
 Technology peripherals
AI
Google uses AI to break the ten-year ranking algorithm seal. It is executed trillions of times every day, but netizens say it is the most unrealistic research?
Technology peripherals
AI
Google uses AI to break the ten-year ranking algorithm seal. It is executed trillions of times every day, but netizens say it is the most unrealistic research?
Google uses AI to break the ten-year ranking algorithm seal. It is executed trillions of times every day, but netizens say it is the most unrealistic research?

Arrangement | Nuka-Cola, Chu Xingjuan
Friends who have taken basic computer science courses must have personally designed a sorting algorithm - that is, using code to rearrange the items in an unordered list in ascending or descending order. It's an interesting challenge, and there are many possible ways to do it. A lot of time has been invested in figuring out how to accomplish sorting tasks more efficiently.
As a basic operation, most programming languages have built-in sorting algorithms in their standard libraries. There are many different sorting techniques and algorithms used in codebases around the world to organize large amounts of data online, but at least as far as the C libraries used with the LLVM compiler are concerned, the sorting code has not changed in more than a decade.
Recently, Google's DeepMind AI team has now developed a reinforcement learning tool, AlphaDev, that can develop extremely optimized algorithms without the need for pre-training with human code examples. Today, these algorithms have been integrated into the LLVM standard C sorting library, marking the first time in more than a decade that this part of the sorting library has changed, and the first time that algorithms designed with reinforcement learning have been added to the library.
Think of the programming process as a "game"
DeepMind systems are often able to discover solutions to problems that humans have never thought of because it does not require any prior exposure to human game strategies. DeepMind relies entirely on self-confrontation when learning from experience, so there are sometimes blind spots that can be exploited by humans.
This method is actually very similar to programming. Large language models are able to write efficient code because they have seen numerous examples of human code. But because of this, it is difficult for language models to produce things that humans have not done before. If we want to further optimize ubiquitous existing algorithms (such as sorting functions), it will be difficult to break through the constraints of inherent ideas by continuing to rely on existing human code. So how can AI find truly new directions?
DeepMind researchers used methods similar to chess and Go to optimize code tasks, turning them into single-player "jigsaw puzzles." AlphaDev Systems has developed an x86 assembly algorithm that treats the running delay of the code as a score, and strives to minimize the score while ensuring that the code can run smoothly. AlphaDev has gradually mastered the art of writing efficient and concise code, thanks to the application of reinforcement learning.
AlphaDev is based on AlphaZero. DeepMind is well-known for developing AI software that can learn game rules on its own. This line of thinking has proven to be very effective and has successfully solved many game problems, such as chess, Go and "StarCraft". While the specifics vary depending on the game you play, DeepMind's software does learn over repeated play, continually exploring ways to maximize your score.
The two core components of AlphaDev are learning algorithms and representation functions.
Using DRL combined with random search optimization algorithms to assemble games is a method of AlphaDev learning algorithm. The main learning algorithm in AlphaDev is an extension of AlphaZero 33, a well-known DRL algorithm in which a neural network is trained to guide the search through the game.
This function is used to monitor the overall performance during code development, covering the general structure of the algorithm and the use of x86 registers and memory. The system will gradually introduce assembly instructions, added independently when making selections using a Monte Carlo tree search method borrowed from the game system. The tree structure allows the system to quickly narrow the search to a limited area containing a large number of potential instructions, while the Monte Carlo method selects specific instructions from this branching area with a degree of randomness. Note that the "instructions" referred to here are operations such as selecting specific registers to create a valid and complete assembly. )
The system then evaluates the latency and validity status of the assembly code and gives a score, which is compared with the previous score. Through reinforcement learning, the system is able to record the work information of different branches in the tree structure for a given program state. Over time, the system becomes familiar with how to win the game (successful completion of the sort) with the highest score (representing the lowest latency). The primary representation function of AlphaDev is based on Transformers..
To train AlphaDev to discover new algorithms, AlphaDev in each round observes the algorithm it generates and the information contained in the central processing unit (CPU), then completes the game by selecting instructions to add to the algorithm. AlphaDev must efficiently search a large number of possible instruction combinations to find an algorithm that can be sequenced and also be faster than the current best algorithm, while the agent model can be rewarded based on the algorithm's correctness and latency.
