

Why do code specifications require SQL statements not to have too many joins?
Send sub-questions
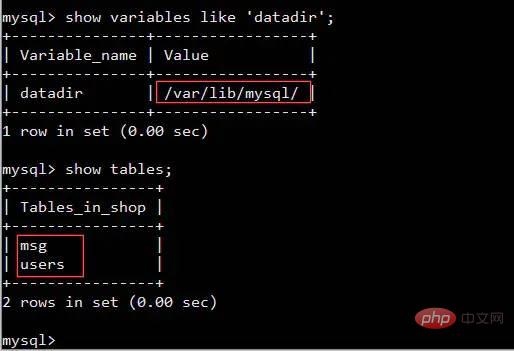
Interviewer: Have you ever operated Linux?
Me: Yes
Interviewer: What command should I use to check the memory usage?
Me: free or top
Interviewer: Then tell me what information you can see using the free command
Me: Then, as shown in the figure below, you can see the usage of memory and cache.
total total memory
##used used memory
free free memory
buff/cache used cache
avaiable memory

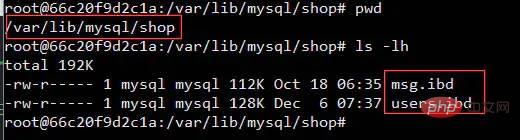
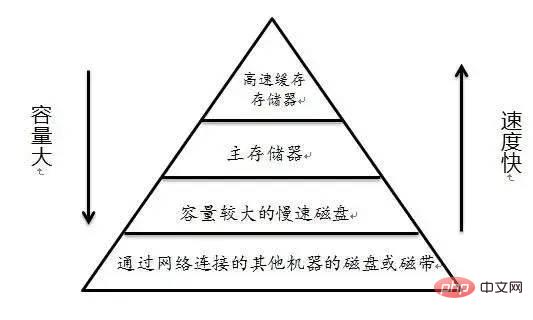
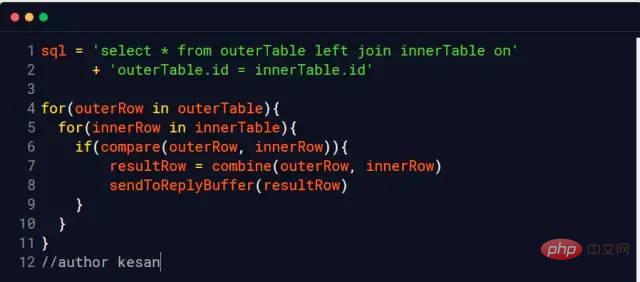
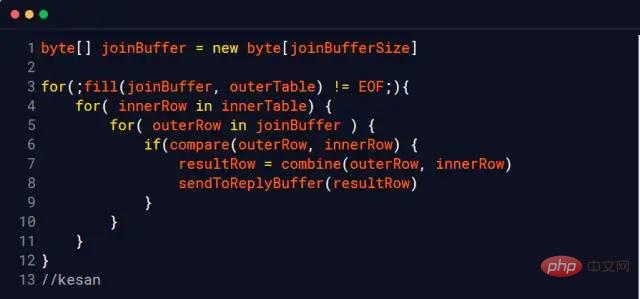
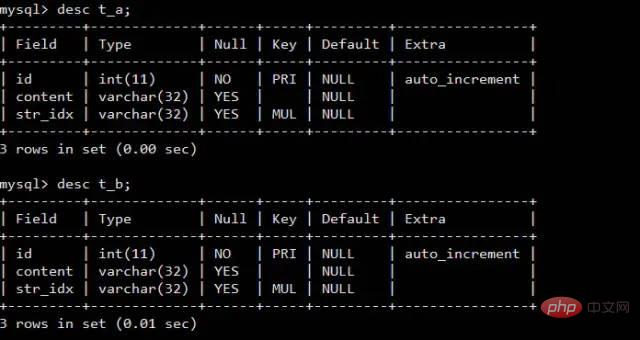
Then you know how Clear the used cache (buff/cache) Me: em... I don’t know Interviewer: ##Me: (Send points, Overjoyed) The benefits are huge. After clearing the cache, we will have more available memory space. Just like the little rocket of xx Guardian on the PC, a lot of memory will be released with one click. Interviewer: em…., go back and wait for notification Interviewer: Change the topic and let’s talk Your understanding of join Me: Okay (if you answer it wrong again, it’s over, seize the opportunity) inner join inner join ##left join left join right join right join full join Full join #Picture source: https://www.cnblogs.com/reaptomorrow-flydream/p/8145610.html Interviewer: If you need to use join statements during project development, how to optimize and improve performance? Me: Divided into two In this case, the data size is small and the data size is large. Interviewer: Then? Me: For 1. The data size is small and all is put into the memory. Wow 2. The data scale is large #You can optimize the execution speed of the join statement by adding indexes You can use redundant information to reduce the number of joins Reduce the number of table connections as much as possible, the number of table connections for one SQL statement No more than 5 times Interviewer: It can be summarized that the join statement is relatively performance-consuming, right? Me: Yes Interviewer: Why? Me: There must be a comparison process when executing the join statement Interviewer: Yes Me: The statement comparing two tables one by one is relatively slow, so we can read the data in the two tables into a memory block in sequence, using MySQL Taking the InnoDB engine as an example, we can definitely find the relevant memory area by using the following statement As shown in the figure Indicates that the size of join_buffer_size will affect the execution performance of our join statement Interviewer: What else? Me: Any project will eventually go online, it is inevitable to generate data, and the scale of the data cannot be too small Interviewer: Yes Like this Me:Most of the data in the database will eventually be saved to the hard disk and stored in the form of files. Take MySQL's InnoDB engine as an example InnoDB uses page as the basic IO unit, and the size of each page is 16KB InnoDB will create an .ibd file for each table to store data Verification Me: This means that we need to read as many files as there are tables to connect, although it can be used Index, but it is still inevitable to move the hard disk head