
 Technology peripherals
AI
Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.
Technology peripherals
AI
Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.
Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.

Generative AI has taken the artificial intelligence community by storm. Both individuals and enterprises have begun to be keen on creating related modal conversion applications, such as Vincent pictures, Vincent videos, Vincent music, etc.
Recently, several researchers from scientific research institutions such as ServiceNow Research and LIVIA have tried to generate charts in papers based on text descriptions. To this end, they proposed a new method of FigGen, and the related paper was also included as a Tiny Paper in ICLR 2023.
 Picture
Picture
Paper address: https://arxiv.org/pdf/2306.00800.pdf
Some people may ask, what is so difficult about generating the charts in the paper? How does this help scientific research?
Scientific research chart generation helps to disseminate research results in a concise and easy-to-understand way, and automatically generating charts can bring many advantages to researchers, such as saving time and energy without spending a lot of money. Take the effort to design a chart from scratch. In addition, designing visually appealing and easy-to-understand figures can make the paper accessible to more people.
However, generating diagrams also faces some challenges. It needs to represent complex relationships between discrete components such as boxes, arrows, and text. Unlike generating natural images, concepts in paper graphs may have different representations and require fine-grained understanding. For example, generating a neural network graph will involve an ill-posed problem with high variance.
Therefore, the researchers in this paper trained a generative model on a dataset of paper diagram pairs to capture the relationship between diagram components and the corresponding text in the paper. This requires dealing with varying lengths and highly technical text descriptions, different chart styles, image aspect ratios, and text rendering fonts, sizes, and orientation issues.
In the specific implementation process, the researchers were inspired by recent text-to-image results, used the diffusion model to generate charts, and proposed a potential diffusion to generate scientific research charts from text descriptions. Model - FigGen.
What are the unique features of this diffusion model? Let's move on to the details.
Models and Methods
The researchers trained a latent diffusion model from scratch.
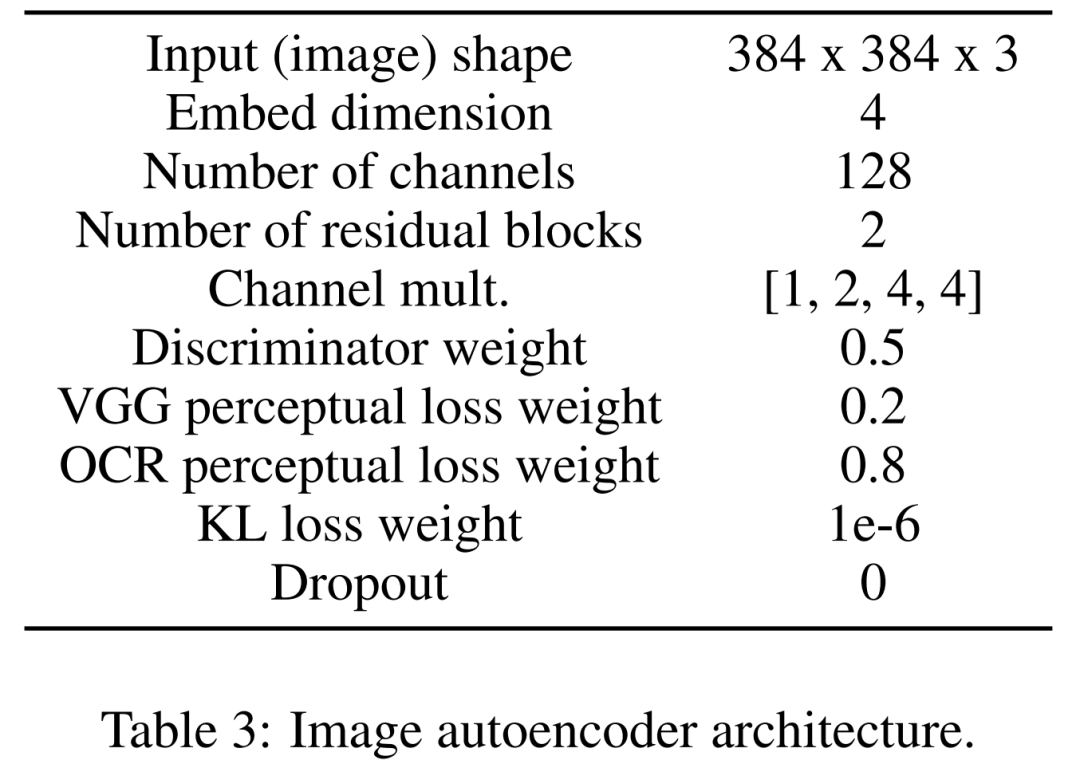
First learn an image autoencoder to map images into compressed latent representations. The image encoder uses KL loss and OCR perceptual loss. The text encoder used for conditioning is learned end-to-end in the training of this diffusion model. Table 3 below shows the detailed parameters of the image autoencoder architecture.
