
 Technology peripherals
AI
No need to label data, '3D understanding' enters the era of multi-modal pre-training! ULIP series is fully open source and refreshes SOTA
Technology peripherals
AI
No need to label data, '3D understanding' enters the era of multi-modal pre-training! ULIP series is fully open source and refreshes SOTA
No need to label data, '3D understanding' enters the era of multi-modal pre-training! ULIP series is fully open source and refreshes SOTA

By aligning three-dimensional shapes, two-dimensional pictures and corresponding language descriptions, multi-modal pre-training methods also drive the development of 3D representation learning.
However, the existing multi-modal pre-training frameworkmethods of collecting data lack scalability, which greatly limits the potential of multi-modal learning. Among them, the most The main bottleneck lies in the scalability and comprehensiveness of language modalities.
Recently, Salesforce AI teamed up with Stanford University and the University of Texas at Austin to release the ULIP (CVP R2023) and ULIP-2 projects, which are leading a new chapter in 3D understanding. .

Paper link: https://arxiv.org/pdf/2212.05171.pdf
Paper link: https://arxiv.org/pdf/2305.08275.pdf
##Code link: https: //github.com/salesforce/ULIP
The researchers used a unique approach to pre-train the model using 3D point clouds, images and text, aligning them to A unified feature space. This approach achieves state-of-the-art results in 3D classification tasks and opens up new possibilities for cross-domain tasks such as image-to-3D retrieval.
