
 Technology peripherals
AI
For large AI models, Tencent Cloud fully disclosed its self-developed Xingmai high-performance computing network for the first time
Technology peripherals
AI
For large AI models, Tencent Cloud fully disclosed its self-developed Xingmai high-performance computing network for the first time
For large AI models, Tencent Cloud fully disclosed its self-developed Xingmai high-performance computing network for the first time

The outbreak of AIGC not only brings computing power challenges, but also places unprecedented demands on the network.
On June 26, Tencent Cloud fully disclosed its self-developed Xingmai high-performance computing network for the first time: Xingmai network has the industry’s highest 3.2T communication bandwidth, which can increase GPU utilization by 40% and save 30%~60%. The model training cost brings 10 times communication performance improvement to large AI models. Tencent Cloud's new generation computing cluster HCC can support a huge computing scale of more than 100,000 cards.
Wang Yachen, Vice President of Tencent Cloud, said: "Xingmai Network is born for large models. The high-performance network services it provides with large bandwidth, high utilization and zero packet loss will help break through the computing power bottleneck and further Release the potential of AI, comprehensively improve the training efficiency of enterprise large models, and accelerate the iterative upgrade and implementation of large model technology on the cloud."
Build a high-performance network dedicated to large models and increase GPU utilization by 40%
The popularity of AIGC has brought about a surge in the number of large AI model parameters from hundreds of millions to trillions. In order to support large-scale training of massive data, a large number of servers form a computing cluster through high-speed networks and are interconnected to complete training tasks together.
On the contrary, the larger the GPU cluster, the greater the additional communication loss. A large cluster does not mean large computing power. The era of AI large models has brought significant challenges to the network, including high bandwidth requirements, high utilization, and information losslessness.
Traditional low-speed network bandwidth cannot satisfy large models with hundreds of billions or trillions of parameters. During the training process, the proportion of communication can be as high as 50%. At the same time, traditional network protocols can easily lead to network congestion, high latency and packet loss, and only 0.1% of network packet loss may lead to 50% loss of computing power, ultimately resulting in a serious waste of computing power resources.
