

Since the advent of GPT-4, people have been amazed by its powerful emergence capabilities, including excellent language understanding capabilities, generation capabilities, logical reasoning capabilities, etc. These capabilities make GPT-4 one of the most cutting-edge models in machine learning. However, OpenAI has not disclosed any technical details of GPT-4 so far.
Last month, George Hotz mentioned GPT-4 in an interview with an AI technology podcast called Latent Space, saying that GPT-4 is actually is a hybrid model. Specifically, George Hotez said that GPT-4 uses an integrated system composed of 8 expert models, each of which has 220 billion parameters (slightly more than the 175 billion parameters of GPT-3), and these Models are trained on different data and task distributions.

Interview from Latent Space.
This may be just a speculation by George Hotez, but this model does have some legitimacy. Recently, a paper jointly published by researchers from Google, UC Berkeley, MIT and other institutions confirmed that the combination of hybrid expert model (MoE) and instruction tuning can significantly improve the performance of large language models (LLM).
 Picture
Picture
Paper address: https://arxiv.org/pdf/2305.14705.pdf
The sparse mixed expert model is a special neural network architecture that can add learnable parameters to large language models (LLM) without increasing the cost of inference. Instruction tuning is a technique for training LLM to follow instructions. The study found that MoE models benefited more from instruction tuning than dense models, and therefore proposed to combine MoE and instruction tuning.