And ULIP-2 makes this multi-modal pre-training possible without any manual annotation, thus enabling large-scale scalability.
ULIP-2 achieved significant performance improvements in the downstream zero-shot classification of ModelNet40, reaching the highest accuracy of 74.0%; on the real-world ScanObjectNN benchmark, it only used 1.4 million An overall accuracy of 91.5% was achieved with just one parameter, marking a breakthrough in scalable multimodal 3D representation learning without the need for human 3D annotation.
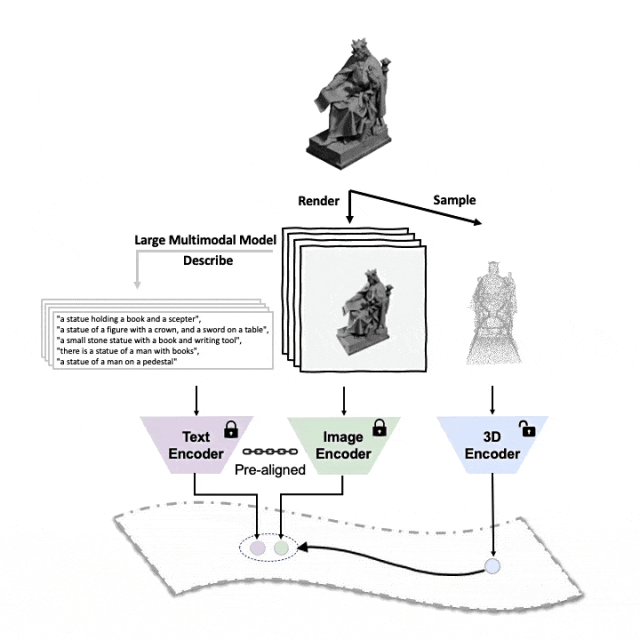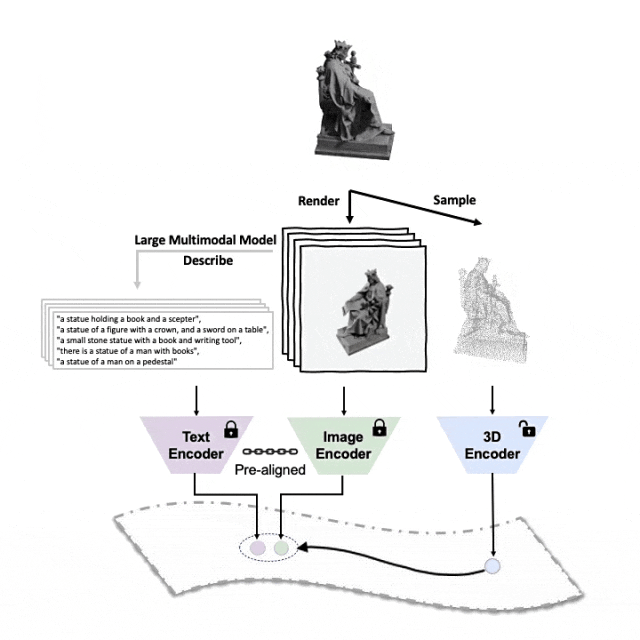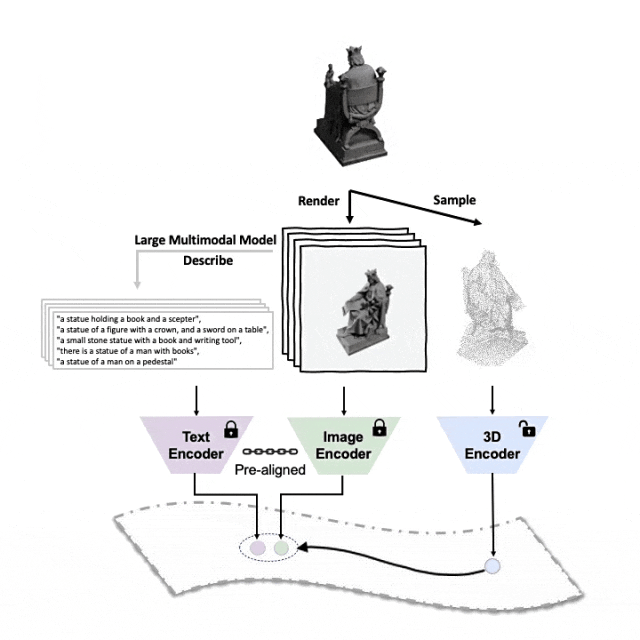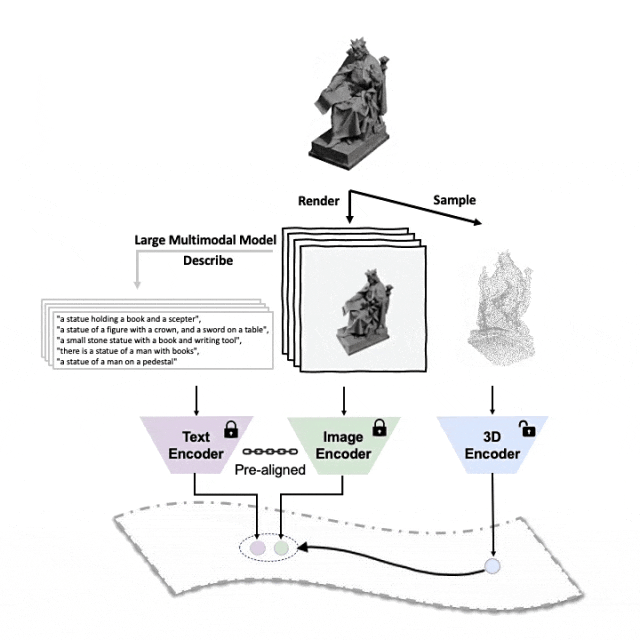
Schematic diagram of the pre-training framework for aligning these three features (3D, image, text)
The code and the released large-scale tri-modal data sets ("ULIP - Objaverse Triplets" and "ULIP - ShapeNet Triplets") have been open source.
Background3D understanding is an important part of the field of artificial intelligence, which allows machines to perceive and interact in three-dimensional space like humans. This capability has important applications in areas such as autonomous vehicles, robotics, virtual reality, and augmented reality.
However, 3D understanding has always faced huge challenges due to the complexity of processing and interpreting 3D data, as well as the cost of collecting and annotating 3D data.