The diffusion model then interacts directly in the latent space, performing data-corrupted forward scheduling while learning to exploit temporal and textual conditional denoising U-Net to recover from the process.
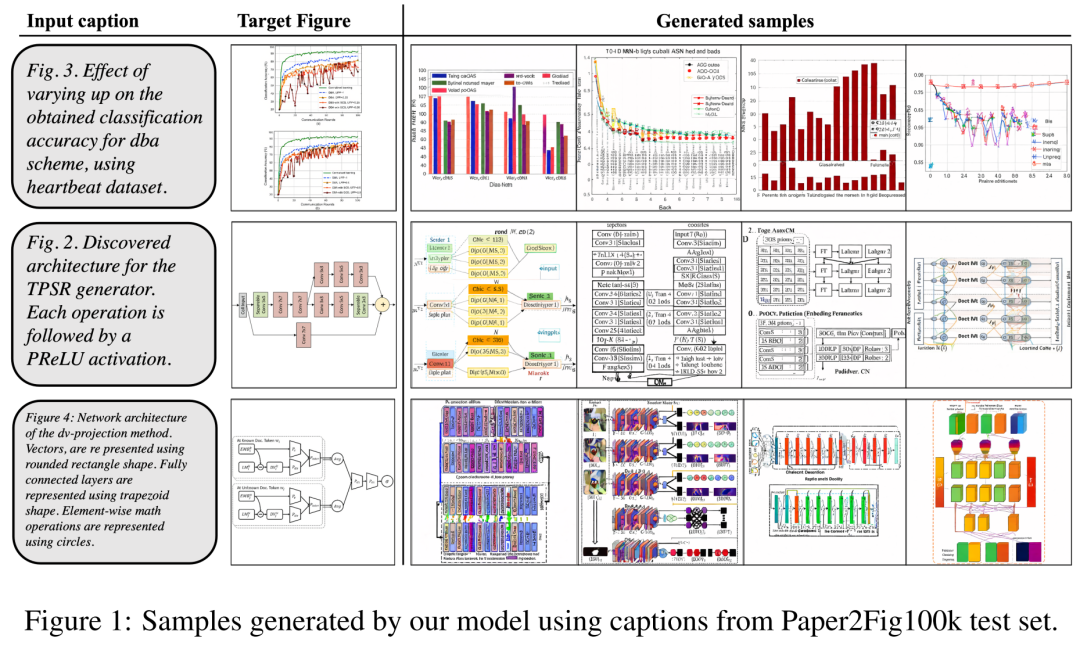
## As for the data set, the researchers used Paper2Fig100k, which consists of graph-text pairs in the paper and contains 81,194 training samples and 21,259 validation samples. Figure 1 below is an example of a diagram generated using text descriptions in the Paper2Fig100k test set.
Model details
First the images Encoder. In the first stage, the image autoencoder learns a mapping from pixel space to a compressed latent representation, making diffusion model training faster. The image encoder also needs to learn to map the latent image back to pixel space without losing important details of the diagram (such as text rendering quality).
To this end, the researchers defined a convolutional codec with a bottleneck that downsamples the image at factor f=8. The encoder is trained to minimize KL loss, VGG-aware loss, and OCR-aware loss with Gaussian distribution.
