
 Technology peripherals
AI
How to use Transformer BEV to overcome extreme situations of autonomous driving?
Technology peripherals
AI
How to use Transformer BEV to overcome extreme situations of autonomous driving?
How to use Transformer BEV to overcome extreme situations of autonomous driving?

Autonomous driving systems need to face various complex scenarios in practical applications, especially Corner Cases (extreme situations) which place higher requirements on the perception and decision-making capabilities of autonomous driving. Corner Case refers to extreme or rare situations that may occur in actual driving, such as traffic accidents, severe weather conditions or complex road conditions. BEV technology enhances the perception capabilities of autonomous driving systems by providing a global perspective, which is expected to provide better support in handling these extreme situations. This article will explore how BEV (Bird's Eye View) technology can help the autonomous driving system cope with the Corner Case and improve the reliability and safety of the system.
 Picture
Picture
Transformer is a deep learning model based on the self-attention mechanism and was first used in natural language processing tasks. . The core idea is to capture long-distance dependencies in the input sequence through a self-attention mechanism, thereby improving the model's ability to process sequence data.
The effective combination of the above two is also a very popular emerging technology in autonomous driving strategies.
01 BEV technical advantage analysis
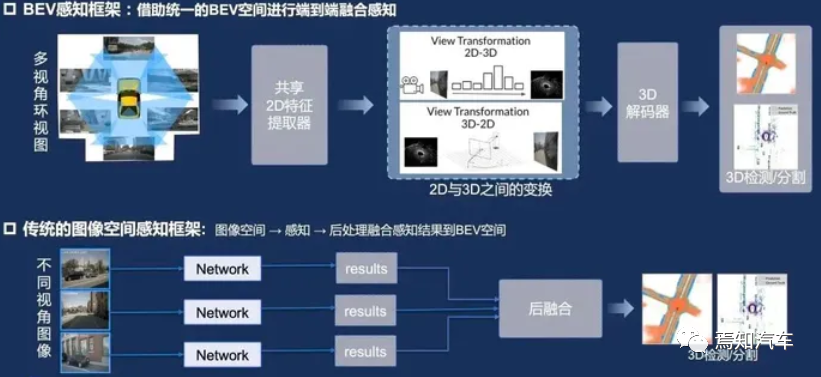
BEV is a method of projecting three-dimensional environmental information onto a two-dimensional plane, displaying it from a top-down perspective Objects and terrain in the environment. In the field of autonomous driving, BEV can help the system better understand the surrounding environment and improve the accuracy of perception and decision-making. In the environment perception stage, BEV can fuse multi-modal data such as lidar, radar and camera on the same plane. This method can eliminate occlusion and overlap problems between data and improve the accuracy of object detection and tracking. At the same time, BEV can provide a clear representation of the environment for subsequent prediction and decision-making stages, which is beneficial to improving the overall performance of the system.
1. Comparison between Lidar and BEV technology:
First of all, BEV technology can provide a global perspective of environmental perception, helping to improve automatic The performance of the driving system in complex scenarios. However, lidar has higher accuracy in terms of distance and spatial information.
Secondly, BEV technology captures images through cameras and can obtain color and texture information, while lidar's performance in this regard is weak.
In addition, the cost of BEV technology is relatively low and suitable for large-scale commercial deployment.
2. Comparison between BEV technology and traditional single-view cameras
The traditional single-view camera is a commonly used vehicle sensing device that can capture Environmental information around the vehicle. However, single-view cameras have certain limitations in terms of field of view and information acquisition. BEV technology integrates images from multiple cameras to provide a global perspective and a more comprehensive understanding of the environment around the vehicle.
 Picture
Picture
BEV technology has better environmental perception compared to single-view cameras in complex scenes and severe weather conditions Ability, because BEV can fuse image information from different angles, thereby improving the system's perception of the environment.
BEV technology can help autonomous driving systems better handle corner cases, such as complex road conditions, narrow or blocked roads, etc., while single-view cameras may not perform well in these situations .
Of course, in terms of cost and resource usage, BEV requires image perception, reconstruction and splicing from various viewing angles, so it consumes more computing power and storage resources. Although BEV technology requires the deployment of multiple cameras, the overall cost is still lower than lidar, and its performance is significantly improved compared to single-view cameras.
