
 Technology peripherals
AI
He can surpass humans in two hours! DeepMind's latest AI speedruns 26 Atari games
Technology peripherals
AI
He can surpass humans in two hours! DeepMind's latest AI speedruns 26 Atari games
He can surpass humans in two hours! DeepMind's latest AI speedruns 26 Atari games

DeepMind’s AI agent is trying to trick itself again!
Look, this guy named BBF mastered 26 Atari games in just 2 hours. His efficiency is as good as that of a human being, surpassing all his predecessors.
You must know that AI agents have always been effective in solving problems through reinforcement learning, but the biggest problem is that this method is very inefficient and requires a long time to explore.
 Picture
Picture
The breakthrough brought by BBF is precisely in terms of efficiency.
No wonder its full name can be called Bigger, Better, or Faster.
Moreover, it can complete training on only a single card, and the computing power requirements are also much reduced.
BBF was jointly proposed by Google DeepMind and the University of Montreal. The data and code are currently open source.
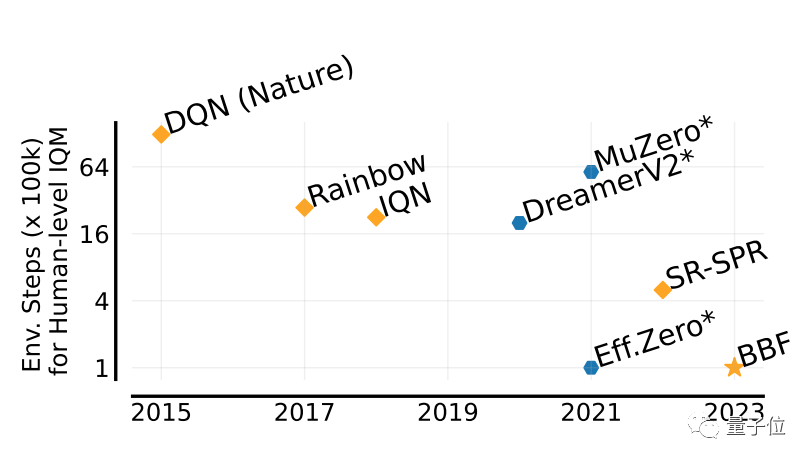
Can achieve up to 5 times the performance of humans
The value used to evaluate the performance of BBF games is called IQM.
IQM is a comprehensive score of multi-faceted game performance. The IQM scores in this article are normalized based on humans.
Compared with multiple previous results, BBF achieved the highest IQM score in the Atari 100K test data set containing 26 Atari games.
Moreover, in the 26 games trained, BBF's performance has exceeded that of humans.
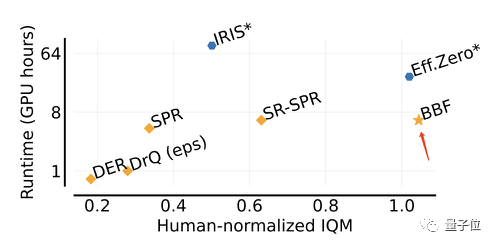
Compared with Eff.Zero, which performs similarly, BBF consumes nearly half the GPU time.
The performance of SPR and SR-SPR, which consume similar GPU time, is significantly different from BBF.
