
 Technology peripherals
AI
Industrial practice of Tencent TRS' meta-learning and cross-domain recommendation
Technology peripherals
AI
Industrial practice of Tencent TRS' meta-learning and cross-domain recommendation
Industrial practice of Tencent TRS' meta-learning and cross-domain recommendation


##1. Meta-learning
1. Pain points of personalized modeling
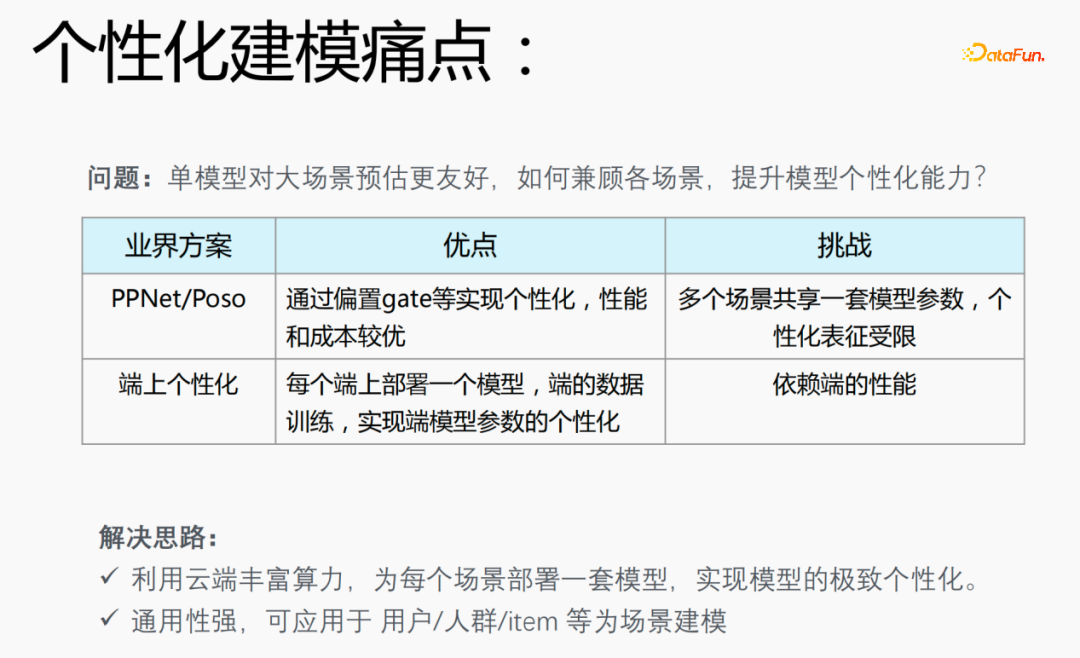
In the recommendation scenario, you will encounter the problem of 28-20 data distribution. 20% of the scenarios apply 80% of the samples, which leads to a problem: a single model is more friendly to large-scale scenario estimation. How to take into account various scenarios and improve model personalization capabilities is a pain point in personalized modeling.
Industry solution:- PPNet/Poso: This model achieves personalization through offset gate, etc., and has better performance and cost, but Multiple scenarios share a set of model parameters, and personalized representation is limited.
- End-on-end personalization: Deploy a model on each end, use the real-time data on the end for training, and realize the personalization of end-end model parameters, but It will depend on the performance of the terminal, and the model cannot be particularly large, so a small model needs to be used for training.
In view of the problems existing in the industry model, we have proposed the following solutions:
- Utilize the rich computing power of the cloud to deploy a set of models for each scenario to achieve ultimate personalization of the model;
- The model is highly versatile and can be applied to users/ Personalized modeling scenarios such as crowd/item.
#2. Meta-learning solves the problem of model personalization

- Requirements: Deploy a set of personalized models for each user and group of people. The model has no loss in cost and performance.
- Solution selection: If a set of models is deployed for each user, the model structure and model parameters are different, which will cause problems in model training and service The cost is relatively high. We consider providing personalized model parameters for each scenario under the same model structure to solve the problem of model personalization.
- Deployment location: Deploy the model on the cloud and use the rich computing power on the cloud for calculation; at the same time, you want to flexibly control the model on the cloud.
- Algorithm idea: Traditional meta-learning solves the problems of few samples and cold start. Through a full understanding of the algorithm, in the field of recommendation, the use of meta-learning Innovation to solve the problem of extreme personalization of models.
The overall idea is to use meta-learning to deploy a set of personalized model parameters for each user in the cloud, ultimately achieving the effect of no loss in cost and performance.
3. Introduction to meta-learning

Meta-learning refers to learning General knowledge is used to guide algorithms for new tasks, giving the network rapid learning capabilities. For example: the classification task in the picture above: cats and birds, flowers and bicycles, we define this classification task as a K-short N-class classification task, hoping to learn classification knowledge through meta-learning. In the finetune estimation process, we hope that for classification tasks such as dogs and otters, fine-tuning can achieve the ultimate estimation effect with very few samples. For another example, when we learn the four mixed operations, we first learn addition and subtraction, and then multiplication and division. When these two knowledge are mastered, we can learn how to combine the two knowledge to calculate. For the mixed operations of addition, subtraction, multiplication and division , we do not calculate them separately, but on the basis of addition, subtraction, multiplication and division, we learn the operation rules of multiplication and division first and then addition and subtraction, and then use some samples to train this rule in order to quickly understand this rule, so that in the new estimate Better results were obtained on the data. The idea of meta-learning is similar to this.
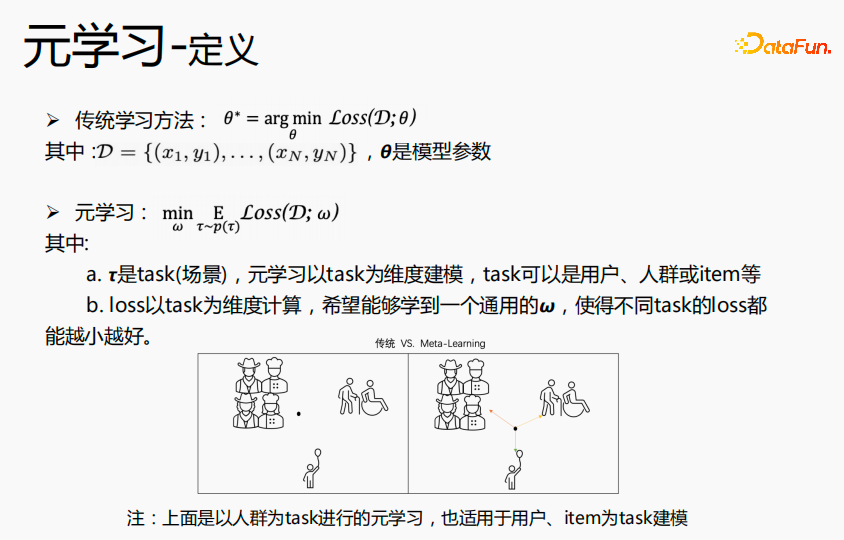
The traditional learning method aims to learn the optimal θ for all data, that is, the globally optimal θ. Meta-learning takes the task as the dimension to learn the general  in the scene, and the loss can reach the optimal level in all scenes. The θ learned by traditional learning methods is closer to the crowd in large scenes, has better predictions for large scenes, and has average effect on long-tail predictions; meta-learning is to learn a point that is similar in each scene, and use each The scene data or new scene data are fine-tuned at this point to reach the optimal point for each scene. Therefore, it is possible to construct personalized model parameters in each scenario to achieve the goal of ultimate personalization. In the above example, the crowd is used as the task for meta-learning, but it is also suitable for users or items to be used as tasks for modeling.
in the scene, and the loss can reach the optimal level in all scenes. The θ learned by traditional learning methods is closer to the crowd in large scenes, has better predictions for large scenes, and has average effect on long-tail predictions; meta-learning is to learn a point that is similar in each scene, and use each The scene data or new scene data are fine-tuned at this point to reach the optimal point for each scene. Therefore, it is possible to construct personalized model parameters in each scenario to achieve the goal of ultimate personalization. In the above example, the crowd is used as the task for meta-learning, but it is also suitable for users or items to be used as tasks for modeling.