To sum up, BEV technology has certain advantages compared with other perception technologies in the field of autonomous driving. Especially when it comes to processing Corner Cases, BEV technology can provide a global perspective of environmental perception, helping to improve the performance of autonomous driving systems in complex scenarios. However, in order to fully leverage the advantages of BEV technology, further research and development are still needed to improve performance in image processing capabilities, sensor fusion technology, and abnormal behavior prediction. At the same time, combined with other perception technologies (such as lidar) and deep learning and machine learning algorithms, the stability and safety of the autonomous driving system in various scenarios can be further improved.
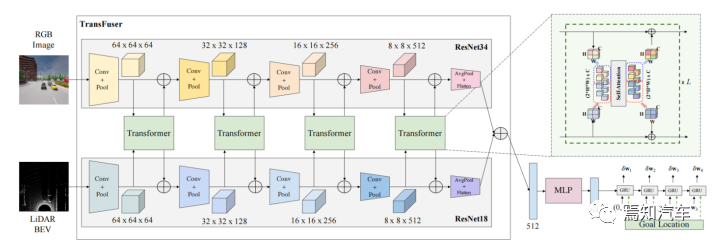
02 Autonomous driving system based on Transformer and BEV
At the same time, Bird's Eye View (BEV) serves as an effective environment perception Methods play an important role in autonomous driving systems. Combining the advantages of Transformer and BEV, we can build an end-to-end autonomous driving system to achieve high-precision perception, prediction and decision-making. This article will also explore how Transformer and BEV can be effectively combined and applied in the field of autonomous driving to improve system performance.
The specific steps are as follows:
1. Data preprocessing:
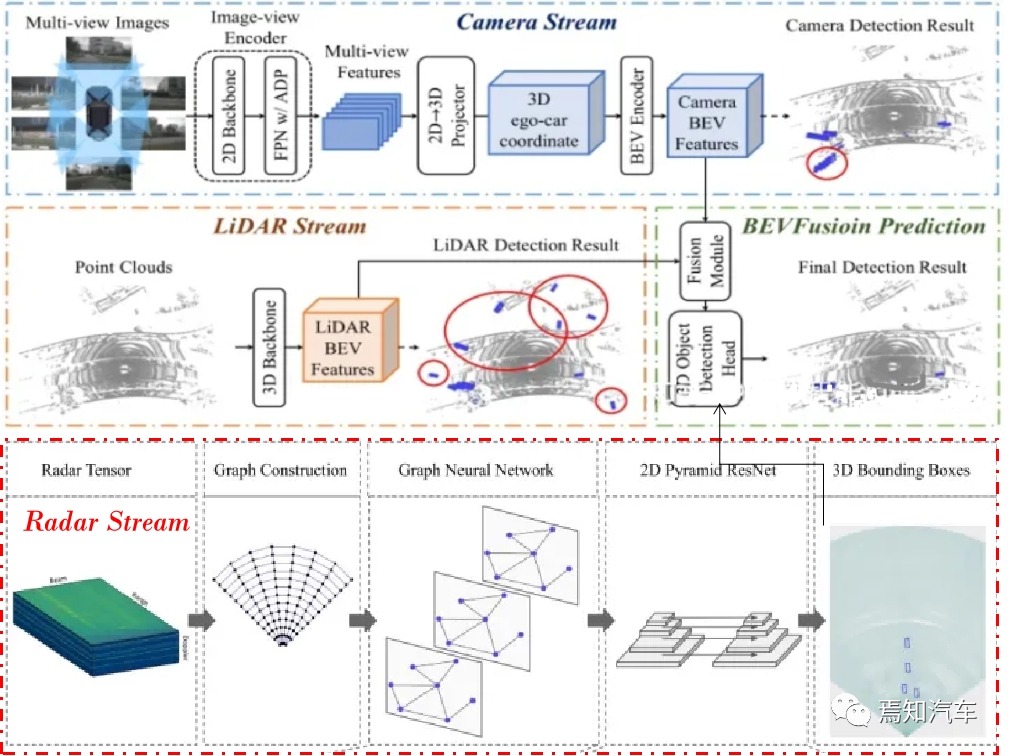
Combine lidar, Multi-modal data such as radar and camera are fused into BEV format, and necessary preprocessing operations are performed, such as data enhancement, normalization, etc.
