
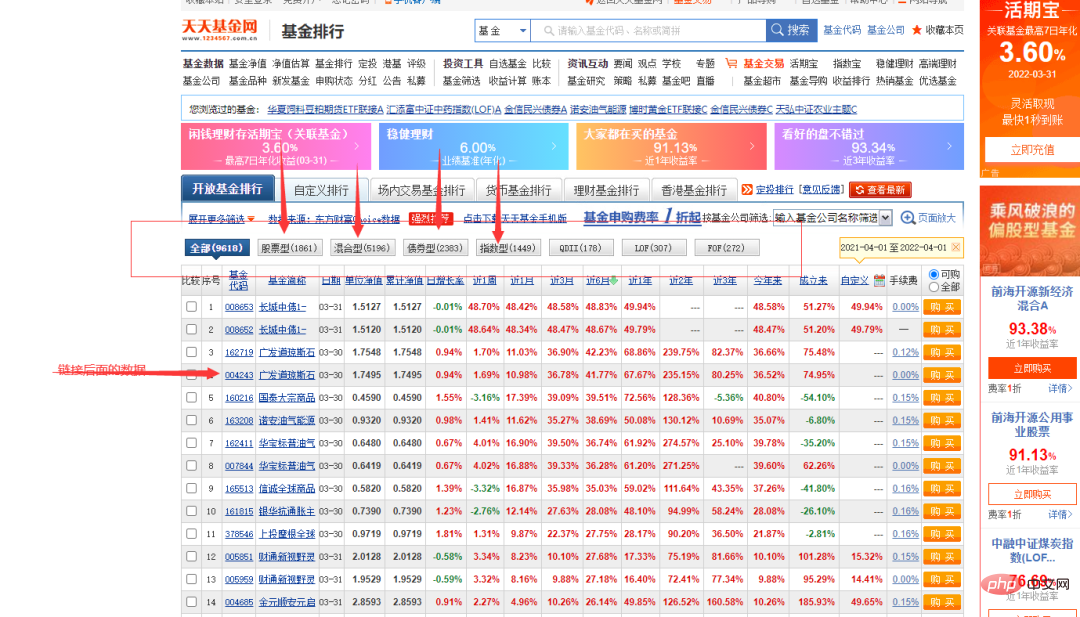
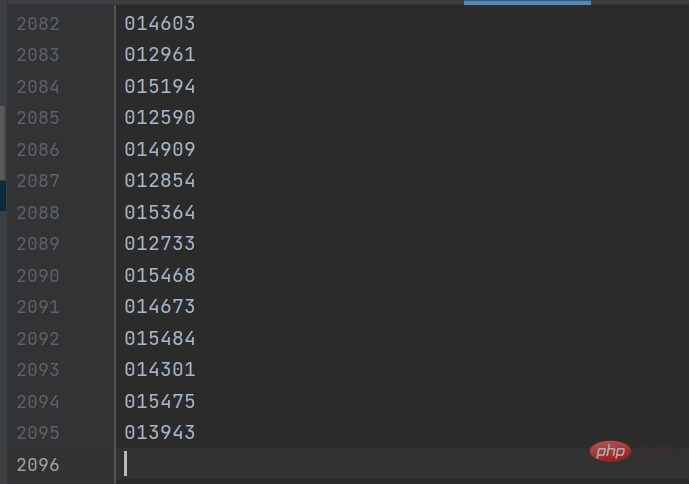
You can see that the fund code column in the picture above has different numbers. Click on one randomly to enter the fund details page. The links are also very regular, with the fund code as the symbol. 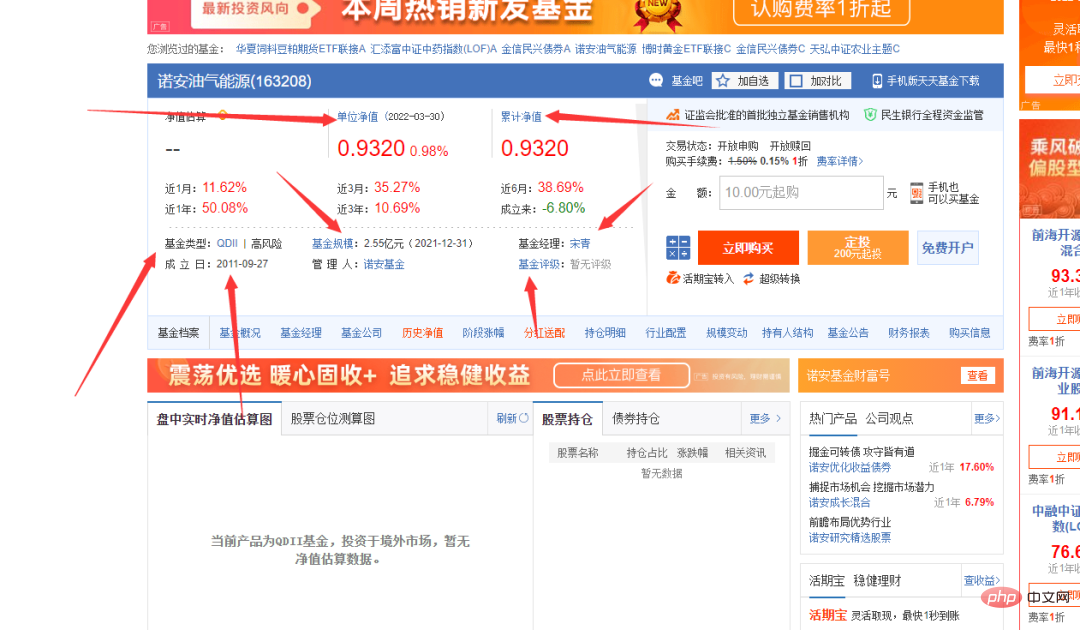
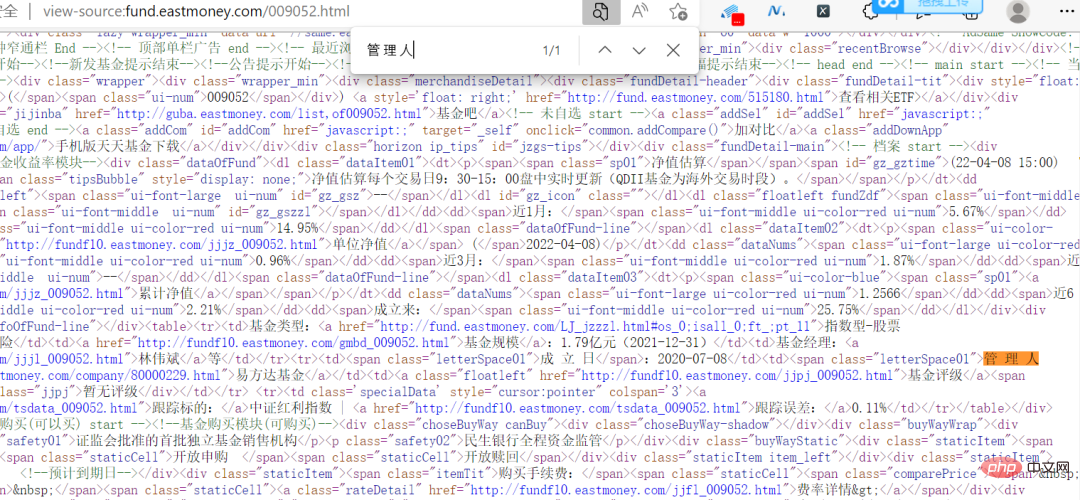
pi is changing in the request parameters, and this value happens to correspond to the page, so you can directly construct the request parameters. . 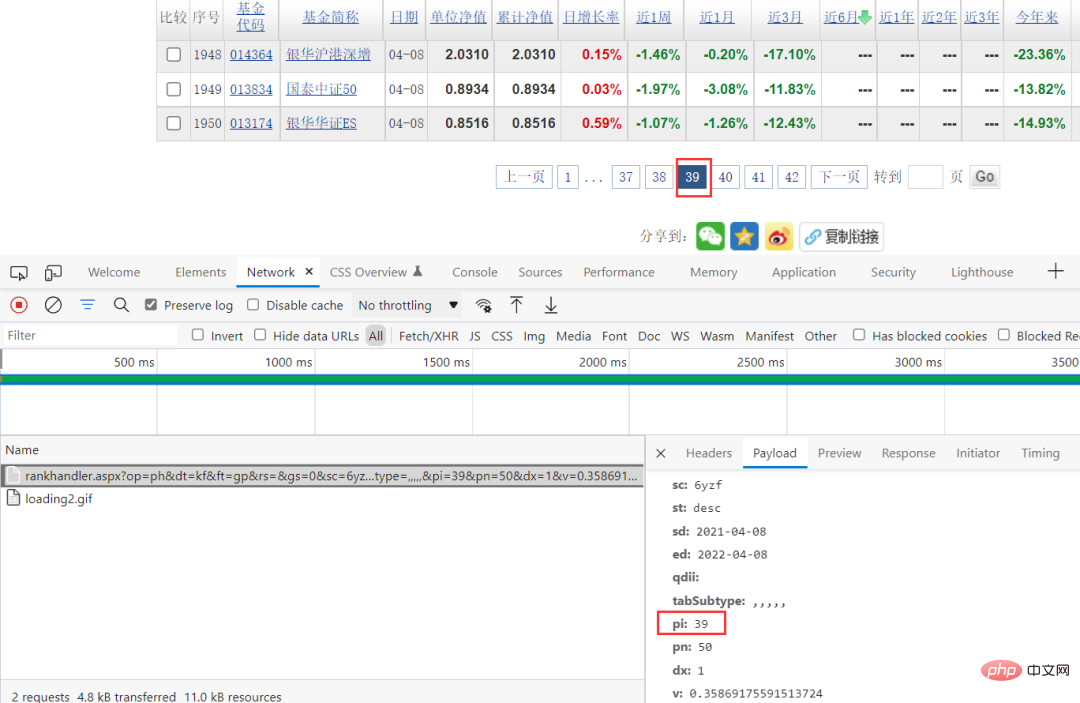
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P<items>.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
gp_id = item.group('items').split(',')[0]The result is as shown below:
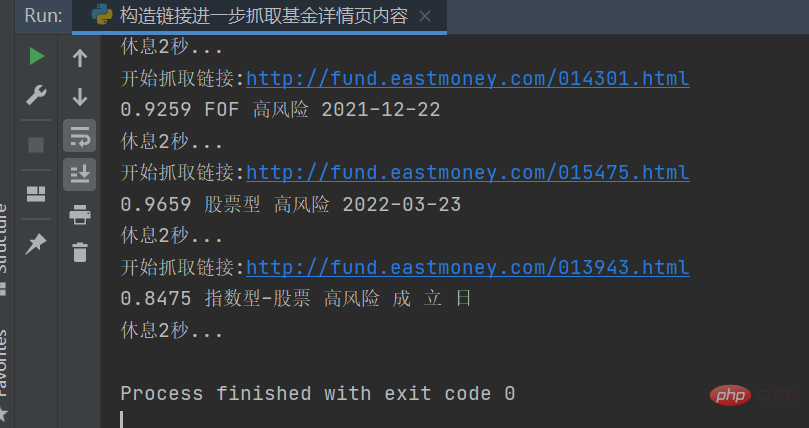
