
 Technology peripherals
AI
The large model of the alpaca family evolves collectively! 32k context equals GPT-4, produced by Tian Yuandong's team
Technology peripherals
AI
The large model of the alpaca family evolves collectively! 32k context equals GPT-4, produced by Tian Yuandong's team
The large model of the alpaca family evolves collectively! 32k context equals GPT-4, produced by Tian Yuandong's team

The open source alpaca large model LLaMA context is equal to GPT-4, with only one simple change!
This paper just submitted by Meta AI shows that after the LLaMA context window is expanded from 2k to 32k, it only requires less than 1000 steps of fine-tuning.
The cost is negligible compared to pre-training.

Expanding the context window means that the AI's "working memory" capacity is increased. Specifically, it can:
- Support more rounds of dialogue , reduce forgetting, such as more stable role-playing
- Enter more information to complete more complex tasks, such as processing longer documents or multiple documents at one time
More important meaning The question is, can all large alpaca model families based on LLaMA adopt this method at low cost and evolve collectively?
Yangtuo is currently the most comprehensive open source basic model, and has derived many fully open source commercially available large models and vertical industry models.
# Tian Yuandong, the corresponding author of the paper, also excitedly shared this new development in his circle of friends.
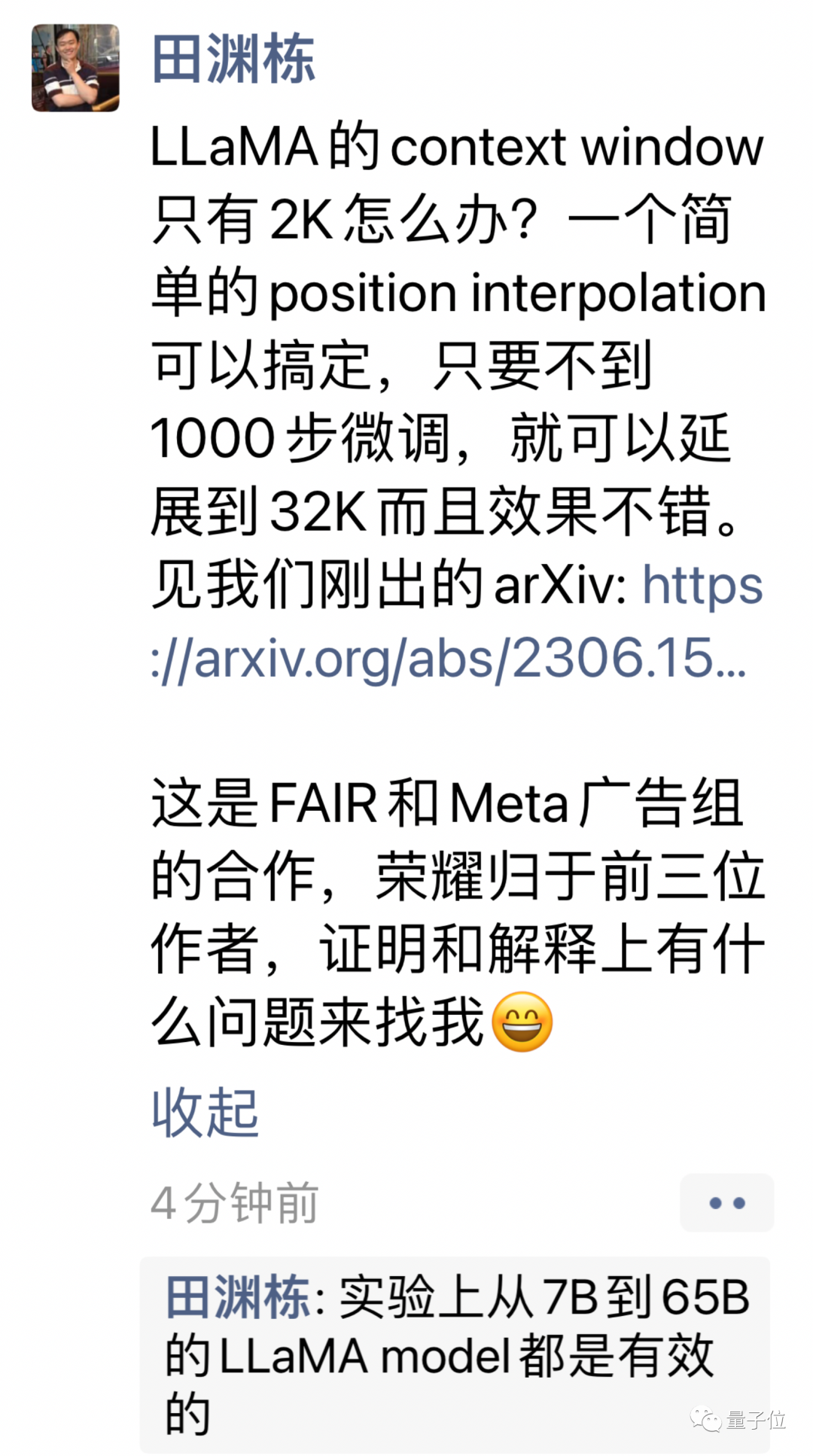
Large models based on RoPE can use
The new method is called position interpolation (Position Interpolation), which is suitable for large models that use RoPE (rotation position encoding) Applicable to all models.
