulting condition sequence is input to a temporal Transformer layer for temporal modeling. In this way, STC-encoder can facilitate the explicit embedding of temporal cues and provide a unified entry for conditional embedding for diverse inputs, thereby enhancing inter-frame consistency. In addition, the study repeated the spatial conditions of a single image and a single sketch in the temporal dimension to ensure their consistency with the temporal conditions, thus facilitating the condition embedding process.
After the conditions are processed through the STC-encoder, the final condition sequence has the same spatial shape as the STC-encoder and is then fused by element-wise addition. Finally, the merged conditional sequence is concatenated along the channel dimension as a control signal. For text and style conditions, a cross-attention mechanism is utilized to inject text and style guidance.
Training and inference
Two-stage training strategy. Although VideoComposer can be initialized through pre-training of image LDM, which can alleviate the training difficulty to a certain extent, it is difficult for the model to have the ability to perceive temporal dynamics and the ability to generate multiple conditions at the same time. , this will increase the difficulty of training combined video generation. Therefore, this study adopted a two-stage optimization strategy. In the first stage, the model was initially equipped with timing modeling capabilities through T2V training; in the second stage, VideoComposer was optimized through combined training to achieve better performance.
reasoning. During the inference process, DDIM is used to improve inference efficiency. And adopt classifier-free guidance to ensure that the generated results meet the specified conditions. The generation process can be formalized as follows:
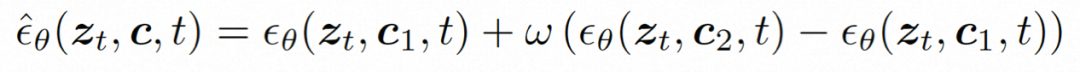
where ω is the guidance ratio; c1 and c2 are two sets of conditions. This guidance mechanism is judged by the set of two conditions, and can give the model more flexible control through intensity control.
Experimental results
In the experimental exploration, the study demonstrated that VideoComposer serves as a unified model with a universal generation framework and verified the capabilities of VideoComposer on 9 classic tasks.
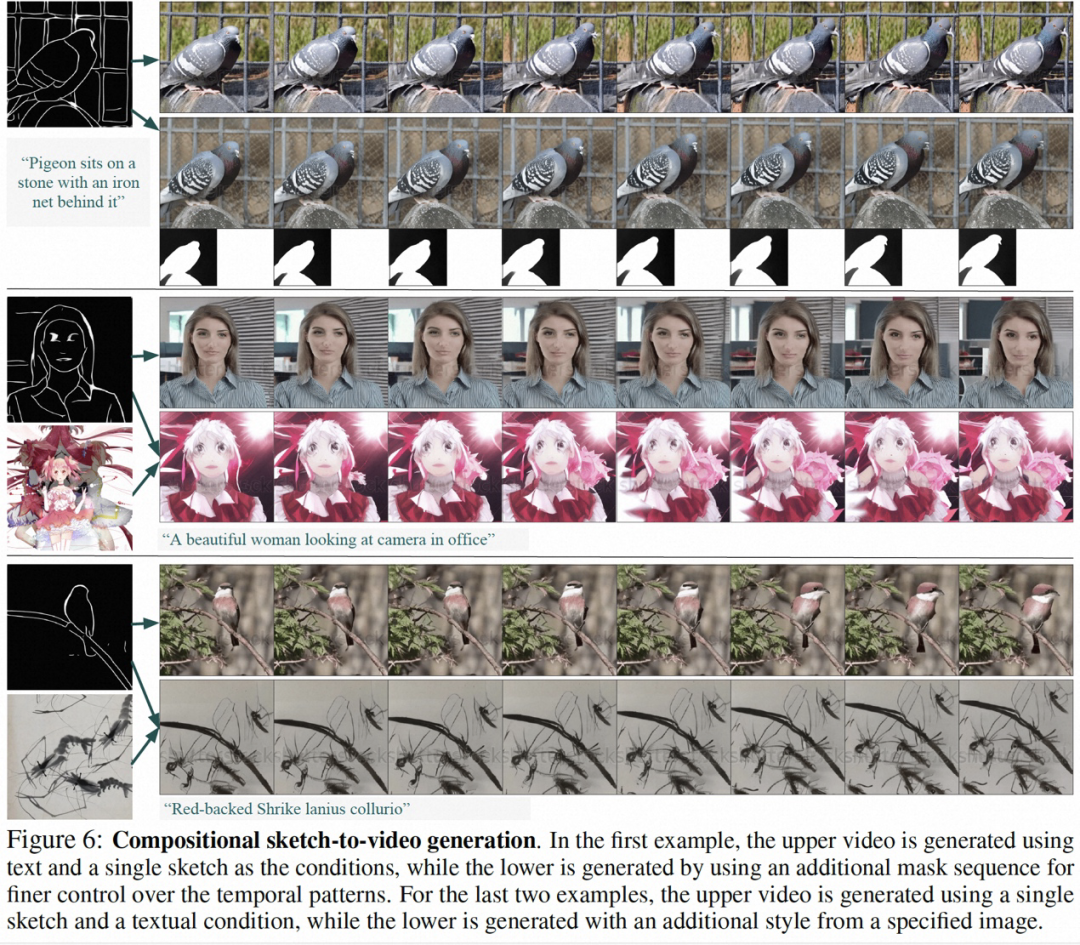
Part of the results of this research are as follows, in static picture to video generation (Figure 4), video Inpainting (Figure 5), static sketch generation to video (Figure 6), hand-painted motion control Video (Figure 8) and motion transfer (Figure A12) can both reflect the advantages of controllable video generation.