Based on comprehensive self-research capabilities, Tencent Cloud has carried out software and hardware upgrades and innovations in switches, communication protocols, communication libraries, and operation systems, and is the first to launch the industry's leading large-model dedicated high-performance network - Xingmai network.
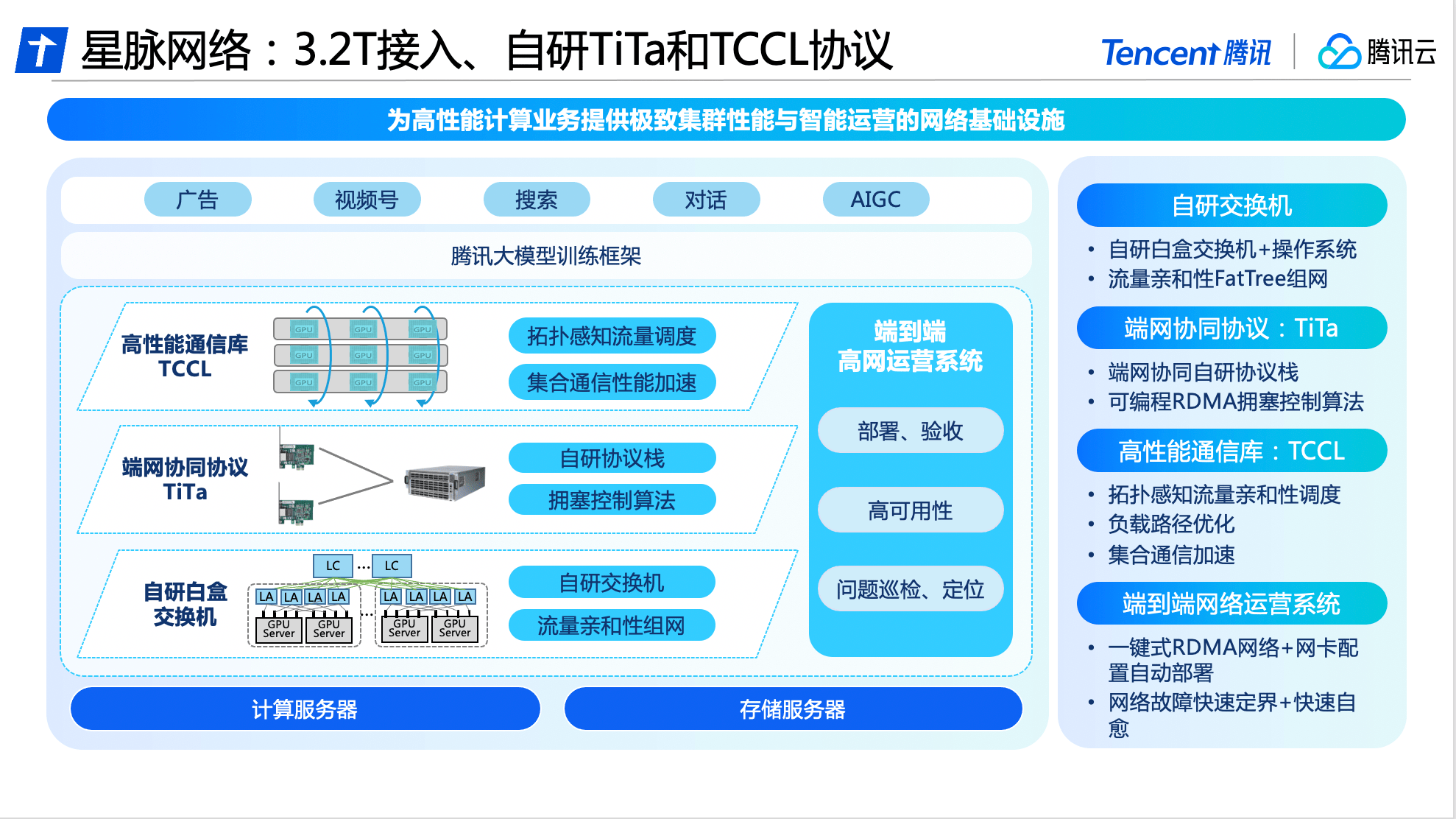
In terms of hardware, Xingmai Network is based on Tencent's network research and development platform and uses all self-developed equipment to build an interconnection base to achieve automated deployment and configuration.
In terms of software, Tencent Cloud’s self-developed TiTa network protocol adopts advanced congestion control and management technology, which can monitor and adjust network congestion in real time, meet the communication needs between a large number of server nodes, and ensure smooth data exchange and delay. Low, achieving zero packet loss under high load, making cluster communication efficiency more than 90%.
In addition, Tencent Cloud also designed a high-performance collective communication library TCCL for Xingmai Network and integrated it into customized solutions, enabling the system to realize microsecond-level network quality perception. By using a dynamic scheduling mechanism to reasonably allocate communication channels, training interruptions due to network problems can be effectively avoided, and communication delays can be reduced by 40%.
The availability of the network also determines the computing stability of the entire cluster. In order to ensure the high availability of Xingmai network, Tencent Cloud has developed an end-to-end full-stack network operation system. Through the end-network three-dimensional monitoring and intelligent positioning system, end-network problems are automatically delimited and analyzed, so that the overall fault troubleshooting time can be shortened. The day level is reduced to the minute level. After improvements, the overall deployment time of the large-scale model training system has been shortened to 4.5 days, ensuring 100% accuracy of the basic configuration.
After three generations of technological evolution, we have deeply cultivated and researched the integration of software and hardware
Behind the all-round upgrade of Xingmai Network is the result of three generations of technological evolution of Tencent’s data center network.