RoPE was proposed by the Zhuiyi Technology team as early as 2021, and has now become one of the most common position encoding methods for large models.

But directly using extrapolation to expand the context window under this architecture will completely destroy the self-attention mechanism.
Specifically, the part beyond the length of the pre-trained context will cause the model perplexity to soar to the same level as an untrained model.
The new method is changed to linearly reduce the position index and expand the range alignment of the front and rear position index and relative distance.

# It is more intuitive to use pictures to express the difference between the two.
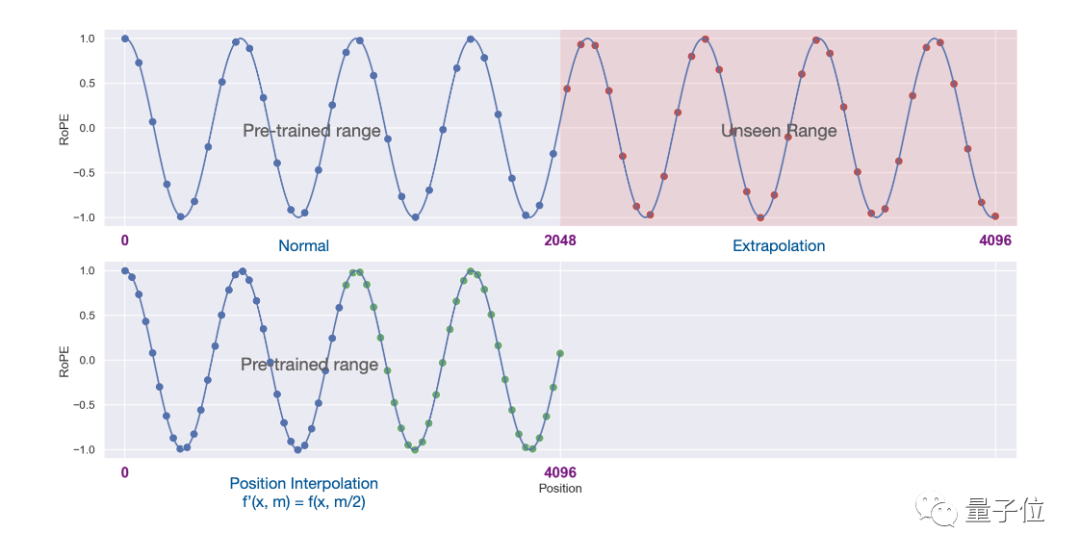
Experimental results show that the new method is effective for LLaMA large models from 7B to 65B.
There is no significant performance degradation in Long Sequence Language Modeling, Passkey Retrieval, and Long Document Summarization.
#In addition to experiments, a detailed proof of the new method is also given in the appendix of the paper.