 Picture
Picture
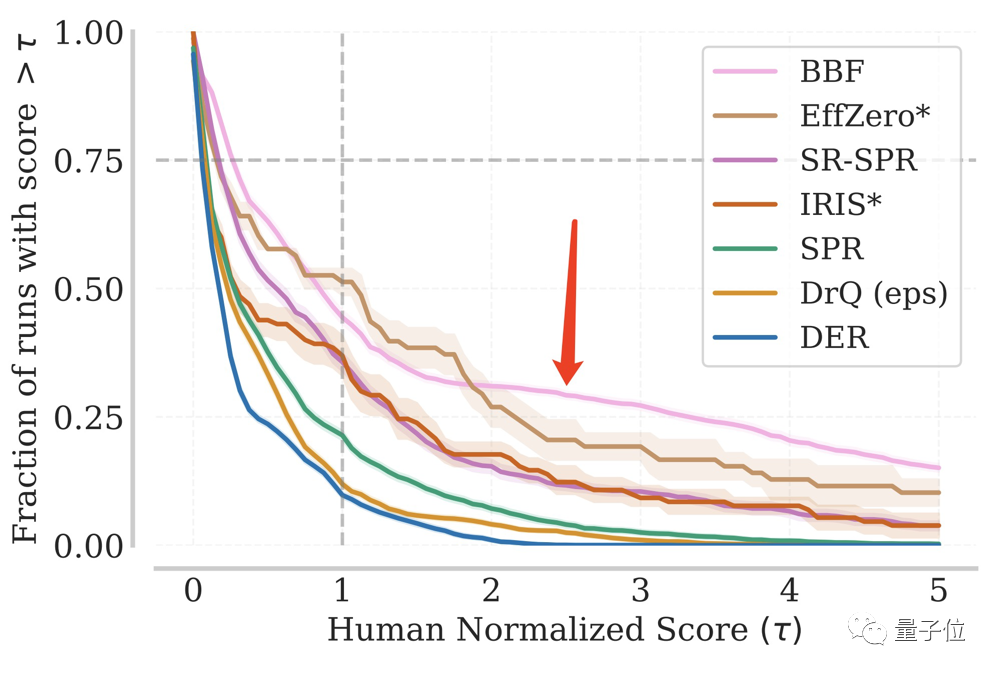
In repeated tests, the proportion of BBF reaching a certain IQM score has always remained at a high level.
Even in more than 1/8 of the total number of tests, it achieved 5 times the performance of humans.
 Picture
Picture
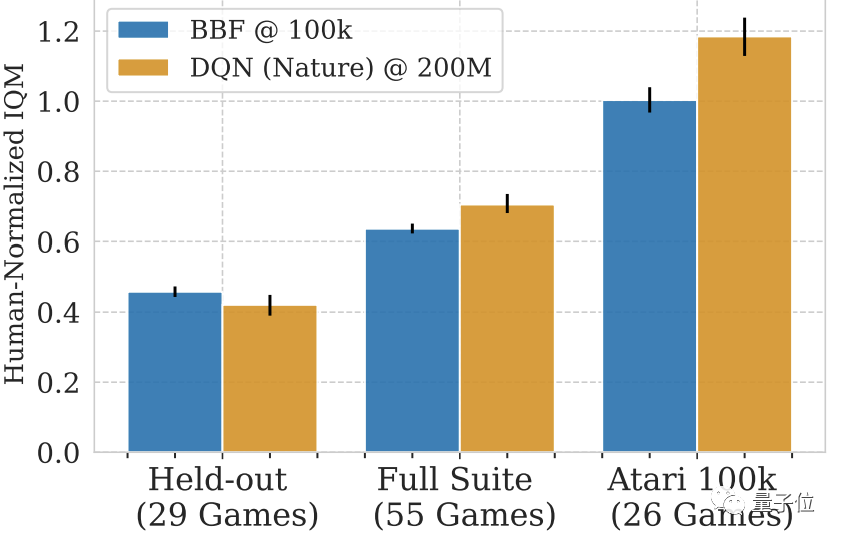
Even with other Atari games without training, BBF can achieve more than half the IQM score of a human.
If you look at the 29 untrained games alone, BBF's score is 40 to 50% that of humans.
 Picture
Picture
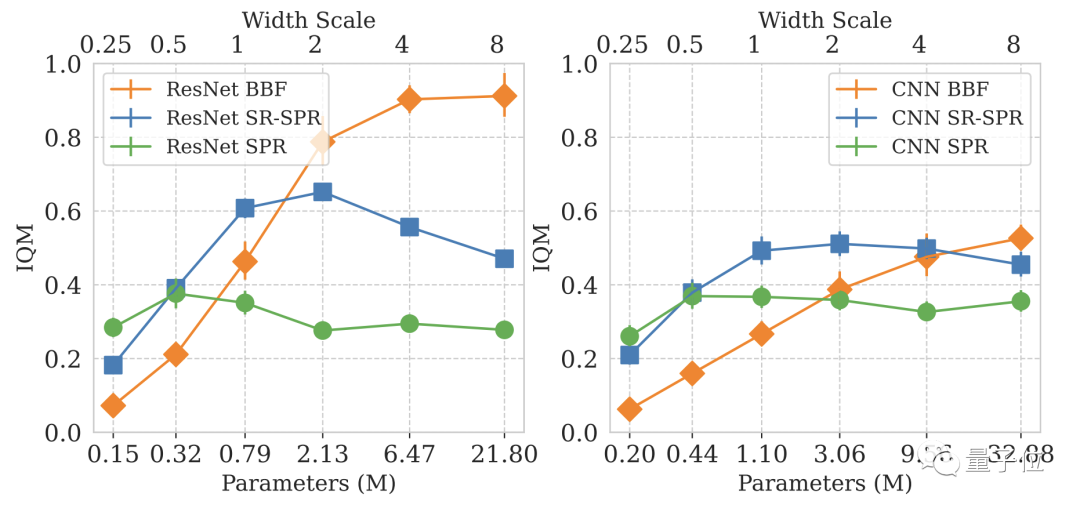
Modified based on SR-SPR
The problem that promotes BBF research is how to use it when the sample size is sparse Scaling deep reinforcement learning networks.