Second is the text encoder. Researchers have found that general-purpose text encoders are not suitable for graph generation tasks. Therefore they define a Bert transformer trained from scratch in the diffusion process, which uses an embedding channel of size 512, which is also the embedding size that regulates the cross-attention layers of U-Net. The researchers also explored changes in the number of transformer layers under different settings (8, 32, and 128).
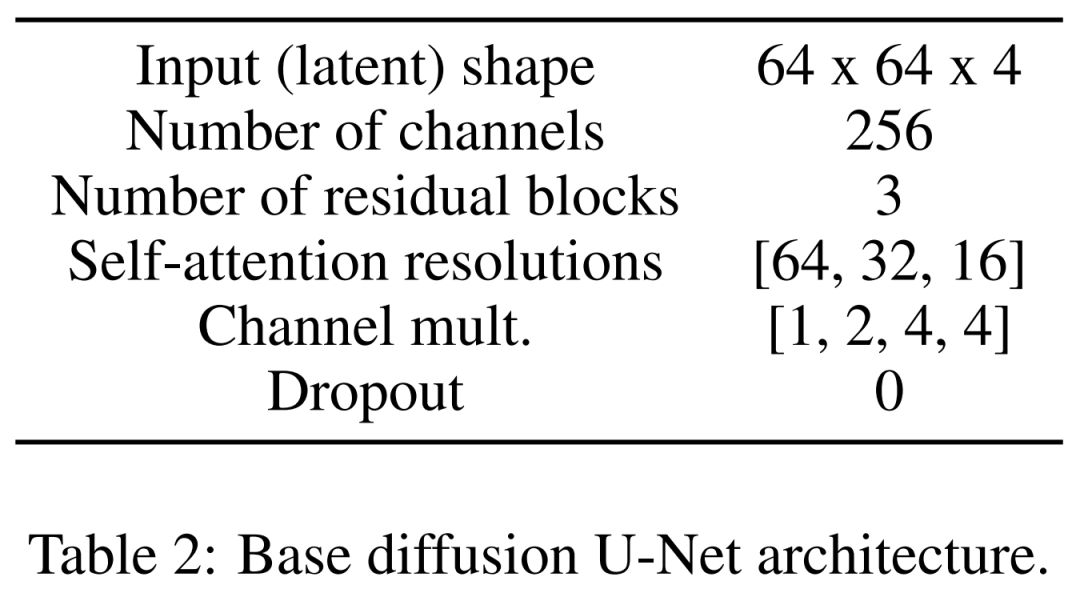
Finally, there is the latent diffusion model. Table 2 below shows the network architecture of U-Net. We perform the diffusion process on a perceptually equivalent latent representation of the image, where the input size of the image is compressed to 64x64x4, making the diffusion model faster. They defined 1,000 diffusion steps and linear noise scheduling.
##Training details
To train the image autoencoder, the researchers used an Adam optimizer with an effective batch size of 4 samples and a learning rate of 4.5e−6, during which four 12GB NVIDIA V100 graphics cards were used. To achieve training stability, they warmup the model in 50k iterations without using the discriminator.
For training the latent diffusion model, the researchers also used the Adam optimizer, which has an effective batch size of 32 and a learning rate of 1e−4. When training the model on the Paper2Fig100k dataset, they used eight 80GB NVIDIA A100 graphics cards.