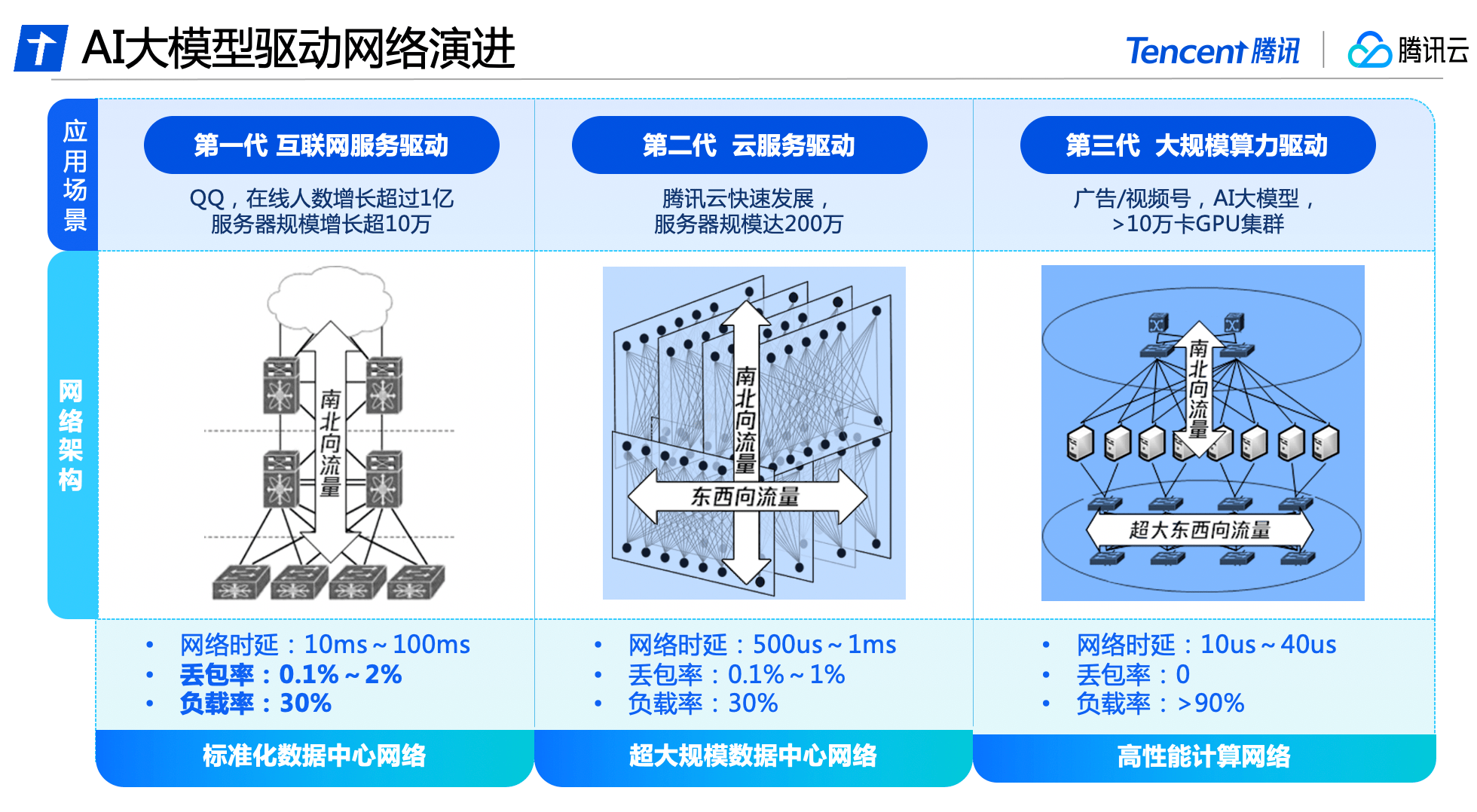
In the early days of Tencent's development, data center network traffic mainly consisted of north-south traffic for users to access data center servers. The network architecture was mainly based on access, aggregation, and egress. At this stage, commercial network equipment was mainly used to build a standardized data center network, supporting the growth of QQ online users by more than 100 million and the scale of servers by more than 100,000.
With the rise of big data and cloud computing, east-west traffic between servers has gradually increased, and cloud tenants have created virtualization and isolation requirements for the network. The data center network architecture has gradually evolved into a cloud network architecture that carries both north-south and east-west traffic. Tencent Cloud has built a fully self-developed network equipment and management system to create an ultra-large-scale data center network with nearly 2 million servers.