ULIP
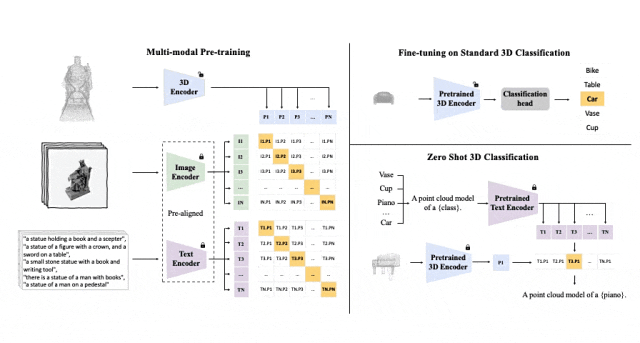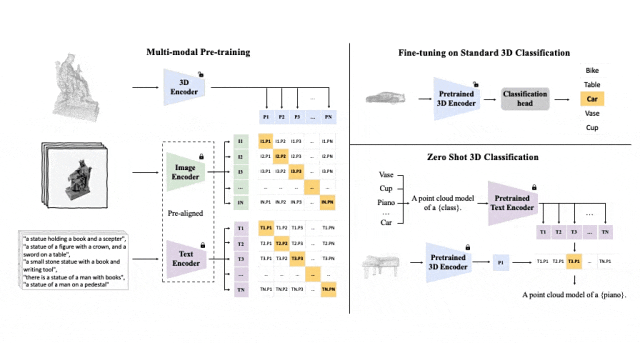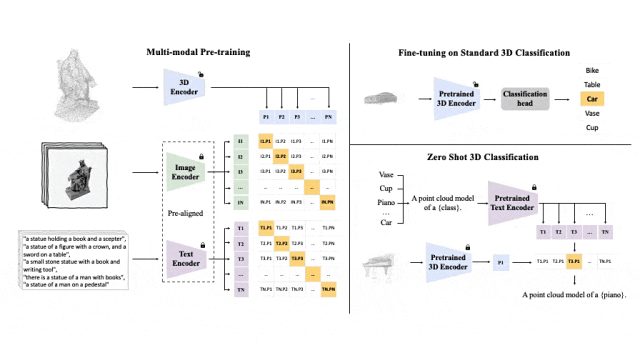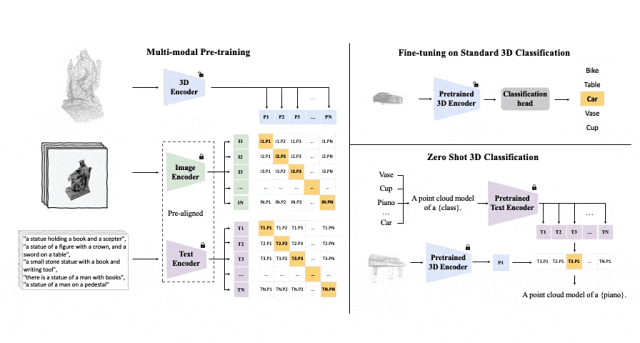
##Tri-modal pre-training framework and its downstream tasks
ULIP (already accepted by CVPR2023) adopts a unique approach to pre-train the model using 3D point clouds, images and text, aligning them into a unified representation space .This approach achieves state-of-the-art results in 3D classification tasks and opens up new possibilities for cross-domain tasks such as image-to-3D retrieval.
The key to the success of ULIP is the use of pre-aligned image and text encoders, such as CLIP, which are pre-trained on a large number of image-text pairs.
These encoders align the features of the three modalities into a unified representation space, enabling the model to understand and classify 3D objects more effectively.
This improved 3D representation learning not only enhances the model’s understanding of 3D data, but also enables cross-modal applications such as zero-shot 3D classification and image-to-3D retrieval because the 3D encoder gains Multimodal context.
The pre-training loss function of ULIP is as follows:
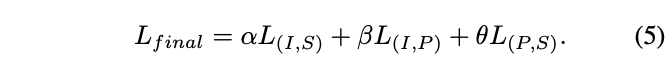
In the default settings of ULIP, α is is set to 0, β and θ are set to 1, and the contrastive learning loss function between each two modes is defined as follows, where M1 and M2 refer to any two modes among the three modes:
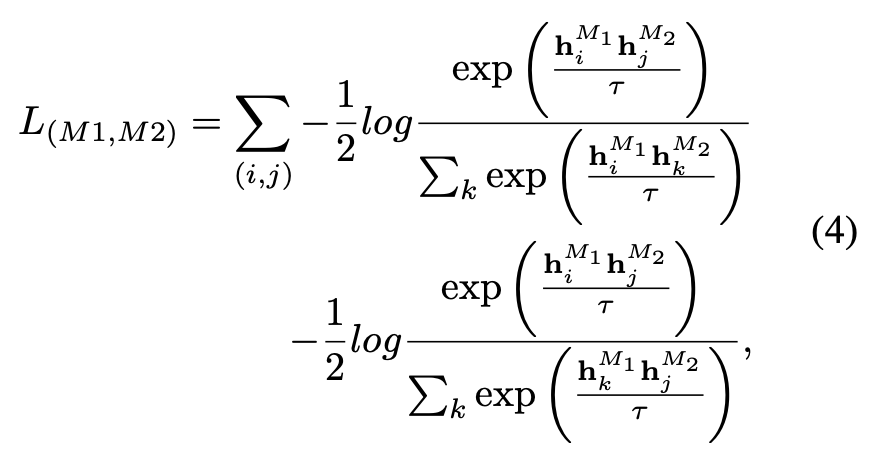
ULIP also conducted experiments on retrieval from image to 3D, and the results are as follows:

The experimental results show that the ULIP pre-trained model has been able to learn meaningful multi-modal features between images and 3D point clouds.
