

Microsoft's new hot paper: Transformer expands to 1 billion tokens

When everyone continues to upgrade and iterate their own large models, the ability of LLM (large language model) to process context windows has also become an important evaluation indicator.
For example, the star large model GPT-4 supports 32k tokens, equivalent to 50 pages of text; Anthropic, founded by a former member of OpenAI, has increased Claude's token processing capabilities to 100k, about 75,000 One word is roughly equivalent to summarizing the first part of "Harry Potter" in one click.
In Microsoft’s latest research, they directly expanded Transformer to 1 billion tokens this time. This opens up new possibilities for modeling very long sequences, such as treating an entire corpus or even the entire Internet as one sequence.
For comparison, the average person can read 100,000 tokens in about 5 hours, and may take longer to digest, remember, and analyze the information. Claude can do this in less than a minute. If converted into this research by Microsoft, it would be a staggering number.
 Picture
Picture
- Paper address: https://arxiv.org/pdf/2307.02486.pdf
- Project address: https://github.com/microsoft/unilm/tree/master
Specifically, the study proposes LONGNET, a Transformer variant that can extend sequence length to over 1 billion tokens without sacrificing performance for shorter sequences. The article also proposes dilated attention, which can exponentially expand the model's perception range.
LONGNET has the following advantages:
1) It has linear computational complexity;
2) It can be used as a distributed trainer for longer sequences;
3) dilated attention can seamlessly replace standard attention and work seamlessly with existing Transformer-based optimization methods integrated.
Experimental results show that LONGNET exhibits strong performance in both long sequence modeling and general language tasks.
In terms of research motivation, the paper states that in recent years, extending neural networks has become a trend, and many networks with good performance have been studied. Among them, the sequence length, as part of the neural network, should ideally be infinite. But the reality is often the opposite, so breaking the limit of sequence length will bring significant advantages:
- First, it provides a large-capacity memory and receptive field for the model. Enable it to interact effectively with humans and the world.
- Secondly, longer context contains more complex causal relationships and reasoning paths that the model can exploit in the training data. On the contrary, shorter dependencies will introduce more spurious correlations, which is not conducive to the generalization of the model.
- Third, longer sequence length can help the model explore longer contexts, and extremely long contexts can also help the model alleviate the catastrophic forgetting problem.
#However, the main challenge in extending sequence length is finding the right balance between computational complexity and model expressive power.
For example, RNN style models are mainly used to increase sequence length. However, its sequential nature limits parallelization during training, which is crucial in long sequence modeling.
Recently, state space models have become very attractive for sequence modeling, which can be run as a CNN during training and converted to an efficient RNN at test time. However, this type of model does not perform as well as Transformer at regular lengths.
Another way to extend the sequence length is to reduce the complexity of the Transformer, that is, the quadratic complexity of self-attention. At this stage, some efficient Transformer-based variants have been proposed, including low-rank attention, kernel-based methods, downsampling methods, and retrieval-based methods. However, these approaches have yet to scale Transformer to the scale of 1 billion tokens (see Figure 1).
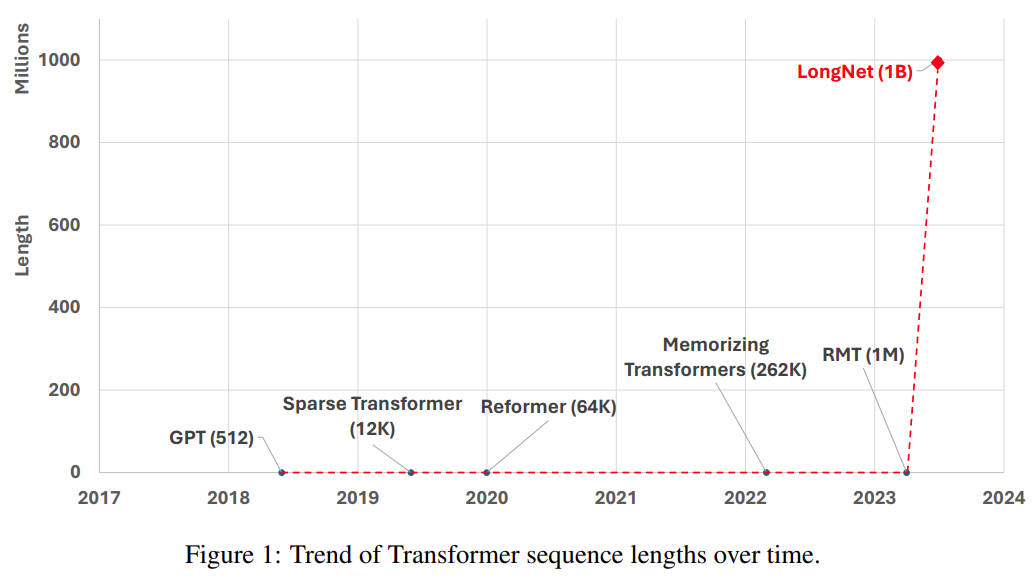 Picture
Picture
The following table compares the computational complexity of different calculation methods. N is the sequence length, and d is the hidden dimension.
