

As the saying goes, words are like faces, and words are like people. Compared with rigid printed fonts, handwriting can better reflect the personal characteristics of the writer. I believe many people have imagined having their own set of handwriting fonts and using them in social software to better show their personal style.
However, unlike English letters, the number of Chinese characters is extremely large, and it is very expensive to create your own exclusive font. For example, the newly released national standard GB18030-2022 Chinese character set contains more than 80,000 Chinese characters. There are reports that a blogger on a video website spent 18 hours writing more than 7,000 Chinese characters, using 13 pens during the process, and his hands were numb from writing!
#The above questions triggered the author of the paper to think. Can he design an automatic text generation model to help solve the problem of high cost of creating exclusive fonts? In order to solve this problem, the researchers envisioned an AI that can imitate handwriting. Only the user needs to provide a small number of handwriting samples (about a dozen) to extract the writing style contained in the handwriting (such as the size of the characters, the degree of inclination, the degree of inclination, etc.) aspect ratio, stroke length and curvature, etc.), and copy the style to synthesize more text, thereby efficiently synthesizing a complete set of handwritten fonts for users.

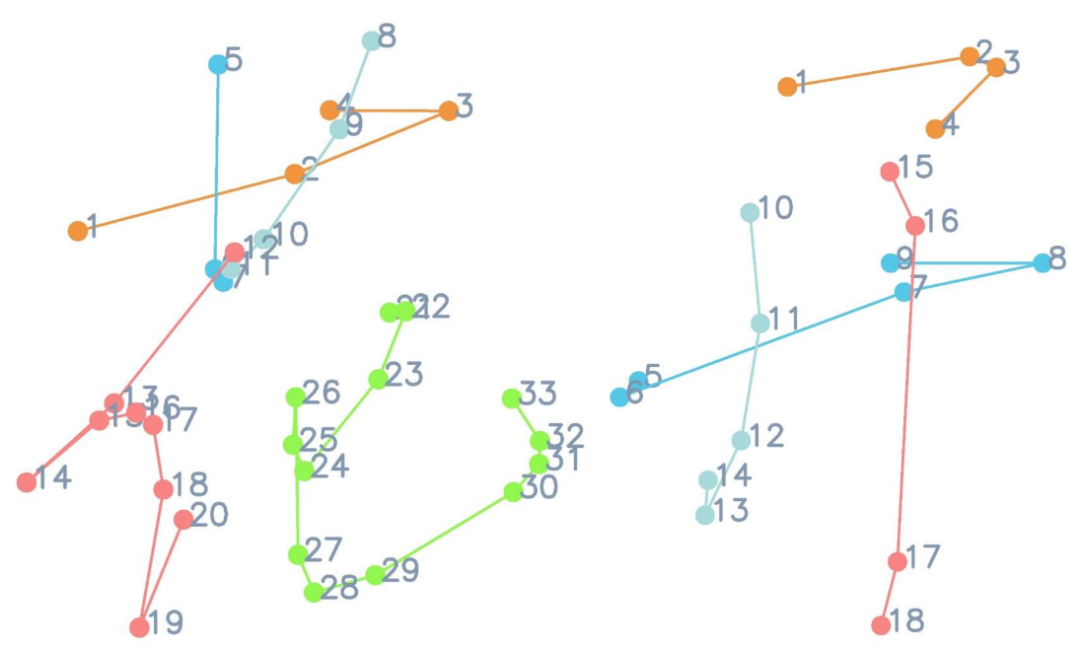
Further, the author of the paper analyzed the input and output of the model from the perspectives of application value and user experience. The modal has made the following thoughts: 1. Considering that the online handwritings of the sequence mode contain richer information (the detailed position and writing order of the track points, as shown in the figure below) than the offline handwritings of the image mode. (shown), setting the output mode of the model to online text will have wider application prospects, such as robot writing and calligraphy education. 2. In daily life, it is more convenient for people to use mobile phones to take photos to obtain offline text than to obtain online text through collection devices such as tablets and touch pens. Therefore, setting the input mode of the generated model to offline text will make it more convenient for users to use!