Experimental results
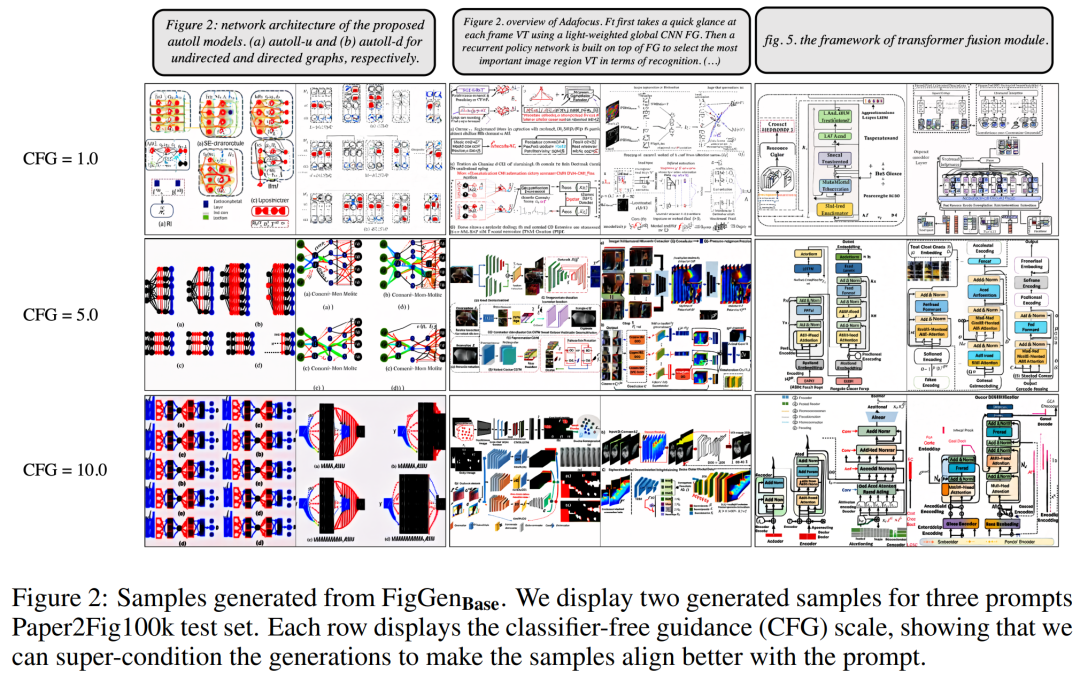
In the generation process, the researcher used a DDIM sampler with 200 steps and generated 12,000 samples to calculate FID, IS, KID and OCR-SIM1. Robust use of classifier-free guidance (CFG) to test hyperconditioning.
Table 1 below shows the results for different text encoders. It can be seen that large text encoders produce the best qualitative results and condition generation can be improved by increasing the size of the CFG. Although the qualitative samples are not of sufficient quality to solve the problem, FigGen has grasped the relationship between text and images.
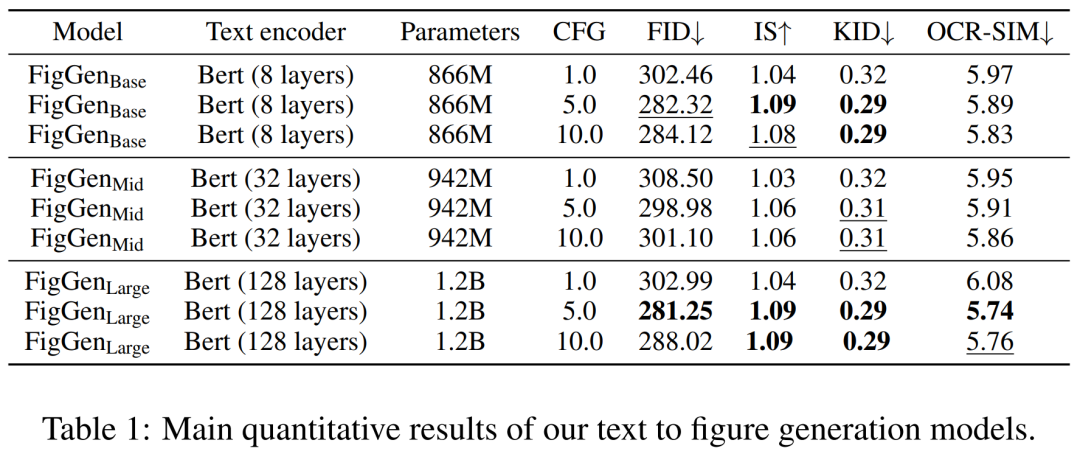
Figure 2 below shows the additional FigGen samples generated when adjusting the Classifier-Free Guidance (CFG) parameters. The researchers observed that increasing the size of the CFG, which was also demonstrated quantitatively, led to improvements in image quality.
 Pictures
Pictures
Figure 3 below shows more generation examples from FigGen. Pay attention to the variation in length between samples, as well as the technical level of the text description, which will closely affect the difficulty of the model to correctly generate understandable images.