Surprisingly, compared to the other retrieved 3D models, the first retrieved 3D model is closest in appearance to the query image.
For example, when we use images from different aircraft types (fighters and airliners) for retrieval (second and third rows), the closest 3D point cloud retrieved is still Subtle differences in query images are preserved.
ULIP-2
##Here is a 3D object that generates multi-angle text descriptions Example. We first render 3D objects into 2D images from a set of views, and then use a large multi-modal model to generate descriptions for all generated images
ULIP-2 in ULIP Basically, use large-scale multi-modal models to generate all-round corresponding language descriptions for 3D objects, thereby collecting scalable multi-modal pre-training data without any manual annotation, making the pre-training process and the trained model more efficient and enhanced its adaptability.
ULIP-2’s method includes generating multi-angle and different language descriptions for each 3D object, and then using these descriptions to train the model, so that 3D objects, 2D images, and language descriptions can be combined Feature space alignment is consistent.
This framework enables the creation of large tri-modal datasets without manual annotation, thereby fully utilizing the potential of multi-modal pre-training.
ULIP-2 also released the large-scale three-modal data sets generated: "ULIP - Objaverse Triplets" and "ULIP - ShapeNet Triplets".

Some statistical data of two tri-modal datasets
Experimental resultsThe ULIP series has achieved amazing results in multi-modal downstream tasks and fine-tuning experiments on 3D expressions. In particular, the pre-training in ULIP-2 can be achieved without any manual annotation. of.
ULIP-2 achieved significant improvements (74.0% top-1 accuracy) on the downstream zero-shot classification task of ModelNet40; in the real-world ScanObjectNN benchmark, it achieved An overall accuracy of 91.5% was achieved with only 1.4M parameters, marking a breakthrough in scalable multi-modal 3D representation learning without the need for manual 3D annotation.
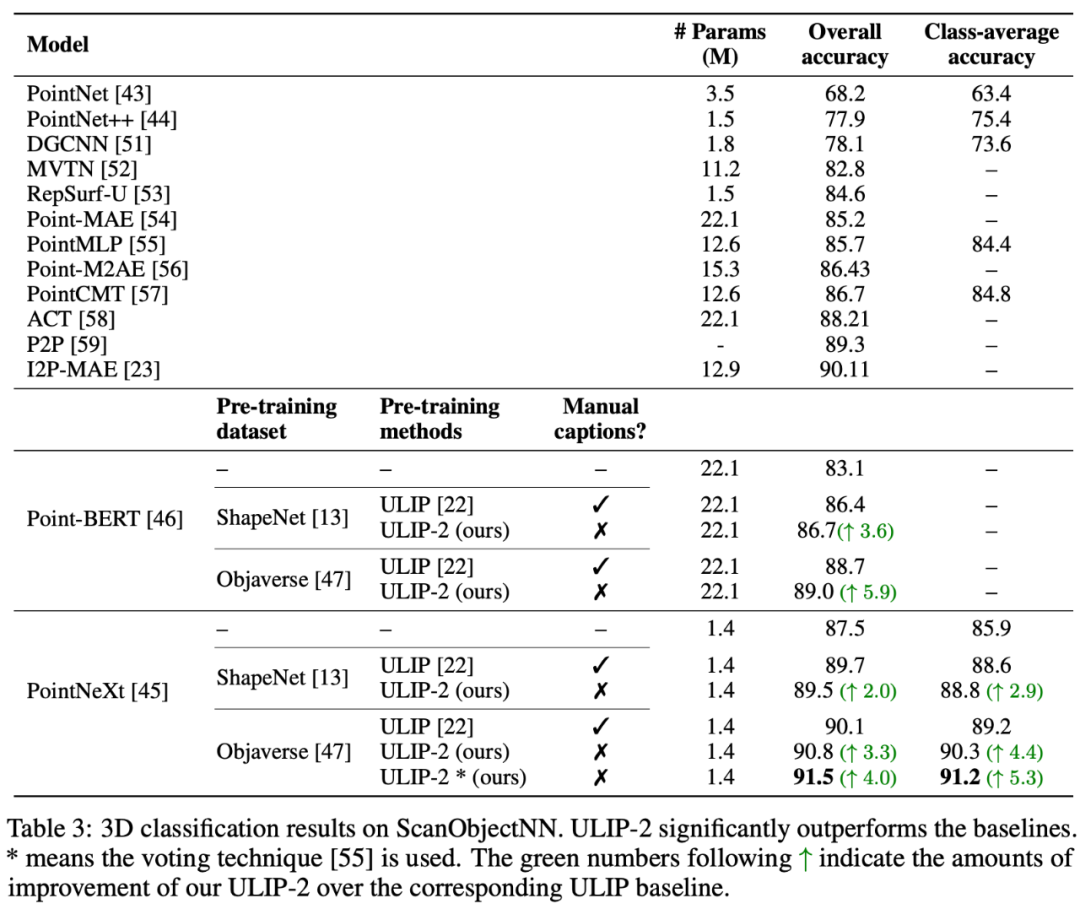
Both papers conducted detailed ablation experiments.
In "ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding", since the pre-training framework of ULIP involves the participation of three modalities, the author used experiments to explore whether it is only Is it better to align two of the modes or to align all three modes? The experimental results are as follows:
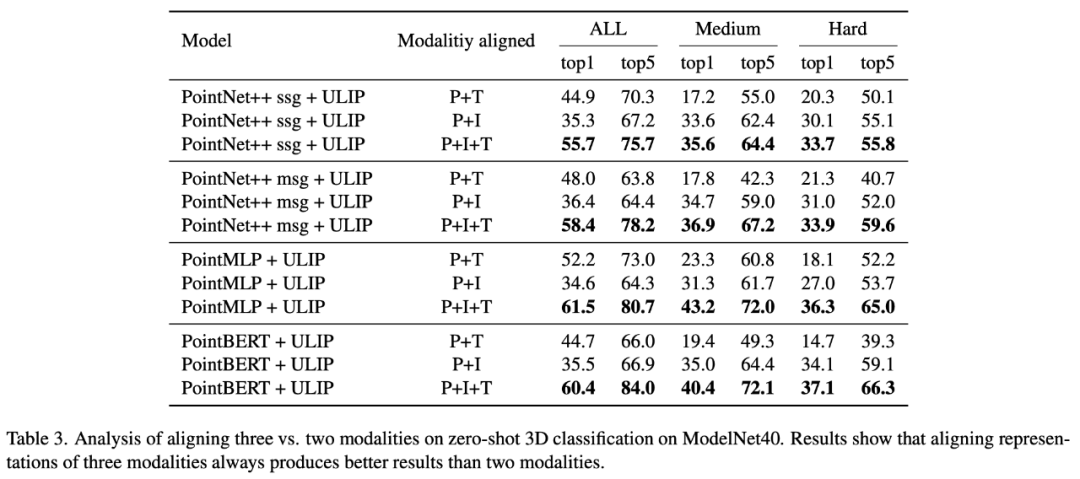
As can be seen from the experimental results, In different 3D backbones, aligning three modalities is better than aligning only two modalities, which also proves the rationality of ULIP's pre-training framework.
