

Why doesn't Alibaba use ZooKeeper for service discovery?
Standing at the intersection of the future, it is often interesting to look back at the lost path of history, because we will inadvertently have crazy ideas, such as if something happened in advance, but another thing did not happen. What will happen? Just like what would have happened if Archduke Ferdinand and his wife, heirs to the throne of the Austro-Hungarian Empire, had not been shot dead by the passionate Serbian youth Princip, and what would have happened if Qiu Laodao had not passed through Niujia Village?
At the end of 2007, Taobao launched an internal reconstruction project called "Colorful Stone". This project later It became Taobao's servitization, self-research for distribution, and the beginning of the Internet middleware system. The Taobao service registration center ConfigServer was born in the same year.
Around 2008, Yahoo, the former Internet giant, began to gradually publicize its big data distributed coordination product ZooKeeper in public. This product made reference to the papers published by Google on Chubby and Paxos.
In November 2010, ZooKeeper developed from a sub-project of Apache Hadoop to a top-level project of Apache, officially announcing that ZooKeeper has become an industrial-grade mature and stable product.
In 2011, Alibaba open sourced Dubbo. In order to make it better open source, it needed to separate its relationship with Alibaba’s internal systems. Dubbo supported the open source ZooKeeper as its registration center. Later, in China, it was implemented through the efforts of everyone in the industry. Under the circumstances, Dubbo ZooKeeper's typical service-oriented solution has made ZooKeeper famous as a registration center.
Double 11 in 2015, nearly 8 years have passed since the ConfigServer service was launched. Alibaba’s internal “service scale” exceeded several million, as well as the promotion of the “thousands of miles away” IDC disaster recovery technology strategy, etc., which jointly promoted Alibaba has started an internal architecture upgrade from ConfigServer 2.0 to ConfigServer 3.0.
Time is moving towards 2018. Standing at the intersection of 10 years, how many people are willing to slow down a little and take a closer look at the field of service discovery when chasing the ever-changing new technology concepts. How many people have thought about or I have thought about a question:
Service discovery, is ZooKeeper really the best choice?
Looking back at history, we also occasionally have myths. In the context of service discovery, what would have happened if ZooKeeper was born earlier than our HSF registration center ConfigServer?
Will we take the detour of first using ZooKeeper and then frantically transforming and patching ZooKeeper to adapt to Alibaba's service-oriented scenarios and needs?
However, standing on the shoulders of today and our predecessors, we have never realized as firmly as we do today that In the field of service discovery, ZooKeeper is simply not the best choice , just like Eureka who has been with us all these years and this article Eureka! Why You Shouldn't Use ZooKeeper for Service Discovery firmly explains why you should not use ZooKeeper for service discovery!
My way is not alone.
Registration Center Requirements Analysis and Key Design Considerations
Next, let us return to the demand analysis for service discovery, combined with Alibaba’s practice in key scenarios, to analyze one by one and discuss together. Why ZooKeeper is not the most suitable registration center solution.
Is the registration center a CP or AP system?
I believe readers are familiar with the CAP and BASE theories, and they have become one of the key principles guiding the construction of distributed systems and Internet applications. Here Without going into details about the theory, we go directly to the analysis of the data consistency and availability requirements of the registration center:
Data consistency requirement analysis
The most essential function of the registration center can be regarded as a Query function Si = F(service-name), with service-name as the query parameter,service-name The available endpoints (ip:port) of the corresponding service is the return value.
Note: Service will be abbreviated as svc in the following text.