Public information shows that Alibaba’s research on visual basic models mainly focuses on the research of large visual representation models, visual generative large models and their downstream applications. It has published more than 60 CCF-A papers in related fields and won more than 10 international championships in multiple industry competitions, such as the controllable image generation method Composer, the image and text pre-training methods RA-CLIP and RLEG, and the uncropped long Video self-supervised learning HiCo/HiCo, speaking face generation method LipFormer, etc. all come from this team.
The above is the detailed content of Video generation with controllable time and space has become a reality, and Alibaba's new large-scale model VideoComposer has become popular. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Is it infringing to post other people's videos on Douyin? How does it edit videos without infringement?
Mar 21, 2024 pm 05:57 PM
Is it infringing to post other people's videos on Douyin? How does it edit videos without infringement?
Mar 21, 2024 pm 05:57 PM
With the rise of short video platforms, Douyin has become an indispensable part of everyone's daily life. On TikTok, we can see interesting videos from all over the world. Some people like to post other people’s videos, which raises a question: Is Douyin infringing upon posting other people’s videos? This article will discuss this issue and tell you how to edit videos without infringement and how to avoid infringement issues. 1. Is it infringing upon Douyin’s posting of other people’s videos? According to the provisions of my country's Copyright Law, unauthorized use of the copyright owner's works without the permission of the copyright owner is an infringement. Therefore, posting other people’s videos on Douyin without the permission of the original author or copyright owner is an infringement. 2. How to edit a video without infringement? 1. Use of public domain or licensed content: Public
 How to make money from posting videos on Douyin? How can a newbie make money on Douyin?
Mar 21, 2024 pm 08:17 PM
How to make money from posting videos on Douyin? How can a newbie make money on Douyin?
Mar 21, 2024 pm 08:17 PM
Douyin, the national short video platform, not only allows us to enjoy a variety of interesting and novel short videos in our free time, but also gives us a stage to show ourselves and realize our values. So, how to make money by posting videos on Douyin? This article will answer this question in detail and help you make more money on TikTok. 1. How to make money from posting videos on Douyin? After posting a video and gaining a certain amount of views on Douyin, you will have the opportunity to participate in the advertising sharing plan. This income method is one of the most familiar to Douyin users and is also the main source of income for many creators. Douyin decides whether to provide advertising sharing opportunities based on various factors such as account weight, video content, and audience feedback. The TikTok platform allows viewers to support their favorite creators by sending gifts,
 2 Ways to Remove Slow Motion from Videos on iPhone
Mar 04, 2024 am 10:46 AM
2 Ways to Remove Slow Motion from Videos on iPhone
Mar 04, 2024 am 10:46 AM
On iOS devices, the Camera app allows you to shoot slow-motion video, or even 240 frames per second if you have the latest iPhone. This capability allows you to capture high-speed action in rich detail. But sometimes, you may want to play slow-motion videos at normal speed so you can better appreciate the details and action in the video. In this article, we will explain all the methods to remove slow motion from existing videos on iPhone. How to Remove Slow Motion from Videos on iPhone [2 Methods] You can use Photos App or iMovie App to remove slow motion from videos on your device. Method 1: Open on iPhone using Photos app
 How to publish Xiaohongshu video works? What should I pay attention to when posting videos?