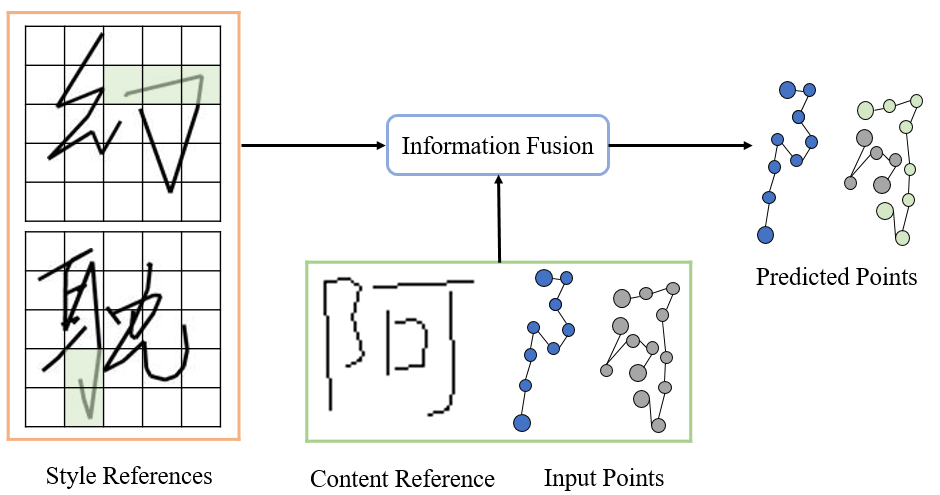
To sum up, the research goal of this article is to propose a stylized online handwritten text generation Model (stylized online handwriting generation method). This model can not only copy the writing style contained in the offline text provided by the user, but also generate content-controllable handwriting online according to the user's needs.

In order to achieve the above goals, researchers analyzed two key issues: 1. Since users can only provide a small number of character samples, can the user's unique writing style be learned only from these small number of reference samples? In other words, is it feasible to copy a user's writing style based on a small number of reference samples? 2. The research goal of this article is not only to ensure that the generated text style is controllable, but also that the content is also controllable. Therefore, after learning the user's writing style, how to efficiently combine the style with the text content to generate handwriting that meets the user's expectations? Next, let’s take a look at how the SDT (style disentangled Transformer) method proposed in this CVPR 2023 solves these two problems.
Research motivation Researchers found that there are usually two writing styles in personal handwriting: 1. There is an overall stylistic commonality in the handwriting of the same writer, with individual characters showing similar slant and aspect ratios, and the stylistic commonalities of different writers vary. Because this characteristic can be used to distinguish different writers, researchers call it writer's style. 2. In addition to overall stylistic commonalities, there are detailed stylistic inconsistencies between different characters from the same writer. For example, for the two characters "黑" and "杰", they have the same four-dot water radical in character structure. However, there are slight writing differences in the writing of this radical in different characters, which is reflected in the length of the strokes. , position and curvature. Researchers call this subtle style pattern in glyphs glyph style. Inspired by the above observations, SDT aims to decouple the writer and glyph style from personal handwriting, hoping to improve the ability to imitate the style of user handwriting.

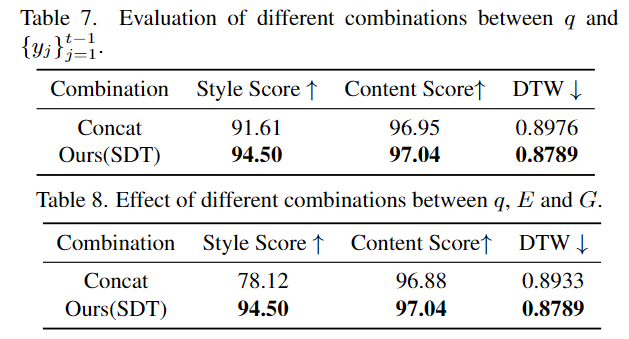
After learning the style information, unlike previous handwritten text generation methods that simply splice style and content features, SDT will Content features are used as query vectors to adaptively capture style information, thereby achieving efficient integration of style and content and generating handwriting that meets user expectations.
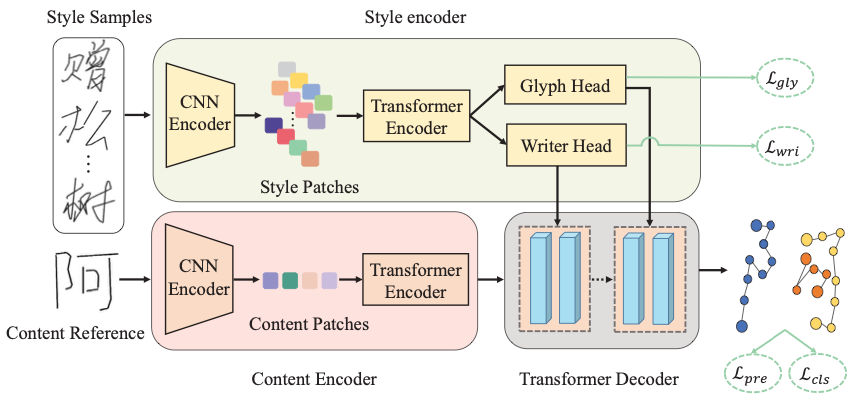
##Method Framework The overall framework of SDT is shown in the figure below, which consists of three parts: a dual-branch style encoder, a content encoder and a transformer decoder. First, this paper proposes two complementary contrastive learning objectives to guide the writer branch and glyph branch of the style encoder to learn corresponding style extraction respectively. Then, SDT uses the attention mechanism of the transformer (multi-head attention) to dynamically fuse the style features and the content features extracted by the content encoder to progressively synthesize online handwritten text.