The details will be constructed later page link to obtain the fund information of the details page. The key code is as follows:
response = requests.get(url, headers=headers) response.encoding = response.apparent_encoding selectors = etree.HTML(response.text) danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0] danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0] leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0] lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
The result is as shown in the figure below:
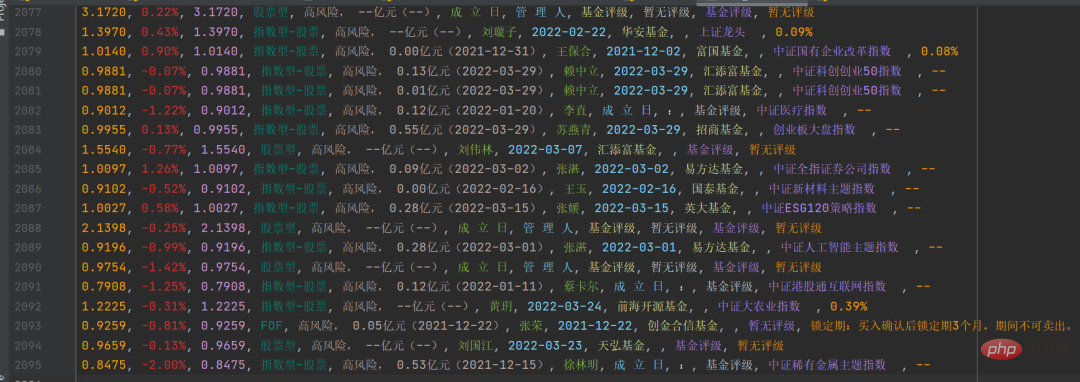
 Process the specific information into corresponding strings, and then save it to
Process the specific information into corresponding strings, and then save it to csv file, the results are as shown below:
 With this, you can do further statistics and data analysis.