Tencent Cloud was the first to launch a high-performance computing network in China to meet the needs of large AI models, and adopted a separation architecture for east-west and north-south traffic. It has built an independent network architecture with ultra-large bandwidth that meets the characteristics of AI training traffic, and cooperates with self-developed software and hardware facilities to achieve independent controllability of the entire system and meet the new needs of super computing power for network performance.
Recently, Tencent Cloud released a new generation of HCC high-performance computing cluster, which is based on the Xingmai high-performance network. It can achieve 3.2T ultra-high interconnection bandwidth, and the computing performance is 3 times higher than the previous generation. It is a large AI model. Training to build a reliable and high-performance network base.
In the future, Tencent Cloud will continue to invest in the research and development of basic technologies to provide strong technical support for the digital and intelligent transformation of all walks of life.
The above is the detailed content of For large AI models, Tencent Cloud fully disclosed its self-developed Xingmai high-performance computing network for the first time. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Large AI models are very expensive and only big companies and the super rich can play them successfully
Apr 15, 2023 pm 07:34 PM
Large AI models are very expensive and only big companies and the super rich can play them successfully
Apr 15, 2023 pm 07:34 PM
The ChatGPT fire has led to another wave of AI craze. However, the industry generally believes that when AI enters the era of large models, only large companies and super-rich companies can afford AI, because the creation of large AI models is very expensive. The first is that it is computationally expensive. Avi Goldfarb, a marketing professor at the University of Toronto, said: "If you want to start a company, develop a large language model yourself, and calculate it yourself, the cost is too high. OpenAI is very expensive, costing billions of dollars." Rental computing certainly will It's much cheaper, but companies still have to pay expensive fees to AWS and other companies. Secondly, data is expensive. Training models requires massive amounts of data, sometimes the data is readily available and sometimes not. Data like CommonCrawl and LAION can be free
 How to build an AI-oriented data governance system?
Apr 12, 2024 pm 02:31 PM
How to build an AI-oriented data governance system?
Apr 12, 2024 pm 02:31 PM
In recent years, with the emergence of new technology models, the polishing of the value of application scenarios in various industries and the improvement of product effects due to the accumulation of massive data, artificial intelligence applications have radiated from fields such as consumption and the Internet to traditional industries such as manufacturing, energy, and electricity. The maturity of artificial intelligence technology and application in enterprises in various industries in the main links of economic production activities such as design, procurement, production, management, and sales is constantly improving, accelerating the implementation and coverage of artificial intelligence in all links, and gradually integrating it with the main business , in order to improve industrial status or optimize operating efficiency, and further expand its own advantages. The large-scale implementation of innovative applications of artificial intelligence technology has promoted the vigorous development of the big data intelligence market, and also injected market vitality into the underlying data governance services. With big data, cloud computing and computing
 Popular science: What is an AI large model?
Jun 29, 2023 am 08:37 AM
Popular science: What is an AI large model?
Jun 29, 2023 am 08:37 AM
AI large models refer to artificial intelligence models trained using large-scale data and powerful computing power. These models usually have a high degree of accuracy and generalization capabilities and can be applied to various fields such as natural language processing, image recognition, speech recognition, etc. The training of large AI models requires a large amount of data and computing resources, and it is usually necessary to use a distributed computing framework to accelerate the training process. The training process of these models is very complex and requires in-depth research and optimization of data distribution, feature selection, model structure, etc. AI large models have a wide range of applications and can be used in various scenarios, such as smart customer service, smart homes, autonomous driving, etc. In these applications, AI large models can help people complete various tasks more quickly and accurately, and improve work efficiency.