(a) Comparative study of writers’ styles SDT proposes a supervised comparative learning objective (WriterNCE) for writer style extraction, which brings together character samples belonging to the same writer, pushes away handwriting samples belonging to different writers, and explicitly guides the writer Branches focus on stylistic commonalities in individual handwriting.
(b) Character style contrastive learning In order to learn more detailed glyph styles, SDT proposes an unsupervised comparative learning goal (GlyphNCE), used to maximize the mutual information between different views of the same character, and encourage the glyph branch to focus on learning the detailed patterns in the characters. As shown in the figure below, first do two independent samples of the same handwritten character to obtain a pair of positive samples containing detailed stroke information
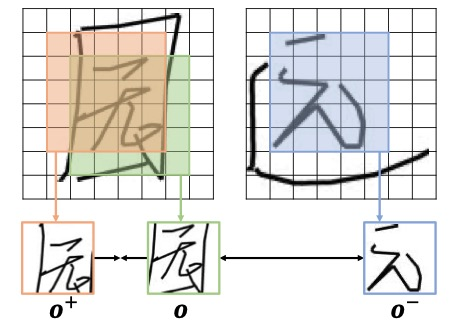
(c) Integration strategy of style and content information After obtaining the two style features , how to efficiently integrate it with the content encoding learned by the content encoder? In order to solve this problem, at any decoding time t, SDT regards the content feature as the initial point, and then combines the trajectory points output before q and t time
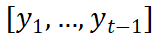
Form new content context
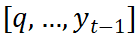
. Next, the content context is treated as a query vector and style information as key & value vectors. With the integration of the cross-attention mechanism, content context and two style information are dynamically aggregated in turn.
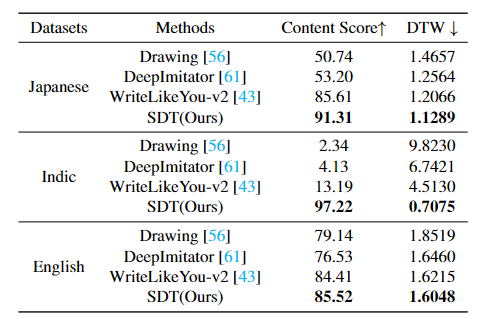
Quantitative Evaluation SDT is in The best performance has been achieved on Chinese, Japanese, Indian and English data sets, especially in the style score index. Compared with the previous SOTA method, SDT has achieved a major breakthrough.
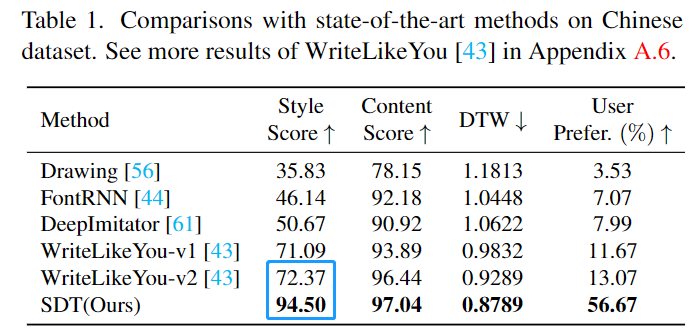
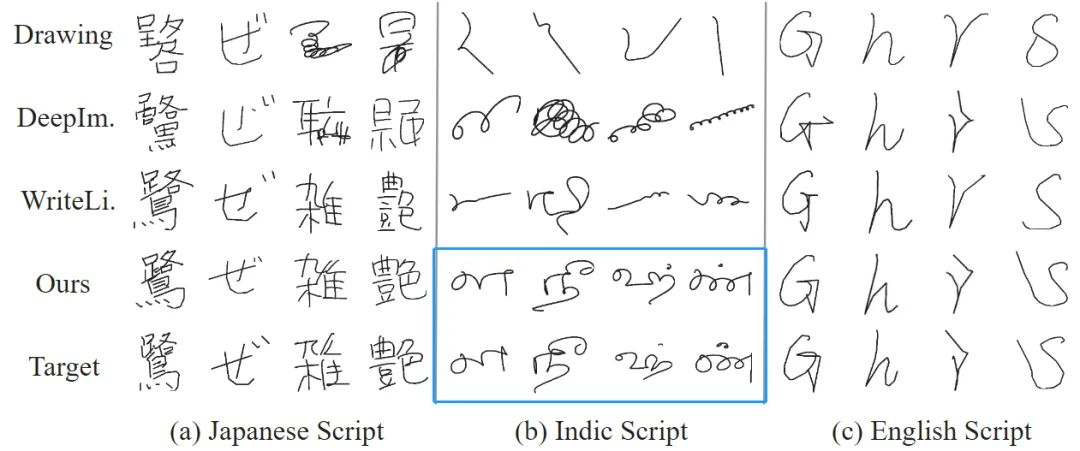
#Qualitative evaluation In terms of Chinese generation, compared with previous methods, the handwritten characters generated by SDT can avoid character collapse It can also copy the user's writing style very well. Thanks to glyph style learning, SDT can also do a good job in generating stroke details of characters.

