
 Backend Development
Python Tutorial
Teach you step-by-step how to use Python web crawler to obtain King of Glory hero equipment instructions and automatically generate markdown files
Backend Development
Python Tutorial
Teach you step-by-step how to use Python web crawler to obtain King of Glory hero equipment instructions and automatically generate markdown files
Teach you step-by-step how to use Python web crawler to obtain King of Glory hero equipment instructions and automatically generate markdown files
1. Preface
Played Friends who play the Honor of Kings game all know that hero equipment is very important. A reasonable equipment, coupled with inscriptions, can make you unstoppable and unstoppable on the battlefield of King!
A few days ago, I saw in the [Minglao] group that he shared a Python web crawler to obtain the equipment instructions of the King of Glory hero, and used the thread pool to download the equipment pictures, and then automatically generated them. Markdown file, there is a lot of useful content, I will share it with you here, everyone is welcome to try it.
2. Data Acquisition
Our target website here is the official website of King of Glory, as shown in the figure below. 
Then click the [More] button of [Hero/Skin] on the right side of the homepage to enter the details page, as shown in the figure below. Click [In-game Props] to see the output The information is installed, which contains the target information we want. 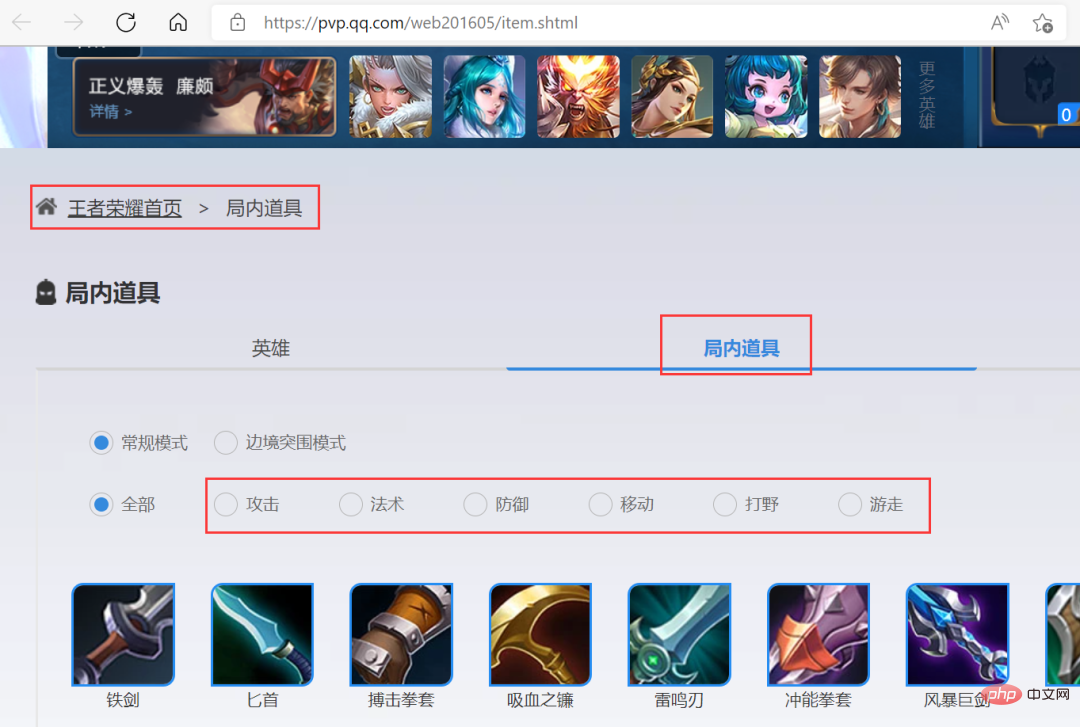
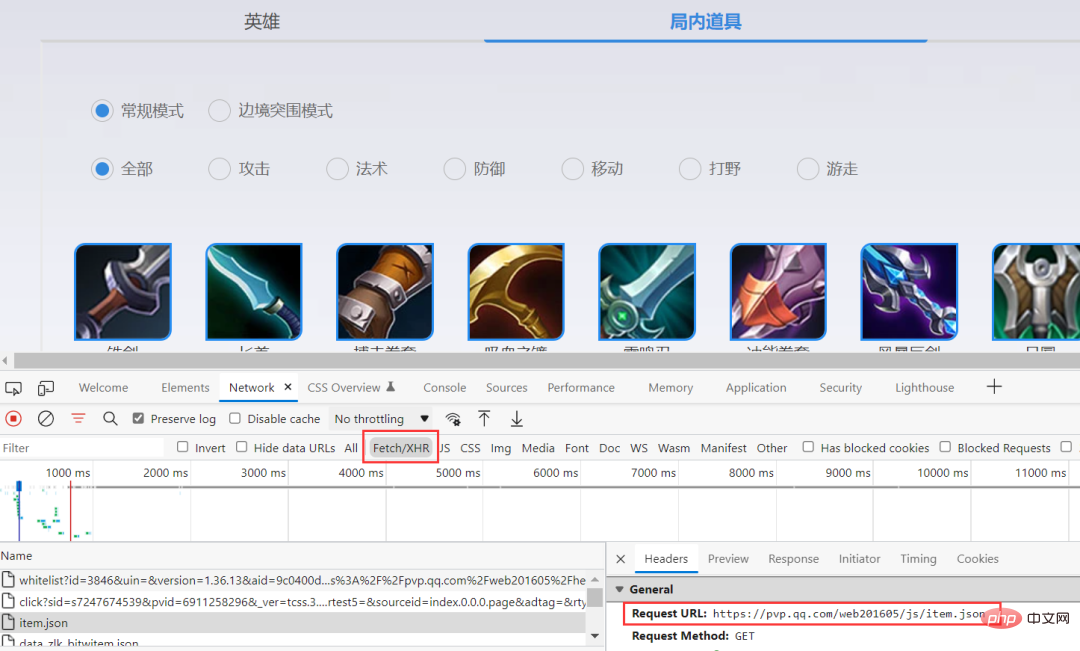
By capturing packets through the browser, you can obtain specific information, which can be seen stored in the json format.
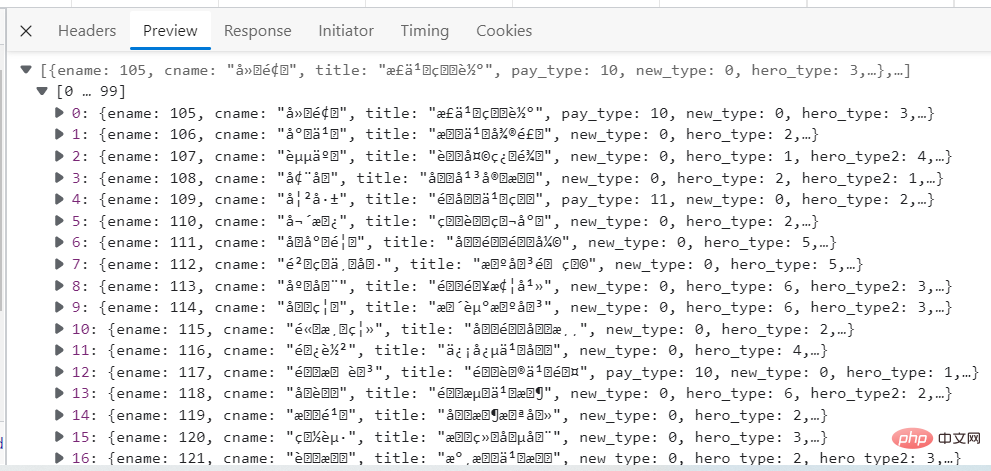
 The picture below is a screenshot of the data details. You can see that there are Chinese garbled characters. This does not affect it. At least the data can be obtained.
The picture below is a screenshot of the data details. You can see that there are Chinese garbled characters. This does not affect it. At least the data can be obtained.
Code implementation process
After finding the data source, the next step is to implement the code. Let’s take a look. , the [Minglao] code is directly applied here, and it is run in jupyter notebook.
