
 Technology peripherals
It Industry
Highly anticipated! Baojun Yunduo will be launched soon with a price of less than 150,000 yuan
Technology peripherals
It Industry
Highly anticipated! Baojun Yunduo will be launched soon with a price of less than 150,000 yuan
Highly anticipated! Baojun Yunduo will be launched soon with a price of less than 150,000 yuan

Baojun Auto officials are actively conducting warm-up activities for the upcoming new model Baojun Yunduo. As far as the editor understands, today the official announced the appearance details of the car again. The new car is inspired by the aesthetics of the sky and has a unique design that is quite recognizable. The appearance of Baojun Cloud is like a walking cloud, round and full. At the same time, the body adopts 16 low-wind resistance streamline designs, adding to the light and agile feeling.

According to official news, Baojun Cloud will provide three different cloud colors, including Yunhai White, Dusk Cloud Purple and Smoke Cloud Green. These color options further accentuate the model's sky theme. In addition, the new car is also equipped with a series of unique lighting designs. The through-type "Skyline skyline" daytime running lights are 1.7 meters long, while the "Horizon horizon" through-type rear taillights integrate functions such as brake lights, turn signals and position lights. This new car is equipped with standard automatic LED headlights. The low beam illumination angle can reach 45 degrees, the illumination distance can exceed 80 meters, and the high beam illumination distance can exceed 150 meters. When turning, the new car will automatically light up the built-in corner lights, thereby improving driving safety.

Baojun Yunduo also has highlights in the skylight design. A wide "cloud top" canopy is installed on the roof, measuring 1.8 meters long and 1.2 meters wide, with a total area of more than 2 square meters and a lighting area of 4 square meters. According to the official introduction, the canopy of the new car is made of gray glass sandwich material with a high UV protection rate of 99.9%. Moreover, the driver can also control the electric sunshade through voice control, which is convenient and practical.
In addition, Baojun Yunduo also has many practical functions. The vehicle is equipped with a size of 215/55 R18’s five-spoke low-wind resistance wheels have a stylish and dynamic appearance. The lateral width of the electric tailgate reaches 1153 mm, the maximum vertical opening height reaches 1840 mm, and the opening and closing angle can reach 70 degrees. In addition, the electric tailgate supports voice control and has anti-pinch and memory functions. In addition, the new car is also equipped with a multifunctional rearview mirror with rich functions, including turn signals, electric heating, electric adjustment, electric folding, blind spot reminder, and 360 camera.

The price of Baojun Yunduo is expected to be less than 150,000 yuan, and the specific time for its official launch will be announced soon. Consumers are full of expectations for this new Baojun car, which is designed with sky aesthetics as its design inspiration. As the official releases more detailed information, it is believed that this model will bring a new driving experience to consumers.
The above is the detailed content of Highly anticipated! Baojun Yunduo will be launched soon with a price of less than 150,000 yuan. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
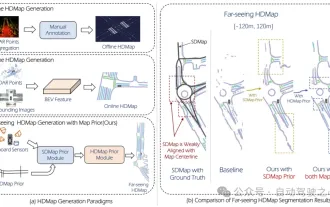 Mass production killer! P-Mapnet: Using the low-precision map SDMap prior, the mapping performance is violently improved by nearly 20 points!
Mar 28, 2024 pm 02:36 PM
Mass production killer! P-Mapnet: Using the low-precision map SDMap prior, the mapping performance is violently improved by nearly 20 points!
Mar 28, 2024 pm 02:36 PM
As written above, one of the algorithms used by current autonomous driving systems to get rid of dependence on high-precision maps is to take advantage of the fact that the perception performance in long-distance ranges is still poor. To this end, we propose P-MapNet, where the “P” focuses on fusing map priors to improve model performance. Specifically, we exploit the prior information in SDMap and HDMap: on the one hand, we extract weakly aligned SDMap data from OpenStreetMap and encode it into independent terms to support the input. There is a problem of weak alignment between the strictly modified input and the actual HD+Map. Our structure based on the Cross-attention mechanism can adaptively focus on the SDMap skeleton and bring significant performance improvements;
 LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
Written above & the author’s personal understanding: This paper is dedicated to solving the key challenges of current multi-modal large language models (MLLMs) in autonomous driving applications, that is, the problem of extending MLLMs from 2D understanding to 3D space. This expansion is particularly important as autonomous vehicles (AVs) need to make accurate decisions about 3D environments. 3D spatial understanding is critical for AVs because it directly impacts the vehicle’s ability to make informed decisions, predict future states, and interact safely with the environment. Current multi-modal large language models (such as LLaVA-1.5) can often only handle lower resolution image inputs (e.g.) due to resolution limitations of the visual encoder, limitations of LLM sequence length. However, autonomous driving applications require
 Will the autonomous driving annotation industry be subverted by the world model in 2024?
Mar 01, 2024 pm 10:37 PM
Will the autonomous driving annotation industry be subverted by the world model in 2024?
Mar 01, 2024 pm 10:37 PM
1. Problems faced by data annotation (especially based on BEV tasks) With the rise of BEV transformer-based tasks, the dependence on data has become heavier and heavier, and the annotation based on BEV tasks has also become more and more complex. important. At present, whether it is 2D-3D joint obstacle annotation, lane line annotation based on reconstructed point cloud clips or Occpuancy task annotation, it is still too expensive (compared with 2D annotation tasks, it is much more expensive). Of course, there are also many semi-automatic or automated annotation studies based on large models in the industry. On the other hand, the data collection cycle for autonomous driving is too long and involves a series of data compliance issues. For example, you want to capture the field of a flatbed truck across the camera.
 The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
A purely visual annotation solution mainly uses vision plus some data from GPS, IMU and wheel speed sensors for dynamic annotation. Of course, for mass production scenarios, it doesn’t have to be pure vision. Some mass-produced vehicles will have sensors like solid-state radar (AT128). If we create a data closed loop from the perspective of mass production and use all these sensors, we can effectively solve the problem of labeling dynamic objects. But there is no solid-state radar in our plan. Therefore, we will introduce this most common mass production labeling solution. The core of a purely visual annotation solution lies in high-precision pose reconstruction. We use the pose reconstruction scheme of Structure from Motion (SFM) to ensure reconstruction accuracy. But pass