SDT also performs well in other languages. Especially in terms of Indian text generation, existing mainstream methods can easily generate collapsed characters, but our SDT can still maintain the correctness of character content.
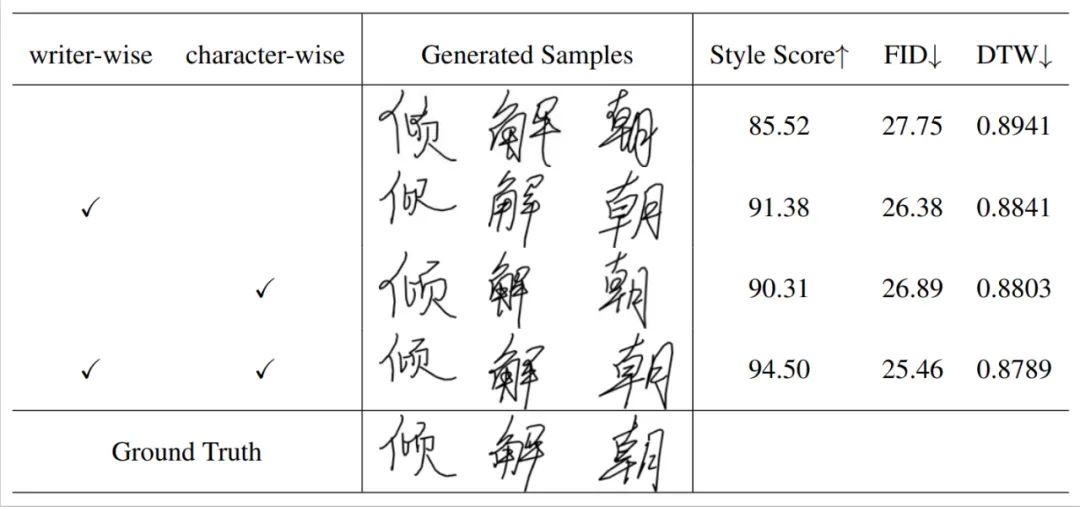
The impact of different modules on algorithm performance is shown in the following table , the various modules proposed in this article have synergistic effects and effectively improve the performance of copying user handwriting. Specifically, the addition of the writer's style improves SDT's imitation of the overall character style, such as the tilt and aspect ratio of the characters, while the addition of the glyph style improves the stroke details of the generated characters. Compared with the simple fusion strategy of existing methods, SDT's adaptive dynamic fusion strategy comprehensively enhances the character generation performance in various indicators.
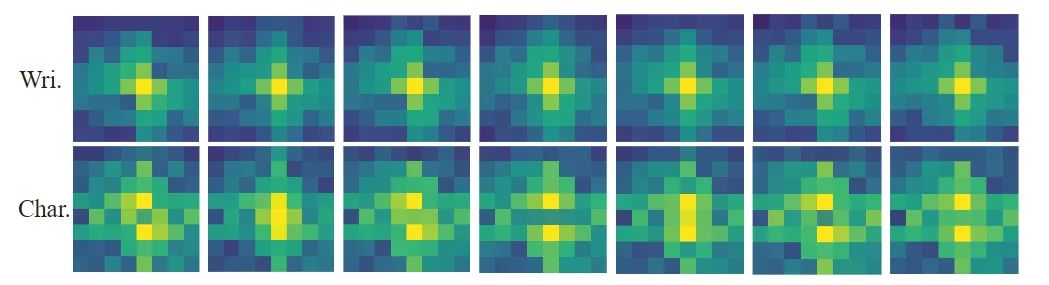
##Two kinds Visual analysis of style Perform Fourier transform on the two style features to obtain the following spectrogram. It can be observed from the figure that the writer's style contains more low-frequency components, while the glyph style mainly focuses on high-frequency components. . In fact, the low-frequency components contain the overall outline of the target, while the high-frequency components pay more attention to the details of the object. This finding further validates and explains the effectiveness of the decoupled writing style.
Everyone can create their own exclusive fonts through handwriting AI and better express themselves on social platforms!
The above is the detailed content of AI that can imitate handwriting and create exclusive fonts for you. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