 picture
picture
Method
The study’s solution, LONGNET, successfully extended the sequence length to 1 billion tokens. Specifically, this research proposes a new component called dilated attention and replaces the attention mechanism of Vanilla Transformer with dilated attention. A general design principle is that the allocation of attention decreases exponentially as the distance between tokens increases. The study shows that this design approach obtains linear computational complexity and logarithmic dependence between tokens. This resolves the conflict between limited attention resources and access to every token.
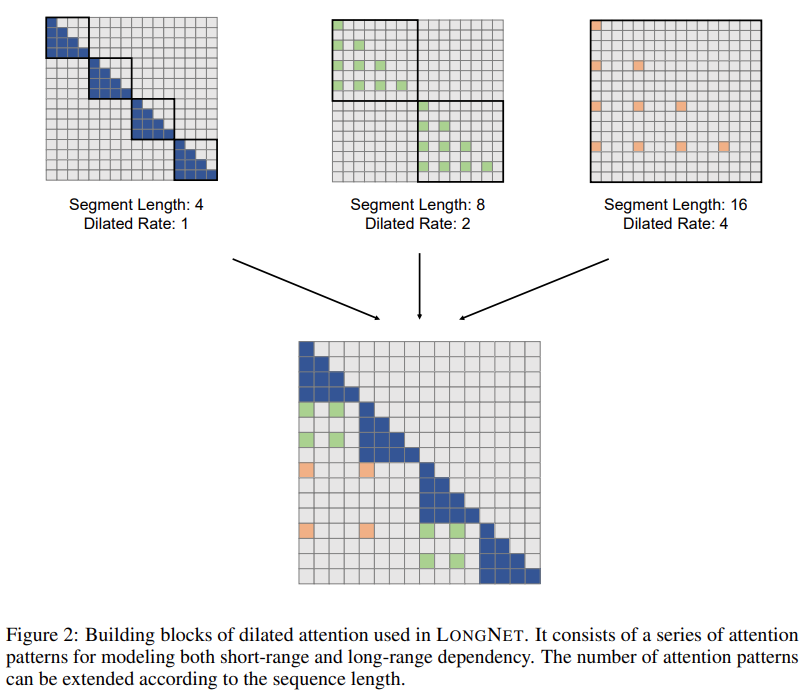 Picture
Picture
During the implementation process, LONGNET can be converted into a dense Transformer to seamlessly support existing Transformer-specific There are optimization methods (such as kernel fusion, quantization and distributed training). Taking advantage of linear complexity, LONGNET can be trained in parallel across nodes, using distributed algorithms to break computing and memory constraints.