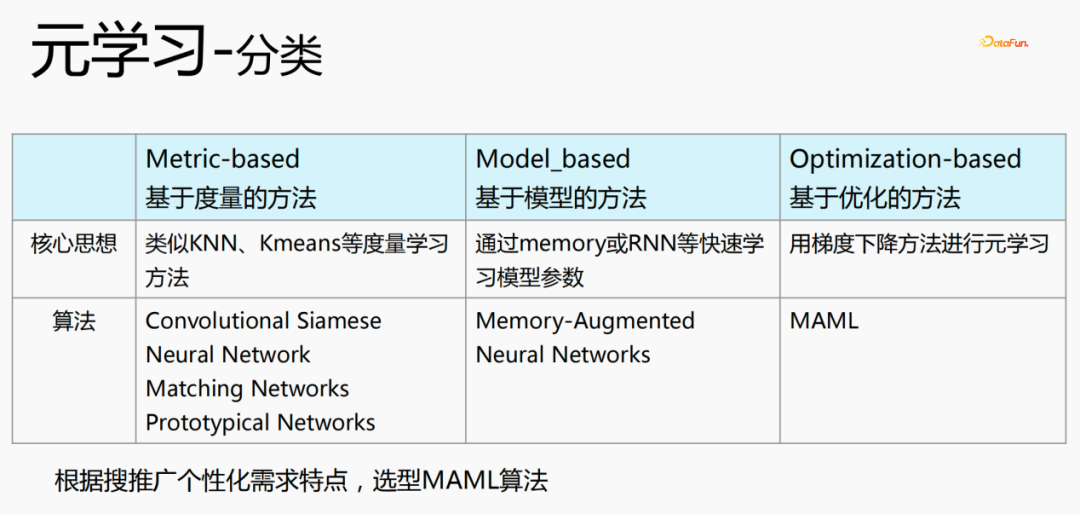
There are three classifications of meta-learning:
- Metric-based methods ( Metric-based): Use metric learning methods such as KNN and K-means to learn the distance between new scenes and existing scenes, and estimate which category they belong to. Representative algorithms are Convolutional Siamese, Neural Network, Matching Networks, and Prototypical Networks.
- Model-based method (Model_based): quickly learn model parameters through memory or RNN, etc. The representative algorithms are: Memeory-Augmented, Neural Networks
- Optimization-based method (Optimization-based): This is a popular method in recent years. It uses the gradient descent method to calculate the loss for each scene to obtain the optimal The optimal parameter represents the algorithm MAML, which is currently used for personalized modeling.
4. Meta-learning algorithm

##Model-Agnostic Meta-Learning (MAML) is an algorithm that has nothing to do with the model structure, is suitable for generalization, and is divided into two parts: meta-train and finetune.
meta-train has an initialization θ and performs two samplings, scene sampling and intra-field sample sampling. The first step is scene sampling. In this round of sampling process, the total sample has hundreds of thousands or even millions of tasks, and n tasks will be sampled from the millions of tasks; the second step, on each scene, Sample batchsize samples for this scene and divide the batchsize samples into two parts, one part is Support Set and the other part is Query Set; use Support Set to update theta of each scene using stochastic gradient descent method; third step, use Query Set Set calculates the loss for each scene; in the fourth step, add all the losses and pass the gradient back to θ; multiple rounds of calculations are performed as a whole until the termination condition is met. Among them, Support Set can be understood as a training set, and Query Set can be understood as a validation set.

The Finetune process is very close to the meta-train process. θ is placed in a specific scene, the support set of the scene is obtained, and the gradient descent method is used ( SGD), obtain the optimal parameters of the scene 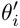 ; use
; use 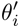 to generate estimated results for the samples (query set) to be scored in the task scene.
to generate estimated results for the samples (query set) to be scored in the task scene.
5. Meta-learning Industrialization Challenge
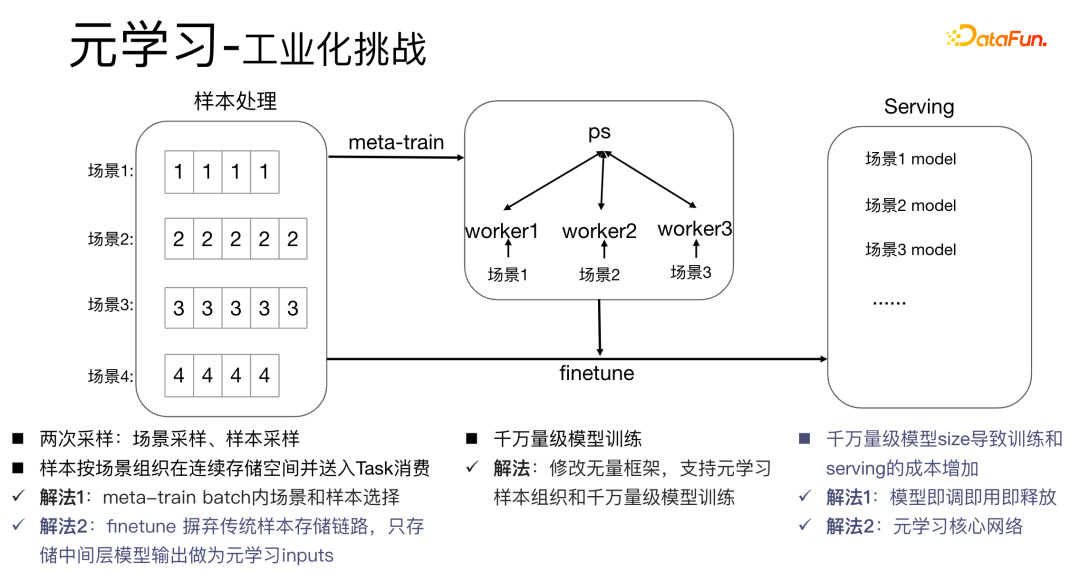
Applying meta-learning algorithms in industrial scenarios will There are relatively big challenges: the meta-train process of the meta-learning algorithm involves two samplings, scene sampling and sample sampling. For samples, it is necessary to organize the samples well and store and process them in the order of the scenes. At the same time, a dictionary table is needed to store the corresponding relationship between the samples and the scenes. This process consumes a lot of storage space and computing performance. At the same time, the samples need to be Putting it into workers for consumption poses a very big challenge to industrial scenarios.
We have the following solutions:
- Solution 1: Perform sample selection within meta-train batch. At the same time, for tens of millions of model trainings, we modify the infinite framework to support meta-learning sample organization and tens of millions of Large-scale model training. The traditional model deployment method is to deploy a set of models in every scenario, which will lead to very large model sizes in the tens of millions and increase the training and serving costs. We use a tune-and-use-and-release method to store only one set of model parameters, which can avoid increasing the model size. At the same time, in order to save performance, we only study the core network part.
- Solution 2: Perform finetune during the serving process. The traditional sample storage link makes the maintenance cost of the sample higher. Therefore, we abandon the traditional method and only Store the data of the intermediate layer as input for meta-learning.
