

As everyone continues to upgrade and iterate their own large models, the ability of LLM (large language model) to process context windows has also become an important evaluation indicator.
For example, OpenAI’s gpt-3.5-turbo provides a context window option of 16k tokens, and AnthropicAI has increased Claude’s token processing capability to 100k. What is the concept of a large model processing context window? For example, GPT-4 supports 32k tokens, which is equivalent to 50 pages of text, which means that GPT-4 can remember up to about 50 pages of content when talking or generating text.
Generally speaking, the ability of large language models to handle the context window size is predetermined. For example, for the LLaMA model released by Meta AI, its input token size must be less than 2048.
However, in applications such as conducting long conversations, summarizing long documents, or executing long-term plans, the preset context window limit is often exceeded. Therefore, it is difficult to handle longer context windows. LLM is more popular.
But this faces a new problem. Training an LLM with a long context window from scratch requires a lot of investment. This naturally leads to the question: can we extend the context window of existing pre-trained LLMs?
A straightforward approach is to fine-tune an existing pre-trained Transformer to obtain a longer context window. However, empirical results show that models trained in this way adapt very slowly to long context windows. After 10000 batches of training, the increase in the effective context window is still very small, only from 2048 to 2560 (as can be seen in Table 4 in the experimental section). This suggests that this approach is inefficient at scaling to longer context windows.
In this article, researchers from Meta introduced Position Interpolation (PI) to some existing pre-trained LLM (including LLaMA) The context window is expanded. The results show that LLaMA context window scaling from 2k to 32k requires less than 1000 steps of fine-tuning.
 Picture
Picture
Paper address: https://arxiv.org/pdf/2306.15595.pdf
The key idea of this research is not to perform extrapolation, but to directly reduce the position index so that the maximum position index matches the context window limit of the pre-training stage. In other words, in order to accommodate more input tokens, this study interpolates positional encodings at adjacent integer positions, taking advantage of the fact that positional encodings can be applied to non-integer positions, as opposed to extrapolating beyond the trained positions. than, the latter can lead to catastrophic values.
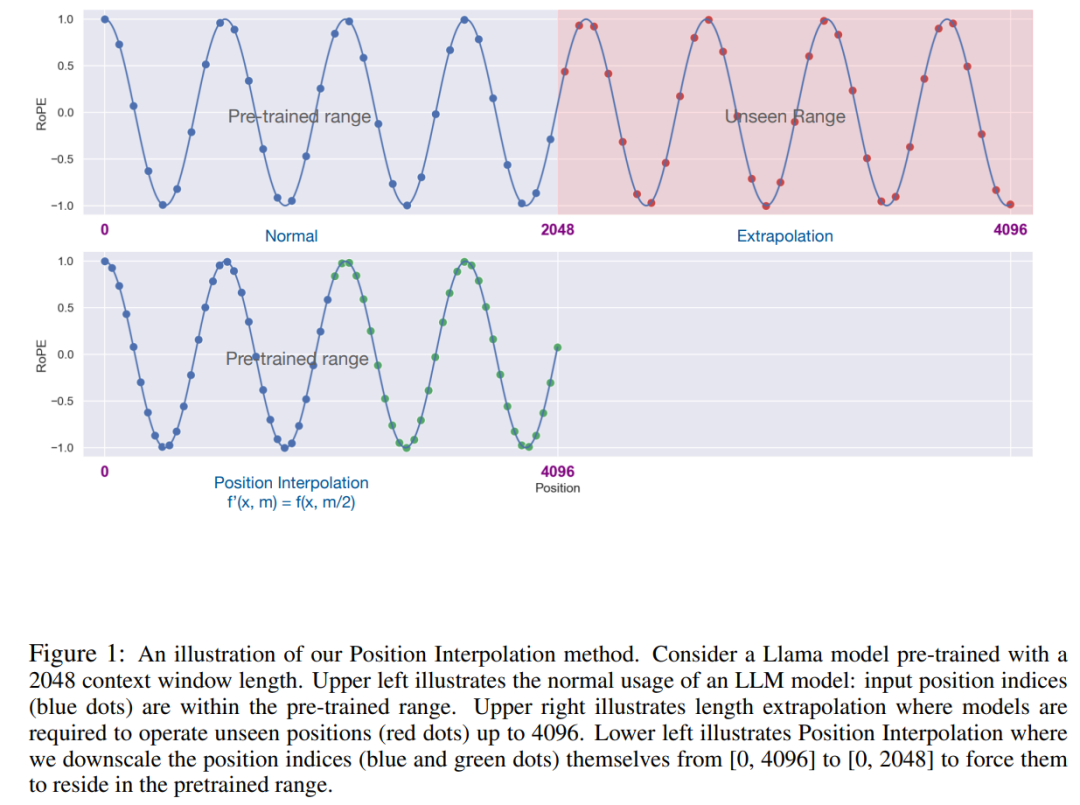
PI method extends the context window size of pre-trained LLM (such as LLaMA) based on RoPE (rotation position encoding) To up to 32768, with minimal fine-tuning (within 1000 steps), this study achieves better performance on a variety of tasks requiring long context, including retrieval, language modeling, and long document summarization from LLaMA 7B to 65B . At the same time, the model extended by PI maintains relatively good quality within its original context window.
