
 Technology peripherals
AI
How amazing is the simple speech conversion model that supports cross-language, human voice and dog barking interchange, and only uses nearest neighbors?
Technology peripherals
AI
How amazing is the simple speech conversion model that supports cross-language, human voice and dog barking interchange, and only uses nearest neighbors?
How amazing is the simple speech conversion model that supports cross-language, human voice and dog barking interchange, and only uses nearest neighbors?

The voice world in which AI participates is really magical. It can not only change one person's voice to that of any other person, but also exchange voices with animals.
We know that the goal of speech conversion is to convert the source speech into the target speech while keeping the content unchanged. Recent any-to-any speech conversion methods improve naturalness and speaker similarity, but at the expense of greatly increased complexity. This means that training and inference become more expensive, making improvements difficult to evaluate and establish.
The question is, does high-quality speech conversion require complexity? In a recent paper from the University of Stellenbosch in South Africa, several researchers explored this issue.

- ##Paper address: https://arxiv.org/pdf/2305.18975.pdf
- GitHub address: https://bshall.github.io/knn-vc/
The research highlights are: They introduced K nearest neighbor speech conversion ( kNN-VC), a simple and powerful any-to-any speech conversion method. Instead of training an explicit transformation model, K-nearest neighbor regression is simply used.
Specifically, the researchers first used a self-supervised speech representation model to extract the feature sequence of the source utterance and the reference utterance, and then replaced each frame of the source representation with one in the reference. nearest neighbor to convert to the target speaker, and finally use a neural vocoder to synthesize the converted features to obtain the converted speech.
From the results, despite its simplicity, KNN-VC achieves comparable or even improved intelligibility in both subjective and objective evaluations compared to several baseline speech conversion systems Similarity to the speaker.
Let’s appreciate the effect of KNN-VC voice conversion. Looking first at human voice conversion, KNN-VC is applied to source and target speakers unseen in the LibriSpeech dataset.
Source voice00:11
##Synthetic voice 100:11
Synthetic Speech 200:11
KNN-VC also supports cross-language speech conversion, such as Spanish to German, German to Japanese, Chinese to Spanish.
Source Chinese00:08
Destination Spanish00:05
Synthetic Speech 300:08
What’s even more amazing is that KNN-VC can also combine human voices with dogs Bark swap.
Source Dog Barking00:09
Source Human Voice00:05
Synthetic Voice 400:08
##Synthetic Voice 500:05We next look at how KNN-VC runs and compares it with other jixian methods.
Method Overview and Experimental Results
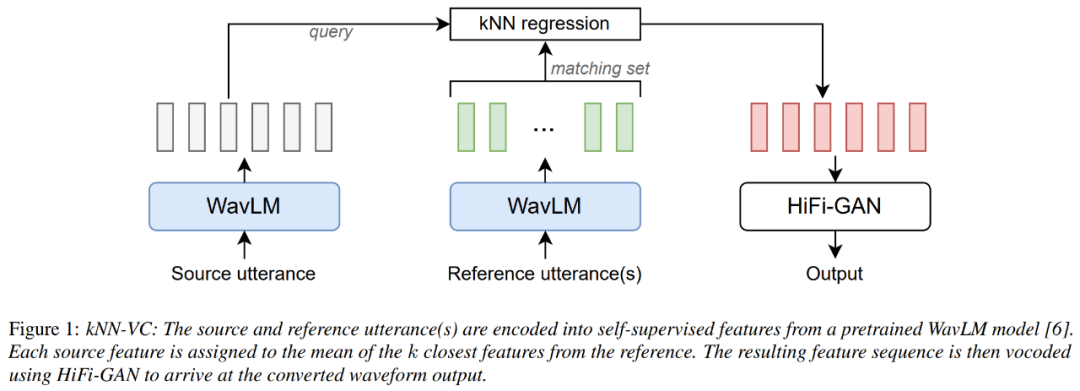
The architecture diagram of kNN-VC is as shown below, following the encoder-converter-vocoder structure. First the encoder extracts self-supervised representations of the source and reference speech, then the converter maps each source frame to their nearest neighbor in the reference, and finally the vocoder generates audio waveforms based on the converted features.
The encoder uses WavLM, the converter uses K nearest neighbor regression, and the vocoder uses HiFiGAN. The only component that requires training is the vocoder.
For the WavLM encoder, the researcher only used the pre-trained WavLM-Large model and did not do any training on it in the article. For the kNN transformation model, kNN is non-parametric and does not require any training. For the HiFiGAN vocoder, the original HiFiGAN author's repo was used to vocode the WavLM features, becoming the only part that required training.