Let’s take a look at the key data first endpoints (ip:port) The impact of inconsistency, that is, the consequences of not satisfying C in CAP:
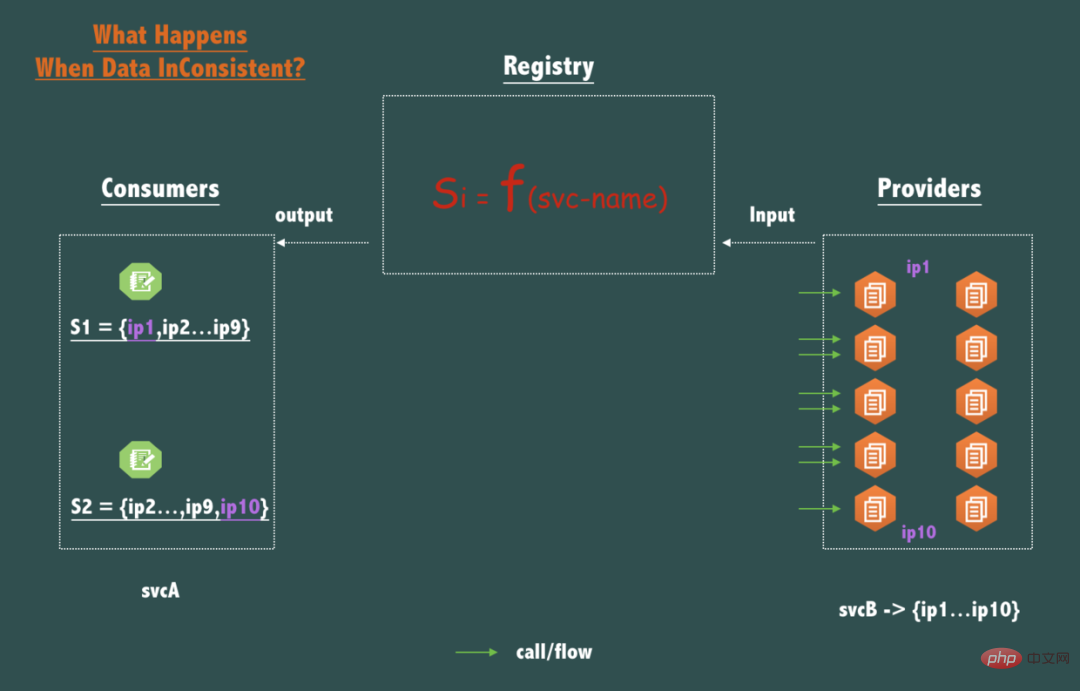
As shown in the figure above, if a svcB deploys 10 nodes (replica/Replica), if for the same service name svcB, the caller svcA’s 2 nodes’ 2 queries return inconsistent data, for example: S1 = {ip1,ip2,ip3...,ip9}, S2 = {ip2,ip3,....ip10}, then what is the impact of this inconsistency?
I believe you must have noticed that the traffic of each node of svcB will be a little unbalanced.
Compared with the other 8 nodes {ip2...ip9}, the request traffic of ip1 and ip10 is a little smaller, but it is obvious that in a distributed system, even for peer-to-peer deployed services, because the request arrives Time, hardware status, operating system scheduling, virtual machine GC, etc., at any point in time, the status of these peer-to-peer deployed nodes cannot be completely consistent, and in the case of inconsistent traffic, as long as the registration center is within the time promised by the SLA If the data converges to a consistent state (that is, satisfies eventual consistency) within 1 second (for example, within 1 second), the traffic will soon tend to be consistent in a statistical sense. Therefore, the registration center is designed with an eventually consistent model, which is completely acceptable in production practice.
Partition Tolerance and Availability Requirements Analysis
Next let’s take a look at registration in the case of Network Partition The impact of the unavailability of the center on service calls is the impact when A in the CAP is not satisfied.