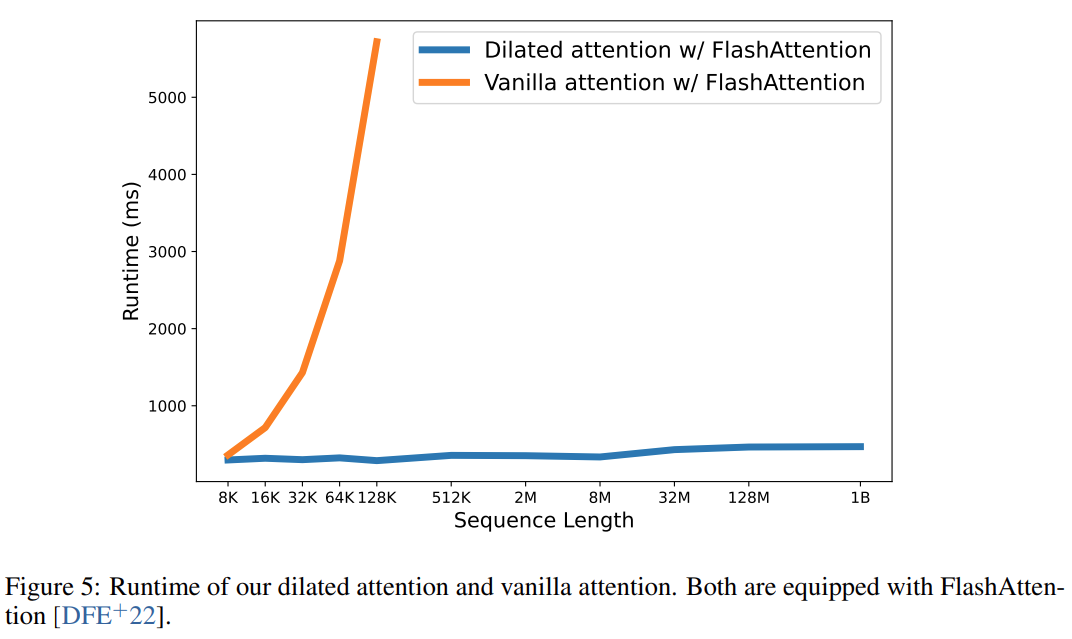
In the end, the research effectively expanded the sequence length to 1B tokens, and the runtime was almost constant, as shown in the figure below. In contrast, the vanilla Transformer's runtime suffers from quadratic complexity.
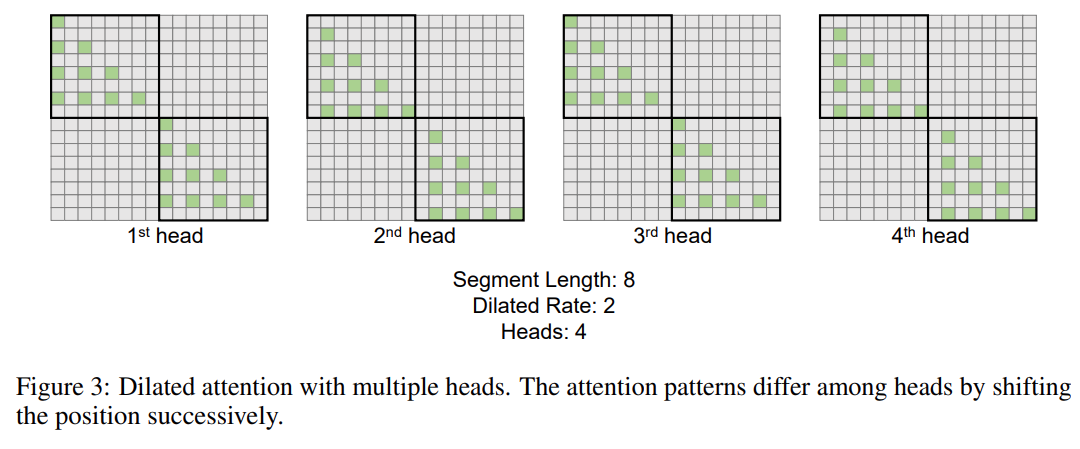
This research further introduces the multi-head dilated attention mechanism. As shown in Figure 3 below, this study performs different computations across different heads by sparsifying different parts of query-key-value pairs.