With this, you can do further statistics and data analysis.
Hello everyone, I am a Python advanced person. This article mainly shares the use of Python web crawler to obtain fund data information. This project is not too difficult, but there are a few pitfalls. Everyone is welcome to try it. If you encounter any problems, please add me as a friend and I will help solve it.
This article is mainly based on the classification of [stock type]. I have not done other types. You are welcome to try. In fact, the logic is the same, just change the parameters. . 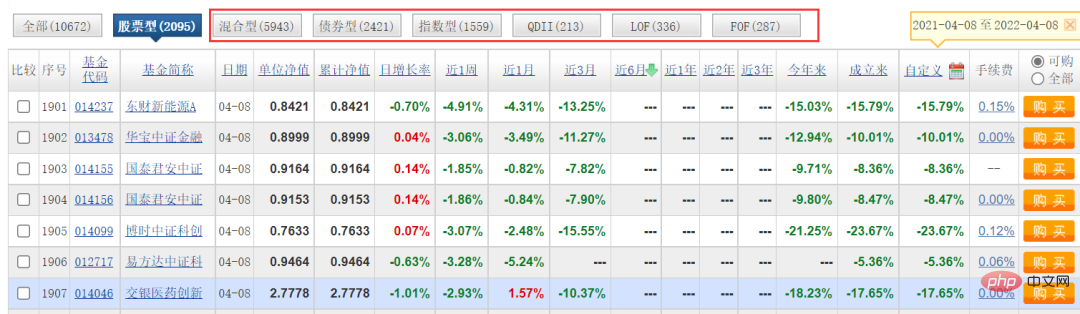
The above is the detailed content of Teach you step by step how to use Python web crawler to obtain fund information. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