Consider a typical ZooKeeper three-machine room disaster recovery 5-node deployment structure (i.e. 2-2-1 structure), as shown below:
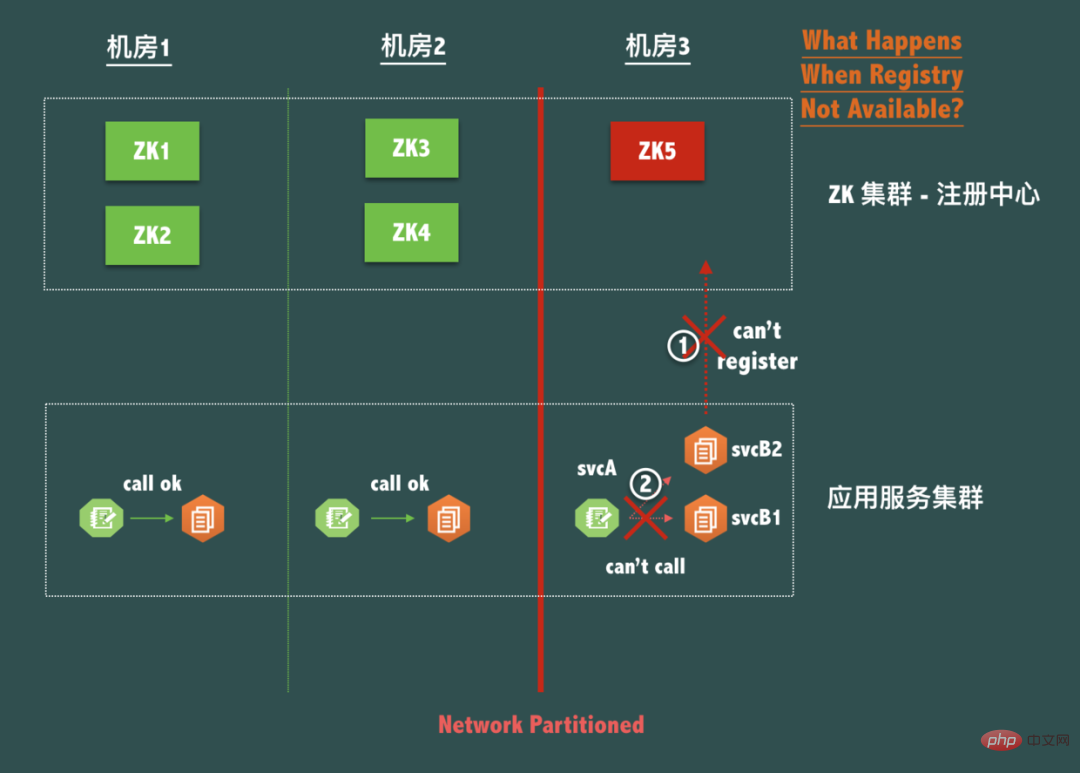
Now because the registration center itself has given up availability in order to ensure data consistency (C) under split-brain (P), services in the same computer room cannot be called. This is absolutely not allowed! It can be said that in practice, the registration center cannot destroy the connectivity between services for any reason of its own. This is an iron law that the registration center design should follow! We will continue to discuss the disaster recovery of the registration center client later.
At the same time, let’s consider the data inconsistency in this case. If computer rooms 1, 2, and 3 become isolated islands, then if the svcA of each computer room only gets the svcB of this computer room The IP list, that is, the IP list data of svcB in each computer room is completely inconsistent. What is the impact?
In fact, it doesn’t have a big impact, but in this case, all calls are made by the same computer room. When we design the registration center, sometimes we even take the initiative to take advantage of the inconsistency of the data in this registration center. To help applications actively call the same computer room, thereby optimizing the effect of service call link RT!
Through our above explanation, we can see that in the CAP trade-off, the availability of the registration center is more valuable than the strong consistency of the data, so the overall design should be more biased towards AP rather than CP, and data inconsistency is acceptable scope, and discarding A under P completely violates the principle that the registration center cannot destroy the connectivity of the service itself for any reason of its own.
Service scale, capacity, service connectivity
What is the scale of your company’s “microservices”? Hundreds of microservices? Deployed hundreds of nodes? What about 3 years later? The Internet is a place where miracles happen. Maybe your "service" becomes a household name overnight, your traffic doubles, and your scale doubles!
When the data center service scale exceeds a certain number (service scale = F{service pub number, service sub number}), ZooKeeper as the registration center will soon be overwhelmed like the donkey in the picture below

In fact, when ZooKeeper is used in the right place, that is, in coarse-grained distributed locks and distributed coordination scenarios, the TPS and number of connections that ZooKeeper can support are sufficient. Because these scenarios do not have strong demands on ZooKeeper's scalability and capacity.