Get equipment data
import requests
import pandas as pd
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/88.0.4324.104 Safari/537.36 '
}
target = 'https://pvp.qq.com/web201605/js/item.json'
item_list = requests.get(target, headers=headers).json()
item_df = pd.DataFrame(item_list)
item_df.sort_values(["item_type", "price", "item_id"], inplace=True)
item_df.fillna("", inplace=True)
item_df.des1 = item_df.des1.str.replace("</?p>", "", regex=True)
item_df.des2 = item_df.des2.str.replace("</?p>", "", regex=True)
item_dfThe result is as shown below:
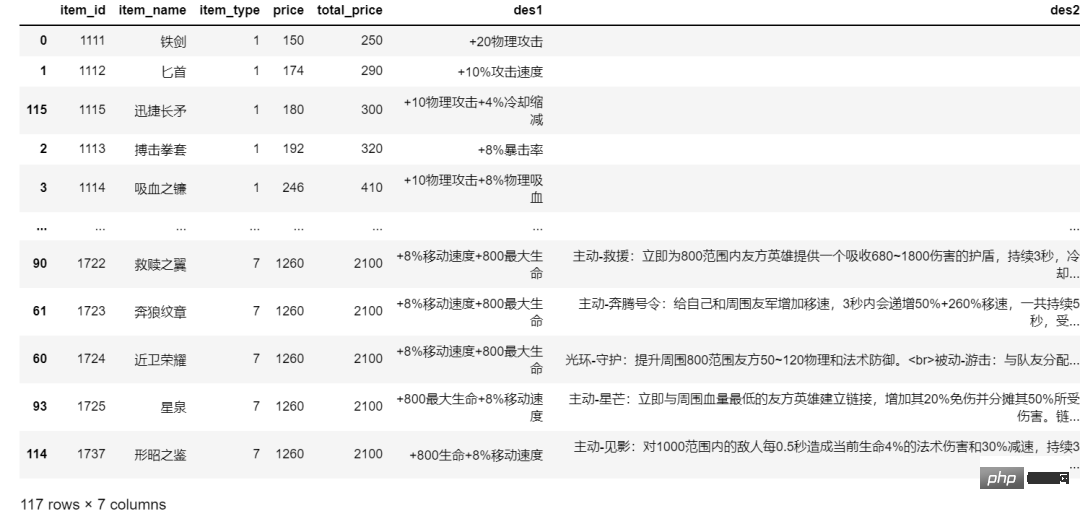
Next, use the thread pool method to download pictures. The method of splicing pictures is also very simple. You can see it at a glance by looking at the picture below.
The following is the code implementation: 
import os
from concurrent.futures import ThreadPoolExecutor
def download_img(item_id):
if os.path.exists(f"imgs/{item_id}.jpg"):
return
imgurl = f"http://game.gtimg.cn/images/yxzj/img201606/itemimg/{item_id}.jpg"
res = requests.get(imgurl)
with open(f"imgs/{item_id}.jpg", "wb") as f:
f.write(res.content)
os.makedirs("imgs", exist_ok=True)
with ThreadPoolExecutor(max_workers=8) as executor:
nums = executor.map(download_img, item_df.item_id)
The code is as follows. The first part is the preprocessing of the data, and the second part is writing the file:
item_type_dict = {1: '攻击', 2: '法术', 3: '防御', 4: '移动', 5: '打野', 7: '游走'}
item_ids = item_df.item_id.values
item_df.item_id = item_df.item_id.apply(
lambda item_id: f"")
item_df.item_type = item_df.item_type.map(item_type_dict)
item_df.columns = ["图片", "装备名称", "类型", "售价", "总价", "基础描述", "扩展描述"]
item_dfwith open("王者装备说明.md", "w") as f:
for item_type, item_split in item_df.groupby("类型", sort=False):
f.write(f"# {item_type}\n")
item_split.drop(columns="类型", inplace=True)
f.write(item_split.to_markdown(index=False))
f.write("\n\n")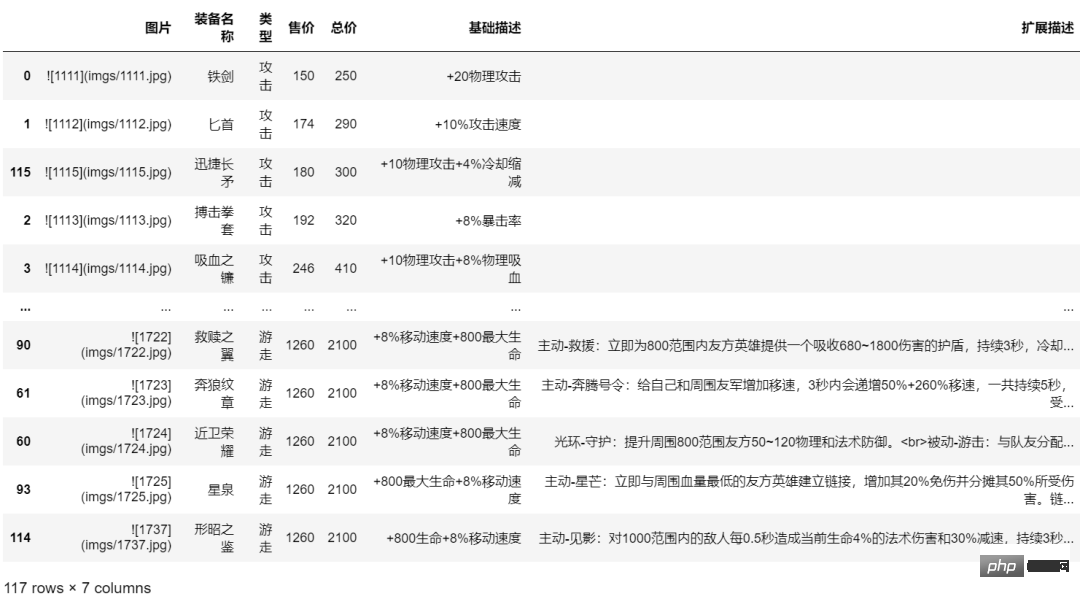
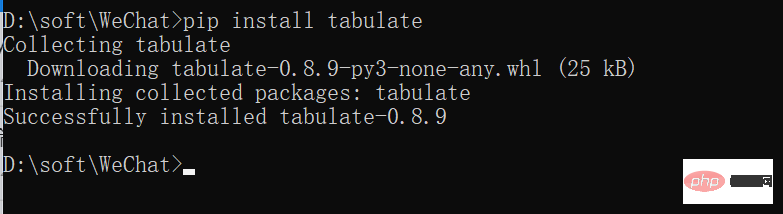
What a great guy! When I implemented this step, I encountered an error, as shown below: 
Missing optional dependency 'tabulate'. Use pip or conda to install tabulate.