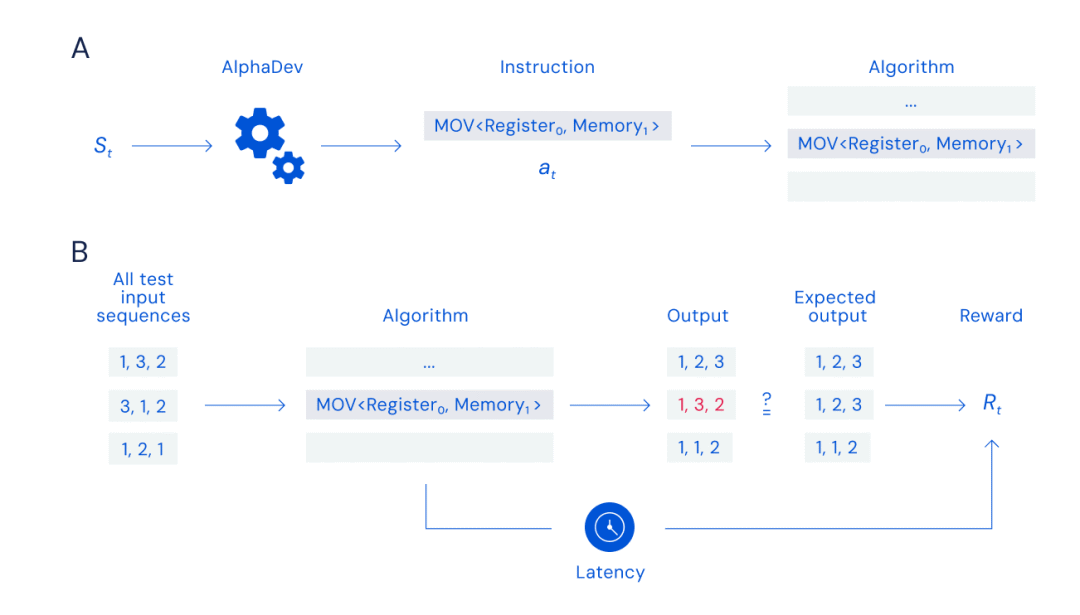
Picture A: Assembly game, Picture B: Reward calculation
Finally, AlphaDev discovered new sorting algorithms that can improve the LLVM libc sorting library: for shorter sequences, the sorting library is 70% faster; for sequences of more than 250,000 elements, the speed is improved About 1.7%.
Specifically, the innovation of this algorithm mainly lies in two instruction sequences: AlphaDev Swap Move (swap move) and AlphaDev Copy Move (copy move). Through these two instructions, AlphaDev skips a step and performs a A way to connect items that may seem wrong but is actually a shortcut.
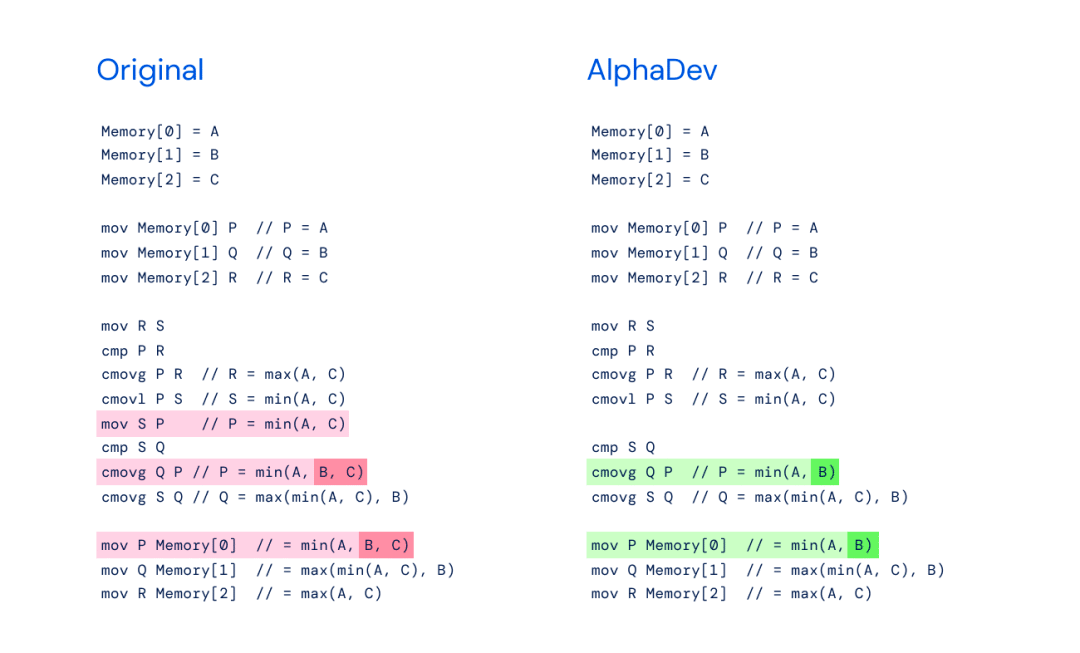
Left: Original sort3 implementation with min(A,B,C).