First, we need to convert multi-modal data such as lidar, radar and camera to BEV format. For lidar point cloud data, we can project the three-dimensional point cloud onto a two-dimensional plane, and then rasterize the plane to generate a height map; for radar data, we can convert the distance and angle information into a height map. Karl coordinates are then rasterized on the BEV plane; for camera data, we can project the image data onto the BEV plane to generate a color or intensity map.
 Picture
Picture
2. Perception module:
Perception in autonomous driving stage, the Transformer model can be used to extract features in multi-modal data, such as lidar point clouds, images, radar data, etc. By conducting end-to-end training on these data, Transformer can automatically learn the intrinsic structure and interrelationships of these data, thereby effectively identifying and locating obstacles in the environment.
Use the Transformer model to extract features from BEV data to detect and locate obstacles.
Superimpose these BEV format data together to form a multi-channel BEV image. Assume that the BEV height map of the lidar is H(x, y), the BEV range map of the radar is R(x, y), and the BEV intensity map of the camera is I(x, y), then the multi-channel BEV image can be expressed as :
##B(x, y) = [H(x, y), R(x, y), I(x, y)]
Where B(x, y) represents the pixel value of the multi-channel BEV image at coordinates (x, y), [] represents channel superposition.
3. Prediction module:
Based on the output of the perception module, use the Transformer model to predict the future behavior and trajectory of other traffic participants. By learning historical trajectory data, Transformer is able to capture the movement patterns and interactions of traffic participants, thereby providing more accurate predictions for autonomous driving systems.
Specifically, we first use Transformer to extract features from multi-channel BEV images. Assuming that the input BEV image is B(x, y), we can extract features F(x, y) through multi-layer self-attention mechanism and position encoding:
F(x, y) = Transformer(B(x, y))
where F(x, y) represents the feature map, the feature value at coordinates (x, y).
Then, we use the extracted features F(x, y) to predict the behaviors and trajectories of other traffic participants. Transformer's decoder can be used to generate prediction results, as follows:
P(t) = Decoder(F(x, y), t)
Where P(t) represents the prediction result at time t, and Decoder represents the Transformer decoder.
Through the above steps, we can achieve data fusion and prediction based on Transformer and BEV. The specific Transformer structure and parameter settings can be adjusted according to actual application scenarios to achieve optimal performance.
4. Decision-making module:
Based on the results of the prediction module, combined with traffic rules and vehicle dynamics models, the Transformer model is used to generate appropriate Driving strategy.
 picture
picture
By integrating environmental information, traffic rules and vehicle dynamics models into the model, Transformer can learn efficient and safe driving strategies. Such as path planning, speed planning, etc. In addition, using Transformer's multi-head self-attention mechanism, the weights between different information sources can be effectively balanced to make more reasonable decisions in complex environments.
The following are the specific steps to adopt this method:
1. Data collection and preprocessing:
First of all, a large amount of driving data needs to be collected, including vehicle status information (such as speed, acceleration, steering wheel angle, etc.), road condition information (such as road type, traffic signs, lane lines, etc.), surrounding environment information (such as other vehicles, pedestrians, cyclists, etc.) and the actions taken by the driver. These data are preprocessed, including data cleaning, standardization and feature extraction.
2. Data encoding and serialization:
Encode the collected data into a form suitable for Transformer model input. This typically involves discretizing continuous numerical data and converting the discretized data into vector form. At the same time, the data needs to be serialized so that the Transformer model can handle timing information.
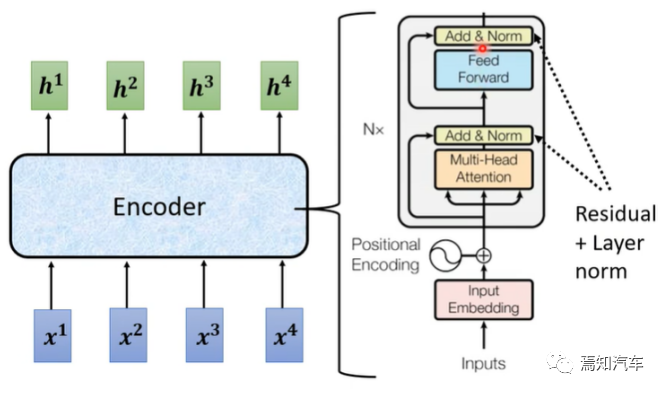
2.1. Transformer encoder
Transformer encoder consists of multiple identical sub-layers. Each sub-layer Contains two parts: Multi-Head Attention and Feed-Forward Neural Network.
