
 Backend Development
Python Tutorial
Take stock of the differences between the urllib library and requests library in Python
Backend Development
Python Tutorial
Take stock of the differences between the urllib library and requests library in Python
Take stock of the differences between the urllib library and requests library in Python
1. Preface
When using a Python crawler, you need to simulate initiating network requests. The main libraries used are the requests library and python built-in For the urllib library, it is generally recommended to use requests, which is a re-encapsulation of urllib.
What is the difference between them?
The following is a detailed explanation of the case to understand the main differences in their use.
2. urllib library
Introduction:The response object of the urllib library is to first create the http and request objects, and then load them into reques.urlopen. http request.
What is returned is http, response object, which is actually html attribute. Use .read().decode() to decode and convert it into str string type. After decoding, Chinese characters can be displayed.
Example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
##Run result:
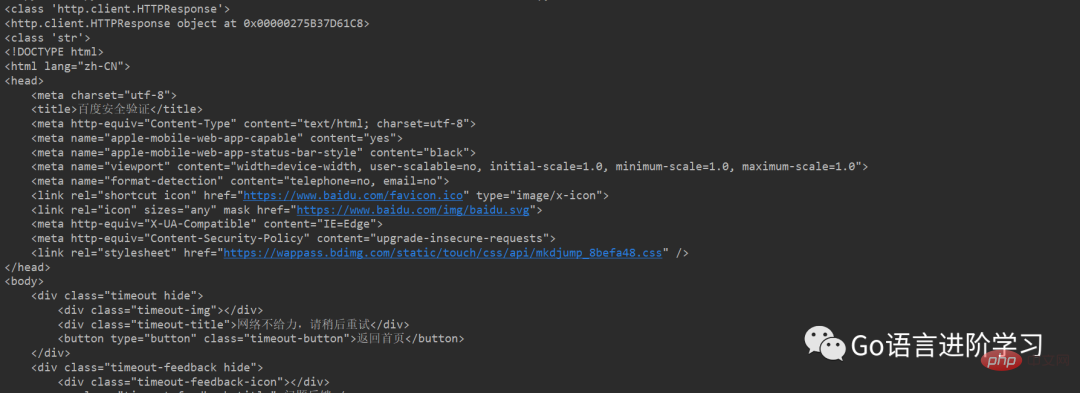 ##Note:
##Note:
Usually crawl web pages, when constructing http When making a request, you need to add some additional information, such as Useragent, cookie, etc., or add a proxy server. Often these are necessary anti-crawling mechanisms.
##
三、requests库
简介:requests库调用是requests.get方法传入url和参数,返回的对象是Response对象,打印出来是显示响应状态码。
通过.text 方法可以返回是unicode 型的数据,一般是在网页的header中定义的编码形式,而content返回的是bytes,二级制型的数据,还有 .json方法也可以返回json字符串。
如果想要提取文本就用text,但是如果你想要提取图片、文件等二进制文件,就要用content,当然decode之后,中文字符也会正常显示。
requests的优势:Python爬虫时,更建议用requests库。因为requests比urllib更为便捷,requests可以直接构造get,post请求并发起,而urllib.request只能先构造get,post请求,再发起。
例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
运行结果 (可以直接获取整网页的信息,打印控制台):
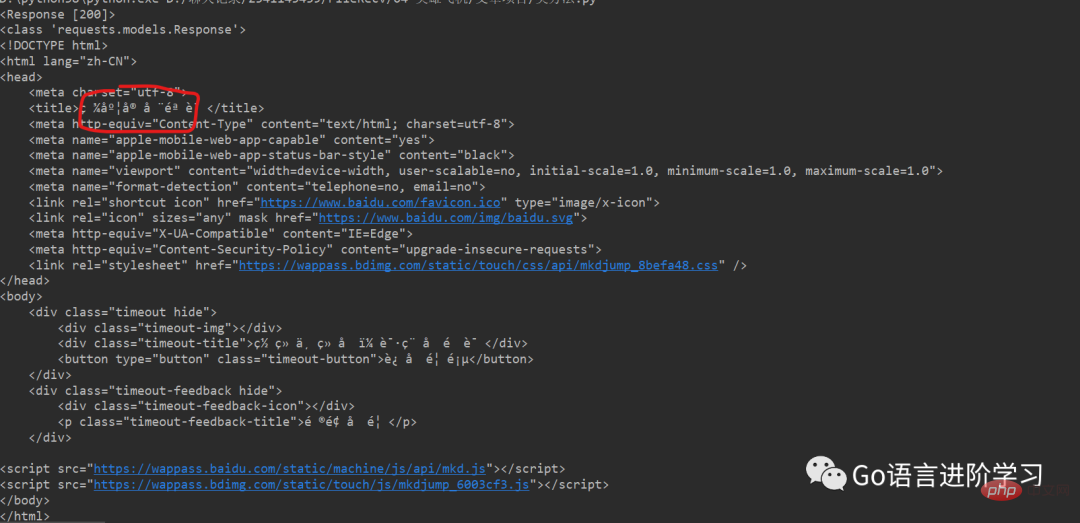
四、总结
1. 本文基于Python基础,主要介绍了urllib库和requests库的区别。
2. 在使用urllib内的request模块时,返回体获取有效信息和请求体的拼接需要decode和encode后再进行装载。进行http请求时需先构造get或者post请求再进行调用,header等头文件也需先进行构造。
3. requests是对urllib的进一步封装,因此在使用上显得更加的便捷,建议在实际应用当中尽量使用requests。
4. 希望能给一些对爬虫感兴趣,有一个具体的概念。方法只是一种工具,试着去爬一爬会更容易上手,网络也会有很多的坑,做爬虫更需要大量的经验来应付复杂的网络情况。
5. 希望大家一起探讨学习, 一起进步。
The above is the detailed content of Take stock of the differences between the urllib library and requests library in Python. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
VS Code is available on Mac. It has powerful extensions, Git integration, terminal and debugger, and also offers a wealth of setup options. However, for particularly large projects or highly professional development, VS Code may have performance or functional limitations.
 Can vscode run ipynb
Apr 15, 2025 pm 07:30 PM
Can vscode run ipynb
Apr 15, 2025 pm 07:30 PM
The key to running Jupyter Notebook in VS Code is to ensure that the Python environment is properly configured, understand that the code execution order is consistent with the cell order, and be aware of large files or external libraries that may affect performance. The code completion and debugging functions provided by VS Code can greatly improve coding efficiency and reduce errors.