The study was conducted empirically in three experimental settings, including
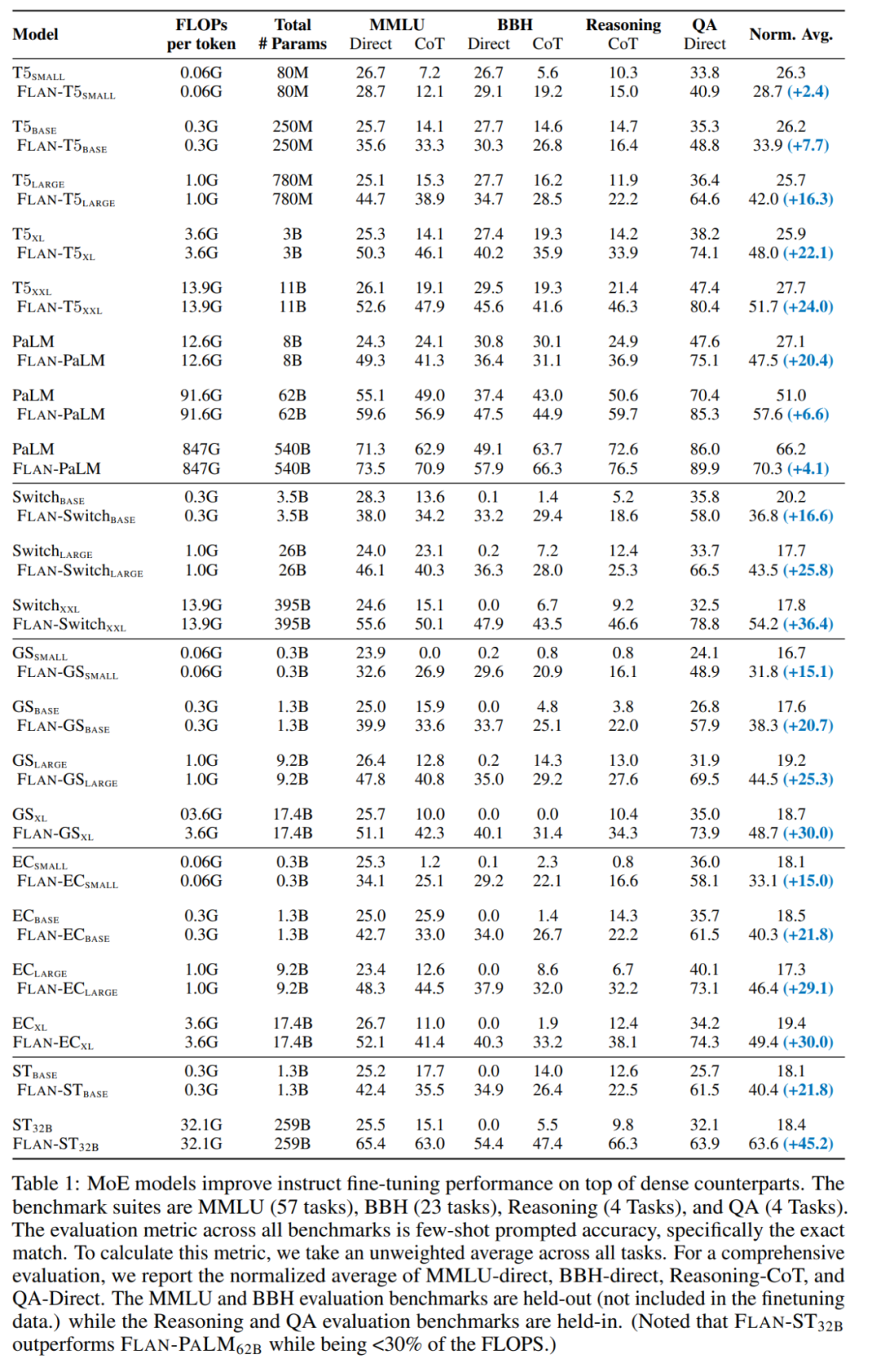
In the first case, the MoE model is generally inferior to a dense model with the same computational power. However, with the introduction of instruction tuning (the second and third cases), FLAN-MoE_32B (Fine-tuned LAnguage Net, abbreviated as Flan, is an instruction-tuned model, Flan-MoE is instruction tuning). Excellent MoE) outperforms FLAN-PALM_62B on four benchmark tasks, but only uses one-third of the FLOPs.
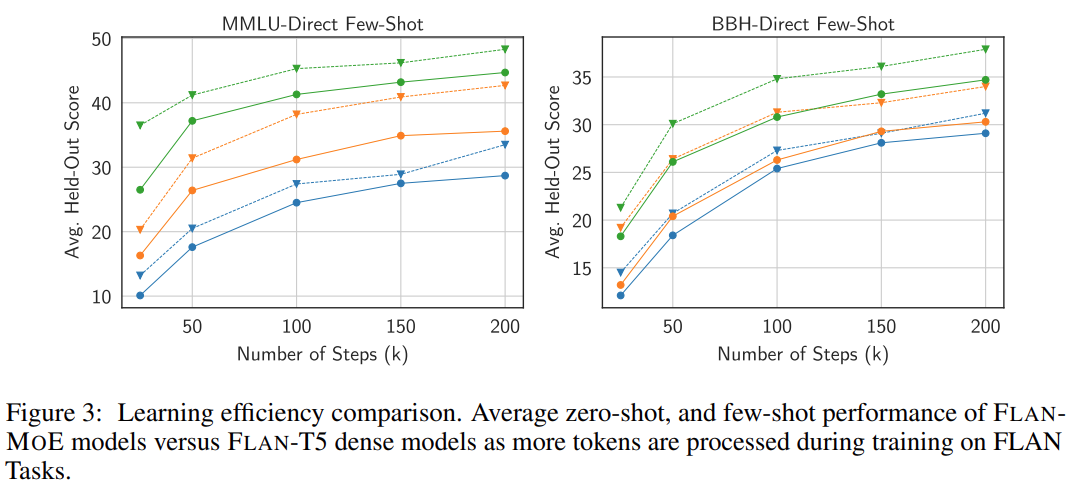
As shown in the figure below, before using instruction tuning, MoE→FT is not as good as T5→FT. After instruction tuning, Flan-MoE→FT outperforms Flan-T5→FT. MoE gains more from instruction tuning (15.6) than dense models (10.2):
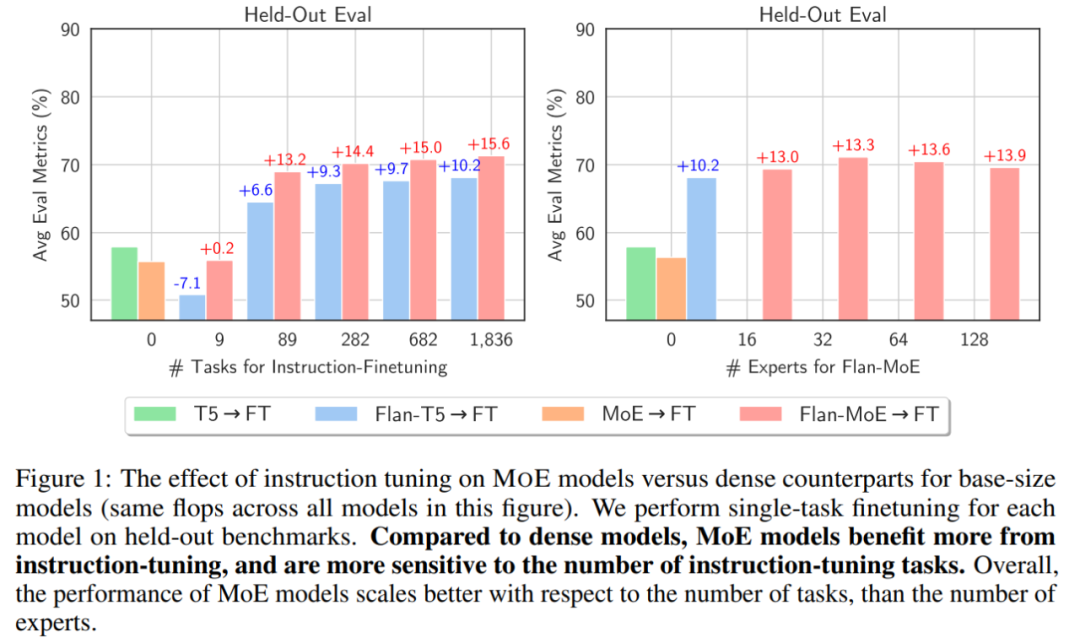 Picture
Picture
It seems that GPT -4 There is some basis for adopting a hybrid model. MoE can indeed gain greater benefits from instruction tuning:
 Picture
Picture
The researchers used sparse activation MoE (Mixture-of-Experts) in the FLAN-MOE (a set of sparse mixed expert models fine-tuned by instructions) model. Additionally, they replaced the feedforward components of other Transformer layers with MoE layers.
