
 Technology peripherals
AI
One article to understand lidar and visual fusion perception of autonomous driving
Technology peripherals
AI
One article to understand lidar and visual fusion perception of autonomous driving
One article to understand lidar and visual fusion perception of autonomous driving

2022 is the window period for intelligent driving to move from L2 to L3/L4. More and more automobile manufacturers have begun to deploy higher-level intelligent driving mass production, and the era of automobile intelligence has quietly arrived.
With the technical improvement of lidar hardware, car-grade mass production and cost reduction, high-level intelligent driving functions have promoted the mass production of lidar in the field of passenger cars. A number of models equipped with lidar will be delivered this year, and 2022 is also known as "the first year of lidar on the road."
01 Lidar sensor vs image sensor
Lidar is a sensor used to accurately obtain the three-dimensional position of an object. It is essentially a laser Detection and ranging. With its excellent performance in target contour measurement and universal obstacle detection, it is becoming the core configuration of L4 autonomous driving.
However, the range measurement range of lidar (generally around 200 meters, and the mass production models of different manufacturers have different indicators) results in a perception range that is much smaller than that of image sensors.
And because its angular resolution (generally 0.1° or 0.2°) is relatively small, the resolution of the point cloud is much smaller than that of the image sensor. When sensing at a long distance, it is projected to the target object. The points on the image may be so sparse that they cannot even be imaged. For point cloud target detection, the effective point cloud distance that the algorithm can really use is only about 100 meters.
Image sensors can acquire complex surrounding information at high frame rates and high resolutions, and are cheap. Multiple sensors with different FOV and resolutions can be deployed for different distances and ranges. visual perception, the resolution can reach 2K-4K.
However, the image sensor is a passive sensor with insufficient depth perception and poor ranging accuracy. Especially in harsh environments, the difficulty of completing sensing tasks will increase significantly.
In the face of strong light, low illumination at night, rain, snow, fog and other weather and light environments, intelligent driving has high requirements on sensor algorithms. Although lidar is not sensitive to the influence of ambient light, the distance measurement will be greatly affected by waterlogged roads, glass walls, etc.
It can be seen that lidar and image sensors each have their own advantages and disadvantages. Most high-level intelligent driving passenger cars choose to integrate different sensors to complement each other's advantages and integrate redundancy.
Such a fused sensing solution has also become one of the key technologies for high-level autonomous driving.
02 Point cloud and image fusion perception based on deep learning
The fusion of point cloud and image belongs to Multi-Sensor Fusion ,MSF) technology field, there are traditional random methods and deep learning methods, which are mainly divided into three levels according to the abstraction level of information processing in the fusion system:
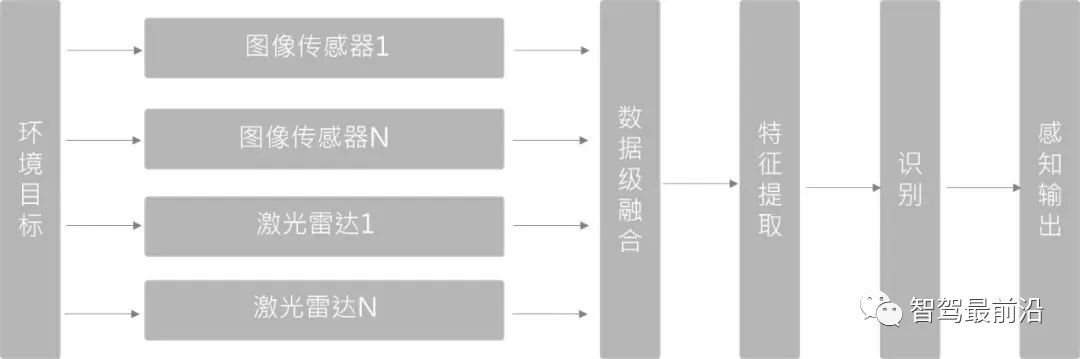
Data layer fusion (Early Fusion)
First fuse the sensor observation data, and then extract features from the fused data for identification. In 3D target detection, PointPainting (CVPR20) adopts this method. The PointPainting method first performs semantic segmentation on the image, maps the segmented features to the point cloud through a point-to-image pixel matrix, and then "draws the point" The point cloud is sent to the 3D point cloud detector to perform regression on the target Box.