In "ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding", the author explores the impact of different large-scale multimodal models on the pre-training framework. The results are as follows:
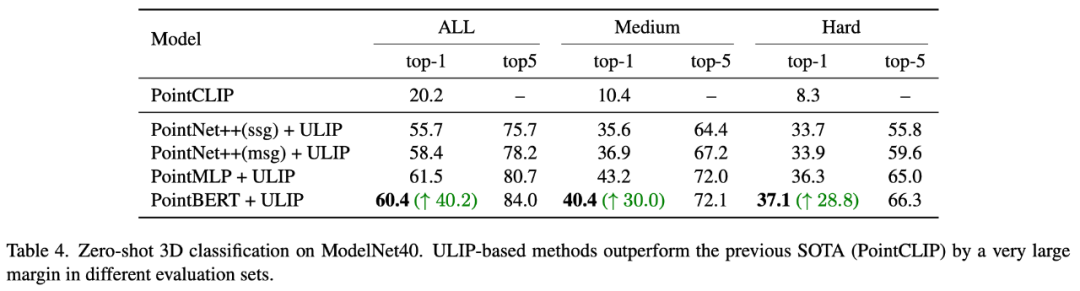
The experimental results can be seen that the effect of ULIP-2 framework pre-training can be upgraded with the use of large-scale multi-modal models. And promotion has a certain degree of growth.
In ULIP-2, the author also explored how using different numbers of views to generate the tri-modal data set would affect the overall pre-training performance. The experimental results are as follows:
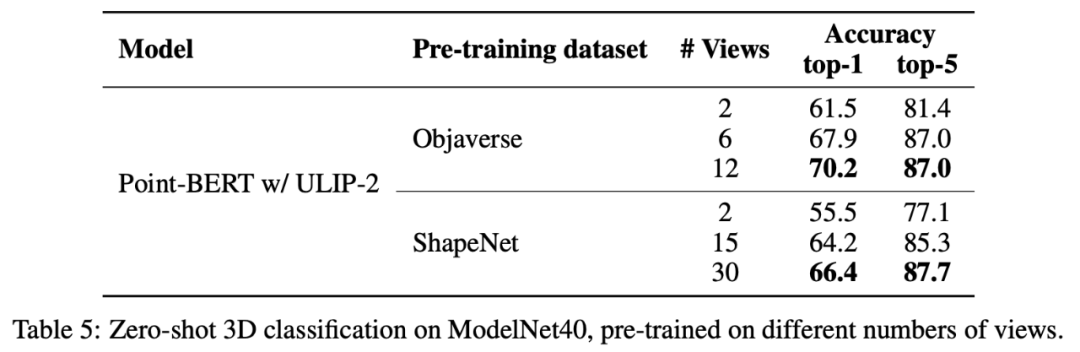
#The experimental results show that as the number of perspectives used increases, the effect of zero-shot classification of the pre-trained model will also increase.
This also supports the point in ULIP-2 that a more comprehensive and diverse language description will have a positive effect on multi-modal pre-training.
In addition, ULIP-2 also explored the impact of language descriptions of different topk sorted by CLIP on multi-modal pre-training. The experimental results are as follows:
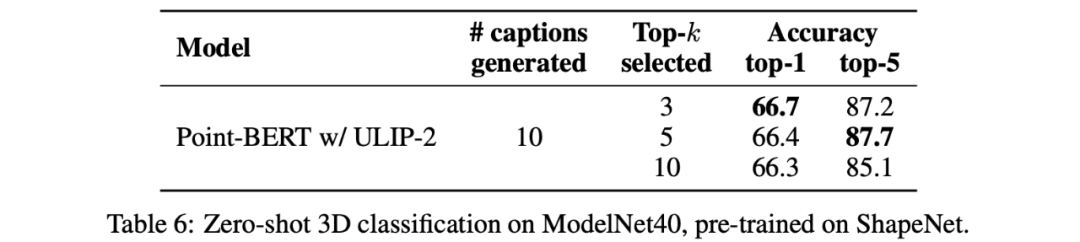
The experimental results show that the ULIP-2 framework has a certain degree of robustness to different topk. Top 5 is used as the default setting in the paper.
Conclusion
The ULIP project (CVPR2023) and ULIP-2 jointly released by Salesforce AI, Stanford University, and the University of Texas at Austin are changing the field of 3D understanding.
ULIP aligns different modalities into a unified space, enhancing 3D feature learning and enabling cross-modal applications.
ULIP-2 is further developed to generate a holistic language description for 3D objects, create and open source a large number of three-modal data sets, and this process does not require manual annotation.
These projects set new benchmarks in 3D understanding, paving the way for a future where machines truly understand our three-dimensional world.