Picture
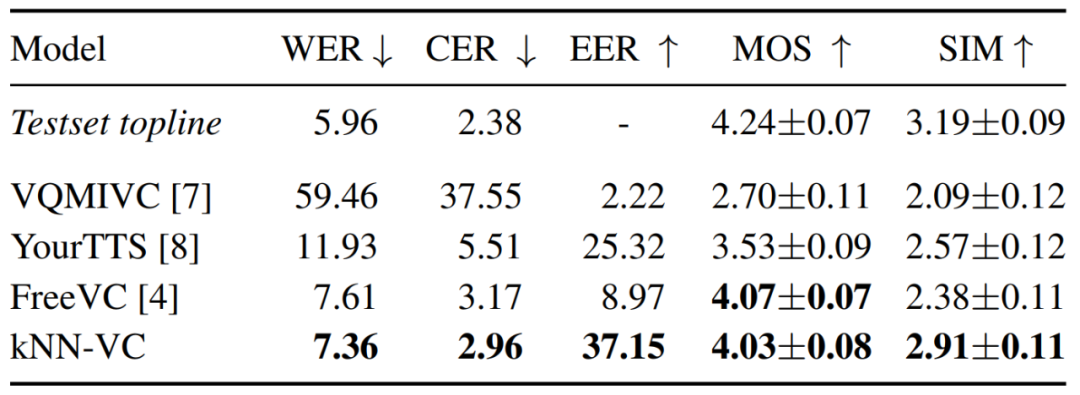
 In the experiment, the researchers first compared KNN-VC with other baseline methods, using the maximum available Target data (approximately 8 minutes of audio per speaker) to test the speech conversion system.
In the experiment, the researchers first compared KNN-VC with other baseline methods, using the maximum available Target data (approximately 8 minutes of audio per speaker) to test the speech conversion system.
For KNN-VC, the researcher uses all target data as the matching set. For the baseline method, they average speaker embeddings for each target utterance.
Table 1 below reports the results for intelligibility, naturalness, and speaker similarity for each model. As can be seen, kNN-VC achieves similar naturalness and clarity to the best baseline FreeVC, but with significantly improved speaker similarity. This also confirms the assertion of this article: high-quality speech conversion does not require increased complexity.
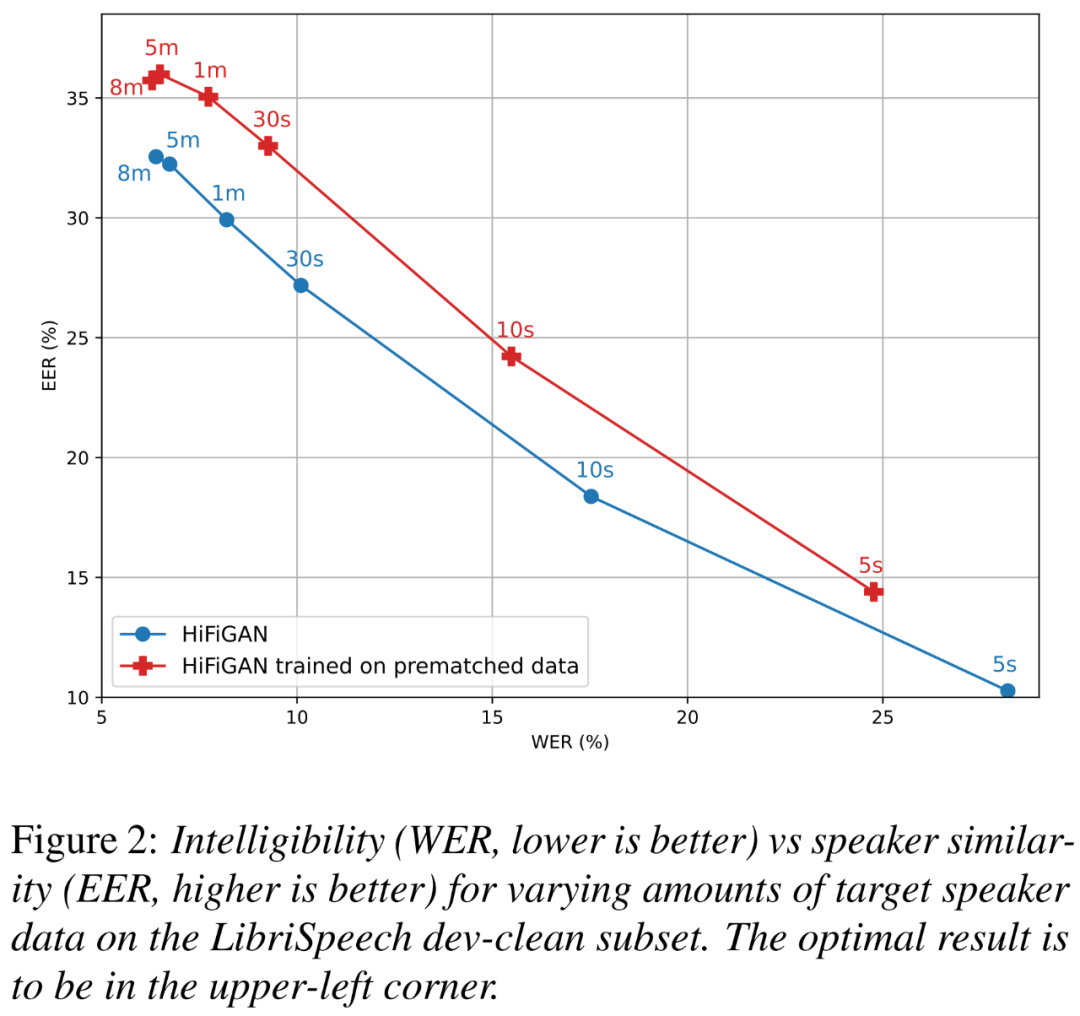
In addition, the researchers wanted to understand how much of the improvement was due to HiFi-GAN trained on pre-matched data, as well as target speaker data How much does size affect intelligibility and speaker similarity.
