
 Technology peripherals
AI
Google AudioPaLM implements 'text + audio' dual-modal solution, a large model for both speaking and listening
Technology peripherals
AI
Google AudioPaLM implements 'text + audio' dual-modal solution, a large model for both speaking and listening
Google AudioPaLM implements 'text + audio' dual-modal solution, a large model for both speaking and listening

With its powerful performance and versatility, large-scale language models have driven the development of a number of multi-modal large models, such as audio, video, etc.
The underlying architecture of the language model is mostly based on Transformer and mainly decoder, so it can adapt to other sequence modalities without too much adjustment of the model architecture.
Recently, Google released a unified speech-text model AudioPaLM, which merges text and audio tokens into a multi-modal joint vocabulary, and then combines different task description tags to Achieve training of decoder-only models on any mixed speech and text tasks, including speech recognition (ASR), text-to-speech synthesis, automatic speech translation (AST) and speech-to-speech translation (S2ST), etc., which will be traditionally used by heterogeneous The tasks solved by the model are unified into an architecture and training process.
 Picture
Picture
Paper link: https://arxiv.org/pdf/2306.12925.pdf
Example link: https://google-research.github.io/seanet/audiopalm/examples/
In addition, since the underlying architecture of AudioPaLM is a large Transformer models, which can be initialized with the weights of a large language model pre-trained on text, can benefit from the linguistic knowledge of models such as PaLM.
From the perspective of implementation results, AudioPaLM has achieved state-of-the-art results on the AST and S2ST benchmarks, and its performance on the ASR benchmark is comparable to other models.
By leveraging AudioLM’s audio cues, the AudioPaLM model is able to perform S2ST on new speaker speech migration, surpassing existing methods in terms of speech quality and speech preservation.
The AudioPaLM model also has the zero-shot ability to perform AST tasks on speech input/target language combinations not seen in training.
AudioPaLM
The researchers used a decoder-only Transformer model to model text and speech tokens, where the text and audio have been processed before being input to the model. Word segmentation, so the input is just a sequence of integers, and the detokenized operation is performed on the output end and returned to the user.
 Picture
Picture
Audio embedding and word segmentation
The process of converting the original audio waveform into tokens includes extracting embeddings from existing speech representation models and discretizing the embeddings into a limited set of audio tokens
In previous work, embeddings were extracted from the w2v-BERT model and quantized by k-means. In this paper, the researchers experimented with three solutions:
w2v-BERT: Use the w2v-BERT model trained on multi-lingual data instead of pure English; and no normalization processing is performed before k-means clustering, otherwise it will lead to multi-language environment Medium performance degrades. Then generate tokens at a rate of 25Hz with a vocabulary size of 1024
USM-v1: Use a more powerful, 2 billion parameter Universal Speech Model (USM) encoder to perform similar operations, and extract embeddings from intermediate layers;
USM-v2: trained with auxiliary ASR loss and further fine-tuned to support multi-language.
Modify text-only decoder
In the Transfomrer decoder structure, except Except for the input and the final softmax output layer, the number of modeling tokens is not involved, and in the PaLM architecture, the weight variables of the input and output matrices are shared, that is, they are transposed to each other.
So you only need to expand the size of the embedding matrix from (t × m) to (t a) × m to turn a pure text model into a model that can simulate both text and text. A model for audio, where t is the size of the text vocabulary, a is the size of the audio vocabulary, and m is the embedding dimension.
To take advantage of the pre-trained text model, the researchers changed the checkpoint of the existing model by adding new rows to the embedding matrix.
The specific implementation is that the first t tokens correspond to the SentencePiece text tags, and the following a tokens represent the audio tags. Although the text embedding reuses the pre-trained weights, the audio embedding is Newly initialized, must be trained.
Experimental results show that compared with retraining from scratch, text-based pre-training models are very beneficial to improving the performance of multi-modal tasks of speech and text.
Decode the audio token into native audio
In order to synthesize the audio waveform from the audio token , the researchers tested two different methods:
1. Autoregressive decoding similar to the AudioLM model
2. Similar to the SoundStorm model Non-autoregressive decoding
Both methods require first generating a SoundStream token and then using a convolutional decoder to convert it into an audio waveform.
The researchers trained on Multilingual LibriSpeech. The speech condition was a 3-second long speech sample, which was represented as an audio token and a SoundStream token at the same time
By providing part of the original input speech as speech conditions, the model is able to preserve the original speaker's speech when translating the speaker's speech into different languages, and fill in the blank time by repeated playback when the original audio is shorter than 3 seconds.