Mar 23, 2024 pm 08:50 PM
How to publish Xiaohongshu video works? What should I pay attention to when posting videos?
Mar 23, 2024 pm 08:50 PM
With the rise of short video platforms, Xiaohongshu has become a platform for many people to share their lives, express themselves, and gain traffic. On this platform, publishing video works is a very popular way of interaction. So, how to publish Xiaohongshu video works? 1. How to publish Xiaohongshu video works? First, make sure you have a video content ready to share. You can use your mobile phone or other camera equipment to shoot, but you need to pay attention to the image quality and sound clarity. 2. Edit the video: In order to make the work more attractive, you can edit the video. You can use professional video editing software, such as Douyin, Kuaishou, etc., to add filters, music, subtitles and other elements. 3. Choose a cover: The cover is the key to attracting users to click. Choose a clear and interesting picture as the cover to attract users to click on it.
 Where can I find Alibaba ID?
Mar 08, 2024 pm 09:49 PM
Where can I find Alibaba ID?
Mar 08, 2024 pm 09:49 PM
In Alibaba software, once you successfully register an account, the system will assign you a unique ID, which will serve as your identity on the platform. But for many users, they want to query their ID, but don't know how to do it. Then the editor of this website will bring you detailed introduction to the strategy steps below. I hope it can help you! Where can I find the answer to Alibaba ID: [Alibaba]-[My]. 1. First open the Alibaba software. After entering the homepage, we need to click [My] in the lower right corner; 2. Then after coming to the My page, we can see [id] at the top of the page; Alibaba Is the ID the same as Taobao? Alibaba ID and Taobao ID are different, but the two
 Alibaba's Hangzhou global headquarters was put into use on May 10
May 07, 2024 pm 02:43 PM
Alibaba's Hangzhou global headquarters was put into use on May 10
May 07, 2024 pm 02:43 PM
This website reported on May 7 that on May 10, Alibaba’s global headquarters (Xixi Area C) located in Hangzhou Future Science and Technology City will be officially put into use. At the same time, Alibaba Beijing Chaoyang Science and Technology Park will also be opened. This marks the number of Alibaba headquarters office buildings worldwide reaching four. ▲Alibaba Global Headquarters (Zone C, Xixi) May 10th is also Alibaba’s 20th “Alibaba Day”. On this day every year, the company will hold celebrations, and two new parks will be open to Alibaba’s relatives, friends, and alumni. Xixi Area C is currently Alibaba’s largest self-owned park and can accommodate 30,000 people for office work. ▲Alibaba Beijing Chaoyang Science and Technology Park Alibaba Global Headquarters is located in Hangzhou Future Science and Technology City, north of Wenyi West Road and east of Gaojiao Road, with a total construction area of 984,500 square meters, of which
 DAMO Academy announces the final test questions of the 2024 Alibaba Global Mathematics Competition: five tracks, results in August
Jun 23, 2024 pm 06:36 PM
DAMO Academy announces the final test questions of the 2024 Alibaba Global Mathematics Competition: five tracks, results in August
Jun 23, 2024 pm 06:36 PM
According to news from this site on June 23, this site learned from the DAMO WeChat public account that at 24:00 on June 22, Beijing time, the finals of the 2024 Alibaba Global Mathematics Competition officially ended. More than 800 contestants from 17 countries and regions around the world were shortlisted for this finals. Next, we will enter the independent marking stage of the expert group. Grading includes preliminary evaluation, cross-examination, final verification and other processes. In the five tracks of the finals, 1 Gold Medal, 2 Silver Medals, 4 Bronze Medals and 10 Excellence Awards will be awarded based on results. A total of 85 winners will be announced in August. Alibaba Damo Academy also announced the topics for the mathematics finals. The finals are divided into five tracks, namely: 1. Algebra and number theory; 2. Geometry and topology; 3. Analysis and equations; 4. Combination and probability; 5. Application and calculation.
 How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
1. First open Weibo on your mobile phone and click [Me] in the lower right corner (as shown in the picture). 2. Then click [Gear] in the upper right corner to open settings (as shown in the picture). 3. Then find and open [General Settings] (as shown in the picture). 4. Then enter the [Video Follow] option (as shown in the picture). 5. Then open the [Video Upload Resolution] setting (as shown in the picture). 6. Finally, select [Original Image Quality] to avoid compression (as shown in the picture).