frequently Interviewer:In other words, frequent movement of the head will affect the performance, right Me:Yes, don’t the current open source frameworks like to say that they have greatly improved performance through sequential reading and writing, such as hbase and kafka Interviewer: That’s right, then Do you think Linux has optimized this? Tip, you can execute the free command again to take a look Me:Strange why the cache occupies more than 1.2G ##Image source: https://www.linuxatemyram.com/ Interviewer: Have you ever thought about buff/cache is stored in What? Why does buff/cache occupy so much memory, and the available memory is available and there is still 1.1G? Why can you clear the memory occupied by buff/cache through two commands, but you can only release used by ending the process? Me: Releasing the memory occupied by buff/cache so casually means that it is not important, and clearing it will not affect the operation of the system Interviewer: Not entirely true Me: Is that so? I think of a sentence in "CSAPP" (In-depth Understanding of Computer Systems) The essence of the memory hierarchy is that each layer of storage device is the cache of the lower layer device In layman’s terms, it means that Linux will treat the memory as the cache of the hard disk Related information: http://tldp.org /LDP/sag/html/buffer-cache.html Interviewer: Now you know how to answer the scoring question Me: I…. Interviewer: Give it to you again Given an opportunity, what would you do if you were asked to implement the Join algorithm? Me: If there is no index, the nested loop will be finished. If there is an index, you can use the index to improve performance. Interviewer: Back to join_buffer, what do you think is stored in join_buffer? Me: During the scanning process, the database will select a table and add it to The data that needs to be returned and compared with other tables is put into join_buffer Interviewer: How to deal with it when there is an index? Me: This is relatively simple. Just read the index trees of the two tables directly for comparison and that's it. Let me introduce the non-index processing method here Nested Loop Join Block nested loop MySQL InnoDB will use this algorithm when no index can be used Consider the following two tables t_a and t_b When it is not possible When using an index to perform a join operation, InnoDB will automatically use the Block nested loop algorithm When I was in school, the database teacher most I like to study database paradigms, and it wasn’t until I got to work that I learned that everything should be based on performance. If redundancy is possible, use redundancy. If redundancy is not possible, join if join really affects performance. Try increasing your join_buffer_size, or change to a solid state drive. "In-depth understanding of computer systems"-Chapter 6 Memory Hierarchysync; echo 3 > /proc/sys/vm/drop_caches You can clear the buff/cache. Can you tell me if I can execute this command online? 
Let’s talk about SQL Join
Review
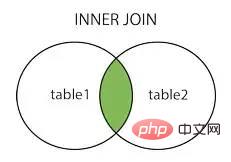
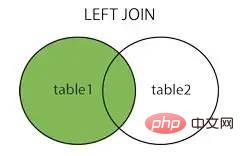
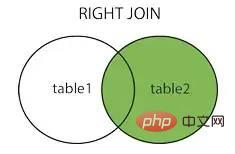
join in SQL can combine specified tables according to certain conditions and return data to the clientJoin methods include