RoPE is present in large language models such as LLaMA, ChatGLM-6B, and PaLM that we are familiar with. This method Proposed by Su Jianlin and others from Zhuiyi Technology, RoPE implements relative position encoding through absolute encoding.
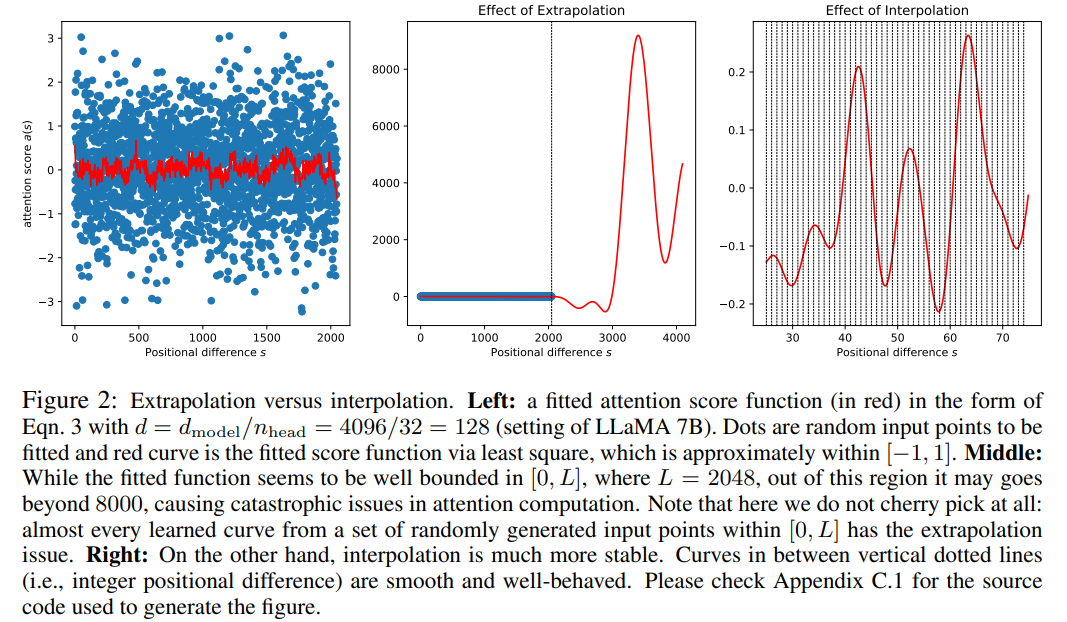
Although the attention score in RoPE only depends on the relative position, its extrapolation performance is not good. In particular, when scaling directly to larger context windows, perplexity can spike to very high numbers (i.e. > 10^3).
This article uses the position interpolation method, and its comparison with the extrapolation method is as follows. Due to the smoothness of the basis functions ϕ_j, the interpolation is more stable and does not lead to outliers.