But in service discovery and health monitoring scenarios, as the service scale increases, whether it is write requests caused by service registration when applications are frequently released, or millisecond-level service health status refreshes Write requests, or wish that all the machines or containers in the entire data center have long connections to the registration center. ZooKeeper will soon be unable to cope with the connection pressure brought by long connections. However, ZooKeeper's writing is not scalable and cannot be solved by adding nodes. Horizontal scalability issues.
If you want to solve the problem of service scale growth based on ZooKeeper, a practical method that can be considered is to find ways to sort out the business, vertically divide the business domain, and divide it into multiple ZooKeeper registration centers. However, as a platform organization group that provides general services, is it really feasible to divide and manage business according to the technical baton due to insufficient service capabilities?
And this violates the fact that the registration center itself (insufficient capacity) destroys the connectivity of the service. To give a simple example, 1 search business, 1 map business, 1 large entertainment business, 1 In the game business, should their services be mutually exclusive? Maybe today is yes, but what about tomorrow, what about one year from now, what about ten years from now? Who knows that in the future, several business domains will be opened up to create weird business innovations? As a basic service, the registration center cannot predict the future and certainly cannot hinder the business service's demand for future inherent connectivity.
Does the registration center need persistent storage and transaction logs?
Needed and not needed.
We know that ZooKeeper's ZAB protocol will keep writing a transaction log on each ZooKeeper node for each write request, and at the same time, it will regularly mirror the memory data (Snapshot) to the disk to ensure the data security. Consistency and durability, as well as data recovery after a crash, are very good features, but we have to ask, in a service discovery scenario, the core data - a real-time address list of healthy services is really needed Is the data persistent?
For this data, the answer is no.
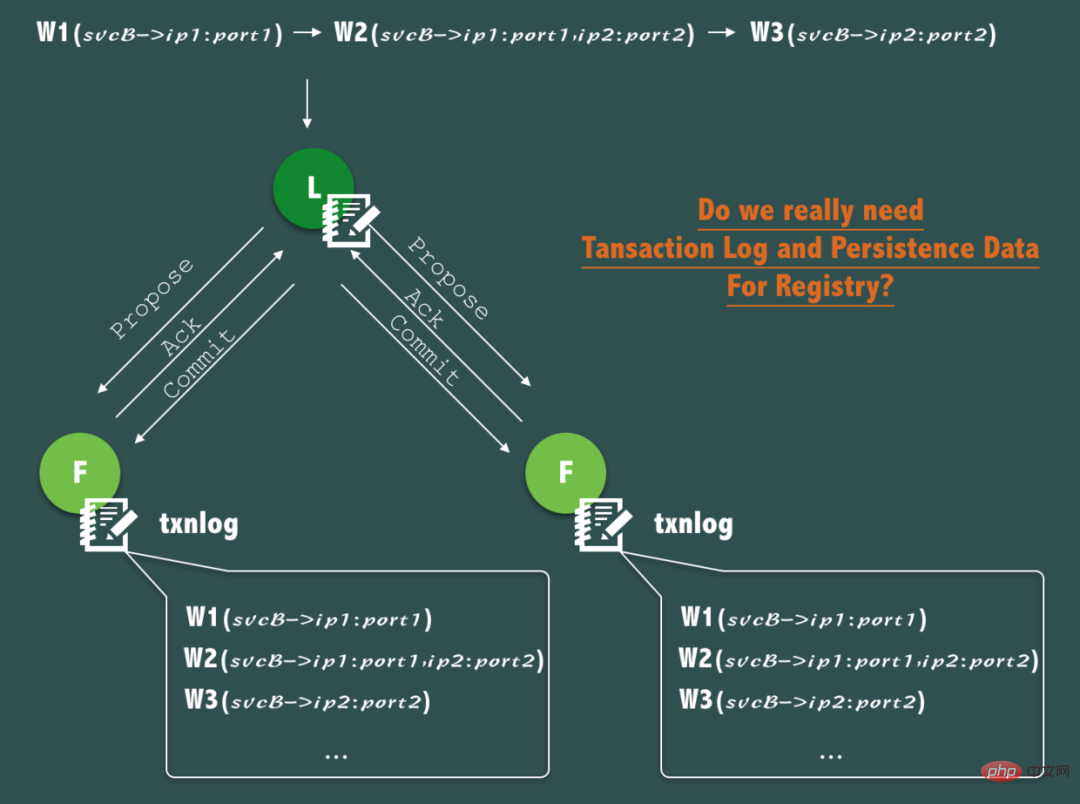
As shown in the figure above, if svcB has experienced registration service (ip1), expansion to 2 nodes (ip1, ip2), and shrinkage due to downtime (ip1 downtime) ), during this process, three write operations to ZooKeeper occurred.