6. Meta-learning scheme
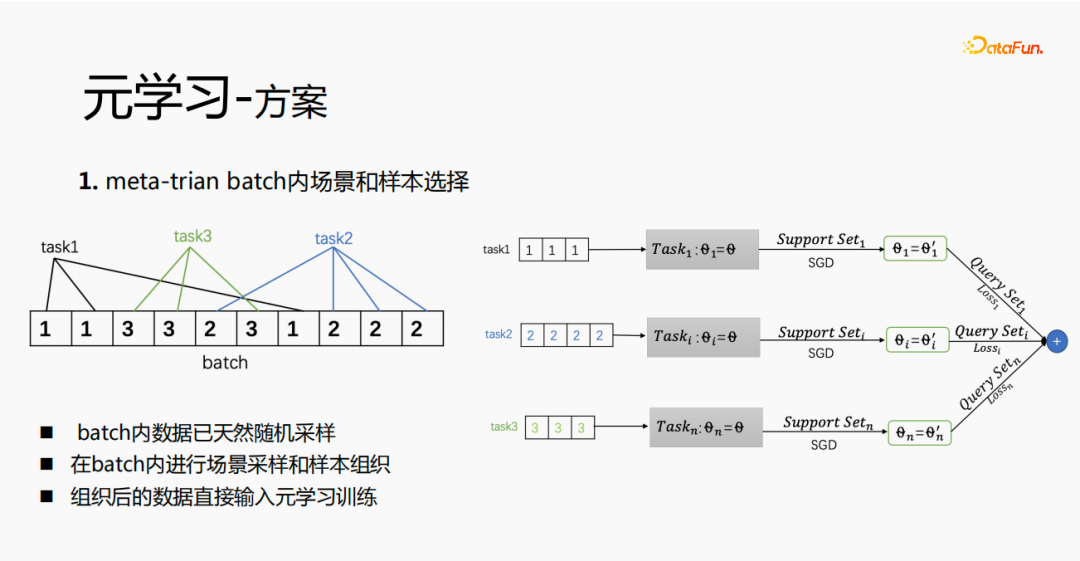
First in meta-train To realize the selection of scenes and samples within a batch, there will be multiple pieces of data in each batch, and each data belongs to a task. Within a batch, these data are extracted according to tasks, and the extracted samples are put into the meta-train training process. This solves the problem of needing to independently maintain a set of processing links for scene selection and sample selection.

Through experimental research and reading papers, we found that in fine-tune and in the meta-learning process, the closer to the prediction layer, the better the model The greater the impact on the prediction effect. At the same time, the emb layer has a greater impact on the prediction effect of the model, and the middle layer does not have a great impact on the prediction effect. So our idea is that meta-learning only selects parameters that are closer to the prediction layer. From a cost perspective, the emb layer will increase the cost of learning, and the emb layer will not be trained for meta-learning.
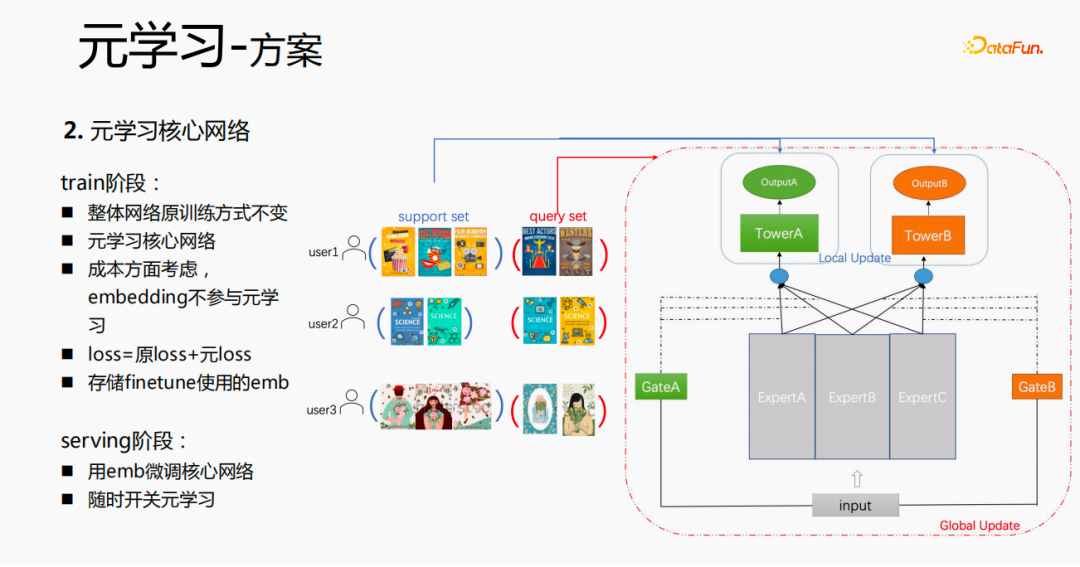
The overall training process, as shown in the mmoe training network in the picture above, we learn the parameters of the tower layer, and the parameters of other scenes are still based on the original training methods to learn. The samples are organized with the user as the dimension. Each user has his own training data. The training data is divided into two parts, one part is the support set and the other part is the query set. In the support set, only the content on the local side is learned for tower update and parameter training; then the query set data is used to calculate the loss of the entire network and then the gradient is returned to update the parameters of the entire network.
Therefore, the entire training process is: the original training method of the overall network remains unchanged; meta-learning only learns the core network; considering the cost, embedding does not participate in meta-learning; loss = original loss yuan loss; when fintune, store emb. In the serving process, emb is used to fine-tune the core network, and the switch can be used to control meta-learning on and off.
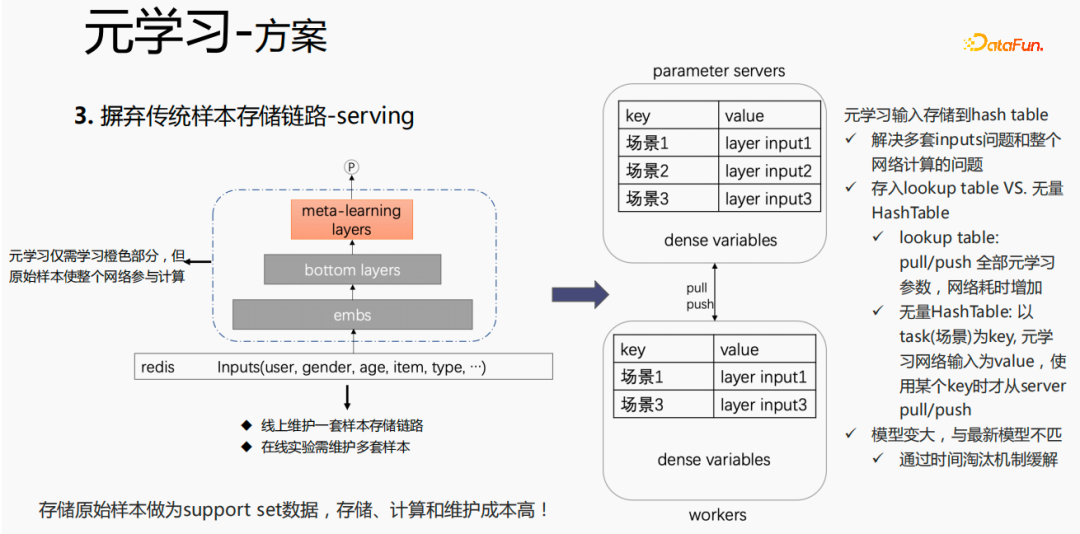
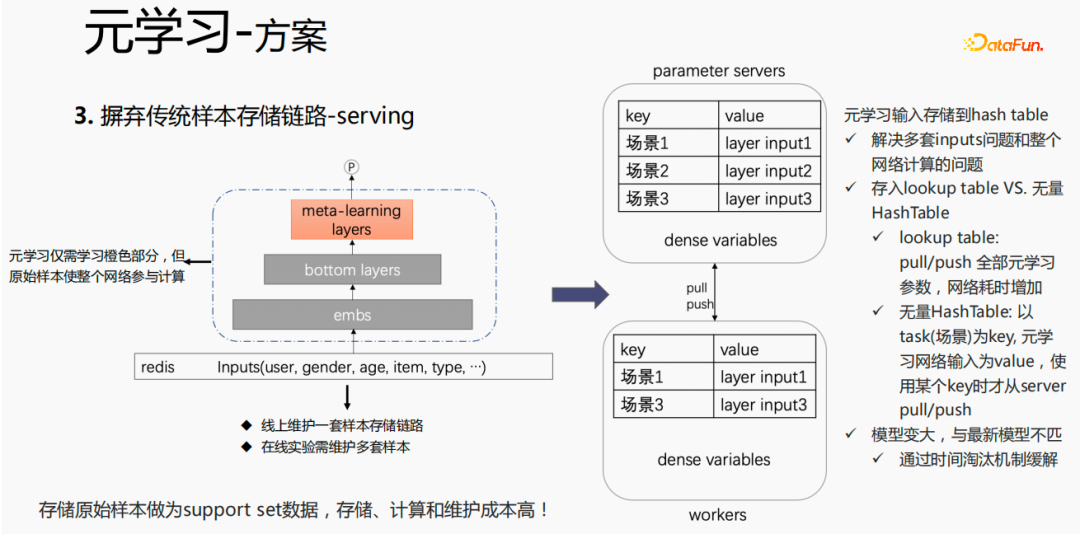
For the traditional sample storage method, if finetune is performed directly during the serving process, there will be serious problems. Problem: One set of sample storage links needs to be maintained online; multiple sets of online experiments require multiple sets of samples to be maintained. At the same time, in the finetune process, the original samples are used for finetune. The samples go through the emb layer, bottom layers and meta-learning layer. However, meta-learning only needs to learn meta-learning layers in the serving process and does not care about other parts. We consider saving only the meta-learning input to the model during the serving process, which can save the maintenance of the sample link and achieve a certain effect. If only the emb part is saved, the calculation cost and maintenance cost of this part can be saved. .