 Picture
Picture
In this study, RoPE f was replaced by f ′, and the following formula was obtained
 picture
picture
This study refers to the conversion on positional encoding as positional interpolation. This step reduces the position index from [0, L′ ) to [0, L) to match the original index range before calculating RoPE. Therefore, as input to RoPE, the maximum relative distance between any two tokens has been reduced from L ′ to L . By aligning the range of position indexes and relative distances before and after expansion, the impact on attention score calculations due to context window expansion is mitigated, which makes the model easier to adapt.
It is worth noting that the rescaling position index method does not introduce additional weights, nor does it modify the model architecture in any way.
This study demonstrates that positional interpolation can effectively expand the context window to 32 times its original size, and that this expansion only It takes hundreds of training steps to complete.
Table 1 and Table 2 report the perplexity of the PI model and the baseline model on the PG-19 and Arxiv Math Proof-pile data sets. The results show that the model extended using the PI method significantly improves perplexity at longer context window sizes.
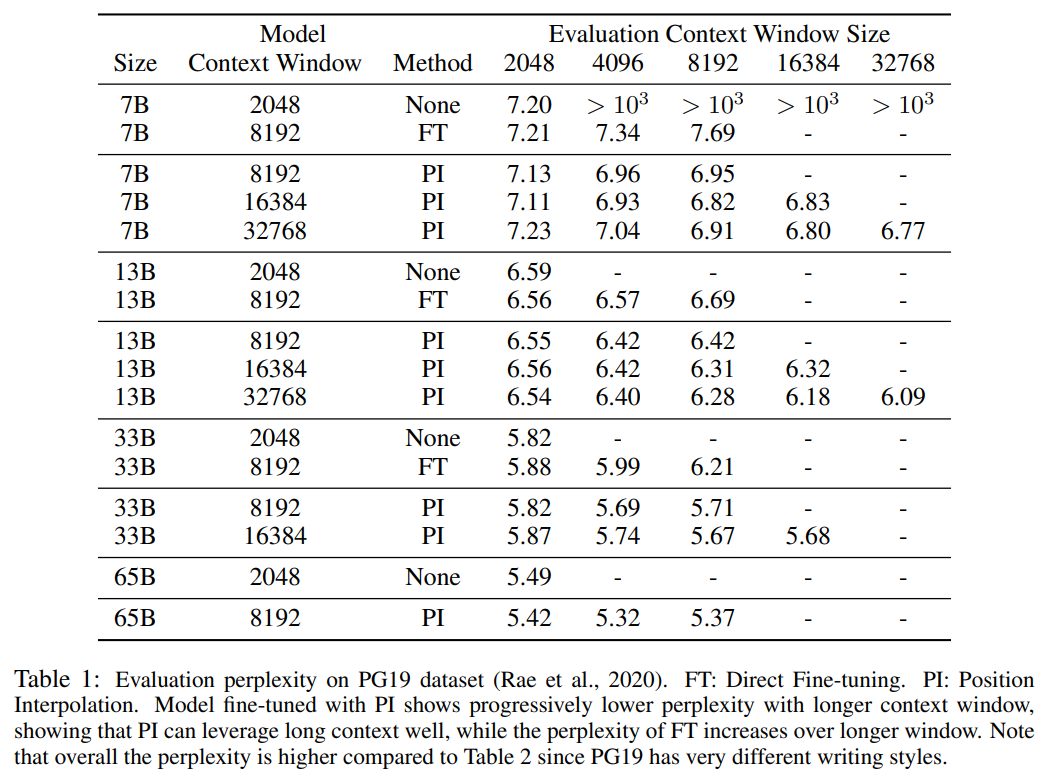
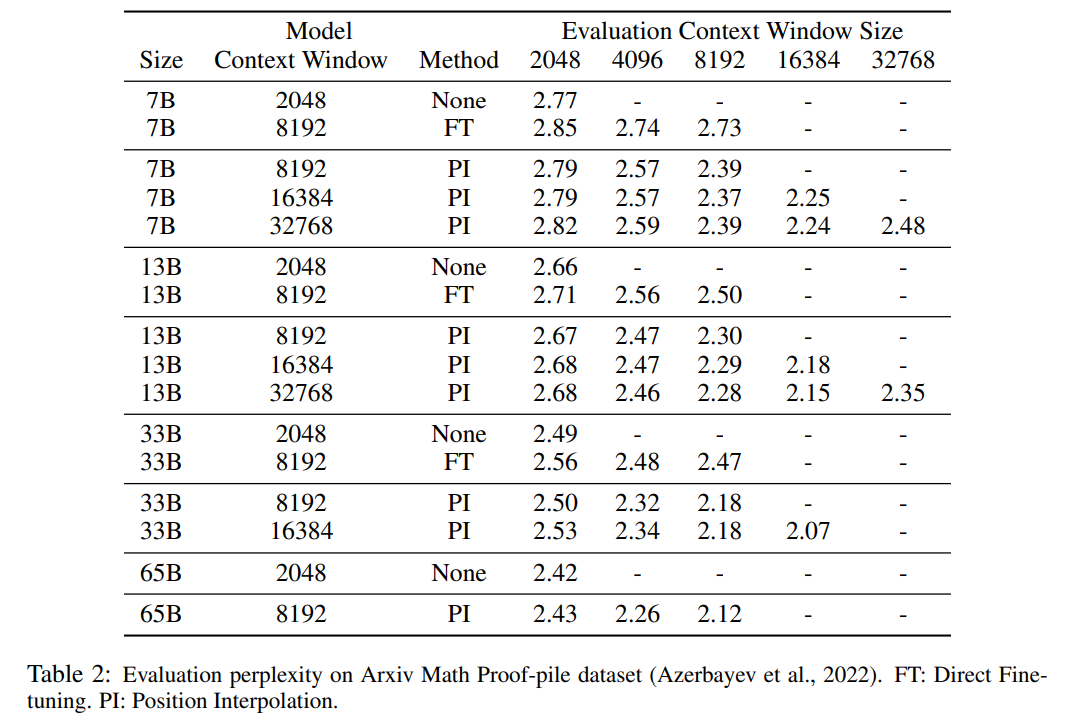
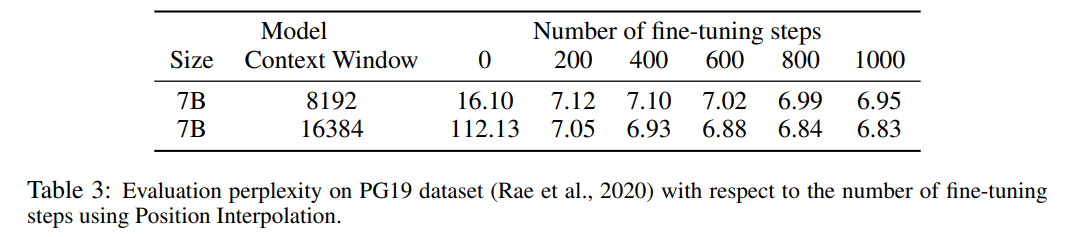
Table 3 reports the extension of the LLaMA 7B model to 8192 using the PI method on the PG19 dataset and 16384 the relationship between perplexity and the number of fine-tuning steps when the context window size is large.
It can be seen from the results that without fine-tuning (the number of steps is 0), the model can demonstrate certain language modeling capabilities, such as when the context window is expanded to 8192 The perplexity is less than 20 (compared to greater than 10^3 for the direct extrapolation method). At 200 steps, the model's perplexity exceeds that of the original model at a context window size of 2048, indicating that the model is able to effectively utilize longer sequences for language modeling than the pre-trained setting. At 1000 steps one can see steady improvement in the model and achieve better perplexity.