 Picture
Picture
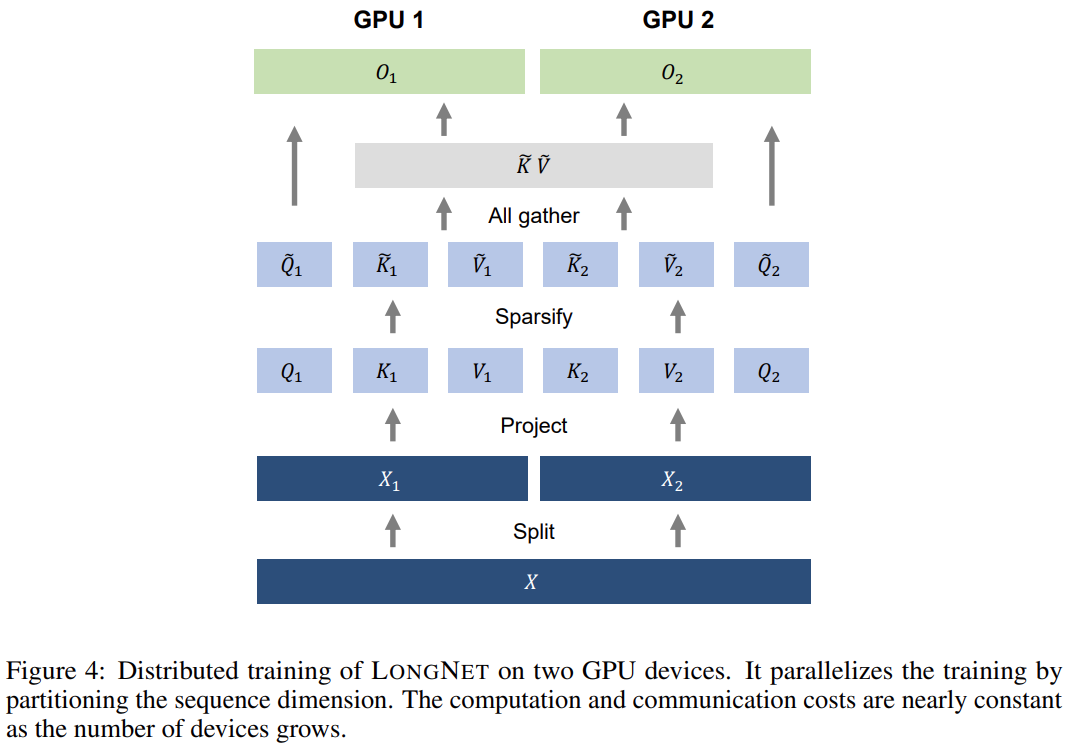
Distributed training
Although the computational complexity of dilated attention has been greatly reduced to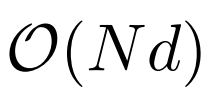 , due to computing and memory limitations, it is not feasible to extend the sequence length to millions of levels on a single GPU device of. There are some distributed training algorithms for large-scale model training, such as model parallelism [SPP 19], sequence parallelism [LXLY21, KCL 22] and pipeline parallelism [HCB 19]. However, these methods are not enough for LONGNET, especially is when the sequence dimension is very large.
, due to computing and memory limitations, it is not feasible to extend the sequence length to millions of levels on a single GPU device of. There are some distributed training algorithms for large-scale model training, such as model parallelism [SPP 19], sequence parallelism [LXLY21, KCL 22] and pipeline parallelism [HCB 19]. However, these methods are not enough for LONGNET, especially is when the sequence dimension is very large.
This research utilizes the linear computational complexity of LONGNET for distributed training of sequence dimensions. Figure 4 below shows the distributed algorithm on two GPUs, which can be further scaled to any number of devices.
##Experiment
This research will LONGNET Comparisons were made with vanilla Transformer and sparse Transformer. The difference between the architectures is the attention layer, while the other layers remain the same. The researchers expanded the sequence length of these models from 2K to 32K, while reducing the batch size to ensure that the number of tokens in each batch remained unchanged.
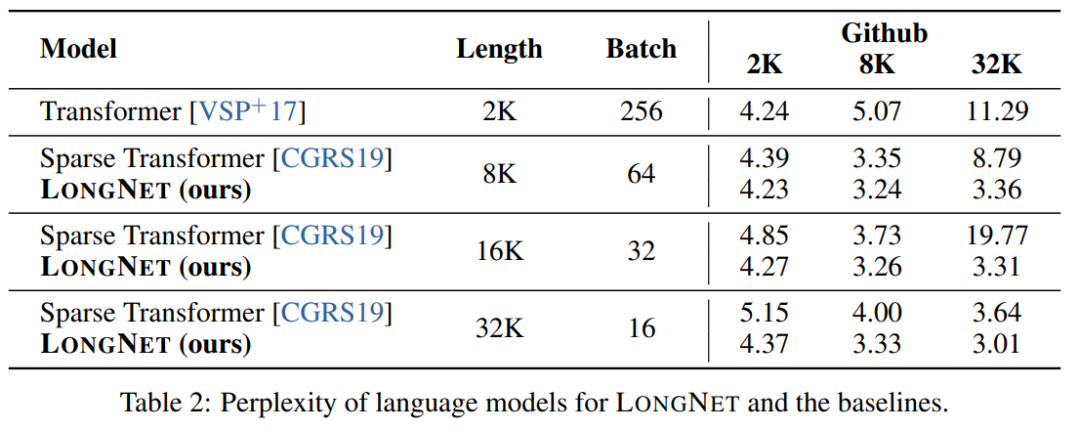
Table 2 summarizes the results of these models on the Stack dataset. Research uses complexity as an evaluation metric. The models were tested using different sequence lengths, ranging from 2k to 32k. When the input length exceeds the maximum length supported by the model, the research implements blockwise causal attention (BCA) [SDP 22], a state-of-the-art extrapolation method for language model inference.