To study this problem, DeepMind focused its attention on the Atari 100K benchmark.
But DeepMind soon discovered that simply increasing the size of the model did not improve its performance.
 Picture
Picture
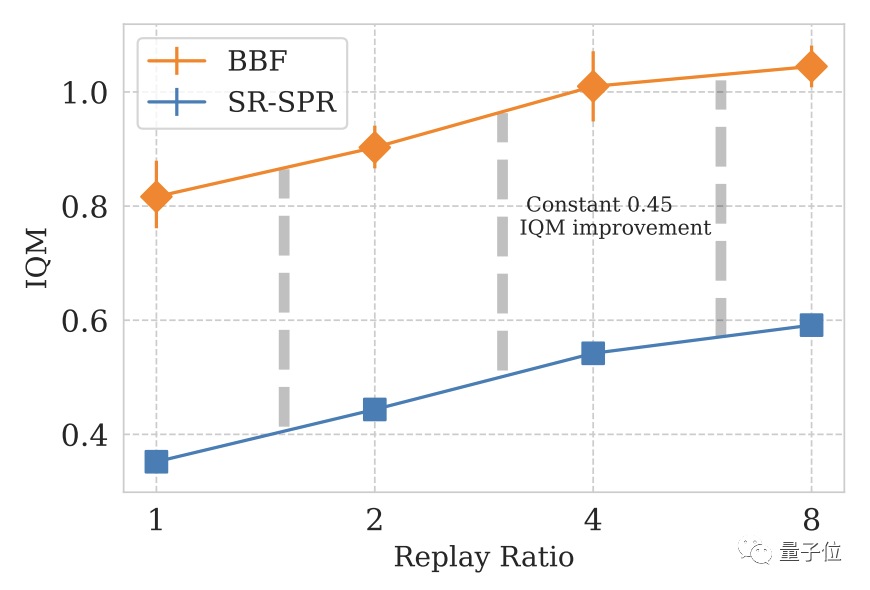
In the design of deep learning models, the number of updates per step (Replay Ratio, RR) is an important parameter.
Specifically for Atari games, the greater the RR value, the higher the model’s performance in the game.
In the end, DeepMind uses SR-SPR as the basic engine, and the RR value of SR-SPR can reach up to 16.
After comprehensive consideration, DeepMind chose 8 as the RR value of BBF.
