
 Technology peripherals
AI
Extend the context length to 256k, is the unlimited context version of LongLLaMA coming?
Technology peripherals
AI
Extend the context length to 256k, is the unlimited context version of LongLLaMA coming?
Extend the context length to 256k, is the unlimited context version of LongLLaMA coming?

In February this year, Meta released the LLaMA large-scale language model series, which successfully promoted the development of open source chat robots. Because LLaMA has fewer parameters than many previously released large models (the number of parameters ranges from 7 billion to 65 billion), but has better performance. For example, the largest LLaMA model with 65 billion parameters is comparable to Google's Chinchilla-70B and PaLM-540B. , so many researchers were excited once it was released.
However, LLaMA is only licensed for use by academic researchers, thus limiting the commercial application of the model.
Therefore, researchers began to look for those LLaMAs that could be used for commercial purposes. The project OpenLLaMA initiated by Hao Liu, a doctoral student at UC Berkeley, is one of the more popular open source copies of LLaMA. Using exactly the same preprocessing and training hyperparameters as the original LLaMA, it can be said that OpenLLaMA completely follows the training steps of LLaMA. Most importantly, the model is commercially available.
OpenLLaMA was trained on the RedPajama data set released by Together. There are three model versions, namely 3B, 7B and 13B. These models have been trained with 1T tokens. The results show that OpenLLaMA's performance is comparable to or even surpasses that of the original LLaMA in multiple tasks.
In addition to constantly releasing new models, researchers are constantly exploring the model's ability to handle tokens.
A few days ago, the latest research by Tian Yuandong’s team extended the LLaMA context to 32K with less than 1000 steps of fine-tuning. Going back further, GPT-4 supports 32k tokens (which is equivalent to 50 pages of text), Claude can handle 100k tokens (roughly equivalent to summarizing the first part of "Harry Potter" in one click) and so on.
Now, a new large-scale language model based on OpenLLaMA is coming, which extends the length of the context to 256k tokens and even more. The research was jointly completed by IDEAS NCBR, the Polish Academy of Sciences, the University of Warsaw, and Google DeepMind.
 Picture
Picture
LongLLaMA is completed based on OpenLLaMA, and the fine-tuning method uses FOT (Focused Transformer). This paper shows that FOT can be used to fine-tune already existing large models to extend their context length.
The study uses the OpenLLaMA-3B and OpenLLaMA-7B models as a starting point and fine-tunes them using FOT. The resulting models, called LONGLLAMAs, are able to extrapolate beyond the length of their training context (even up to 256K) and maintain performance on short-context tasks.
- Project address: https://github.com/CStanKonrad/long_llama
- Paper address: https://arxiv. org/pdf/2307.03170.pdf
Some people describe this research as an infinite context version of OpenLLaMA. With FOT, the model can be easily extrapolated to longer sequences, such as A model trained on 8K tokens can be easily extrapolated to a 256K window size.
 Picture
Picture
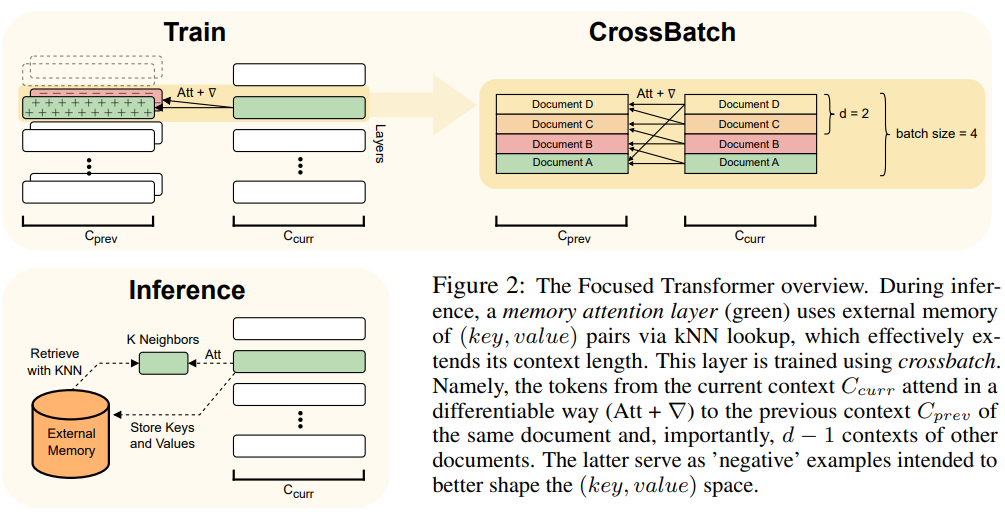
This article uses the FOT method, which is a plug-and-play extension in the Transformer model and can be used Train new models or fine-tune existing larger models with longer context.