In addition, the study removed absolute position encoding. First, the results show that increasing sequence length during training generally results in better language models. Second, the sequence length extrapolation method in inference does not apply when the length is much larger than the model supports. Finally, LONGNET consistently outperforms baseline models, demonstrating its effectiveness in language modeling.
Expansion curve of sequence length
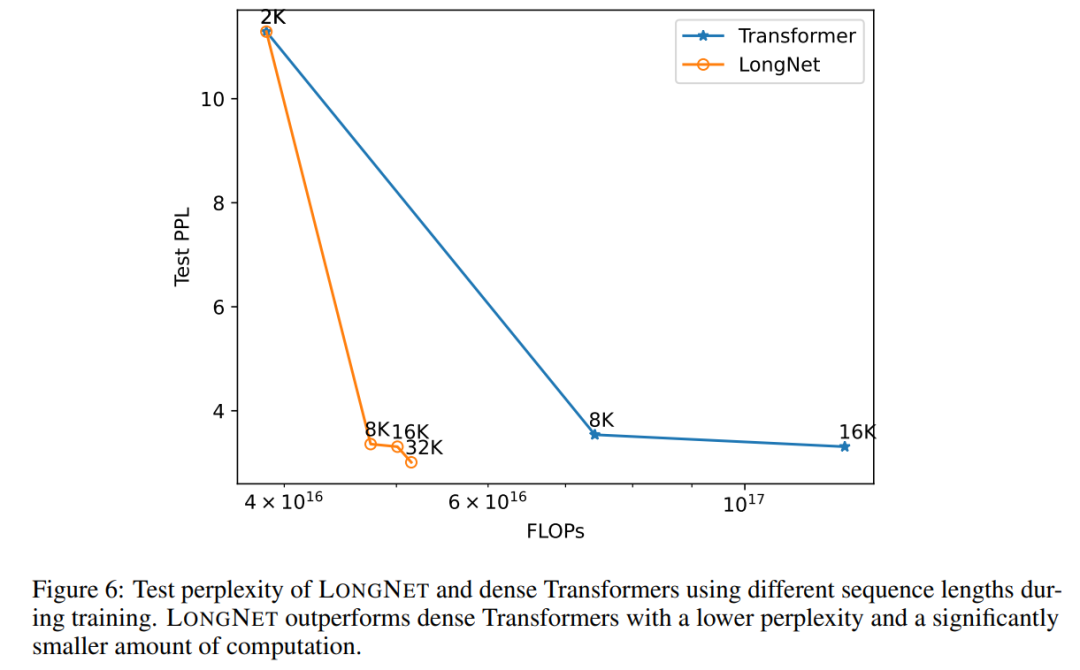
Figure 6 plots the sequence length expansion curves of vanilla transformer and LONGNET. This study estimates the computational effort by counting the total flops of matrix multiplications. The results show that both vanilla transformer and LONGNET achieve larger context lengths from training. However, LONGNET can extend the context length more efficiently, achieving lower test loss with less computation. This demonstrates the advantage of longer training inputs over extrapolation. Experiments show that LONGNET is a more efficient way to extend the context length in language models. This is because LONGNET can learn longer dependencies more efficiently.