Each MoE layer can be understood as an "expert", and then the softmax activation function is used to model these experts to obtain a probability distribution.
Although each MoE layer has many parameters, the experts are sparsely activated. This means that for a given input token, only a limited subset of experts can complete the task, thus providing greater capacity to the model.
For a MoE layer with E experts, this effectively provides O (E^2) different feedforward network combinations, allowing for greater computational flexibility.
Since FLAN-MoE is an instruction-tuned model, instruction tuning is very important. This study fine-tuned FLAN-MOE based on the FLAN collective data set. Furthermore, this study adjusted the input sequence length of each FLAN-MOE to 2048 and the output length to 512.
On average, Flan-MoE performs better across all model scales without adding any additional computation. Better than its dense counterpart (Flan-T5).
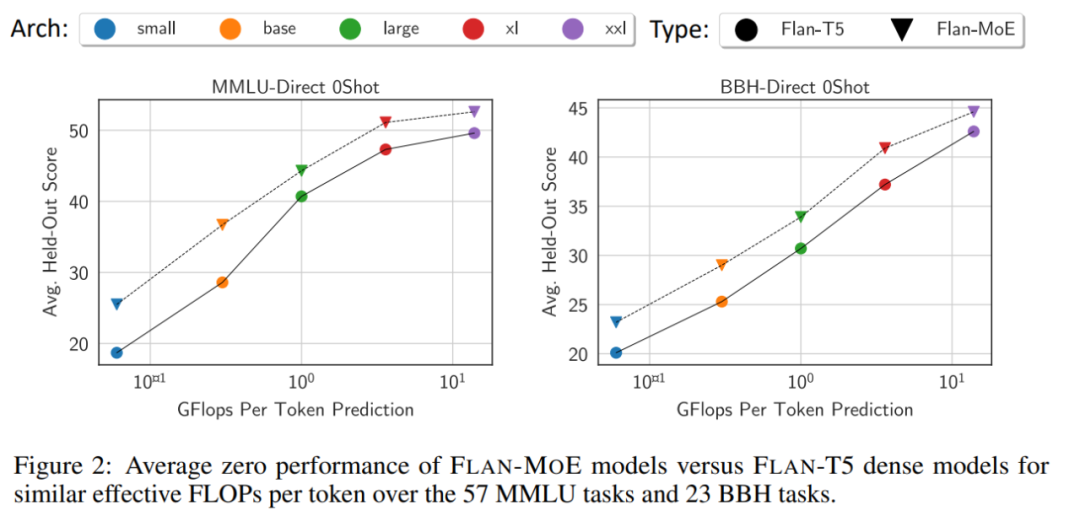 Pictures
Pictures
Number of experts. Figure 4 shows that as the number of experts increases, initially the model benefits from a richer set of specialized subnetworks, each capable of handling a different task or aspect in the problem space. This approach makes MoE highly adaptable and efficient in handling complex tasks, thereby improving performance overall. However, as the number of experts continues to increase, the model performance gains begin to decrease, eventually reaching a saturation point.