However, careful analysis shows that through transaction logs, persistent and continuous recording of this change process is actually of little significance, because in service discovery, the service call initiator is more concerned about the real-time address list of the service it wants to call. and real-time health status. Each time a call is made, it does not care about the historical service address list and past health status of the service to be called.
But why is it necessary? Because a complete production-available registration center, in addition to the real-time address list and real-time health status of the service, will also store some metadata information of the service, such as the service's Meta-information such as version, group, data center, weight, authentication policy information, service label, etc. These data need to be stored persistently, and the registration center should provide the ability to retrieve these meta-information.
Service Health Check
When using ZooKeeper as the service registration center, the health check of the service often uses ZooKeeper's Session active Track mechanism and the mechanism combined with Ephemeral ZNode. Simply put, it is to combine the service's Health monitoring is bound to ZooKeeper's health monitoring of Session, or to TCP long link activity detection.
This can also cause fatal problems in many cases. When the TCP long link activity detection between ZK and the service provider machine is normal, is the service healthy? The answer is of course no! The registration center should provide a richer health monitoring solution, and the logic of whether the service is healthy or not should be open to the service provider to define, rather than making it a one-size-fits-all TCP activity test!
One of the basic design principles of health detection is to feedback the true health status of the service itself as truly as possible. Otherwise, a health status determination result that is not believed by service callers is worse than no health detection.
Disaster recovery considerations of the registration center
As mentioned earlier, In practice, the registration center cannot destroy the connectivity between services for any reason of its own, So in terms of availability, there is an essential question. If the registration center (Registry) itself is completely down, should the link of svcA calling svcB be affected?
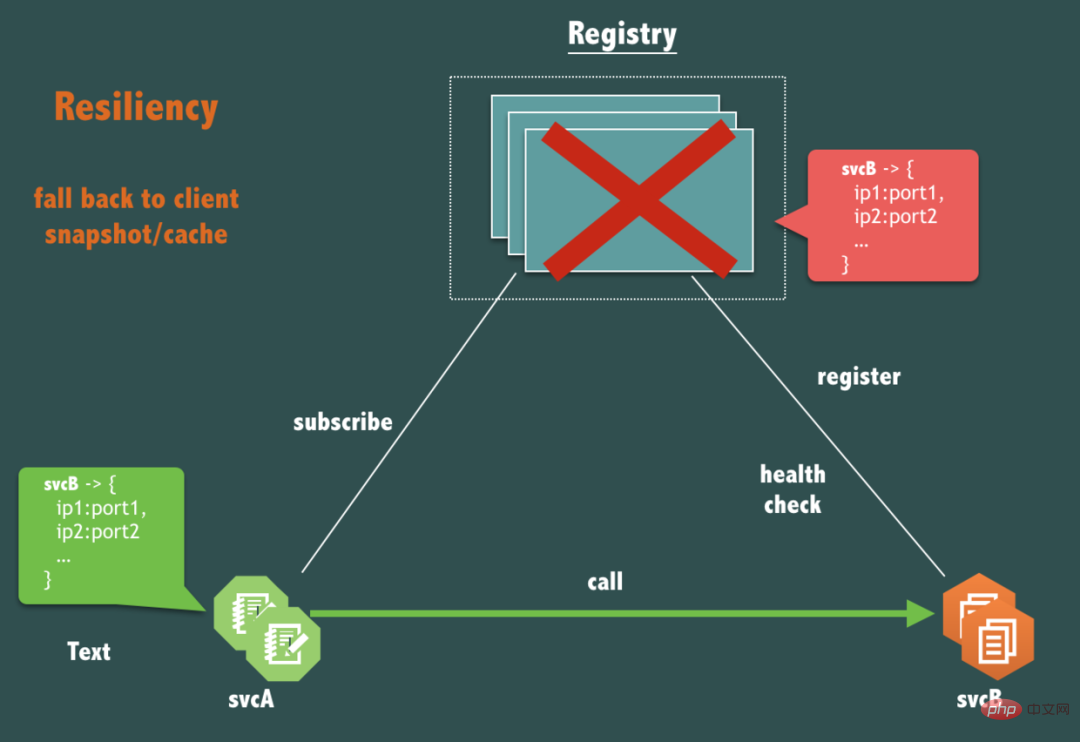
Yes, it should not be affected.