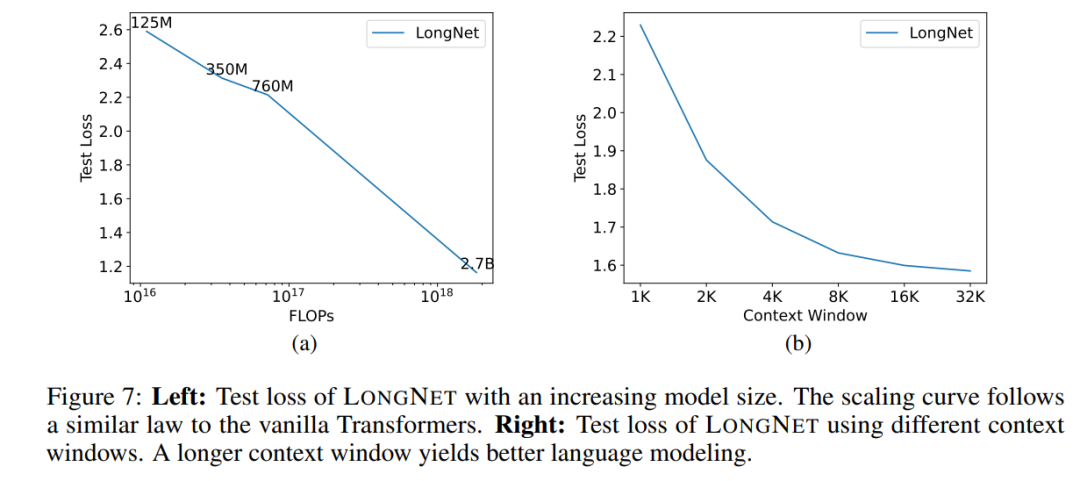
##Expand model size
An important property of large language models is that the loss expands in a power law as the amount of calculation increases. To verify whether LONGNET still follows similar scaling rules, the study trained a series of models with different model sizes (from 125 million to 2.7 billion parameters). 2.7 billion models were trained with 300B tokens, while the remaining models used approximately 400B tokens. Figure 7 (a) plots the expansion curve of LONGNET with respect to computation. The study calculated the complexity on the same test set. This proves that LONGNET can still follow a power law. This also means that dense Transformer is not a prerequisite for extending language models. Additionally, scalability and efficiency are gained with LONGNET.
##Long context prompt
Prompt Yes An important way to bootstrap language models and provide them with additional information. This study experimentally validates whether LONGNET can benefit from longer context hint windows.This study retains a prefix (prefixes) as a prompt and tests the perplexity of its suffixes (suffixes). Moreover, during the research process, the prompt was gradually expanded from 2K to 32K. To make a fair comparison, the length of the suffix is kept constant while the length of the prefix is increased to the maximum length of the model. Figure 7(b) reports the results on the test set. It shows that the test loss of LONGNET gradually decreases as the context window increases. This proves the superiority of LONGNET in fully utilizing long context to improve language models.
The above is the detailed content of Microsoft's new hot paper: Transformer expands to 1 billion tokens. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

![How to Show Internet Speed on Taskbar [Easy Steps]](https://img.php.cn/upload/article/000/465/014/169088173253603.png?x-oss-process=image/resize,m_fill,h_207,w_330) How to Show Internet Speed on Taskbar [Easy Steps]
Aug 01, 2023 pm 05:22 PM
How to Show Internet Speed on Taskbar [Easy Steps]
Aug 01, 2023 pm 05:22 PM
Internet speed is an important parameter in determining the outcome of your online experience. Whether downloading or uploading files or just browsing the web, we all need a decent internet connection. This is why users look for ways to display internet speed on the taskbar. Displaying network speed in the taskbar allows users to monitor things quickly, no matter the task at hand. The taskbar is always visible unless you are in full screen mode. But Windows doesn't offer a native option to display internet speed in the taskbar. That's why you need third-party tools. Read on to learn all about the best options! How to run a speed test from the Windows command line? Press + to open Run, type power shell, and press ++. Window
 Fix: Network connection issue that prevents access to the Internet in Windows 11 Safe Mode
Sep 23, 2023 pm 01:13 PM
Fix: Network connection issue that prevents access to the Internet in Windows 11 Safe Mode
Sep 23, 2023 pm 01:13 PM
Having no internet connection on your Windows 11 computer in Safe Mode with Networking can be frustrating, especially when diagnosing and troubleshooting system issues. In this guide, we will discuss the potential causes of the problem and list effective solutions to ensure you can access the internet in Safe Mode. Why is there no internet in safe mode with networking? The network adapter is incompatible or not loading correctly. Third-party firewalls, security software, or antivirus software may interfere with network connections in safe mode. Network service is not running. Malware Infection What should I do if the Internet cannot be used in Safe Mode on Windows 11? Before performing advanced troubleshooting steps, you should consider performing the following checks: Make sure to use
 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 ICCV'23 paper award 'Fighting of Gods'! Meta Divide Everything and ControlNet were jointly selected, and there was another article that surprised the judges
Oct 04, 2023 pm 08:37 PM
ICCV'23 paper award 'Fighting of Gods'! Meta Divide Everything and ControlNet were jointly selected, and there was another article that surprised the judges
Oct 04, 2023 pm 08:37 PM
ICCV2023, the top computer vision conference held in Paris, France, has just ended! This year's best paper award is simply a "fight between gods". For example, the two papers that won the Best Paper Award included ControlNet, a work that subverted the field of Vincentian graph AI. Since being open sourced, ControlNet has received 24k stars on GitHub. Whether it is for diffusion models or the entire field of computer vision, this paper's award is well-deserved. The honorable mention for the best paper award was awarded to another equally famous paper, Meta's "Separate Everything" ”Model SAM. Since its launch, "Segment Everything" has become the "benchmark" for various image segmentation AI models, including those that came from behind.
 NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!
Nov 14, 2023 pm 03:09 PM
NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!
Nov 14, 2023 pm 03:09 PM
Since Neural Radiance Fields was proposed in 2020, the number of related papers has increased exponentially. It has not only become an important branch of three-dimensional reconstruction, but has also gradually become active at the research frontier as an important tool for autonomous driving. NeRF has suddenly emerged in the past two years, mainly because it skips the feature point extraction and matching, epipolar geometry and triangulation, PnP plus Bundle Adjustment and other steps of the traditional CV reconstruction pipeline, and even skips mesh reconstruction, mapping and light tracing, directly from 2D The input image is used to learn a radiation field, and then a rendered image that approximates a real photo is output from the radiation field. In other words, let an implicit three-dimensional model based on a neural network fit the specified perspective
 Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.
Jun 27, 2023 pm 05:46 PM
Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.
Jun 27, 2023 pm 05:46 PM
Generative AI has taken the artificial intelligence community by storm. Both individuals and enterprises have begun to be keen on creating related modal conversion applications, such as Vincent pictures, Vincent videos, Vincent music, etc. Recently, several researchers from scientific research institutions such as ServiceNow Research and LIVIA have tried to generate charts in papers based on text descriptions. To this end, they proposed a new method of FigGen, and the related paper was also included in ICLR2023 as TinyPaper. Picture paper address: https://arxiv.org/pdf/2306.00800.pdf Some people may ask, what is so difficult about generating the charts in the paper? How does this help scientific research?
 Chat screenshots reveal the hidden rules of AI review! AAAI 3000 yuan is strong accept?
Apr 12, 2023 am 08:34 AM
Chat screenshots reveal the hidden rules of AI review! AAAI 3000 yuan is strong accept?
Apr 12, 2023 am 08:34 AM
Just as the AAAI 2023 paper submission deadline was approaching, a screenshot of an anonymous chat in the AI submission group suddenly appeared on Zhihu. One of them claimed that he could provide "3,000 yuan a strong accept" service. As soon as the news came out, it immediately aroused public outrage among netizens. However, don’t rush yet. Zhihu boss "Fine Tuning" said that this is most likely just a "verbal pleasure". According to "Fine Tuning", greetings and gang crimes are unavoidable problems in any field. With the rise of openreview, the various shortcomings of cmt have become more and more clear. The space left for small circles to operate will become smaller in the future, but there will always be room. Because this is a personal problem, not a problem with the submission system and mechanism. Introducing open r
 The Chinese team won the best paper and best system paper awards, and the CoRL research results were announced.
Nov 10, 2023 pm 02:21 PM
The Chinese team won the best paper and best system paper awards, and the CoRL research results were announced.
Nov 10, 2023 pm 02:21 PM
Since it was first held in 2017, CoRL has become one of the world's top academic conferences in the intersection of robotics and machine learning. CoRL is a single-theme conference for robot learning research, covering multiple topics such as robotics, machine learning and control, including theory and application. The 2023 CoRL Conference will be held in Atlanta, USA, from November 6th to 9th. According to official data, 199 papers from 25 countries were selected for CoRL this year. Popular topics include operations, reinforcement learning, and more. Although CoRL is smaller in scale than large AI academic conferences such as AAAI and CVPR, as the popularity of concepts such as large models, embodied intelligence, and humanoid robots increases this year, relevant research worthy of attention will also