Buffer
show variables like '%buffer%'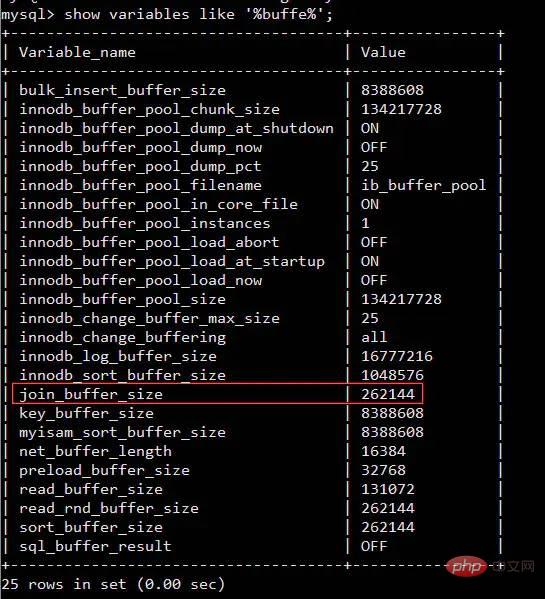
A major premise


Taste it carefullyAfter thinking for a few minutes

##Join Algorithm

Summary
Reference materials
Author of "Experiments and fun with the Linux disk cache" Use several examples to illustrate the impact of hard disk cache on program execution performance
《Linux ate my ram》Explanation of Free parameters
How to clear the buffer/pagecache (disk cache) under Linux The sub-question command is given at the beginning of the article Explain
How MySQL runs: Understand MySQL from the root
Block bested loop The official documentation from MariaDB explains the implementation of the Block-Nested-Loop algorithm
The above is the detailed content of Why do code specifications require SQL statements not to have too many joins?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
36
110
52
36
110