Considering that some users are unwilling to spend the computing cost of RR=8, DeepMind also developed the RR=2 version of BBF
 Picture
Picture
After DeepMind modified many contents in SR-SPR, it used self-supervised training to obtain BBF, which mainly includes the following aspects:
- Higher convolution layer reset strength: Increasing the convolution layer reset strength can increase the perturbation amplitude for random targets, allowing the model to perform better and reduce losses. After the reset strength of BBF is increased, The perturbation amplitude increased from 20% of SR-SPR to 50%
- Larger network scale: increasing the number of neural network layers from 3 to 15 layers, and increasing the width by 4 times
- Reduced update range (n): If you want to improve the performance of the model, you need to use non-fixed n values. BBF is reset every 40,000 gradient steps. In the first 10,000 gradient steps of each reset, n decreases exponentially from 10 to 3. The decay phase accounts for 25% of the BBF training process
- Update Large attenuation factor (γ): Some people have found that increasing the γ value during the learning process can improve model performance. The γ value of BBF increases from the traditional 0.97 to 0.997
- Weight attenuation: avoid the occurrence of overfitting, The attenuation of BBF is about 0.1
- Delete NoisyNet: NoisyNet included in the original SR-SPR cannot improve model performance
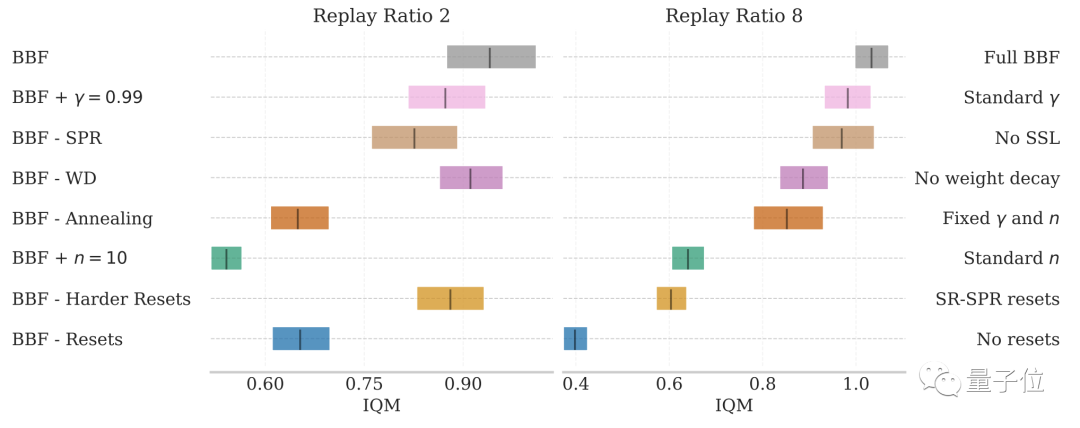
Ablation experimental results show that when the number of updates per step is 2 and Under the conditions of 8, the above factors have varying degrees of impact on the performance of BBF.
 Picture
Picture
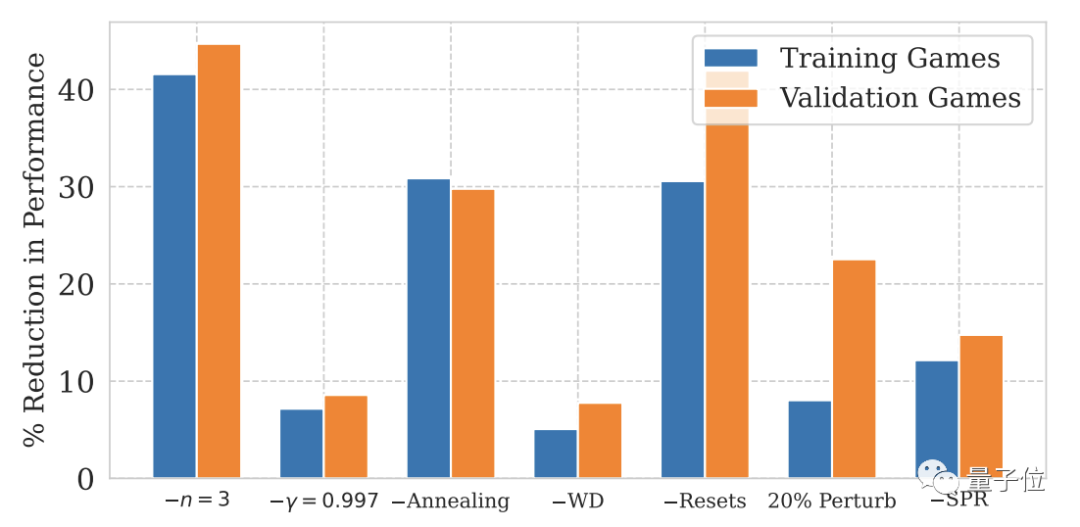
Among them, the impact of hard reset and reduction of update range is the most significant.