We use the following method:
Put the storage in the lookup table of the model. The lookup table will be considered as a dense variable and stored in ps. All parameters will be pulled to the worker. When updated, all parameters will be pushed to the worker. variables, which will increase the time consumption of the network. Another way is to use an infinite HashTable. The HashTable is stored in the form of key and value. The key is the scene and the value is the input of the meta layer. The advantage of this is that you only need to import the input layer of the required scene from ps. Push or pull will save network time as a whole, so we sample this method to store the input of the meta layer. At the same time, if meta-learning layers are stored in the model, it will make the model larger and encounter expiration problems, resulting in a mismatch with the current model. We use time elimination to solve this problem, that is, to eliminate expired embeddings. ,This not only makes the model smaller, but also solves the ,real-time problem.
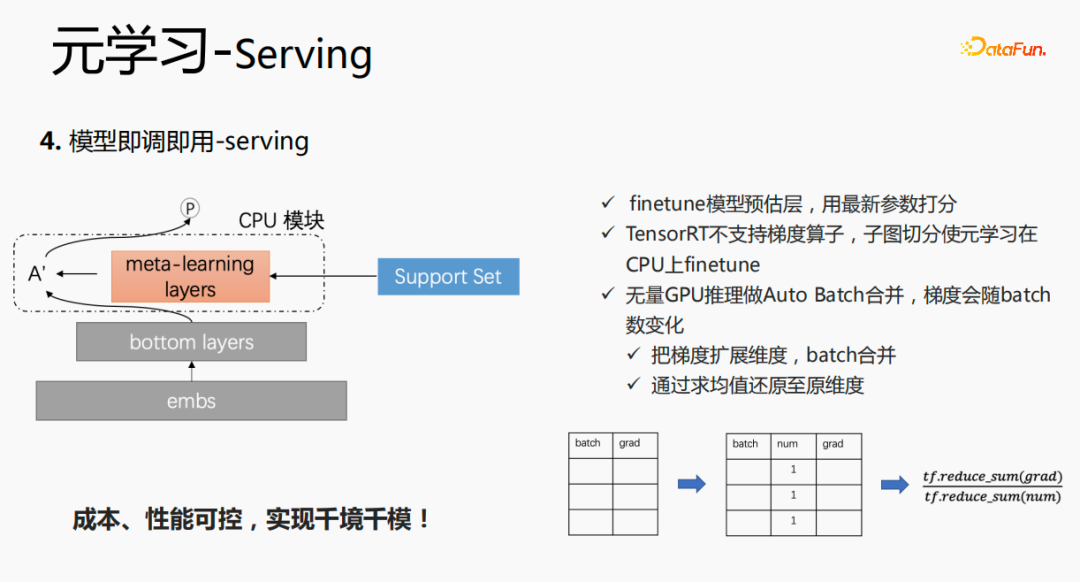
This model will use embedding in the serving stage. The embedding is input to the bottom layers. When scoring, it is not the same as the original method, but Get the data in the support set through meta-learning layers, update the parameters of this layer, and use the updated parameters for scoring. This process cannot be computed on the GPU, so we execute the process on the CPU. At the same time, Wuliang GPU inference performs Auto Batch merging to merge multiple requests. The merged requests are calculated on the GPU. In this way, the gradient will change as the batch increases. To address this problem, we use batch and grad On the basis of , add a num dimension. When calculating the gradient, add the grad and process it according to num to maintain the stability of the gradient. In the end, the cost and performance are controllable, and various scenarios and models are achieved.
7. Industrialized practice of meta-learning
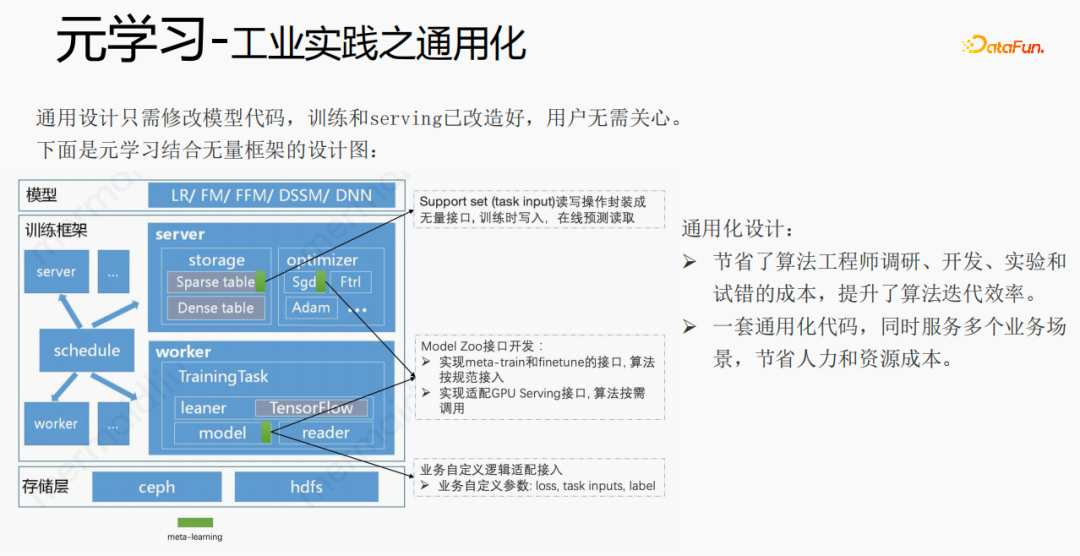
##Using frameworks and components to generalize meta-learning, users When accessing, you only need to modify the model code. Users do not need to care about training and serving. They only need to call the interfaces we have implemented, such as: support set read and write interfaces, meta-train and finetune implementation interfaces, and GPU serving adaptation interfaces. Users only need to pass in business-related parameters such as loss, task inputs, label, etc. This design saves algorithm engineers the cost of research, development, experimentation, and trial and error, and improves the iteration efficiency of the algorithm. At the same time, the generalized code can serve multiple business scenarios, saving manpower and resource costs.