提示却少依赖库,只需要在cmd下进行安装即可pip install tabulate,之后就可以正常运行了。
生成Excel表格
不过Markdown的表格无法任意调整,图片需要点击后才会放大,下面我们考虑生成Excel表格:首先需要整理数据,代码如下:
item_df.图片 = ""
item_df.基础描述 = item_df.基础描述.str.replace("<br>", "\n")
item_df.扩展描述 = item_df.扩展描述.str.replace("<br>", "\n")
item_df生成结果如下图所示:
 之后将结果写入到
之后将结果写入到Excel中去,代码如下所示:
# 写入Excel表格
from openpyxl.drawing.image import Image
from openpyxl.styles import Alignment
with pd.ExcelWriter("王者装备说明.xlsx", engine='openpyxl') as writer:
item_df.to_excel(writer, sheet_name='装备说明', index=False)
worksheet = writer.sheets['装备说明']
worksheet.column_dimensions["A"].width = 11
for item_id, (cell,) in zip(item_ids, worksheet.iter_rows(2, None, 1, 1)):
worksheet.row_dimensions[cell.row].height = 67
worksheet.add_image(Image(f"imgs/{item_id}.jpg"), f'A{cell.row}')
worksheet.column_dimensions["F"].width = 15
worksheet.column_dimensions["G"].width = 35
writer.save()打开文件,效果图如下图所示:

当然了,大家也可以根据自己想要的效果生成HTML和Word等等。
三、总结
大家好,我是Python进阶者。这篇文章主要分享了一个使用Python网络爬虫获取王者荣耀英雄出装说明,并使用线程池的方式下载了出装图片,之后还自动化生成了markdown文件,干货内容很多,欢迎大家积极尝试,如果有遇到问题,请添加我好友,我帮助解决。
最后感谢粉丝【明佬】分享的代码喝王者荣耀出装攻略,真是太强了,上王者指日可待!
最后放上【明佬】的csdn链接:https://xxmdmst.blog.csdn.net/article/details/124035041,点击阅读原文可以直达噢!
The above is the detailed content of Teach you step-by-step how to use Python web crawler to obtain King of Glory hero equipment instructions and automatically generate markdown files. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python have their own advantages and disadvantages, and the choice depends on project needs and personal preferences. 1.PHP is suitable for rapid development and maintenance of large-scale web applications. 2. Python dominates the field of data science and machine learning.
 Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python and JavaScript have their own advantages and disadvantages in terms of community, libraries and resources. 1) The Python community is friendly and suitable for beginners, but the front-end development resources are not as rich as JavaScript. 2) Python is powerful in data science and machine learning libraries, while JavaScript is better in front-end development libraries and frameworks. 3) Both have rich learning resources, but Python is suitable for starting with official documents, while JavaScript is better with MDNWebDocs. The choice should be based on project needs and personal interests.
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python excels in automation, scripting, and task management. 1) Automation: File backup is realized through standard libraries such as os and shutil. 2) Script writing: Use the psutil library to monitor system resources. 3) Task management: Use the schedule library to schedule tasks. Python's ease of use and rich library support makes it the preferred tool in these areas.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
VS Code is the full name Visual Studio Code, which is a free and open source cross-platform code editor and development environment developed by Microsoft. It supports a wide range of programming languages and provides syntax highlighting, code automatic completion, code snippets and smart prompts to improve development efficiency. Through a rich extension ecosystem, users can add extensions to specific needs and languages, such as debuggers, code formatting tools, and Git integrations. VS Code also includes an intuitive debugger that helps quickly find and resolve bugs in your code.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