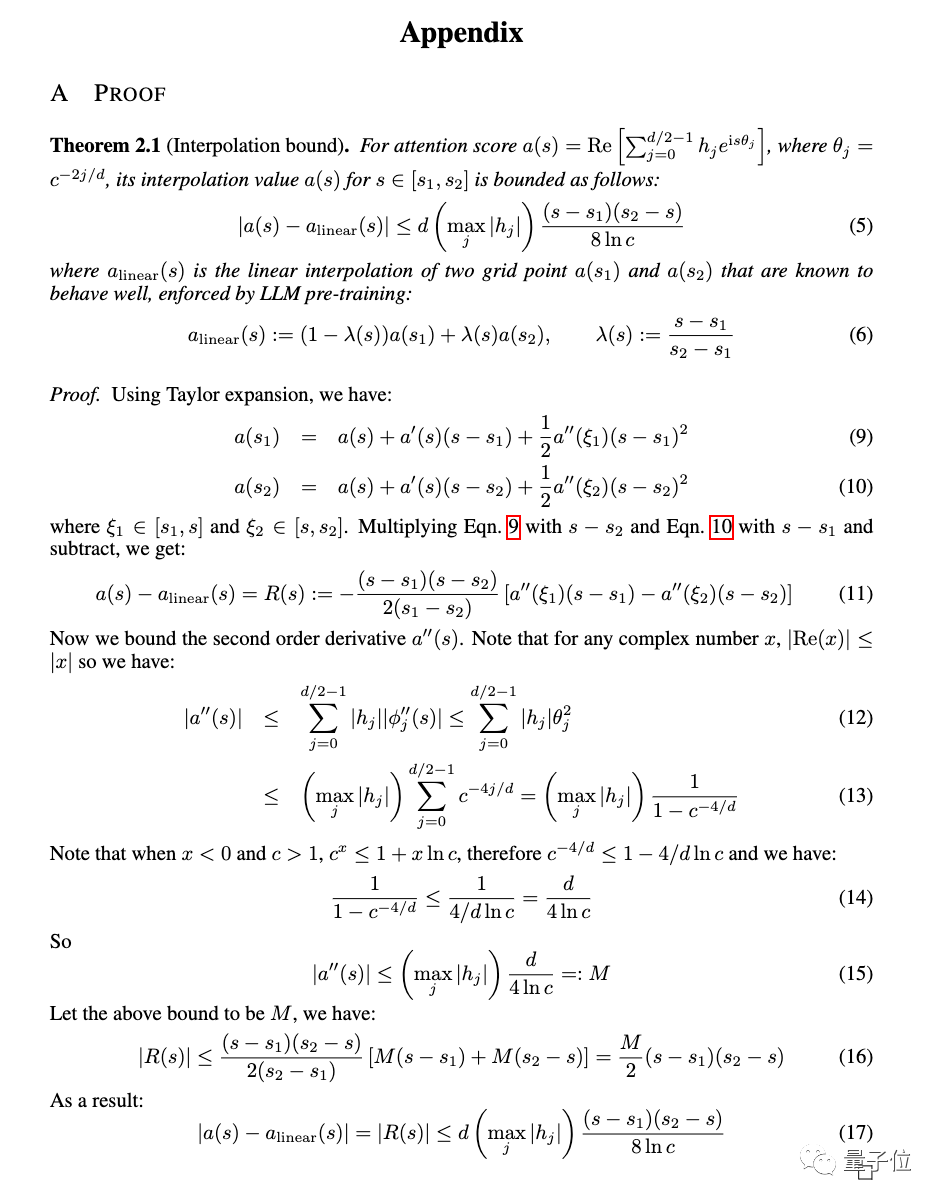
Three More Thing
The context window used to be an important gap between open source large models and commercial large models.
For example, OpenAI’s GPT-3.5 supports up to 16k, GPT-4 supports 32k, and AnthropicAI’s Claude supports up to 100k.
At the same time, many large open source models such as LLaMA and Falcon are still stuck at 2k.
Now, Meta AI’s new results have directly bridged this gap.
Expanding the context window is also one of the focuses of recent large model research. In addition to position interpolation methods, there are many attempts to attract industry attention.
1. Developer kaiokendev explored a method to extend the LLaMa context window to 8k in a technical blog.
2. Galina Alperovich, head of machine learning at data security company Soveren, summarized 6 tips for expanding the context window in an article.