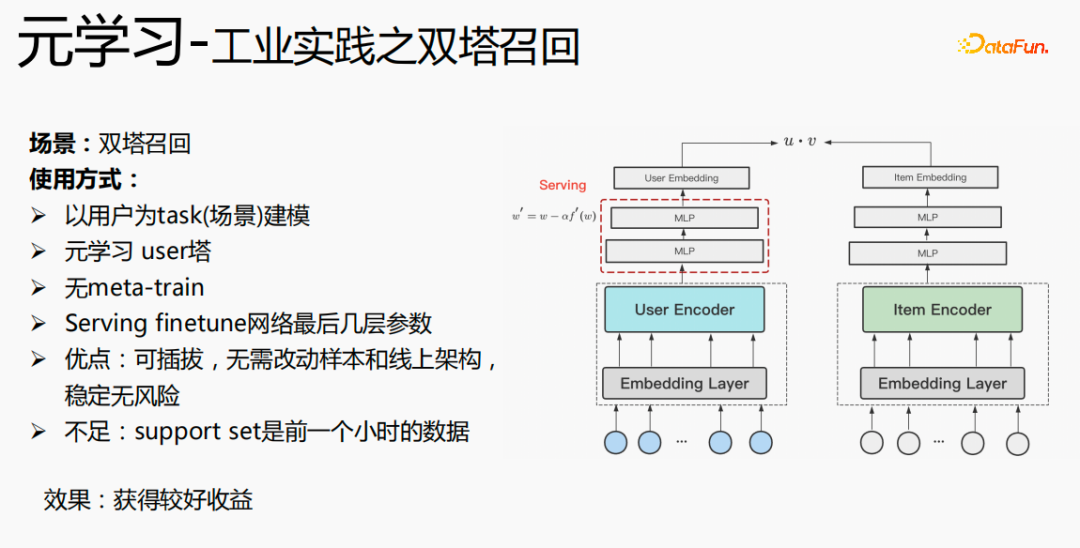
The use of meta-learning in the two-tower recall scenario is based on user-dimensional modeling, including user towers and item towers. The advantages of the model are: pluggable, no need to change samples and online architecture, stable and risk-free; the disadvantage is that the support set is the data of the previous hour, which has real-time issues.

Another application scenario of meta-learning is in the sequence recall scenario, which is modeled with the user as the scenario and the user’s behavior sequence As a support set, the user behavior sequence only has positive samples. We will maintain a negative sample queue, sample the samples in the queue as negative samples, and splice the positive samples as the support set. The advantages of this are: stronger real-time performance and lower cost.
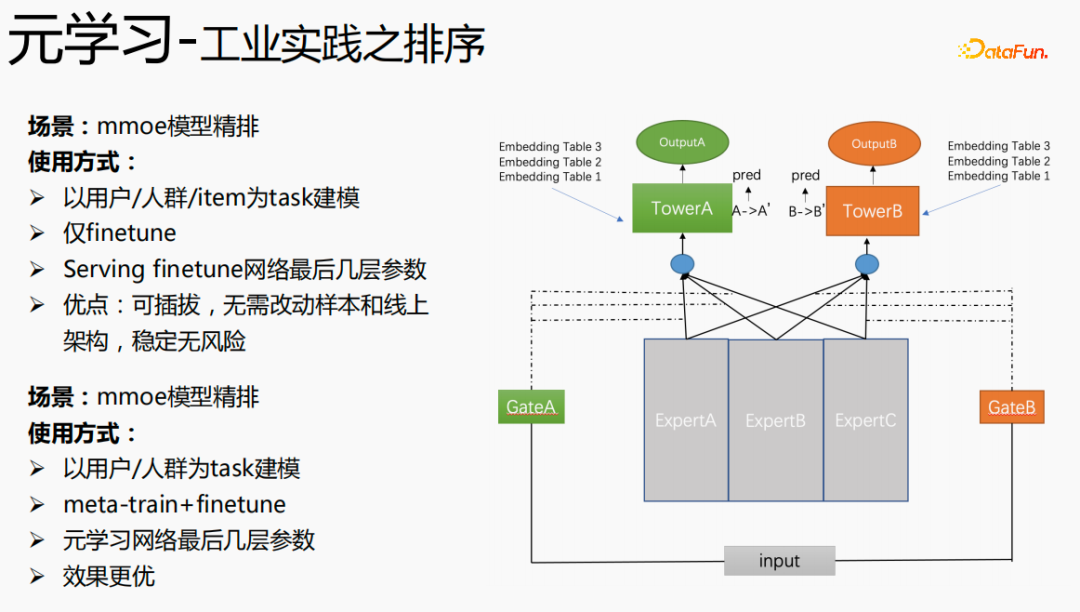
Finally, meta-learning is also applied in sorting scenarios, such as the mmoe fine sorting model in the picture above. There are two implementation methods: only using finetune , as well as using meta-train and finetune simultaneously. The second implementation method is more effective.
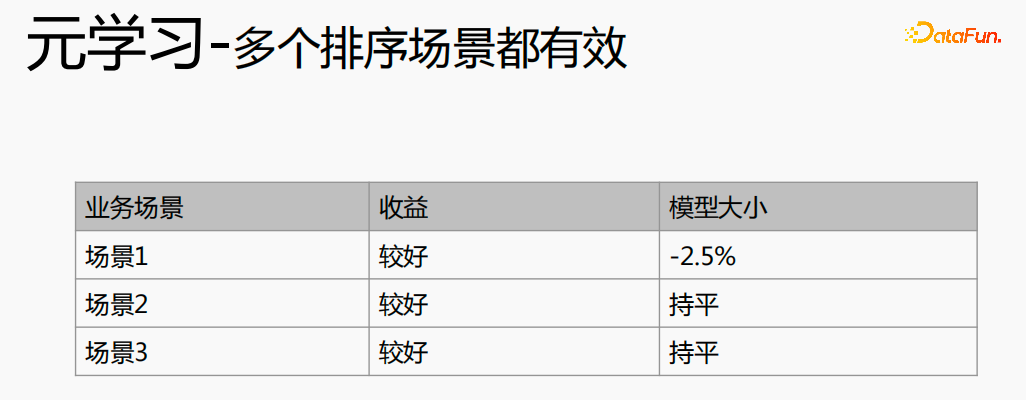
Meta-learning has achieved good results in different scenarios.
2. Cross-domain recommendation
1. Pain points of cross-domain recommendation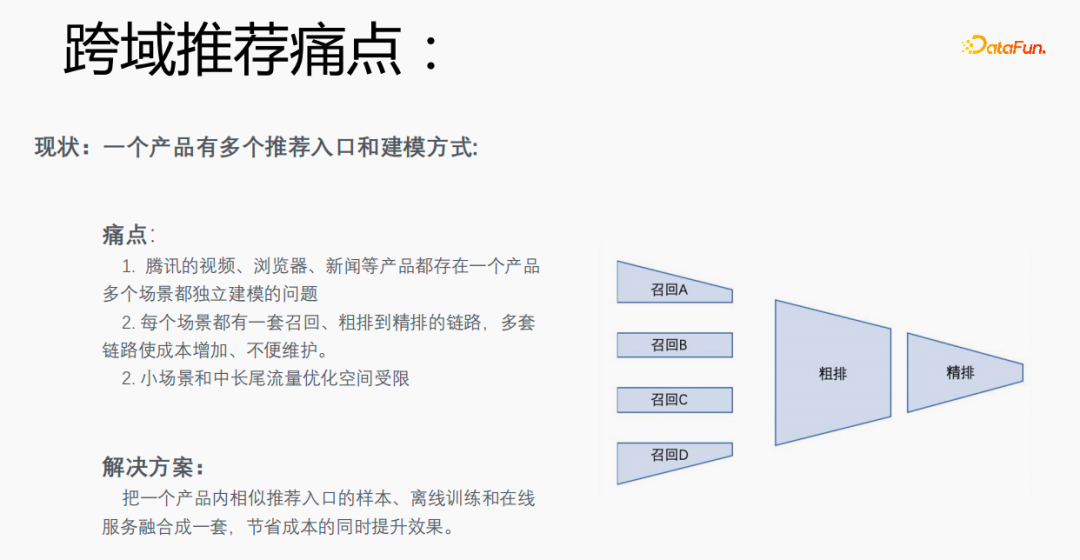
Each scene has multiple recommended entrances. It is necessary to establish a set of links from recall, rough ranking to fine ranking for each scene, which is costly. Especially small scenes and medium and long-tail traffic data are sparse, and the optimization space is limited. Can we integrate samples of similar recommendation portals, offline training and online services in one product into a set to save costs and improve results?