To achieve this, FOT uses a memory attention layer and a cross-batch training process:
- The memory attention layer enables the model to retrieve information from external memory at inference time, effectively extending the context;
- The cross-batch training process makes the model tend to learn (key, value ) representation, these representations are very easy to use for the memory attention layer.
For an overview of the FOT architecture, see Figure 2:
 Picture
Picture
The following table shows some model information of LongLLaMA:
 Picture
Picture
Finally, the project also provides LongLLaMA and Comparison results of the original OpenLLaMA model.
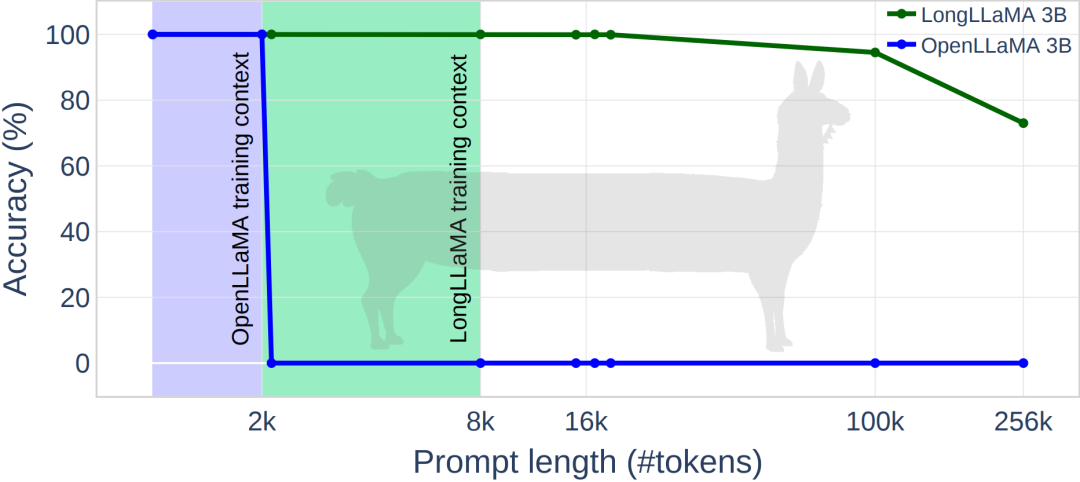
The following figure shows some experimental results of LongLLaMA. On the password retrieval task, LongLLaMA achieved good performance. Specifically, the LongLLaMA 3B model far exceeded its training context length of 8K, achieving 94.5% accuracy for 100k tokens and 73% accuracy for 256k tokens.
 Picture
Picture
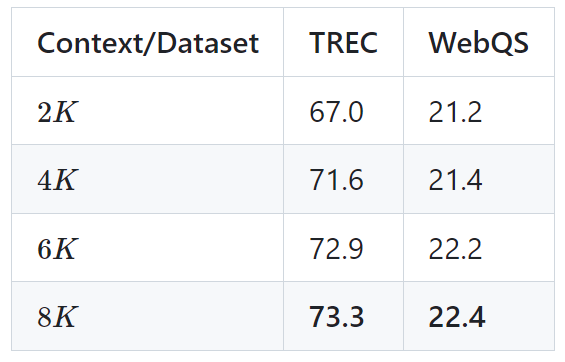
The following table shows the performance of the LongLLaMA 3B model on two downstream tasks (TREC question classification and WebQS question answering) As a result, the results show that LongLLaMA performance improves significantly when using long contexts.