 Picture
Picture
However, the researchers also admitted that although these generated charts cannot provide practical help to the authors of the paper, they still It can be regarded as a promising direction of exploration.
For more research details, please refer to the original paper.
The above is the detailed content of Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
There are many reasons why MySQL startup fails, and it can be diagnosed by checking the error log. Common causes include port conflicts (check port occupancy and modify configuration), permission issues (check service running user permissions), configuration file errors (check parameter settings), data directory corruption (restore data or rebuild table space), InnoDB table space issues (check ibdata1 files), plug-in loading failure (check error log). When solving problems, you should analyze them based on the error log, find the root cause of the problem, and develop the habit of backing up data regularly to prevent and solve problems.
 Can mysql return json
Apr 08, 2025 pm 03:09 PM
Can mysql return json
Apr 08, 2025 pm 03:09 PM
MySQL can return JSON data. The JSON_EXTRACT function extracts field values. For complex queries, you can consider using the WHERE clause to filter JSON data, but pay attention to its performance impact. MySQL's support for JSON is constantly increasing, and it is recommended to pay attention to the latest version and features.
 Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Detailed explanation of database ACID attributes ACID attributes are a set of rules to ensure the reliability and consistency of database transactions. They define how database systems handle transactions, and ensure data integrity and accuracy even in case of system crashes, power interruptions, or multiple users concurrent access. ACID Attribute Overview Atomicity: A transaction is regarded as an indivisible unit. Any part fails, the entire transaction is rolled back, and the database does not retain any changes. For example, if a bank transfer is deducted from one account but not increased to another, the entire operation is revoked. begintransaction; updateaccountssetbalance=balance-100wh
 Master SQL LIMIT clause: Control the number of rows in a query
Apr 08, 2025 pm 07:00 PM
Master SQL LIMIT clause: Control the number of rows in a query
Apr 08, 2025 pm 07:00 PM
SQLLIMIT clause: Control the number of rows in query results. The LIMIT clause in SQL is used to limit the number of rows returned by the query. This is very useful when processing large data sets, paginated displays and test data, and can effectively improve query efficiency. Basic syntax of syntax: SELECTcolumn1,column2,...FROMtable_nameLIMITnumber_of_rows;number_of_rows: Specify the number of rows returned. Syntax with offset: SELECTcolumn1,column2,...FROMtable_nameLIMIToffset,number_of_rows;offset: Skip
 How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
MySQL database performance optimization guide In resource-intensive applications, MySQL database plays a crucial role and is responsible for managing massive transactions. However, as the scale of application expands, database performance bottlenecks often become a constraint. This article will explore a series of effective MySQL performance optimization strategies to ensure that your application remains efficient and responsive under high loads. We will combine actual cases to explain in-depth key technologies such as indexing, query optimization, database design and caching. 1. Database architecture design and optimized database architecture is the cornerstone of MySQL performance optimization. Here are some core principles: Selecting the right data type and selecting the smallest data type that meets the needs can not only save storage space, but also improve data processing speed.
 The primary key of mysql can be null
Apr 08, 2025 pm 03:03 PM
The primary key of mysql can be null
Apr 08, 2025 pm 03:03 PM
The MySQL primary key cannot be empty because the primary key is a key attribute that uniquely identifies each row in the database. If the primary key can be empty, the record cannot be uniquely identifies, which will lead to data confusion. When using self-incremental integer columns or UUIDs as primary keys, you should consider factors such as efficiency and space occupancy and choose an appropriate solution.
 Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
It is impossible to view MongoDB password directly through Navicat because it is stored as hash values. How to retrieve lost passwords: 1. Reset passwords; 2. Check configuration files (may contain hash values); 3. Check codes (may hardcode passwords).
 Monitor MySQL and MariaDB Droplets with Prometheus MySQL Exporter
Apr 08, 2025 pm 02:42 PM
Monitor MySQL and MariaDB Droplets with Prometheus MySQL Exporter
Apr 08, 2025 pm 02:42 PM
Effective monitoring of MySQL and MariaDB databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Prometheus MySQL Exporter is a powerful tool that provides detailed insights into database metrics that are critical for proactive management and troubleshooting.