The service call (request response flow) link should be weakly dependent on the registration center. It must only rely on the registration center when necessary for service release, machine online and offline, service expansion and contraction, etc.
This requires the registration center to carefully design the client it provides. The client should have disaster recovery means for when the registration center service is completely unavailable, such as designing a client caching data mechanism (we call it client snapshot) is an effective method. In addition, the health check mechanism of the registration center must be carefully designed so that situations such as emptying will not occur in this situation.
ZooKeeper’s native client does not have this capability, so when using ZooKeeper to implement the registration center, we must ask ourselves, if all ZooKeeper nodes are killed, will all service call links in your production be able to Are you affected in any way? And failure drills should be done regularly on this point.
Do you have a ZooKeeper expert to rely on?
ZooKeeper seems to be a very simple product, but it is not a matter of course to use it on a large scale in production and to use it well. If you decide to introduce ZooKeeper in production, you'd better be prepared to seek help from ZooKeeper technical experts at any time. The most typical manifestations are in two aspects:
The Client/Session state machine that is difficult to master
ZooKeeper’s native client is definitely not easy to use. Curator will be better, but in fact it is not good enough. You must fully understand it. The interaction protocol between ZooKeeper Client and Server is not simple, and fully understanding and mastering the state machine of ZooKeeper Client/Session (picture below) is not that simple and clear:
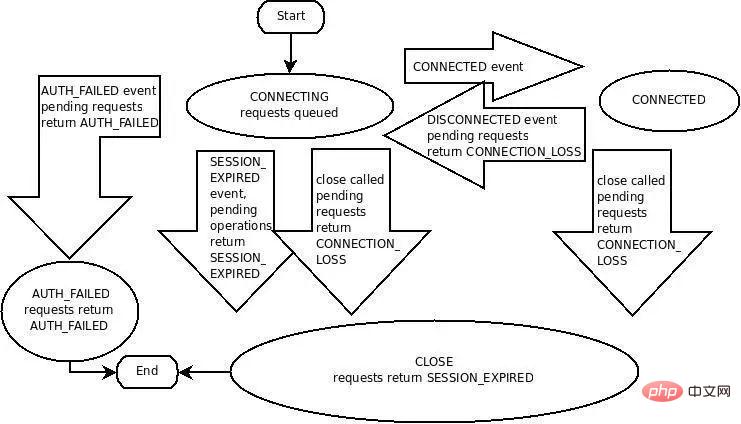
But the service discovery solution based on ZooKeeper relies on the long connection/Session management, Ephemeral ZNode, Event&Notification, and ping mechanisms provided by ZooKeeper. Therefore, to make good use of ZooKeeper for service discovery, you must understand these core mechanisms of ZooKeeper. This is Sometimes it makes you irritable. I just want a service discovery. Why do I need to know so much? And if you understand all of this and don't step into any pitfalls, congratulations, you have become a ZooKeeper technical expert.
Unbearable Exception Handling
When we connect ZooKeeper to Alibaba's internal applications, there is a "Must Know What You Must Know When Connecting ZooKeeper Applications" WIKI, which has the following discussion on exception handling:
If you want to select what application developers need to know most clearly when using ZooKeeper? So based on our previous support experience, it must be exception handling.
When everything (host, disk, network, etc.) is fortunately working properly, the application and ZooKeeper may also run well, but unfortunately, we will face all day long All kinds of accidents, and this follows Murphy's law, unexpected bad things always happen when you are most worried.