 Picture
Picture
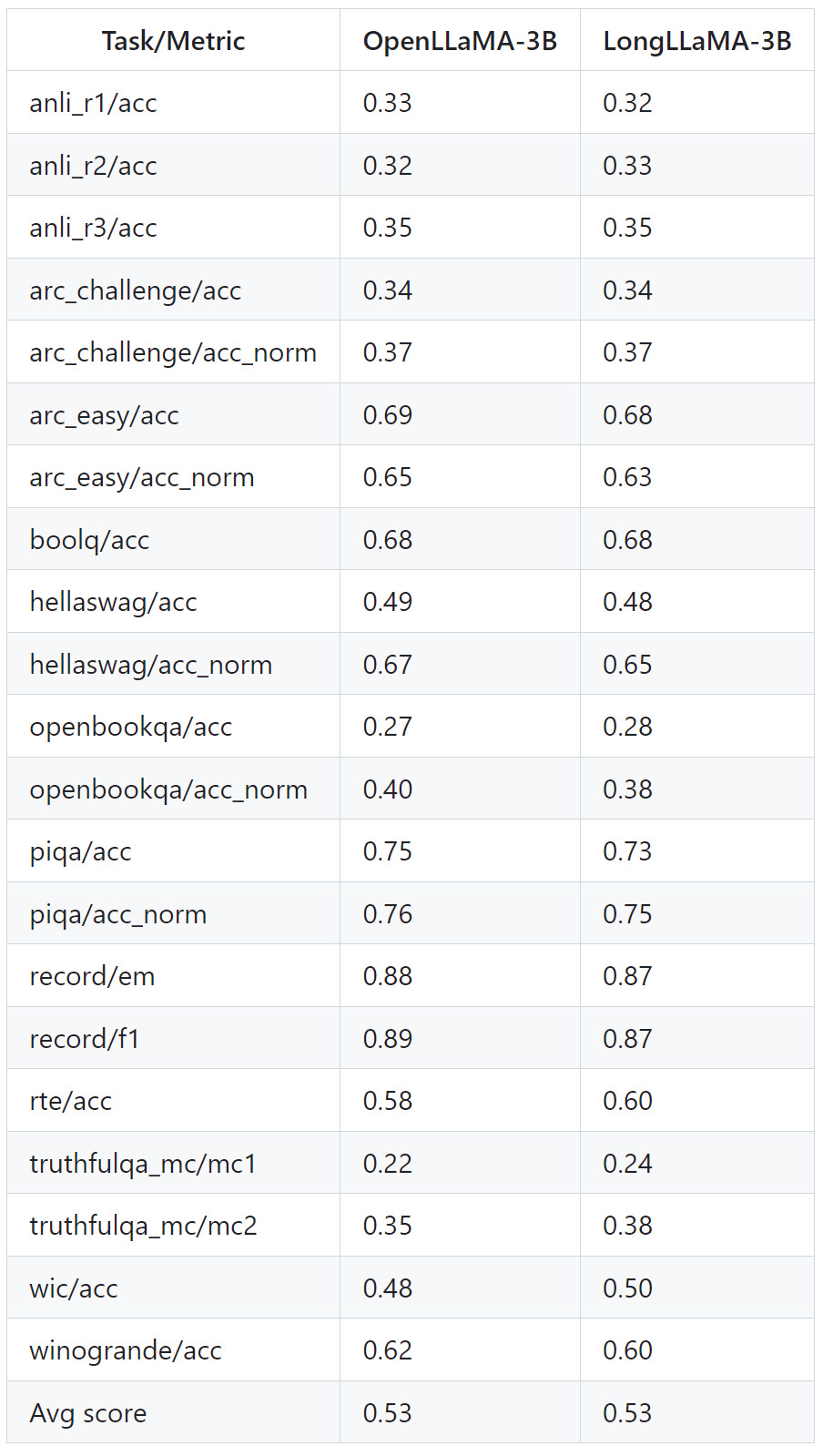
The table below shows that LongLLaMA performs well even on tasks that do not require long context. The experiments compare LongLLaMA and OpenLLaMA in a zero-sample setting.
 Picture
Picture
For more details, please refer to the original paper and project.