Right picture: AlphaDev Swap Move - AlphaDev finds that you only need min(A,B).
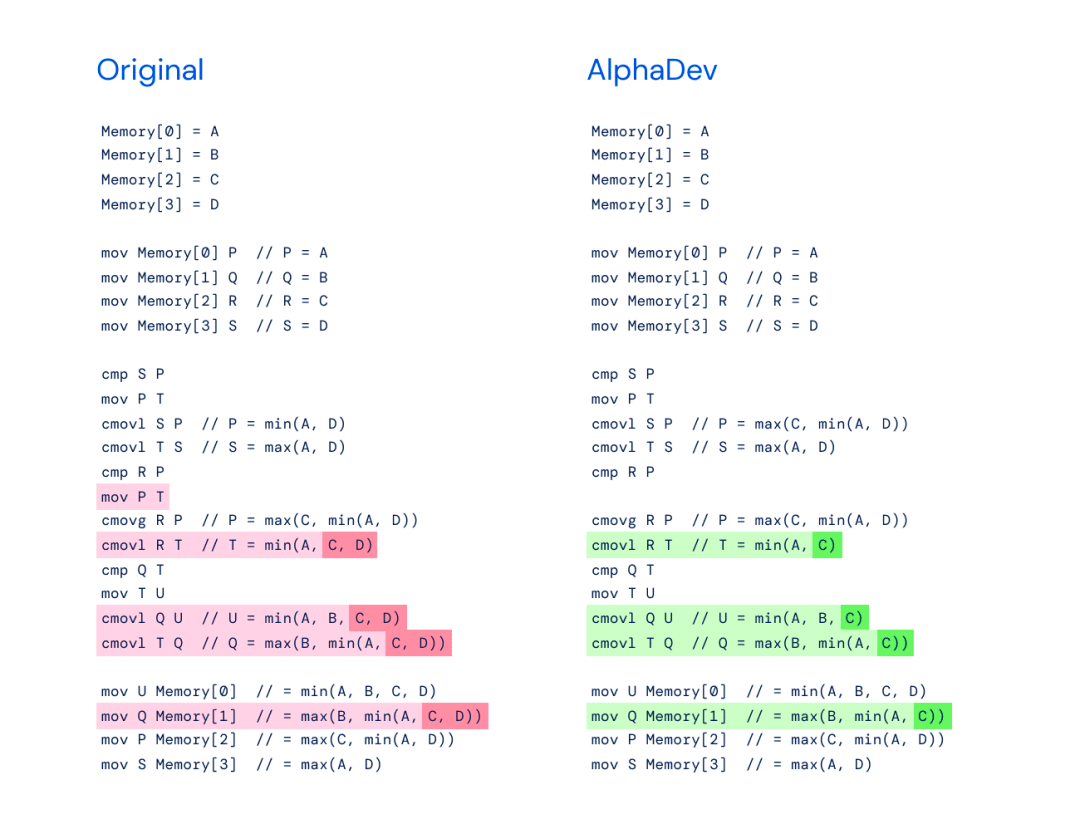
Left: Original implementation of max (B, min (A, C)) for a larger sorting algorithm that sorts eight elements.
Right: AlphaDev found that only max (B, min (A, C)) is needed when using its copy move.
The main advantage of this system is that its training process does not require any code examples. Instead, the system autonomously generates code examples and then evaluates them. In the process, it gradually masters information about effective sequencing of instruction combinations.
From sorting to hashing
After discovering a faster sorting algorithm, DeepMind tested whether AlphaDev could generalize and improve on a different computer science algorithm: hashing.
Hashing is a fundamental algorithm used in computing to retrieve, store, and compress data. Just like a librarian who uses a classification system to locate a particular book, hashing algorithms help users know what they are looking for and where to find it. These algorithms take data for a specific key (e.g. username "Jane Doe") and hash it - a process that converts the raw data into a unique string (e.g. 1234ghfty). This hashing algorithm is used to quickly retrieve data related to a key, avoiding the need to search through the entire data.
DeepMind applies AlphaDev to one of the most commonly used hashing algorithms in data structures in an attempt to discover faster algorithms. AlphaDev found that the algorithm was 30% faster when the hash function used data in the 9-16 byte range.
This year, AlphaDev’s new hashing algorithm was released into the open source Abseil library, available to millions of developers around the world, and the library is now used trillions of times every day.