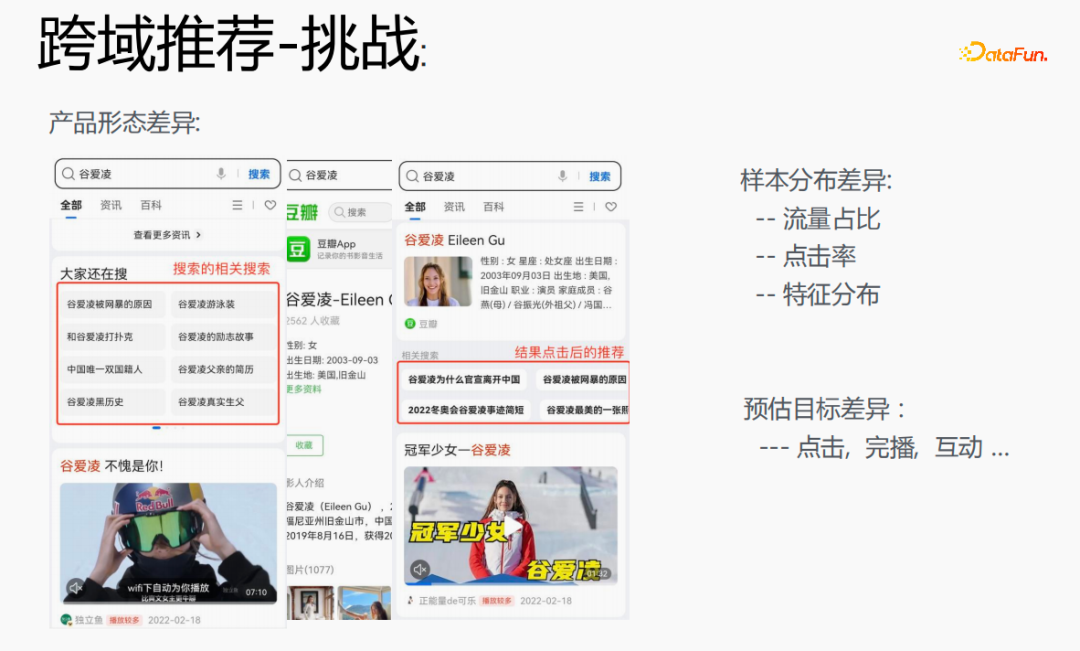
# However, there are certain challenges in doing so. Search for Gu Ailing on the browser, and relevant search terms will appear. After clicking on the specific content and returning, recommendations after clicking on the results will appear. The traffic proportions, click-through rates, and feature distributions of the two are quite different. At the same time, There are also differences in estimated targets.
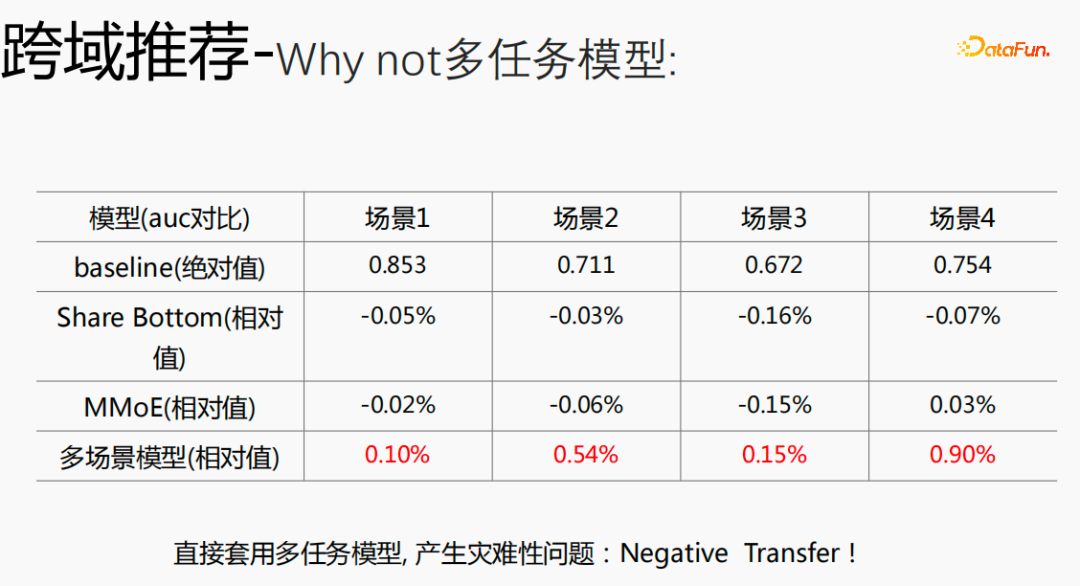
#If you use a multi-task model for a cross-domain model, serious problems will occur and you will not be able to get better benefits.
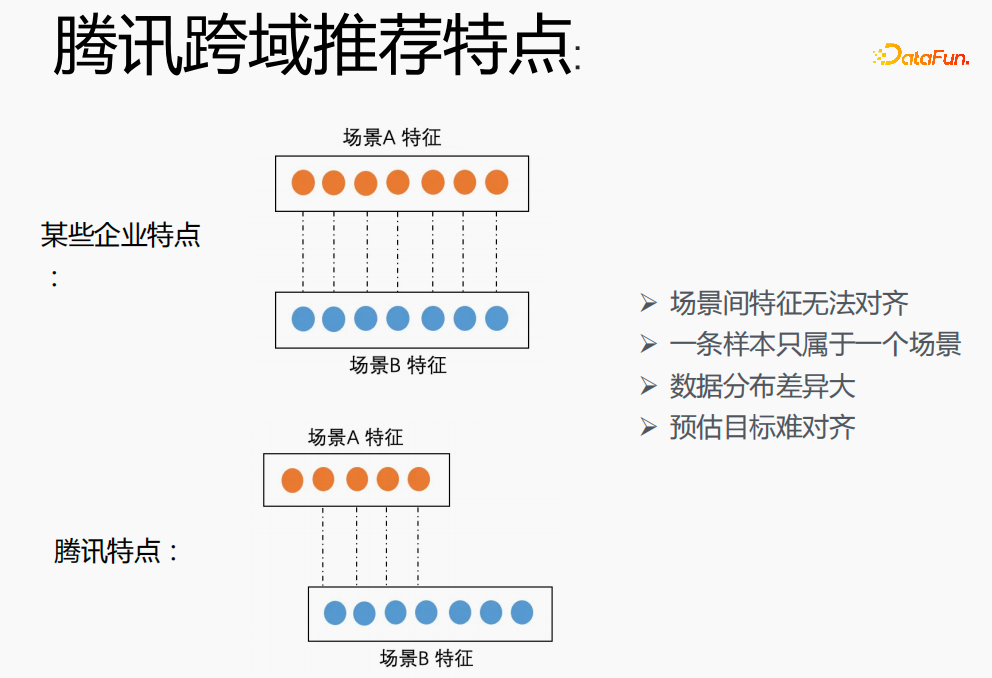
# Implementing cross-scenario modeling in Tencent is a big challenge. First, in other companies, the features of the two scenarios can correspond one-to-one, but in Tencent's cross-domain recommendation field, the features of the two scenarios cannot be aligned. One sample can only belong to one scenario. The data distribution is very different, and it is difficult to align the estimated targets.