 What is the difference between HQL and SQL in Hibernate framework?
Apr 17, 2024 pm 02:57 PM
What is the difference between HQL and SQL in Hibernate framework?
Apr 17, 2024 pm 02:57 PM
HQL and SQL are compared in the Hibernate framework: HQL (1. Object-oriented syntax, 2. Database-independent queries, 3. Type safety), while SQL directly operates the database (1. Database-independent standards, 2. Complex executable queries and data manipulation).
 Usage of division operation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
Usage of division operation in Oracle SQL
Mar 10, 2024 pm 03:06 PM
"Usage of Division Operation in OracleSQL" In OracleSQL, division operation is one of the common mathematical operations. During data query and processing, division operations can help us calculate the ratio between fields or derive the logical relationship between specific values. This article will introduce the usage of division operation in OracleSQL and provide specific code examples. 1. Two ways of division operations in OracleSQL In OracleSQL, division operations can be performed in two different ways.
 Comparison and differences of SQL syntax between Oracle and DB2
Mar 11, 2024 pm 12:09 PM
Comparison and differences of SQL syntax between Oracle and DB2
Mar 11, 2024 pm 12:09 PM
Oracle and DB2 are two commonly used relational database management systems, each of which has its own unique SQL syntax and characteristics. This article will compare and differ between the SQL syntax of Oracle and DB2, and provide specific code examples. Database connection In Oracle, use the following statement to connect to the database: CONNECTusername/password@database. In DB2, the statement to connect to the database is as follows: CONNECTTOdataba
 Detailed explanation of the Set tag function in MyBatis dynamic SQL tags
Feb 26, 2024 pm 07:48 PM
Detailed explanation of the Set tag function in MyBatis dynamic SQL tags
Feb 26, 2024 pm 07:48 PM
Interpretation of MyBatis dynamic SQL tags: Detailed explanation of Set tag usage MyBatis is an excellent persistence layer framework. It provides a wealth of dynamic SQL tags and can flexibly construct database operation statements. Among them, the Set tag is used to generate the SET clause in the UPDATE statement, which is very commonly used in update operations. This article will explain in detail the usage of the Set tag in MyBatis and demonstrate its functionality through specific code examples. What is Set tag Set tag is used in MyBati
 What does the identity attribute in SQL mean?
Feb 19, 2024 am 11:24 AM
What does the identity attribute in SQL mean?
Feb 19, 2024 am 11:24 AM
What is Identity in SQL? Specific code examples are needed. In SQL, Identity is a special data type used to generate auto-incrementing numbers. It is often used to uniquely identify each row of data in a table. The Identity column is often used in conjunction with the primary key column to ensure that each record has a unique identifier. This article will detail how to use Identity and some practical code examples. The basic way to use Identity is to use Identit when creating a table.
 How to implement Springboot+Mybatis-plus without using SQL statements to add multiple tables
Jun 02, 2023 am 11:07 AM
How to implement Springboot+Mybatis-plus without using SQL statements to add multiple tables
Jun 02, 2023 am 11:07 AM
When Springboot+Mybatis-plus does not use SQL statements to perform multi-table adding operations, the problems I encountered are decomposed by simulating thinking in the test environment: Create a BrandDTO object with parameters to simulate passing parameters to the background. We all know that it is extremely difficult to perform multi-table operations in Mybatis-plus. If you do not use tools such as Mybatis-plus-join, you can only configure the corresponding Mapper.xml file and configure The smelly and long ResultMap, and then write the corresponding sql statement. Although this method seems cumbersome, it is highly flexible and allows us to
 How to solve the 5120 error in SQL
Mar 06, 2024 pm 04:33 PM
How to solve the 5120 error in SQL
Mar 06, 2024 pm 04:33 PM
Solution: 1. Check whether the logged-in user has sufficient permissions to access or operate the database, and ensure that the user has the correct permissions; 2. Check whether the account of the SQL Server service has permission to access the specified file or folder, and ensure that the account Have sufficient permissions to read and write the file or folder; 3. Check whether the specified database file has been opened or locked by other processes, try to close or release the file, and rerun the query; 4. Try as administrator Run Management Studio as etc.
 How to use SQL statements for data aggregation and statistics in MySQL?
Dec 17, 2023 am 08:41 AM
How to use SQL statements for data aggregation and statistics in MySQL?
Dec 17, 2023 am 08:41 AM
How to use SQL statements for data aggregation and statistics in MySQL? Data aggregation and statistics are very important steps when performing data analysis and statistics. As a powerful relational database management system, MySQL provides a wealth of aggregation and statistical functions, which can easily perform data aggregation and statistical operations. This article will introduce the method of using SQL statements to perform data aggregation and statistics in MySQL, and provide specific code examples. 1. Use the COUNT function for counting. The COUNT function is the most commonly used