 How to develop high-performance computing functions using Redis and TypeScript
Sep 20, 2023 am 11:21 AM
How to develop high-performance computing functions using Redis and TypeScript
Sep 20, 2023 am 11:21 AM
Overview of how to use Redis and TypeScript to develop high-performance computing functions: Redis is an open source in-memory data structure storage system with high performance and scalability. TypeScript is a superset of JavaScript that provides a type system and better development tool support. Combining Redis and TypeScript, we can develop efficient computing functions to process large data sets and make full use of Redis's memory storage and computing capabilities. This article will show you how to
 Born for AI: Samsung says it will put HBM4 video memory into production in 2025, competing for leadership in high-performance computing
Oct 13, 2023 pm 02:17 PM
Born for AI: Samsung says it will put HBM4 video memory into production in 2025, competing for leadership in high-performance computing
Oct 13, 2023 pm 02:17 PM
The rapid increase in AI computing power in recent years has made computing cards a new sought-after target for major hardware manufacturers. In particular, computing cards launched by companies like NVIDIA are in short supply. In addition to NVIDIA launching powerful GPUs, including Samsung Storage manufacturers such as Hynix and Hynix do not want to miss this AI feast, especially high-performance computing cards that require high-performance graphics memory produced by them. Currently, a senior executive in the storage field of Samsung issued a document saying that Samsung plans to mass-produce the latest memory in 2025. HBM4 video memory, thus surpassing Hynix. In 2016, Samsung officially began mass production of HBM video memory. Compared with GDDR video memory, HBM video memory has larger bandwidth, thereby achieving higher performance transmission. In the consumer market, AMD’s Radeon
 In the era of large AI models, new data storage bases promote the digital intelligence transition of education, scientific research
Jul 21, 2023 pm 09:53 PM
In the era of large AI models, new data storage bases promote the digital intelligence transition of education, scientific research
Jul 21, 2023 pm 09:53 PM
Generative AI (AIGC) has opened a new era of generalization of artificial intelligence. The competition around large models has become spectacular. Computing infrastructure is the primary focus of competition, and the awakening of power has increasingly become an industry consensus. In the new era, large models are moving from single-modality to multi-modality, the size of parameters and training data sets is growing exponentially, and massive unstructured data requires the support of high-performance mixed load capabilities; at the same time, data-intensive The new paradigm is gaining popularity, and application scenarios such as supercomputing and high-performance computing (HPC) are moving in depth. Existing data storage bases are no longer able to meet the ever-upgrading needs. If computing power, algorithms, and data are the "troika" driving the development of artificial intelligence, then in the context of huge changes in the external environment, the three urgently need to regain dynamic
 Vivo launches self-developed general-purpose AI model - Blue Heart Model
Nov 01, 2023 pm 02:37 PM
Vivo launches self-developed general-purpose AI model - Blue Heart Model
Nov 01, 2023 pm 02:37 PM
Vivo released its self-developed general artificial intelligence large model matrix - the Blue Heart Model at the 2023 Developer Conference on November 1. Vivo announced that the Blue Heart Model will launch 5 models with different parameter levels, respectively. It contains three levels of parameters: billion, tens of billions, and hundreds of billions, covering core scenarios, and its model capabilities are in a leading position in the industry. Vivo believes that a good self-developed large model needs to meet the following five requirements: large scale, comprehensive functions, powerful algorithms, safe and reliable, independent evolution, and widely open source. The rewritten content is as follows: Among them, the first is Lanxin Big Model 7B, this is a 7 billion level model designed to provide dual services for mobile phones and the cloud. Vivo said that this model can be used in fields such as language understanding and text creation.
 With reference to the human brain, will learning to forget make large AI models better?
Mar 12, 2024 pm 02:43 PM
With reference to the human brain, will learning to forget make large AI models better?
Mar 12, 2024 pm 02:43 PM
Recently, a team of computer scientists developed a more flexible and resilient machine learning model with the ability to periodically forget known information, a feature not found in existing large-scale language models. Actual measurements show that in many cases, the "forgetting method" is very efficient in training, and the forgetting model will perform better. Jea Kwon, an AI engineer at the Institute for Basic Science in Korea, said the new research means significant progress in the field of AI. The "forgetting method" training efficiency is very high. Most of the current mainstream AI language engines use artificial neural network technology. Each "neuron" in this network structure is actually a mathematical function. They are connected to each other to receive and transmit information.