Multi-head self-attention: First divide the input sequence into h different heads, calculate the self-attention of each head separately, and then splice the output of these heads together. This captures dependencies at different scales in the input sequence.
 Picture
Picture
The calculation formula of bull’s self-attention is:
MHA (X) = Concat(head_1, head_2, ..., head_h) * W_O
where MHA(X) represents the output of multi-head self-attention, and head_i represents the output of the i-th head , W_O is the output weight matrix.
Feedforward Neural Network: Next, the output of the multi-head self-attention is passed to the feedforward neural network. Feedforward neural networks usually contain two fully connected layers and an activation function (such as ReLU). The calculation formula of the feedforward neural network is:
FFN(x) = max(0, xW_1 b_1) * W_2 b_2
where FFN (x) represents the output of the feedforward neural network, W_1 and W_2 are weight matrices, b_1 and b_2 are bias vectors, and max(0, x) represents the ReLU activation function.
In addition, each sub-layer in the encoder contains residual connections and layer normalization (Layer Normalization), which helps to improve the training stability and convergence speed of the model.
2.2. Transformer decoder
Similar to the encoder, the Transformer decoder also consists of multiple layers of the same sub-layers. Each sub-layer consists of three parts: multi-head self-attention, encoder-decoder attention (Encoder-Decoder Attention) and feed-forward neural network.
Multi-head self-attention: The same as the multi-head self-attention in the encoder, used to calculate the degree of correlation between each element in the decoder input sequence.
Encoder-decoder attention: used to calculate the degree of correlation between the decoder input sequence and the encoder output sequence. The calculation method is similar to self-attention, except that the query vector comes from the decoder input sequence, and the key vector and value vector come from the encoder output sequence.
Feedforward neural network: Same as the feedforward neural network in the encoder. Each sub-layer in the decoder also contains residual connections and layer normalization. By stacking multiple layers of encoders and decoders, Transformer is able to handle sequence data with complex dependencies.
3. Build a Transformer model:
Build a Transformer model suitable for autonomous driving scenarios, including setting the appropriate number of layers and heads. and hidden layer size. In addition, the model also needs to be fine-tuned according to task requirements, such as using a driving policy to generate a loss function for the task.
First, the feature vector is obtained by MLP to obtain a low-dimensional vector, which is passed to the automatic regression path point network implemented by GRU, and used to initialize the hidden state of GRU. In addition, the current position and target position are also input, causing the network to focus on the relevant context of the hidden state.
 Picture
Picture
Use a single layer GRU and use a linear layer to predict the path point offset from the hidden state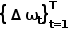 , get the predicted path point
, get the predicted path point 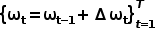 . The input to the GRU is the origin.
. The input to the GRU is the origin.
The controller uses two PID controllers to perform horizontal and longitudinal control respectively based on the predicted path points to obtain steering, braking and throttle values. Perform a weighted average of the path point vectors of consecutive frames, then the input of the longitudinal controller is its module length, and the input of the transverse controller is its orientation.
Calculate the L1 loss of the expert trajectory path points and predicted trajectory path points in the current frame's self-vehicle coordinate system, that is,
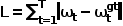
4. Training and verification:
Use the collected data set to train the Transformer model. During the training process, the model needs to be validated to check its generalization ability. The data set can be divided into training, validation, and test sets to evaluate the model.
5. Driving strategy generation:
In actual applications, pre-trained data is input based on the current vehicle status, road condition information and surrounding environment information. Transformer model. The model will generate driving strategies such as acceleration, deceleration, steering, etc. based on these inputs.
6. Driving strategy execution and optimization:
Pass the generated driving strategy to the automatic driving system to control the vehicle. At the same time, data from the actual execution process are collected for further optimization and iteration of the model.
Through the above steps, a method based on the Transformer model can be used to generate an appropriate driving strategy in the autonomous driving decision-making stage. It should be noted that due to the high safety requirements in the autonomous driving field, it is necessary to ensure the performance and safety of the model in various scenarios during actual deployment.