So be sure to carefully understand the exceptions and errors that may occur in ZooKeeper in some scenarios, make sure you understand these exceptions and errors correctly, and know how your application handles these situations correctly.
ConnectionLossException and Disconnected event
Simply put, this is an exception that can be recovered in the same ZooKeeper Session (Recoverable), but application development The operator is responsible for restoring the application to its correct state.
There are many reasons for this exception, such as the network interruption between the application machine and the ZooKeeper node, the ZooKeeper node down, the server Full GC time is too long, or even your application process hangs and the application process becomes Full It is possible to recover after the GC time is too long.
To understand this exception, you need to understand a typical problem in distributed applications, as shown below: 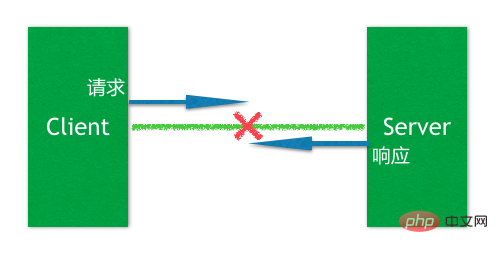
In a typical client request and server response, when they When the long connection between them is interrupted, the client will be in a rather embarrassing situation when it senses the interruption event, that is, it cannot determine the state of the nearby request when the event occurs. The server side Have you received this request? Has it been processed? Because this cannot be determined, when the client reconnects to the server, there is a question mark as to whether the request should be retried (Retry).
So when handling connection disconnection events, application developers must know what the request near the interruption is (this is often difficult to judge), whether the request is idempotent, and for business requests on the server side In service processing, there must be choices and expectations for the semantics of "process only once", "process at most once" and "process at least once".
For example, if the application receives a ConnectionLossException and the previous request was a Create operation, then if the application catches this exception, a possible recovery logic for the application is to determine whether the node created by the previous request has been It exists. If it exists, don't create it again. Otherwise, create it.
For another example, if the application uses exists Watch to monitor the creation event of a non-existent node, then during the ConnectionLossException, it is possible to encounter the situation that during this interruption period, other client processes may The node has been created and deleted, so for the current application, the creation event of the node of concern has been missed. What is the impact of this miss on the application? Is it tolerable or unacceptable? Application developers need to evaluate and process it according to business semantics.
SessionExpiredException and SessionExpired event
Session timeout is an unrecoverable exception. This means that when the application catches this exception, the application cannot To restore the application state in the same Session, a new Session must be re-established. The temporary nodes associated with the old Session may also have expired, and the locks owned may have expired. ...
In the process of trying to use ZooKeeper for service discovery, Alibaba’s friends once summarized an experience sharing on our intranet technology forum

Pertinently mentioned in the article:
... In coding During the process, many possible pitfalls were discovered. At a rough estimate, more than 80% of people who use zk for cluster management for the first time will fall into pitfalls. Some pitfalls are more hidden and will only appear in network problems or abnormal scenarios. It may take a long time to be exposed...
Go left, go right
Is Alibaba not using ZooKeeper at all? Not really.
Anyone who is familiar with Alibaba’s technical system knows that Alibaba actually maintains the largest ZooKeeper cluster in China, with an overall scale of nearly a thousand ZooKeeper service nodes.
At the same time, Alibaba middleware also maintains a code branch of ZooKeeper, TaoKeeper, that is oriented to large-scale production, is highly available, and is easier to monitor and operate. If we take our experience in various business lines and production in the past 10 years, Using the practice of ZooKeeper, if you use a phrase to evaluate ZooKeeper, then we think ZooKeeper should be "The King Of Coordination for Big Data"!