Figure 2 below shows the relationship between WER (smaller is better) and EER (higher is better) for two HiFi-GAN variants at different target speaker sizes.
 Picture
Picture
Netizen Comments
For this "only use nearest neighbors" "'s new speech conversion method kNN-VC, some people think that the pre-trained speech model is used in the article, so using "only" is not accurate. But it is undeniable that kNN-VC is still simpler than other models.
The results also demonstrate that kNN-VC is equally effective, if not the best, compared to very complex any-to-any speech conversion methods.
 Picture
Picture
Some people also said that the example of interchange of human voice and dog barking is very interesting.
 picture
picture
The above is the detailed content of How amazing is the simple speech conversion model that supports cross-language, human voice and dog barking interchange, and only uses nearest neighbors?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 What is the syntax for adding columns in SQL
Apr 09, 2025 pm 02:51 PM
What is the syntax for adding columns in SQL
Apr 09, 2025 pm 02:51 PM
The syntax for adding columns in SQL is ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value]; where table_name is the table name, column_name is the new column name, data_type is the data type, NOT NULL specifies whether null values are allowed, and DEFAULT default_value specifies the default value.
 SQL Clear Table: Performance Optimization Tips
Apr 09, 2025 pm 02:54 PM
SQL Clear Table: Performance Optimization Tips
Apr 09, 2025 pm 02:54 PM
Tips to improve SQL table clearing performance: Use TRUNCATE TABLE instead of DELETE, free up space and reset the identity column. Disable foreign key constraints to prevent cascading deletion. Use transaction encapsulation operations to ensure data consistency. Batch delete big data and limit the number of rows through LIMIT. Rebuild the index after clearing to improve query efficiency.
 Use DELETE statement to clear SQL tables
Apr 09, 2025 pm 03:00 PM
Use DELETE statement to clear SQL tables
Apr 09, 2025 pm 03:00 PM
Yes, the DELETE statement can be used to clear a SQL table, the steps are as follows: Use the DELETE statement: DELETE FROM table_name; Replace table_name with the name of the table to be cleared.
 phpmyadmin creates data table
Apr 10, 2025 pm 11:00 PM
phpmyadmin creates data table
Apr 10, 2025 pm 11:00 PM
To create a data table using phpMyAdmin, the following steps are essential: Connect to the database and click the New tab. Name the table and select the storage engine (InnoDB recommended). Add column details by clicking the Add Column button, including column name, data type, whether to allow null values, and other properties. Select one or more columns as primary keys. Click the Save button to create tables and columns.
 How to deal with Redis memory fragmentation?
Apr 10, 2025 pm 02:24 PM
How to deal with Redis memory fragmentation?
Apr 10, 2025 pm 02:24 PM
Redis memory fragmentation refers to the existence of small free areas in the allocated memory that cannot be reassigned. Coping strategies include: Restart Redis: completely clear the memory, but interrupt service. Optimize data structures: Use a structure that is more suitable for Redis to reduce the number of memory allocations and releases. Adjust configuration parameters: Use the policy to eliminate the least recently used key-value pairs. Use persistence mechanism: Back up data regularly and restart Redis to clean up fragments. Monitor memory usage: Discover problems in a timely manner and take measures.
 How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
Creating an Oracle database is not easy, you need to understand the underlying mechanism. 1. You need to understand the concepts of database and Oracle DBMS; 2. Master the core concepts such as SID, CDB (container database), PDB (pluggable database); 3. Use SQL*Plus to create CDB, and then create PDB, you need to specify parameters such as size, number of data files, and paths; 4. Advanced applications need to adjust the character set, memory and other parameters, and perform performance tuning; 5. Pay attention to disk space, permissions and parameter settings, and continuously monitor and optimize database performance. Only by mastering it skillfully requires continuous practice can you truly understand the creation and management of Oracle databases.
 How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
To create an Oracle database, the common method is to use the dbca graphical tool. The steps are as follows: 1. Use the dbca tool to set the dbName to specify the database name; 2. Set sysPassword and systemPassword to strong passwords; 3. Set characterSet and nationalCharacterSet to AL32UTF8; 4. Set memorySize and tablespaceSize to adjust according to actual needs; 5. Specify the logFile path. Advanced methods are created manually using SQL commands, but are more complex and prone to errors. Pay attention to password strength, character set selection, tablespace size and memory
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