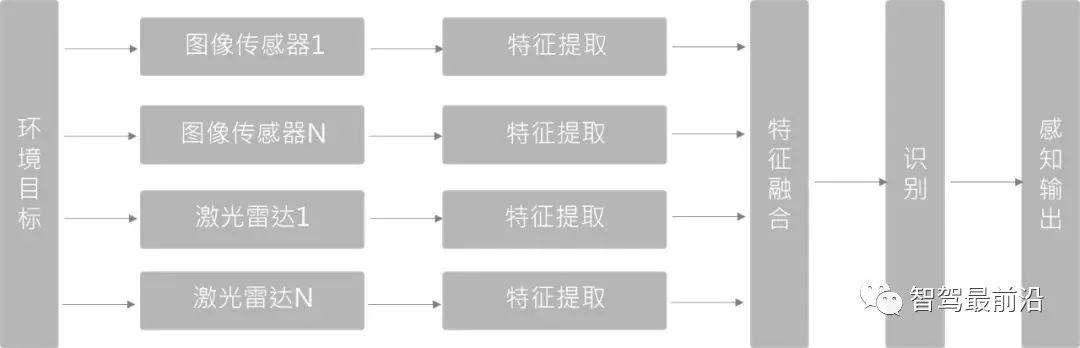
##Feature layer fusion (Deep Fusion)
First extract the natural data features from the observation data provided by each sensor, and then fuse these features for identification. In the fusion method based on deep learning, this method uses feature extractors for both the point cloud and the image branch. The networks of the image branch and the point cloud branch are fused semantically level by level in the forward feedback level to achieve multi-scale information. semantic fusion.
The feature layer fusion method based on deep learning has high requirements for spatiotemporal synchronization between multiple sensors. Once the synchronization is not good, it will directly affect the effect of feature fusion. At the same time, due to differences in scale and viewing angle, it is difficult for the feature fusion of LiDAR and images to achieve the effect of 1 1>2.
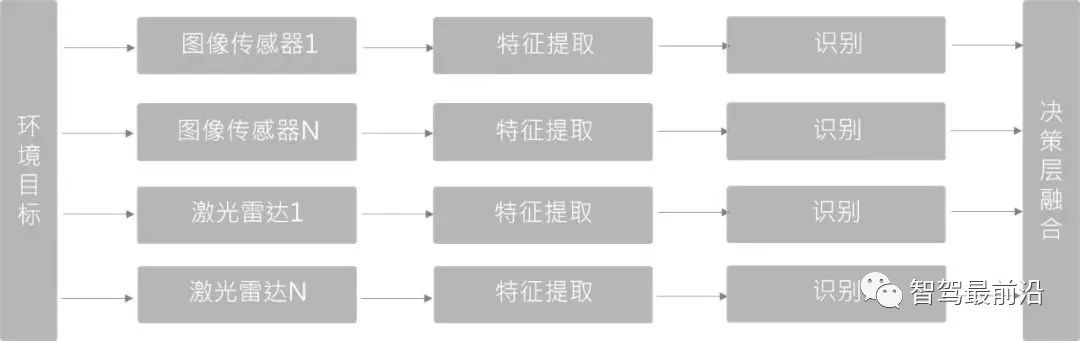
Decision-making layer fusion (Late Fusion)
Compared with the first two, it is the least complex fusion method. It does not fuse at the data layer or feature layer, but is a target-level fusion. Different sensor network structures do not affect each other and can be trained and combined independently.
Since the two types of sensors and detectors fused at the decision-making layer are independent of each other, once a sensor fails, sensor redundancy processing can still be performed, and the engineering robustness is better.
With the continuous iteration of lidar and visual fusion perception technology, as well as the continuous accumulation of knowledge scenarios and cases, it will More and more full-stack converged computing solutions are emerging to bring a safer and more reliable future for autonomous driving.
The above is the detailed content of One article to understand lidar and visual fusion perception of autonomous driving. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