3. Teams from Mila, IBM and other institutions also tried to completely remove positional encoding in Transformer in a paper.

Friends who need it can click the link below to view~
Meta paper: https://www.php.cn/link/ 0bdf2c1f053650715e1f0c725d754b96
Extending Context is Hard…but not Impossiblehttps://www.php.cn/link/9659078925b57e621eb3f9ef19773ac3
The Secret Sauce context window behind 100K in LLMshttps://www.php.cn/link/09a630e07af043e4cae879dd60db1cac
Positionless Coding Paperhttps://www.php.cn/link/fb6c84779f12283a81d739d8f088fc12
The above is the detailed content of The large model of the alpaca family evolves collectively! 32k context equals GPT-4, produced by Tian Yuandong's team. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
Big model app Tencent Yuanbao is online! Hunyuan is upgraded to create an all-round AI assistant that can be carried anywhere
Jun 09, 2024 pm 10:38 PM
On May 30, Tencent announced a comprehensive upgrade of its Hunyuan model. The App "Tencent Yuanbao" based on the Hunyuan model was officially launched and can be downloaded from Apple and Android app stores. Compared with the Hunyuan applet version in the previous testing stage, Tencent Yuanbao provides core capabilities such as AI search, AI summary, and AI writing for work efficiency scenarios; for daily life scenarios, Yuanbao's gameplay is also richer and provides multiple features. AI application, and new gameplay methods such as creating personal agents are added. "Tencent does not strive to be the first to make large models." Liu Yuhong, vice president of Tencent Cloud and head of Tencent Hunyuan large model, said: "In the past year, we continued to promote the capabilities of Tencent Hunyuan large model. In the rich and massive Polish technology in business scenarios while gaining insights into users’ real needs
 Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Bytedance Beanbao large model released, Volcano Engine full-stack AI service helps enterprises intelligently transform
Jun 05, 2024 pm 07:59 PM
Tan Dai, President of Volcano Engine, said that companies that want to implement large models well face three key challenges: model effectiveness, inference costs, and implementation difficulty: they must have good basic large models as support to solve complex problems, and they must also have low-cost inference. Services allow large models to be widely used, and more tools, platforms and applications are needed to help companies implement scenarios. ——Tan Dai, President of Huoshan Engine 01. The large bean bag model makes its debut and is heavily used. Polishing the model effect is the most critical challenge for the implementation of AI. Tan Dai pointed out that only through extensive use can a good model be polished. Currently, the Doubao model processes 120 billion tokens of text and generates 30 million images every day. In order to help enterprises implement large-scale model scenarios, the beanbao large-scale model independently developed by ByteDance will be launched through the volcano
 Uncovering the NVIDIA large model inference framework: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
Uncovering the NVIDIA large model inference framework: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. Product positioning of TensorRT-LLM TensorRT-LLM is a scalable inference solution developed by NVIDIA for large language models (LLM). It builds, compiles and executes calculation graphs based on the TensorRT deep learning compilation framework, and draws on the efficient Kernels implementation in FastTransformer. In addition, it utilizes NCCL for communication between devices. Developers can customize operators to meet specific needs based on technology development and demand differences, such as developing customized GEMM based on cutlass. TensorRT-LLM is NVIDIA's official inference solution, committed to providing high performance and continuously improving its practicality. TensorRT-LL
 Benchmark GPT-4! China Mobile's Jiutian large model passed dual registration
Apr 04, 2024 am 09:31 AM
Benchmark GPT-4! China Mobile's Jiutian large model passed dual registration
Apr 04, 2024 am 09:31 AM
According to news on April 4, the Cyberspace Administration of China recently released a list of registered large models, and China Mobile’s “Jiutian Natural Language Interaction Large Model” was included in it, marking that China Mobile’s Jiutian AI large model can officially provide generative artificial intelligence services to the outside world. . China Mobile stated that this is the first large-scale model developed by a central enterprise to have passed both the national "Generative Artificial Intelligence Service Registration" and the "Domestic Deep Synthetic Service Algorithm Registration" dual registrations. According to reports, Jiutian’s natural language interaction large model has the characteristics of enhanced industry capabilities, security and credibility, and supports full-stack localization. It has formed various parameter versions such as 9 billion, 13.9 billion, 57 billion, and 100 billion, and can be flexibly deployed in Cloud, edge and end are different situations
 New test benchmark released, the most powerful open source Llama 3 is embarrassed
Apr 23, 2024 pm 12:13 PM
New test benchmark released, the most powerful open source Llama 3 is embarrassed
Apr 23, 2024 pm 12:13 PM
If the test questions are too simple, both top students and poor students can get 90 points, and the gap cannot be widened... With the release of stronger models such as Claude3, Llama3 and even GPT-5 later, the industry is in urgent need of a more difficult and differentiated model Benchmarks. LMSYS, the organization behind the large model arena, launched the next generation benchmark, Arena-Hard, which attracted widespread attention. There is also the latest reference for the strength of the two fine-tuned versions of Llama3 instructions. Compared with MTBench, which had similar scores before, the Arena-Hard discrimination increased from 22.6% to 87.4%, which is stronger and weaker at a glance. Arena-Hard is built using real-time human data from the arena and has a consistency rate of 89.1% with human preferences.