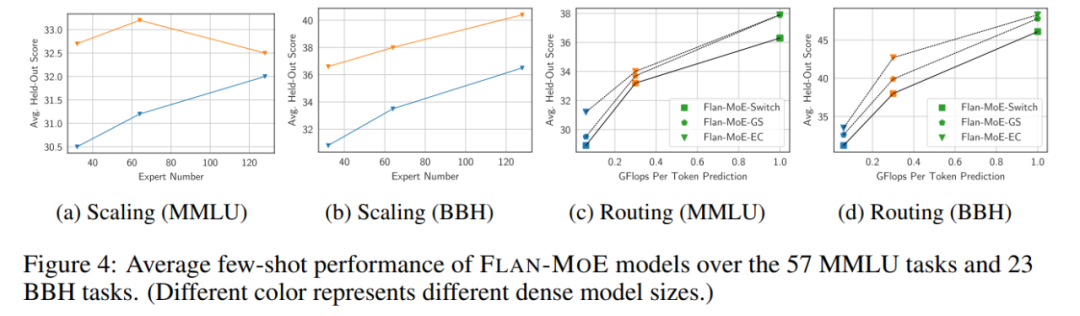 Picture
Picture
Figure 3 and Table 1 provide a detailed study of how different routing decisions affect instruction tuning performance: via FLAN- A comparison between the Switch and FLAN-GS strategies shows that activating more experts improves performance across the four benchmarks. Among these benchmarks, the MMLU-Direct model shows the most significant improvement, increasing from 38.0% to 39.9% for BASE/LARGE-sized models.
Notably, instruction tuning significantly amplified the performance of the MoE model in preserving MMLU, BBH, and internal QA and inference benchmarks compared to dense models of equivalent capacity . These advantages are further amplified for larger MoE models. For example, instruction tuning improves performance by 45.2% for ST_32B, while for FLAN-PALM_62B this improvement is relatively small at about 6.6%.
When doing model extensions, Flan-MoE (Flan-ST-32B) outperforms Flan-PaLM-62B.
 Picture
Picture
#In addition, this study freezes the gating function, expert module and MoE of the given model. Some analytical experiments were conducted on parameters. As shown in Table 2 below, experimental results show that freezing the expert module or MoE component has a negative impact on model performance.
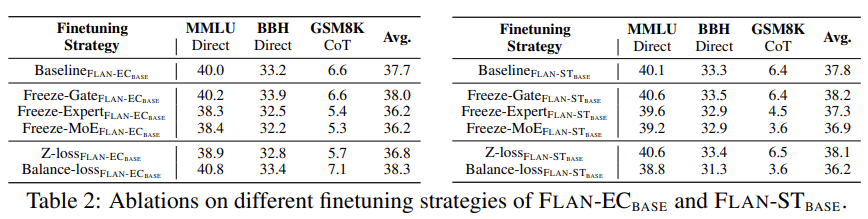
On the contrary, the freeze gating function will slightly improve the model performance, although it is not obvious. The researchers speculate that this observation is related to the underfitting of FLAN-MOE. The study also conducted ablation experiments to explore the fine-tuning data efficiency ablation study described in Figure 5 below.