 Picture
Picture
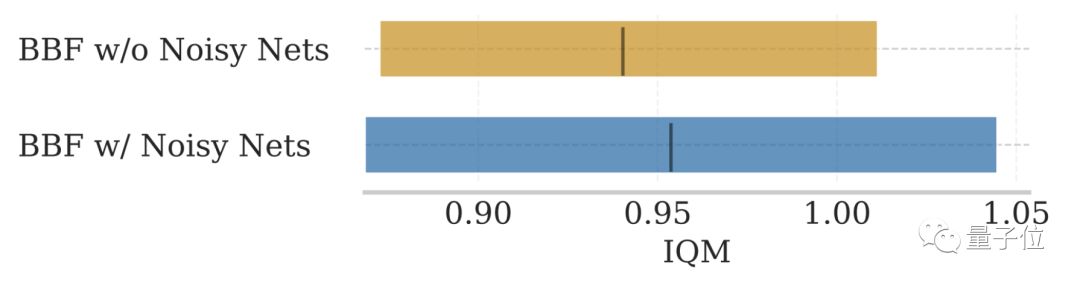
For NoisyNet, which is not mentioned in the above two figures, the impact on model performance is not significant.
 Picture
Picture
Reference link: [1]https://www.php.cn/link/69b4fa3be19bdf400df34e41b93636a4
[2]https://www.marktechpost.com/2023/06/12/superhuman-performance-on-the-atari-100k-benchmark-the-power-of-bbf-a-new-value -based-rl-agent-from-google-deepmind-mila-and-universite-de-montreal/
— End —
The above is the detailed content of He can surpass humans in two hours! DeepMind's latest AI speedruns 26 Atari games. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to configure Debian Apache log format
Apr 12, 2025 pm 11:30 PM
How to configure Debian Apache log format
Apr 12, 2025 pm 11:30 PM
This article describes how to customize Apache's log format on Debian systems. The following steps will guide you through the configuration process: Step 1: Access the Apache configuration file The main Apache configuration file of the Debian system is usually located in /etc/apache2/apache2.conf or /etc/apache2/httpd.conf. Open the configuration file with root permissions using the following command: sudonano/etc/apache2/apache2.conf or sudonano/etc/apache2/httpd.conf Step 2: Define custom log formats to find or
 How Tomcat logs help troubleshoot memory leaks
Apr 12, 2025 pm 11:42 PM
How Tomcat logs help troubleshoot memory leaks
Apr 12, 2025 pm 11:42 PM
Tomcat logs are the key to diagnosing memory leak problems. By analyzing Tomcat logs, you can gain insight into memory usage and garbage collection (GC) behavior, effectively locate and resolve memory leaks. Here is how to troubleshoot memory leaks using Tomcat logs: 1. GC log analysis First, enable detailed GC logging. Add the following JVM options to the Tomcat startup parameters: -XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log These parameters will generate a detailed GC log (gc.log), including information such as GC type, recycling object size and time. Analysis gc.log
 How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
In Debian systems, the readdir function is used to read directory contents, but the order in which it returns is not predefined. To sort files in a directory, you need to read all files first, and then sort them using the qsort function. The following code demonstrates how to sort directory files using readdir and qsort in Debian system: #include#include#include#include#include//Custom comparison function, used for qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 How to configure firewall rules for Debian syslog
Apr 13, 2025 am 06:51 AM
How to configure firewall rules for Debian syslog
Apr 13, 2025 am 06:51 AM
This article describes how to configure firewall rules using iptables or ufw in Debian systems and use Syslog to record firewall activities. Method 1: Use iptablesiptables is a powerful command line firewall tool in Debian system. View existing rules: Use the following command to view the current iptables rules: sudoiptables-L-n-v allows specific IP access: For example, allow IP address 192.168.1.100 to access port 80: sudoiptables-AINPUT-ptcp--dport80-s192.16
 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 How to learn Debian syslog
Apr 13, 2025 am 11:51 AM
How to learn Debian syslog
Apr 13, 2025 am 11:51 AM
This guide will guide you to learn how to use Syslog in Debian systems. Syslog is a key service in Linux systems for logging system and application log messages. It helps administrators monitor and analyze system activity to quickly identify and resolve problems. 1. Basic knowledge of Syslog The core functions of Syslog include: centrally collecting and managing log messages; supporting multiple log output formats and target locations (such as files or networks); providing real-time log viewing and filtering functions. 2. Install and configure Syslog (using Rsyslog) The Debian system uses Rsyslog by default. You can install it with the following command: sudoaptupdatesud