 Using Shengteng AI technology, the Qinling·Qinchuan transportation model helps Xi'an build a smart transportation innovation center
Oct 15, 2023 am 08:17 AM
Using Shengteng AI technology, the Qinling·Qinchuan transportation model helps Xi'an build a smart transportation innovation center
Oct 15, 2023 am 08:17 AM
"High complexity, high fragmentation, and cross-domain" have always been the primary pain points on the road to digital and intelligent upgrading of the transportation industry. Recently, the "Qinling·Qinchuan Traffic Model" with a parameter scale of 100 billion, jointly built by China Vision, Xi'an Yanta District Government, and Xi'an Future Artificial Intelligence Computing Center, is oriented to the field of smart transportation and provides services to Xi'an and its surrounding areas. The region will create a fulcrum for smart transportation innovation. The "Qinling·Qinchuan Traffic Model" combines Xi'an's massive local traffic ecological data in open scenarios, the original advanced algorithm self-developed by China Science Vision, and the powerful computing power of Shengteng AI of Xi'an Future Artificial Intelligence Computing Center to provide road network monitoring, Smart transportation scenarios such as emergency command, maintenance management, and public travel bring about digital and intelligent changes. Traffic management has different characteristics in different cities, and the traffic on different roads
 Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
Advanced practice of industrial knowledge graph
Jun 13, 2024 am 11:59 AM
1. Background Introduction First, let’s introduce the development history of Yunwen Technology. Yunwen Technology Company...2023 is the period when large models are prevalent. Many companies believe that the importance of graphs has been greatly reduced after large models, and the preset information systems studied previously are no longer important. However, with the promotion of RAG and the prevalence of data governance, we have found that more efficient data governance and high-quality data are important prerequisites for improving the effectiveness of privatized large models. Therefore, more and more companies are beginning to pay attention to knowledge construction related content. This also promotes the construction and processing of knowledge to a higher level, where there are many techniques and methods that can be explored. It can be seen that the emergence of a new technology does not necessarily defeat all old technologies. It is also possible that the new technology and the old technology will be integrated with each other.
 Xiaomi Byte joins forces! A large model of Xiao Ai's access to Doubao: already installed on mobile phones and SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte joins forces! A large model of Xiao Ai's access to Doubao: already installed on mobile phones and SU7
Jun 13, 2024 pm 05:11 PM
According to news on June 13, according to Byte's "Volcano Engine" public account, Xiaomi's artificial intelligence assistant "Xiao Ai" has reached a cooperation with Volcano Engine. The two parties will achieve a more intelligent AI interactive experience based on the beanbao large model. It is reported that the large-scale beanbao model created by ByteDance can efficiently process up to 120 billion text tokens and generate 30 million pieces of content every day. Xiaomi used the beanbao large model to improve the learning and reasoning capabilities of its own model and create a new "Xiao Ai Classmate", which not only more accurately grasps user needs, but also provides faster response speed and more comprehensive content services. For example, when a user asks about a complex scientific concept, &ldq
