

After the Stable Diffusion open source graph model, "AI art" has been completely democratized. Only a consumer-grade graphics card can be used to create very beautiful pictures.
In the field of text-to-video conversion, currently the only high-quality commercial Gen-2 model launched by Runway not long ago is the only model that can compete in the open source industry.
Recently, an author on Huggingface released a text-to-video-synthesis model Zeroscope_v2, which was developed based on the ModelScope-text-to-video-synthesis model with 1.7 billion parameters.
 Picture
Picture
Model link: https://huggingface.co/cerspense/zeroscope_v2_576w
Compared with the original version, the video generated by Zeroscope has no watermark, and the smoothness and resolution have been improved to adapt to the 16:9 aspect ratio.
Developer cerspense said that his goal is to compete with Gen-2 as an open source, that is, while improving the quality of the model, it can also be freely used by the public.
Zeroscope_v2 includes two versions. Among them, Zeroscope_v2 567w can quickly generate a video with a resolution of 576x320 pixels and a frame rate of 30 frames/second. It can be used for rapid verification of video concepts and only requires about It can run with 7.9GB of video memory.
Use Zeroscope_v2 XL to generate high-definition video with a resolution of 1024x576 and occupy approximately 15.3GB of video memory.
Zeroscope can also be used with the music generation tool MusicGen to quickly create a purely original short video.
The training of the Zeroscope model used 9923 video clips (clips) and 29769 annotated frames, each clip including 24 frames. Offset noise includes random shifts of objects within video frames, slight changes in frame timings, or small distortions.
Introducing noise during training can enhance the model's understanding of the data distribution, allowing it to generate more diverse and realistic videos and more effectively account for changes in text descriptions.
Use stable diffusion webui
In Huggingface Download the weight file in the zs2_XL directory and put it in the stable-diffusion-webui\models\ModelScope\t2v directory.
When generating videos, the recommended noise reduction intensity value is 0.66 to 0.85
Use Colab
## Note link: https://colab.research.google.com/drive/1TsZmatSu1-1lNBeOqz3_9Zq5P2c0xTTq?usp=sharing
First click the run button under Step 1 and wait for the installation, which will take about 3 minutes;
 Picture
Picture
When a green check mark appears next to the button, proceed to the next step.
 Picture
Picture
#Click the run button near the model you want to install, in order to quickly obtain a clip of about 3 seconds in Colab For videos, it is more recommended to use the low-resolution ZeroScope model (576 or 448).
 Picture
Picture
When executing higher resolution models such as Potat 1 or ZeroScope XL, there is a trade-off in execution time longer.
Wait for the check mark to appear again to proceed to the next step.
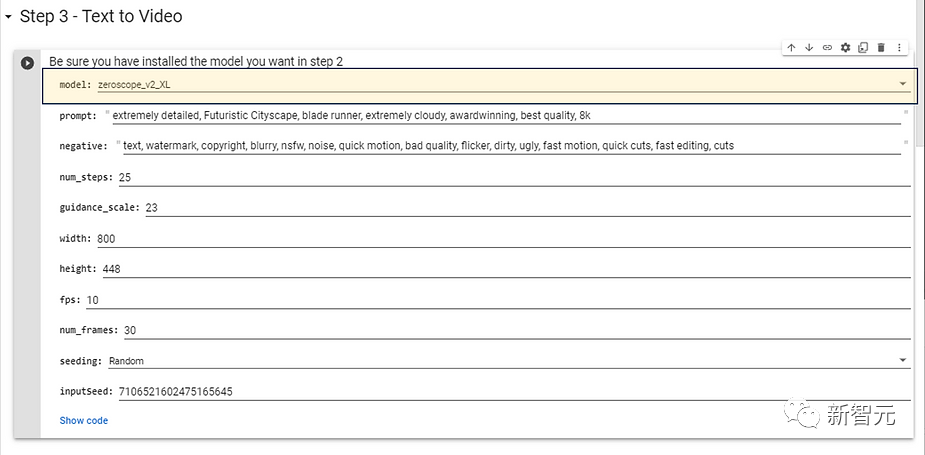
Select the model model installed in Step 2 and want to use it. For higher resolution models, the following configuration parameters are recommended, which do not require too long generation time.