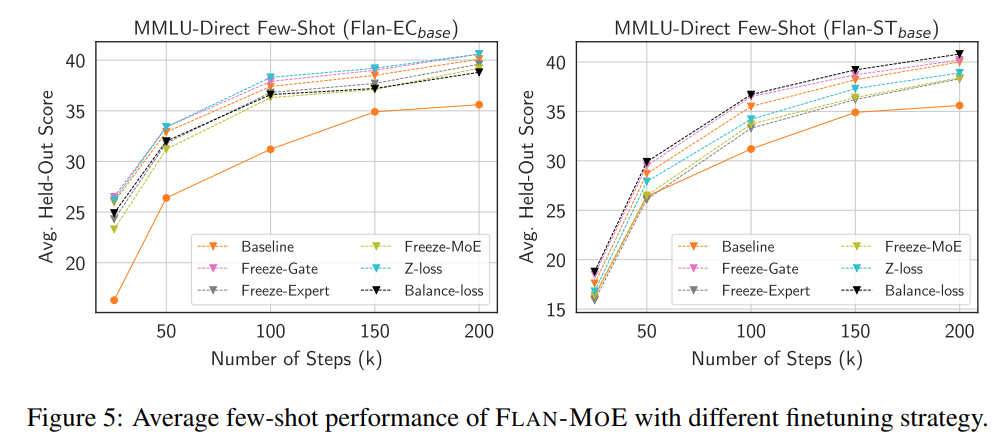
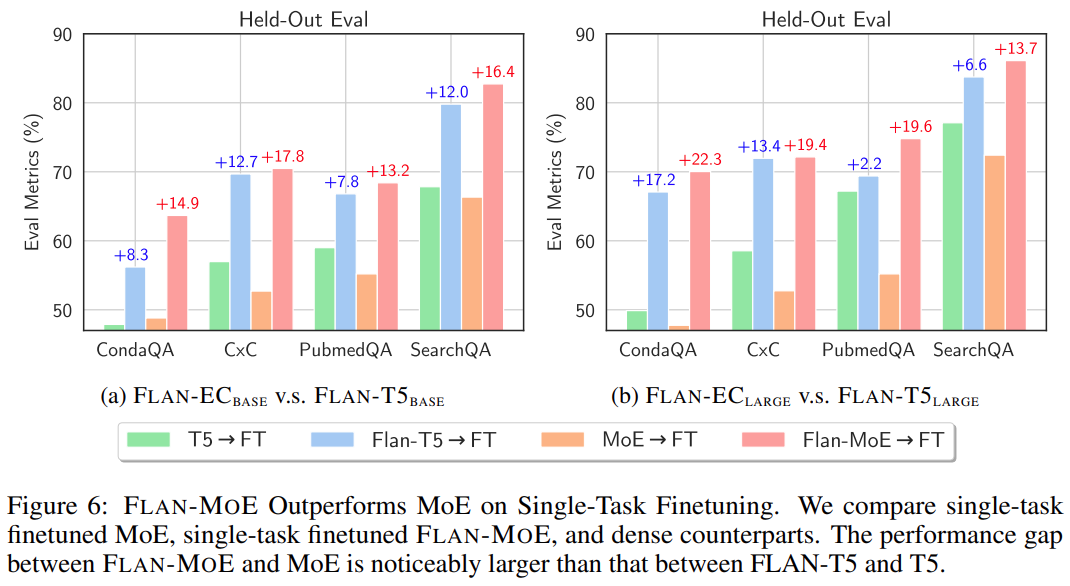
Finally, in order to compare the gap between direct fine-tuning of MoE and FLAN-MOE, this study conducted single-task fine-tuning of MoE, single-task Experiments were conducted on fine-tuned FLAN-MoE and dense models, and the results are shown in Figure 6 below:
Interested readers can read the original text of the paper to learn more More research content.
The above is the detailed content of GPT-4 uses hybrid large models? Research proves that MoE+ instruction tuning indeed makes large models perform better. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