Training task
The training data sets used are speech-text data :
1. Audio Audio: Speech in the source language
2. Transcript: Transcription of the speech in the audio data
3. Translated Audio: The spoken translation of the voice in the audio
##4. Translated Transcript: The written translation of the voice in the audio
Component tasks include:
1. ASR (Automatic Speech Recognition): Transcribe audio to obtain transcribed text
2. AST (Automatic Speech Translation): Translate the audio to get the translated transcript
3. S2ST (Speech to Speech Translation): Translate the audio to get the translated transcript Audio
4. TTS (Text to Speech): Read the transcript for audio.
5. MT (Text-to-Text Machine Translation): Translating Transcriptions to Obtain Translated Transcript Text
A dataset may is used for multiple tasks, so the researchers chose to signal the model which task it should perform on a given input. The specific method is: add a label before the input, specify the English name of the task and input language, and output Language can also be selected.
For example, when you want the model to perform ASR on French corpus, you need to add the label [ASR French] in front of the audio input after word segmentation; to perform TTS tasks in English, you need to add the label in front of the text Add [TTS English]; to perform the S2ST task from English to French, the English audio after segmentation will be preceded by [S2ST English French]
##training mix
The researchers used the SeqIO library to blend the training data and down-weight the larger data sets.
Picture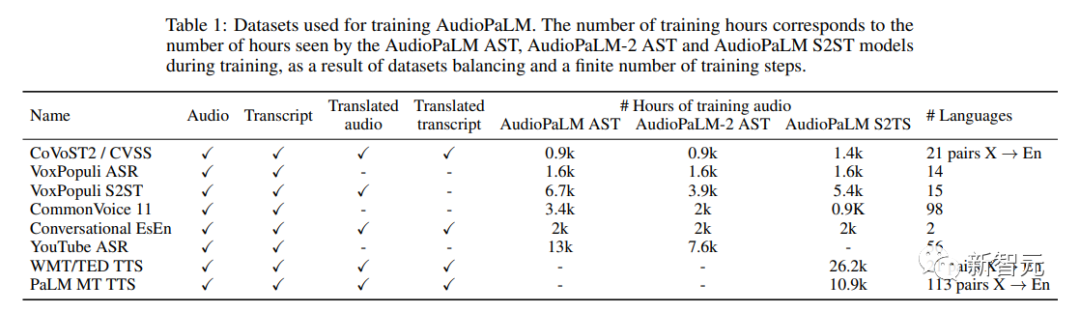 Experimental part
Experimental part
Picture
In addition to evaluating the translation quality of speech content, the researchers also evaluated whether the language generated by AudioPaLM was of high enough quality and whether the speaker's voice was preserved when translated into different languages.
Objective Metrics
Using something similar to the no-reference MOS estimator, given an audio sample, between 1 and Provides an estimate of perceived audio quality in the range of 5.To measure the quality of speech transfer across languages, the researchers used off-the-shelf speaker verification models and calculated the embeddings between the source (encoded/decoded with SoundStream) and the translated speech. Cosine similarity; also measures the acoustic properties (recording conditions, background noise) from the source audio to the target audio.
Subjective Evaluation The researchers conducted two independent studies to evaluate the quality of generated speech and speech similarity. In both studies, Use the same sample set. Due to the uneven quality of the corpus, some contain loud overlapping speech (for example, TV shows or songs playing in the background) or extremely strong noise (for example, clothes rubbing against the microphone) ), similar distortion effects complicate the work of human raters, so the researchers decided to pre-filter by only selecting inputs with an MOS estimate of at least 3.0. Ratings are provided on a 5-point scale, ranging from 1 (poor quality, or completely different sound) to 5 (good quality, same sound). It can be observed from the results that AudioPaLM performs well in both objective and subjective measurements, in terms of audio quality and voice similarity. Both are significantly better than the baseline Translatotron 2 system, and AudioPaLM has higher quality and better speech similarity than the real synthetic recordings in CVSS-T, with relatively large improvements in most indicators. The researchers also compared the systems of high- and low-resource groups (French, German, Spanish, and Catalan with other languages) and found that between these groups There is no significant difference in the indicators. 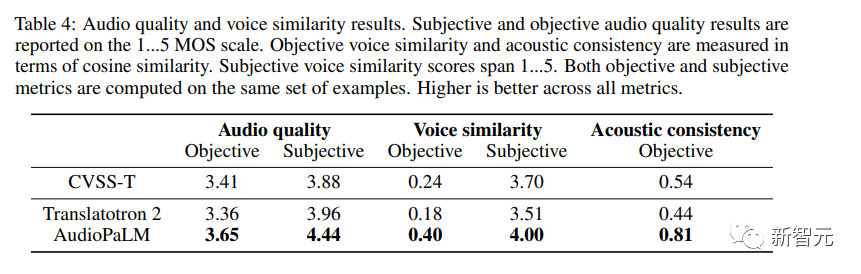 Picture
Picture
The above is the detailed content of Google AudioPaLM implements 'text + audio' dual-modal solution, a large model for both speaking and listening. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Sesame Open Door Exchange Web Page Registration Link Gate Trading App Registration Website Latest
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Page Registration Link Gate Trading App Registration Website Latest
Feb 28, 2025 am 11:06 AM
This article introduces the registration process of the Sesame Open Exchange (Gate.io) web version and the Gate trading app in detail. Whether it is web registration or app registration, you need to visit the official website or app store to download the genuine app, then fill in the user name, password, email, mobile phone number and other information, and complete email or mobile phone verification.
 Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
A detailed introduction to the login operation of the Sesame Open Exchange web version, including login steps and password recovery process. It also provides solutions to common problems such as login failure, unable to open the page, and unable to receive verification codes to help you log in to the platform smoothly.
 Why can't the Bybit exchange link be directly downloaded and installed?
Feb 21, 2025 pm 10:57 PM
Why can't the Bybit exchange link be directly downloaded and installed?
Feb 21, 2025 pm 10:57 PM
Why can’t the Bybit exchange link be directly downloaded and installed? Bybit is a cryptocurrency exchange that provides trading services to users. The exchange's mobile apps cannot be downloaded directly through AppStore or GooglePlay for the following reasons: 1. App Store policy restricts Apple and Google from having strict requirements on the types of applications allowed in the app store. Cryptocurrency exchange applications often do not meet these requirements because they involve financial services and require specific regulations and security standards. 2. Laws and regulations Compliance In many countries, activities related to cryptocurrency transactions are regulated or restricted. To comply with these regulations, Bybit Application can only be used through official websites or other authorized channels
 Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
This article recommends the top ten cryptocurrency trading platforms worth paying attention to, including Binance, OKX, Gate.io, BitFlyer, KuCoin, Bybit, Coinbase Pro, Kraken, BYDFi and XBIT decentralized exchanges. These platforms have their own advantages in terms of transaction currency quantity, transaction type, security, compliance, and special features. For example, Binance is known for its largest transaction volume and abundant functions in the world, while BitFlyer attracts Asian users with its Japanese Financial Hall license and high security. Choosing a suitable platform requires comprehensive consideration based on your own trading experience, risk tolerance and investment preferences. Hope this article helps you find the best suit for yourself
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download Address
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download Address
Feb 28, 2025 am 10:51 AM
It is crucial to choose a formal channel to download the app and ensure the safety of your account.
 Binance binance official website latest version login portal
Feb 21, 2025 pm 05:42 PM
Binance binance official website latest version login portal
Feb 21, 2025 pm 05:42 PM
To access the latest version of Binance website login portal, just follow these simple steps. Go to the official website and click the "Login" button in the upper right corner. Select your existing login method. If you are a new user, please "Register". Enter your registered mobile number or email and password and complete authentication (such as mobile verification code or Google Authenticator). After successful verification, you can access the latest version of Binance official website login portal.
 Bitget trading platform official app download and installation address
Feb 25, 2025 pm 02:42 PM
Bitget trading platform official app download and installation address
Feb 25, 2025 pm 02:42 PM
This guide provides detailed download and installation steps for the official Bitget Exchange app, suitable for Android and iOS systems. The guide integrates information from multiple authoritative sources, including the official website, the App Store, and Google Play, and emphasizes considerations during download and account management. Users can download the app from official channels, including app store, official website APK download and official website jump, and complete registration, identity verification and security settings. In addition, the guide covers frequently asked questions and considerations, such as
 The latest download address of Bitget in 2025: Steps to obtain the official app
Feb 25, 2025 pm 02:54 PM
The latest download address of Bitget in 2025: Steps to obtain the official app
Feb 25, 2025 pm 02:54 PM
This guide provides detailed download and installation steps for the official Bitget Exchange app, suitable for Android and iOS systems. The guide integrates information from multiple authoritative sources, including the official website, the App Store, and Google Play, and emphasizes considerations during download and account management. Users can download the app from official channels, including app store, official website APK download and official website jump, and complete registration, identity verification and security settings. In addition, the guide covers frequently asked questions and considerations, such as