 Picture
Picture
Next, you can enter the prompt word of the target video to change the effect, and you can also enter the negative prompt word (negative prompts) and click the Run button.
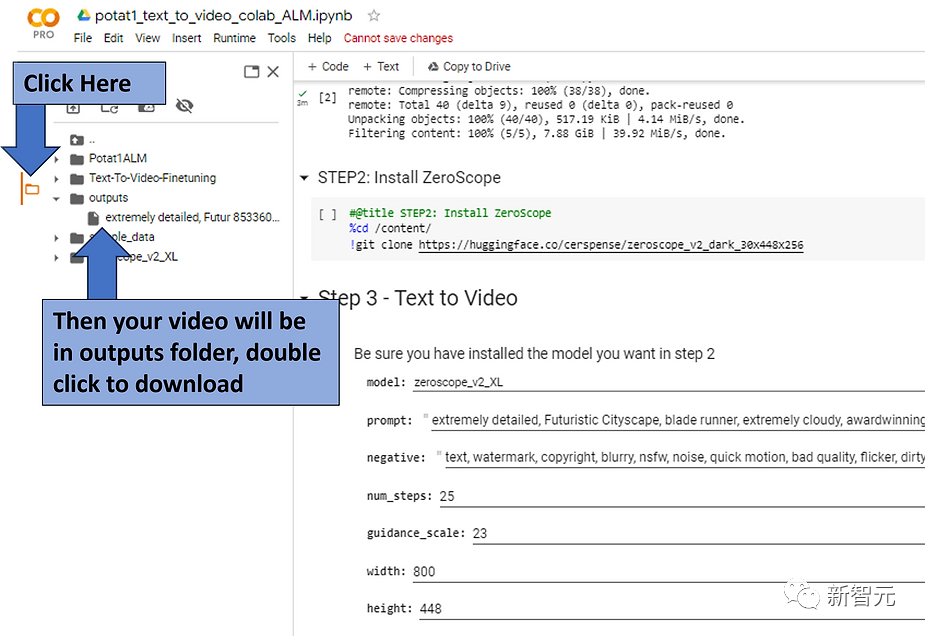
After waiting for a while, the generated video will be placed in the outputs directory.
 picture
picture
Currently, the field of Vincentian video is still in its infancy. Even the best tools can only generate videos of a few seconds, and there are usually relatively large Large visual defects.
But in fact, the Vincentian model initially faced similar problems, but it achieved photorealism only a few months later.
However, unlike the Vincentian graph model, the video field requires more resources during training and generation than images.
Although Google has developed Phenaki and Imagen Video models that can generate high-resolution, longer, and logically coherent video clips, these two models are not available to the public; Meta The Make-a-Video model is also not released.
The currently available tools are still only Runway’s commercial model Gen-2. The release of Zeroscope also marks the emergence of the first high-quality open source model in the Vincent video field.
The above is the detailed content of A new outlet for AI? The first high-quality 'Vinson Video' model Zeroscope triggers an open source war: it can run with a minimum of 8G video memory. For more information, please follow other related articles on the PHP Chinese website!
 setInterval
setInterval
 What is the shortcut key for brush size?
What is the shortcut key for brush size?
 Detailed explanation of linux dd command
Detailed explanation of linux dd command
 How to solve disk parameter errors
How to solve disk parameter errors
 What are the SEO diagnostic methods?
What are the SEO diagnostic methods?
 What are the css3 gradient properties?
What are the css3 gradient properties?
 The most promising coin in 2024
The most promising coin in 2024
 What does pycharm mean when running in parallel?
What does pycharm mean when running in parallel?
 The difference between PD fast charging and general fast charging
The difference between PD fast charging and general fast charging








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