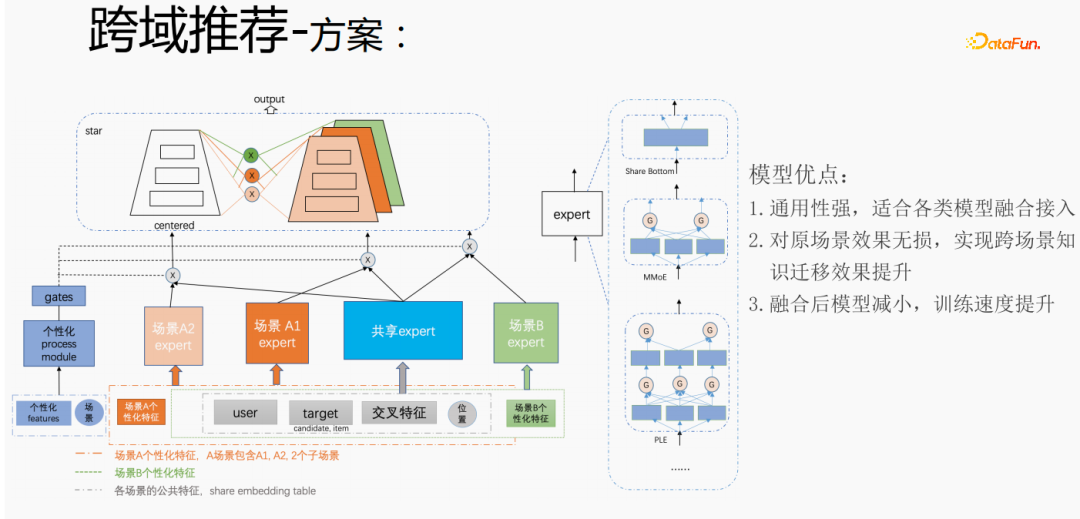
The above method is used to handle the personalized needs of Tencent’s cross-domain recommendation scenarios. For common features, shared embedding is performed. The personalized features of the scene have their own independent embedding space. In the model part, there are shared experts and personalized experts. All data will flow into the shared experts, and the samples of each scene will have their own personality data. Personalize the expert, integrate the shared expert and the personalized expert through the personalized gate, input them into the tower, and use the star method to solve the problem of target sparseness in different scenarios. For the expert part, any model structure can be used, such as Share bottom, MMoE, PLE, or a full model structure on the business scenario. The advantages of this method are: the model is highly versatile and suitable for fusion access of various models; since the scene expert can be directly migrated, the original scene effect is not damaged, and the effect of cross-scenario knowledge transfer is improved; after fusion, the model is reduced and the training speed is improved Improve while saving costs.
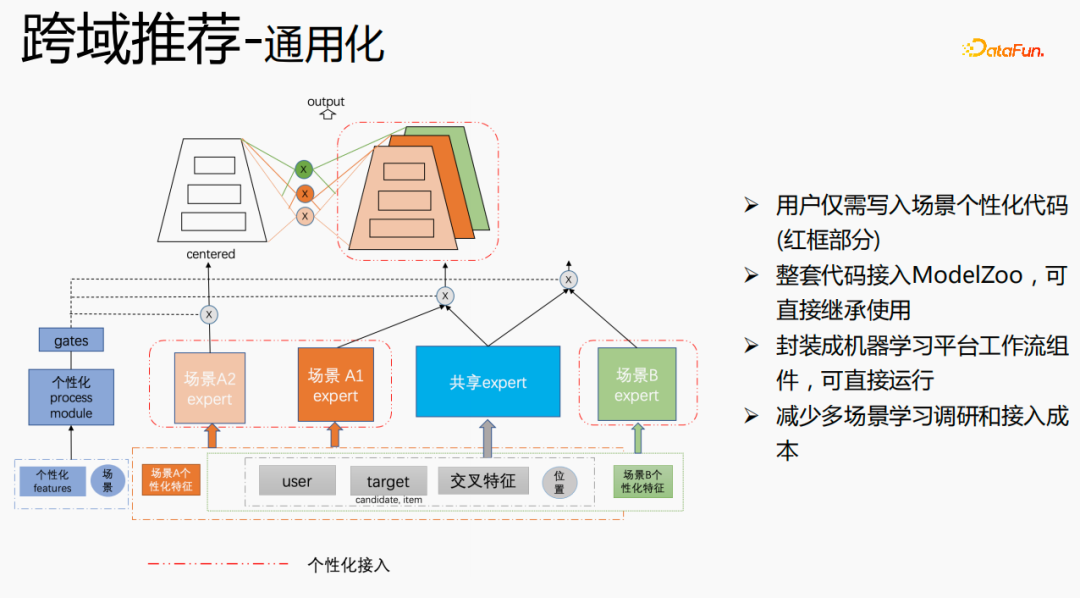
We have carried out universal construction. The red part is the content that needs personalized access, such as: personalized features, personalized model structure, etc. , users only need to write personalized code. For other parts, we have connected the entire set of codes to ModelZoo, which can be directly inherited and used, and encapsulated into machine learning platform workflow components, which can be run directly. This method reduces the cost of multi-scenario learning research and access.
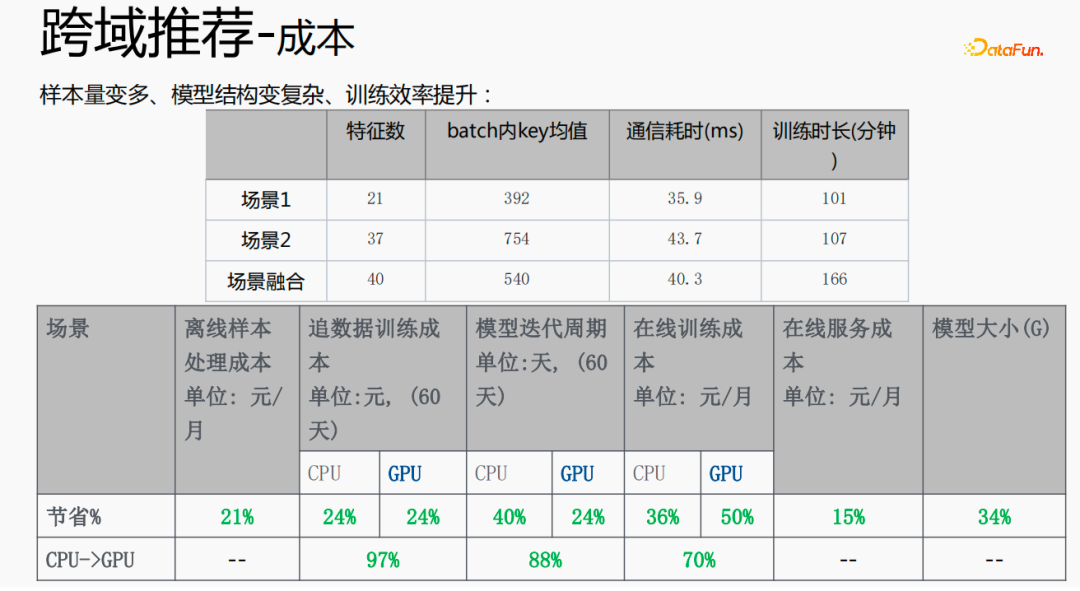
This method increases the sample size and complicates the model structure, but increases the efficiency. The reasons are as follows: Since some features are shared, the number of fused features is less than the sum of the feature numbers of the two scenes; due to the function of shared embedding, the mean key value within the batch is smaller than the sum of the two scenes; decrease It saves the time of pulling or pushing from the server side, thus saving the communication time and reducing the overall training time.
The fusion of multiple scenarios can reduce the overall cost: offline sample processing can reduce the cost by 21%; using CPU to chase data will save 24% of the cost and reduce the iteration time of the model. It will also be reduced by 40%. Online training costs, online service costs, and model size will all be reduced, so the cost of the entire link is reduced. At the same time, fusing the data of multiple scenes together is more suitable for GPU computing. Fusing the CPU of two single scenes to the GPU will save a higher proportion.