Team
Salesforce AI:
Le Xue (Xue Le), Mingfei Gao (Gao Mingfei), Chen Xing (Xingchen), Ning Yu (Yu Ning), Shu Zhang (张捍), Junnan Li (李俊 Nan), Caiming Xiong (Xiong Caiming), Ran Xu (Xu Ran), Juan Carlos niebles, Silvio Savarese.
Stanford University:
Prof. Silvio Savarese, Prof. Juan Carlos Niebles, Prof. Jiajun Wu(Wu Jiajun).
UT Austin:
Prof. Roberto Martín-Martín.
The above is the detailed content of No need to label data, '3D understanding' enters the era of multi-modal pre-training! ULIP series is fully open source and refreshes SOTA. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1422
52
1316
25
1268
29
1242
24
14
1422
52
1316
25
1268
29
1242
24

 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 Learn about 3D Fluent emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Learn about 3D Fluent emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
You must remember, especially if you are a Teams user, that Microsoft added a new batch of 3DFluent emojis to its work-focused video conferencing app. After Microsoft announced 3D emojis for Teams and Windows last year, the process has actually seen more than 1,800 existing emojis updated for the platform. This big idea and the launch of the 3DFluent emoji update for Teams was first promoted via an official blog post. Latest Teams update brings FluentEmojis to the app Microsoft says the updated 1,800 emojis will be available to us every day
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 Get a virtual 3D wife in 30 seconds with a single card! Text to 3D generates a high-precision digital human with clear pore details, seamlessly connecting with Maya, Unity and other production tools
May 23, 2023 pm 02:34 PM
Get a virtual 3D wife in 30 seconds with a single card! Text to 3D generates a high-precision digital human with clear pore details, seamlessly connecting with Maya, Unity and other production tools
May 23, 2023 pm 02:34 PM
ChatGPT has injected a dose of chicken blood into the AI industry, and everything that was once unthinkable has become basic practice today. Text-to-3D, which continues to advance, is regarded as the next hotspot in the AIGC field after Diffusion (images) and GPT (text), and has received unprecedented attention. No, a product called ChatAvatar has been put into low-key public beta, quickly garnering over 700,000 views and attention, and was featured on Spacesoftheweek. △ChatAvatar will also support Imageto3D technology that generates 3D stylized characters from AI-generated single-perspective/multi-perspective original paintings. The 3D model generated by the current beta version has received widespread attention.
 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Project link written in front: https://nianticlabs.github.io/mickey/ Given two pictures, the camera pose between them can be estimated by establishing the correspondence between the pictures. Typically, these correspondences are 2D to 2D, and our estimated poses are scale-indeterminate. Some applications, such as instant augmented reality anytime, anywhere, require pose estimation of scale metrics, so they rely on external depth estimators to recover scale. This paper proposes MicKey, a keypoint matching process capable of predicting metric correspondences in 3D camera space. By learning 3D coordinate matching across images, we are able to infer metric relative
 Paint 3D in Windows 11: Download, Installation, and Usage Guide
Apr 26, 2023 am 11:28 AM
Paint 3D in Windows 11: Download, Installation, and Usage Guide
Apr 26, 2023 am 11:28 AM
When the gossip started spreading that the new Windows 11 was in development, every Microsoft user was curious about how the new operating system would look like and what it would bring. After speculation, Windows 11 is here. The operating system comes with new design and functional changes. In addition to some additions, it comes with feature deprecations and removals. One of the features that doesn't exist in Windows 11 is Paint3D. While it still offers classic Paint, which is good for drawers, doodlers, and doodlers, it abandons Paint3D, which offers extra features ideal for 3D creators. If you are looking for some extra features, we recommend Autodesk Maya as the best 3D design software. like
 'The most important machine never built', Alan Turing and the Turing Machine
Jun 25, 2023 pm 07:42 PM
'The most important machine never built', Alan Turing and the Turing Machine
Jun 25, 2023 pm 07:42 PM
Computing is a familiar concept that most of us understand intuitively. Let's take the function f(x)=x+3 as an example. When x is 3, f(3)=3+3. The answer is 6, very simple. Obviously, this function is computable. But some functions are not that simple, and determining whether they can be calculated is not trivial, meaning they may never lead to a final answer. In 1928, German mathematicians David Hilbert and Wilhelm Ackermann proposed a problem called Entscheidungsproblem (ie "decision problem"). Over time, the question they ask will lead to possible