Actually usable code
Sorting mechanisms in complex programs can handle large collections of arbitrary entries. But at the standard library level, this capability comes from a series of highly restricted specific functions. Each of these functions can only handle one or a few situations. For example, some individual algorithms can only sort 3, 4, or 5 entries. We can sort any number of entries using a set of functions, but we can only sort up to 4 entries per function call.
AlphaDev has been implemented by DeepMind on each function, but its actual operating methods differ significantly.. It is possible to write code without branching statements to handle functions that handle a specific number of entries, i.e. execute different code depending on the state of the variable. So code performance tends to be inversely proportional to the number of instructions involved.
AlphaDev has successfully reduced the number of instructions by one each in sort-3, sort-5 and sort-8, and even more in sort-6 and sort-7. No way to improve the existing code could be found only on sort-4. Repeated tests on real systems show that fewer instructions do improve performance.
To sort a variable number of entries, you need to include branch statements in your code, and different processors have different numbers of components dedicated to handling these branches.
The researchers used 100 different computing devices when evaluating this scenario. AlphaDev has also found ways to further squeeze performance in such scenarios. Let's take a function that sorts up to 4 items at a time as an example to see how it operates.
In the current implementation of the C library, the code needs to perform a series of tests to confirm how many entries need to be sorted, and then call the corresponding sorting function based on the number of entries.
The modified code of AlphaDev adopts a more "magical" idea: it first tests whether there are 2 entries, and if so, calls the corresponding function to sort immediately. If the number is greater than 2, the code will sort the first 3 entries first. This way if there are indeed only 3 entries, the sorted results are returned. Since there are actually 4 items to sort, AlphaDev will run specialized code to insert the 4th item into the appropriate position among the first 3 items that have been sorted in a very efficient manner.
This approach sounds a bit weird, but it turns out that its performance is always better than the existing code.
Since AlphaDev does generate more efficient code, the research team plans to re-merge these results into the LLVM standard C library. But the problem is that the code is in assembly format, not C. Therefore, they need to work backwards to find the C code that generates the same assembly.
A rewritten version of this sentence: Now, this part of the code has been integrated into the LLVM toolchain and updated for the first time in nearly ten years. Researchers estimate that new code generated by AlphaDev is executed trillions of times every day.
Conclusion
This is great! We programmers learned this basic sorting task long ago, but now we're 70% faster. There’s something very exciting about AI in algorithms and libraries that we all rely on delivering significant speedups. "Some developers expressed excitement about the results of Google DeepMind.
But some developers did not buy it: "Quite disappointing...1.7% improvement? 70% of the sequence of 5 elements? Probably the most unpopular and most unrealistic applied research..." There are also developers The author said: "Isn't it a bit misleading to say that a new algorithm has been discovered? It seems more like algorithm optimization. It's still cool anyway."
Reference link:
https://arstechnica.com/science/2023/06/googles-deepmind-develops-a-system-that-writes-efficient-algorithms/
https://www.deepmind.com/blog/alphadev-discovers-faster-sorting-algorithms
Depth: Why hasn’t a giant like Snowflake emerged in China’s database field?
The most bizarre collapse in seventeen years! In order to prevent OpenAI and Google from getting data for free, Reddit charged huge API fees and defamed developers, causing large-scale protests in the community
"Stealing" code to build a company, falsifying academic qualifications, earning $100 million in 6 days but not paying wages, this AI unicorn CEO personally responded after being repeatedly questioned
The above is the detailed content of Google uses AI to break the ten-year ranking algorithm seal. It is executed trillions of times every day, but netizens say it is the most unrealistic research?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
A complete guide to viewing GitLab logs under CentOS system This article will guide you how to view various GitLab logs in CentOS system, including main logs, exception logs, and other related logs. Please note that the log file path may vary depending on the GitLab version and installation method. If the following path does not exist, please check the GitLab installation directory and configuration files. 1. View the main GitLab log Use the following command to view the main log file of the GitLabRails application: Command: sudocat/var/log/gitlab/gitlab-rails/production.log This command will display product
 How to choose the PyTorch version on CentOS
Apr 14, 2025 pm 06:51 PM
How to choose the PyTorch version on CentOS
Apr 14, 2025 pm 06:51 PM
When installing PyTorch on CentOS system, you need to carefully select the appropriate version and consider the following key factors: 1. System environment compatibility: Operating system: It is recommended to use CentOS7 or higher. CUDA and cuDNN:PyTorch version and CUDA version are closely related. For example, PyTorch1.9.0 requires CUDA11.1, while PyTorch2.0.1 requires CUDA11.3. The cuDNN version must also match the CUDA version. Before selecting the PyTorch version, be sure to confirm that compatible CUDA and cuDNN versions have been installed. Python version: PyTorch official branch