03 Examples of Transformer BEV technology solving Corner Case
In this section, we will introduce in detail three examples of BEV technology solving Corner Case Examples include complex road conditions, severe weather conditions, and predicting abnormal behavior. The following figure shows some cornercase scenarios in autonomous driving. The technology of Transformer BEV can effectively identify and deal with most of the edge scenes that can currently be identified.
 Picture
Picture
1. Handling complex road conditions
In complex road conditions Under conditions such as traffic jams, complex intersections or irregular road surfaces, Transformer BEV technology can provide more comprehensive environmental perception. By integrating images from multiple cameras around the vehicle, BEVs generate a continuous overhead view, allowing the autonomous driving system to clearly identify lane lines, obstacles, pedestrians and other traffic participants. For example, at a complex intersection, BEV technology can help the autonomous driving system accurately identify the location and driving direction of each traffic participant, thereby providing a reliable basis for path planning and decision-making.
2. Coping with bad weather conditions
In bad weather conditions, such as rain, snow, fog, etc., traditional cameras and lidar It may be affected and reduce the perception ability of the automatic driving system. Transformer BEV technology still has certain advantages in these situations because it can fuse image information from different angles, thereby improving the system's perception of the environment. In order to further enhance the performance of Transformer BEV technology in severe weather conditions, you can consider using auxiliary equipment such as infrared cameras or thermal imaging cameras to supplement the deficiencies of visible light cameras in these situations.
3. Predict abnormal behaviors
In the actual road environment, pedestrians, cyclists and other traffic participants may have abnormal behaviors, such as suddenly crossing the road, violating Traffic rules etc. BEV technology can help autonomous driving systems better predict these abnormal behaviors. With the global perspective, BEV can provide complete environmental information, allowing the autonomous driving system to more accurately track and predict the dynamics of pedestrians and other traffic participants. In addition, by combining machine learning and deep learning algorithms, Transformer BEV technology can further improve the prediction accuracy of abnormal behaviors, allowing the autonomous driving system to make more reasonable decisions in complex scenarios.
4. Narrow or blocked roads
In narrow or blocked road environments, traditional cameras and lidar may have difficulty obtaining adequate information for effective environmental perception. However, Transformer BEV technology can come into play in these situations because it can integrate images captured by multiple cameras to generate a more comprehensive view. This allows the autonomous driving system to better understand the environment around the vehicle, identify obstacles in narrow passages, and safely navigate these scenarios.
5. Merging vehicles and traffic merging
In scenarios such as highways, autonomous driving systems need to deal with complexities such as merging vehicles and traffic merging. Task. These tasks place high demands on the perception capabilities of the autonomous driving system, as the system needs to evaluate the position and speed of surrounding vehicles in real time to ensure safe merging and traffic merging. With Transformer BEV technology, the autonomous driving system can gain a global perspective and clearly understand the traffic conditions around the vehicle. This will help the autonomous driving system develop appropriate merging strategies to ensure that vehicles can safely integrate into the traffic flow.
6. Emergency response
In emergency situations, such as traffic accidents, road closures or emergencies, the autonomous driving system needs to be fast Make decisions to ensure safe driving. In these cases, Transformer BEV technology can provide real-time, comprehensive environmental awareness for the autonomous driving system, helping the system quickly assess the current road conditions. Combining real-time data and advanced path planning algorithms, autonomous driving systems can develop appropriate emergency strategies to avoid potential risks.
Through these examples, we can see that Transformer BEV technology has great potential in dealing with Corner Case. However, in order to give full play to the advantages of Transformer BEV technology, further research and development are still needed to improve performance in image processing capabilities, sensor fusion technology, and abnormal behavior prediction.
04 Conclusion
This article summarizes the principles and applications of Transformer and BEV technology in autonomous driving, especially how to solve the Corner Case problem. By providing a global perspective and accurate environmental perception, Transformer BEV technology is expected to improve the reliability and safety of autonomous driving systems in the face of extreme situations. However, current technology still has certain limitations, such as performance degradation in adverse weather conditions. Future research should continue to focus on the improvement of BEV technology and its integration with other sensing technologies to achieve a higher level of autonomous driving safety.
The above is the detailed content of How to use Transformer BEV to overcome extreme situations of autonomous driving?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