 Picture
Picture
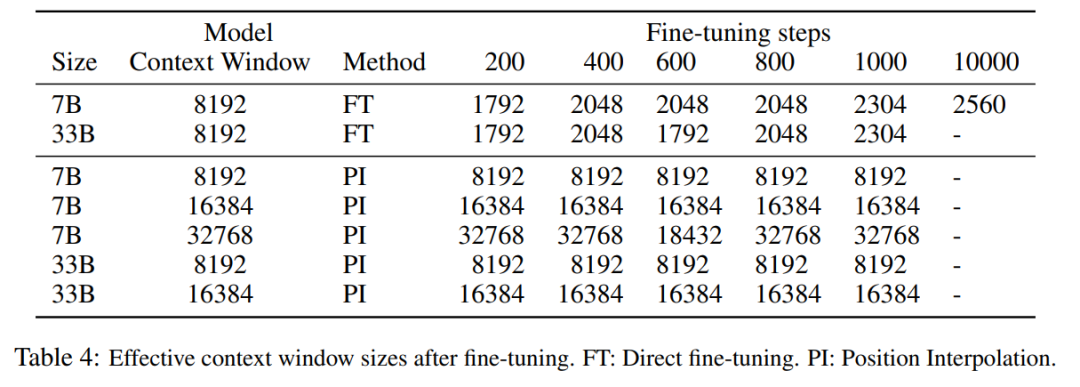
#The following table shows that the model extended by PI successfully achieves the scaling goals in terms of effective context window size , that is, after only 200 steps of fine-tuning, the effective context window size reaches the maximum value, which remains consistent at 7B and 33B model sizes and up to 32768 context windows. In contrast, the effective context window size of the LLaMA model extended only by direct fine-tuning only increased from 2048 to 2560, with no sign of significant accelerated window size increase even after more than 10000 steps of fine-tuning.
 Picture
Picture
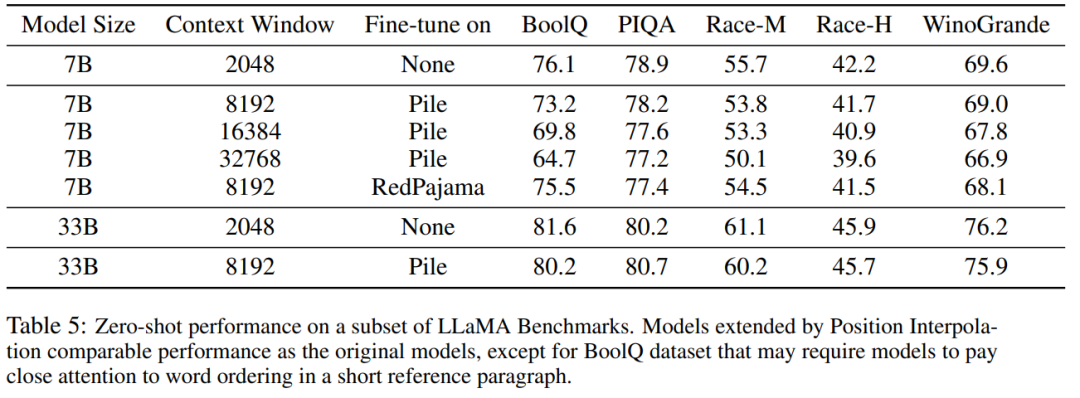
Table 5 shows that the model extended to 8192 produced comparable results on the original baseline task, while the The baseline task is designed for smaller context windows, and the degradation in the baseline task reaches up to 2% for 7B and 33B model sizes.
 Picture
Picture
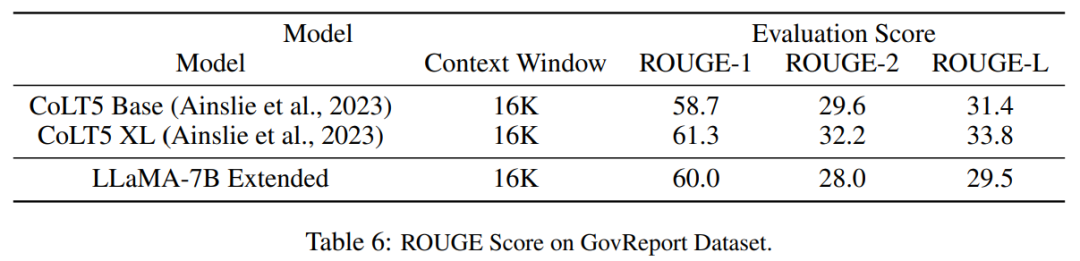
Table 6 shows that the PI model with 16384 context windows can effectively handle long text summarization tasks.
 picture
picture
The above is the detailed content of New research by Tian Yuandong's team: Fine-tuning <1000 steps, extending LLaMA context to 32K. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