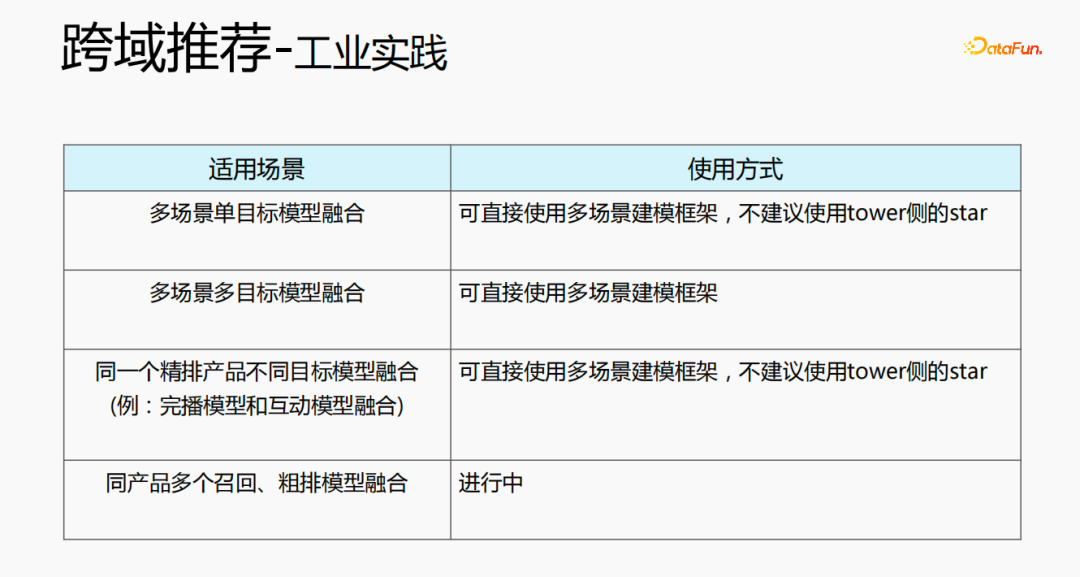
Cross-domain recommendations can be used in a variety of ways. The first one is a multi-scene single-objective model structure, which can directly use the multi-scene modeling framework. It is not recommended to use the star on the tower side; the second one is the fusion of multi-scene and multi-objective, and can directly use the multi-scene modeling framework. ; The third type is the fusion of different target models for the same refined product, and the multi-scenario modeling framework can be used directly. It is not recommended to use the star on the tower side; the last one is the fusion of multiple recall and rough ranking models for the same product, which is currently being developed in progress.
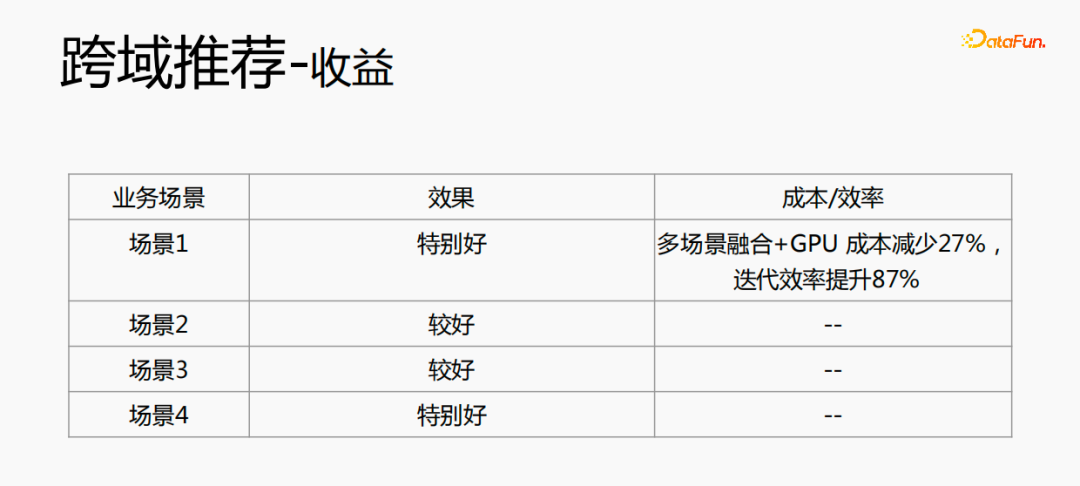
Cross-domain recommendation not only improves the effect, but also saves a lot of costs.
The above is the detailed content of Industrial practice of Tencent TRS' meta-learning and cross-domain recommendation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
Explore the underlying principles and algorithm selection of the C++sort function
Apr 02, 2024 pm 05:36 PM
The bottom layer of the C++sort function uses merge sort, its complexity is O(nlogn), and provides different sorting algorithm choices, including quick sort, heap sort and stable sort.
 Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
Can artificial intelligence predict crime? Explore CrimeGPT's capabilities
Mar 22, 2024 pm 10:10 PM
The convergence of artificial intelligence (AI) and law enforcement opens up new possibilities for crime prevention and detection. The predictive capabilities of artificial intelligence are widely used in systems such as CrimeGPT (Crime Prediction Technology) to predict criminal activities. This article explores the potential of artificial intelligence in crime prediction, its current applications, the challenges it faces, and the possible ethical implications of the technology. Artificial Intelligence and Crime Prediction: The Basics CrimeGPT uses machine learning algorithms to analyze large data sets, identifying patterns that can predict where and when crimes are likely to occur. These data sets include historical crime statistics, demographic information, economic indicators, weather patterns, and more. By identifying trends that human analysts might miss, artificial intelligence can empower law enforcement agencies
 Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
Improved detection algorithm: for target detection in high-resolution optical remote sensing images
Jun 06, 2024 pm 12:33 PM
01 Outlook Summary Currently, it is difficult to achieve an appropriate balance between detection efficiency and detection results. We have developed an enhanced YOLOv5 algorithm for target detection in high-resolution optical remote sensing images, using multi-layer feature pyramids, multi-detection head strategies and hybrid attention modules to improve the effect of the target detection network in optical remote sensing images. According to the SIMD data set, the mAP of the new algorithm is 2.2% better than YOLOv5 and 8.48% better than YOLOX, achieving a better balance between detection results and speed. 02 Background & Motivation With the rapid development of remote sensing technology, high-resolution optical remote sensing images have been used to describe many objects on the earth’s surface, including aircraft, cars, buildings, etc. Object detection in the interpretation of remote sensing images
 Practice and reflections on Jiuzhang Yunji DataCanvas multi-modal large model platform
Oct 20, 2023 am 08:45 AM
Practice and reflections on Jiuzhang Yunji DataCanvas multi-modal large model platform
Oct 20, 2023 am 08:45 AM
1. The historical development of multi-modal large models. The photo above is the first artificial intelligence workshop held at Dartmouth College in the United States in 1956. This conference is also considered to have kicked off the development of artificial intelligence. Participants Mainly the pioneers of symbolic logic (except for the neurobiologist Peter Milner in the middle of the front row). However, this symbolic logic theory could not be realized for a long time, and even ushered in the first AI winter in the 1980s and 1990s. It was not until the recent implementation of large language models that we discovered that neural networks really carry this logical thinking. The work of neurobiologist Peter Milner inspired the subsequent development of artificial neural networks, and it was for this reason that he was invited to participate in this project.
 Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
Application of algorithms in the construction of 58 portrait platform
May 09, 2024 am 09:01 AM
1. Background of the Construction of 58 Portraits Platform First of all, I would like to share with you the background of the construction of the 58 Portrait Platform. 1. The traditional thinking of the traditional profiling platform is no longer enough. Building a user profiling platform relies on data warehouse modeling capabilities to integrate data from multiple business lines to build accurate user portraits; it also requires data mining to understand user behavior, interests and needs, and provide algorithms. side capabilities; finally, it also needs to have data platform capabilities to efficiently store, query and share user profile data and provide profile services. The main difference between a self-built business profiling platform and a middle-office profiling platform is that the self-built profiling platform serves a single business line and can be customized on demand; the mid-office platform serves multiple business lines, has complex modeling, and provides more general capabilities. 2.58 User portraits of the background of Zhongtai portrait construction
 Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!
Mar 14, 2024 pm 11:50 PM
Add SOTA in real time and skyrocket! FastOcc: Faster inference and deployment-friendly Occ algorithm is here!
Mar 14, 2024 pm 11:50 PM
Written above & The author’s personal understanding is that in the autonomous driving system, the perception task is a crucial component of the entire autonomous driving system. The main goal of the perception task is to enable autonomous vehicles to understand and perceive surrounding environmental elements, such as vehicles driving on the road, pedestrians on the roadside, obstacles encountered during driving, traffic signs on the road, etc., thereby helping downstream modules Make correct and reasonable decisions and actions. A vehicle with self-driving capabilities is usually equipped with different types of information collection sensors, such as surround-view camera sensors, lidar sensors, millimeter-wave radar sensors, etc., to ensure that the self-driving vehicle can accurately perceive and understand surrounding environment elements. , enabling autonomous vehicles to make correct decisions during autonomous driving. Head