The above is the detailed content of Extend the context length to 256k, is the unlimited context version of LongLLaMA coming?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to output a countdown in C language
Apr 04, 2025 am 08:54 AM
How to output a countdown in C language
Apr 04, 2025 am 08:54 AM
How to output a countdown in C? Answer: Use loop statements. Steps: 1. Define the variable n and store the countdown number to output; 2. Use the while loop to continuously print n until n is less than 1; 3. In the loop body, print out the value of n; 4. At the end of the loop, subtract n by 1 to output the next smaller reciprocal.
 How to play picture sequences smoothly with CSS animation?
Apr 04, 2025 pm 05:57 PM
How to play picture sequences smoothly with CSS animation?
Apr 04, 2025 pm 05:57 PM
How to achieve the playback of pictures like videos? Many times, we need to implement similar video player functions, but the playback content is a sequence of images. direct...
 CS-Week 3
Apr 04, 2025 am 06:06 AM
CS-Week 3
Apr 04, 2025 am 06:06 AM
Algorithms are the set of instructions to solve problems, and their execution speed and memory usage vary. In programming, many algorithms are based on data search and sorting. This article will introduce several data retrieval and sorting algorithms. Linear search assumes that there is an array [20,500,10,5,100,1,50] and needs to find the number 50. The linear search algorithm checks each element in the array one by one until the target value is found or the complete array is traversed. The algorithm flowchart is as follows: The pseudo-code for linear search is as follows: Check each element: If the target value is found: Return true Return false C language implementation: #include#includeintmain(void){i
 Integers in C: a little history
Apr 04, 2025 am 06:09 AM
Integers in C: a little history
Apr 04, 2025 am 06:09 AM
Integers are the most basic data type in programming and can be regarded as the cornerstone of programming. The job of a programmer is to give these numbers meanings. No matter how complex the software is, it ultimately comes down to integer operations, because the processor only understands integers. To represent negative numbers, we introduced two's complement; to represent decimal numbers, we created scientific notation, so there are floating-point numbers. But in the final analysis, everything is still inseparable from 0 and 1. A brief history of integers In C, int is almost the default type. Although the compiler may issue a warning, in many cases you can still write code like this: main(void){return0;} From a technical point of view, this is equivalent to the following code: intmain(void){return0;}
 How to implement nesting effect of text annotations in Quill editor?
Apr 04, 2025 pm 05:21 PM
How to implement nesting effect of text annotations in Quill editor?
Apr 04, 2025 pm 05:21 PM
A solution to implement text annotation nesting in Quill Editor. When using Quill Editor for text annotation, we often need to use the Quill Editor to...
 What does the return value of 56 or 65 mean by C language function?
Apr 04, 2025 am 06:15 AM
What does the return value of 56 or 65 mean by C language function?
Apr 04, 2025 am 06:15 AM
When a C function returns 56 or 65, it indicates a specific event. These numerical meanings are defined by the function developer and may indicate success, file not found, or read errors. Replace these "magic numbers" with enumerations or macro definitions can improve readability and maintainability, such as: READ_SUCCESS, FILE_NOT_FOUND, and READ_ERROR.
 Zustand asynchronous operation: How to ensure the latest state obtained by useStore?
Apr 04, 2025 pm 02:09 PM
Zustand asynchronous operation: How to ensure the latest state obtained by useStore?
Apr 04, 2025 pm 02:09 PM
Data update problems in zustand asynchronous operations. When using the zustand state management library, you often encounter the problem of data updates that cause asynchronous operations to be untimely. �...
 What determines the return value type of C language function?
Apr 04, 2025 am 06:42 AM
What determines the return value type of C language function?
Apr 04, 2025 am 06:42 AM
The return value type of the function is determined by the return type specified when the function is defined. Common types include int, float, char, and void (indicating that no value is returned). The return value type must be consistent with the actual returned value in the function body, otherwise it will cause compiler errors or unpredictable behavior. When returning a pointer, you must make sure that the pointer points to valid memory, otherwise it may cause a segfault. When dealing with return value types, error handling and resource release (such as dynamically allocated memory) need to be considered to write robust and reliable code.