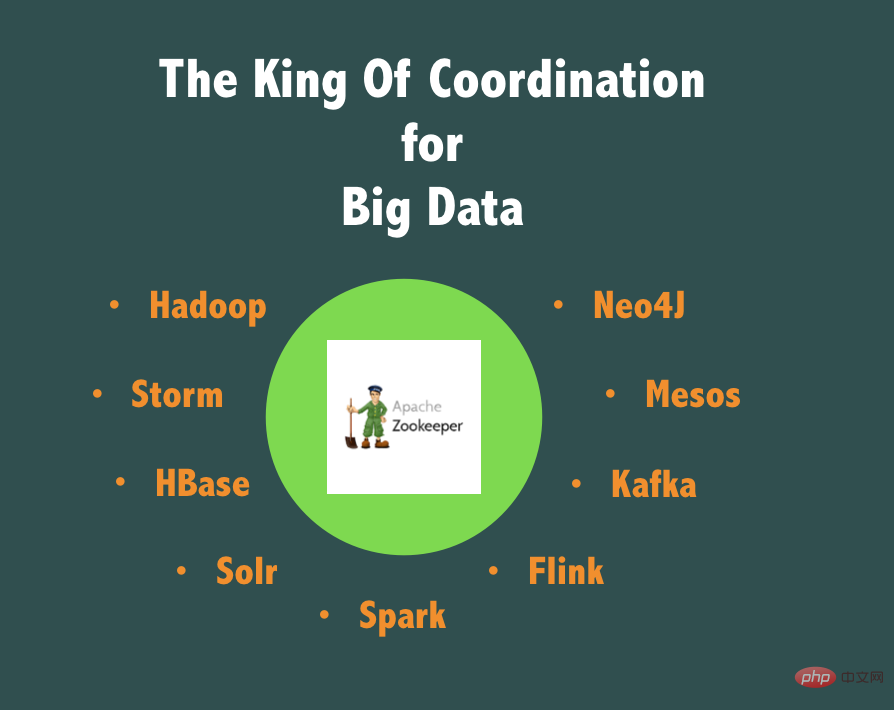
It plays an irreplaceable role in scenarios such as coarse-grained distributed locks, distributed master selection, master-slave high-availability switching, etc. that do not require high TPS support, and these requirements are often concentrated. In related business fields such as big data and offline tasks, because in the field of big data, it is important to segment data sets, and most of the time these data sets are processed in parallel by multiple processes/threads, but there are always some points where it is necessary to combine these tasks with Processes are unified and coordinated. This is where ZooKeeper plays a huge role.
However, in the transaction link of the transaction scenario, there are natural shortcomings in main business data access, large-scale service discovery, large-scale health monitoring, etc. We should try our best to avoid introducing ZooKeeper in these scenarios. In Alibaba's production practice, applications must conduct strict assessments of scenarios, capacity, and SLA requirements when applying to use ZooKeeper.
So you can use ZooKeeper, but please go left for big data, right for transactions, left for distributed coordination, and right for service discovery.
Conclusion
Thank you for your patience in reading this far. At this point, I believe you have understood that we are not writing this article to completely deny ZooKeeper, but only based on our Alibaba’s experience in the past 10 years. In the production practice of large-scale servitization, we will summarize our experience and lessons in the design and use of service discovery and registration centers. We hope to provide some insights to the industry on how to better use ZooKeeper and how to better design their own service registration centers. Inspiring and helpful. Finally, all roads lead to Rome, and I sincerely hope that your registration center will be born directly in Rome.
The above is the detailed content of Why doesn't Alibaba use ZooKeeper for service discovery?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Using ZooKeeper for distributed lock processing in Java API development
Jun 17, 2023 pm 10:36 PM
Using ZooKeeper for distributed lock processing in Java API development
Jun 17, 2023 pm 10:36 PM
As modern applications continue to evolve and the need for high availability and concurrency grows, distributed system architectures are becoming more common. In a distributed system, multiple processes or nodes run at the same time and complete tasks together, and synchronization between processes becomes particularly important. Since many nodes in a distributed environment can access shared resources at the same time, how to deal with concurrency and synchronization issues has become an important task in a distributed system. In this regard, ZooKeeper has become a very popular solution. ZooKee
 Using ZooKeeper and Curator for distributed coordination and management in Beego
Jun 22, 2023 pm 09:27 PM
Using ZooKeeper and Curator for distributed coordination and management in Beego
Jun 22, 2023 pm 09:27 PM
With the rapid development of the Internet, distributed systems have become one of the infrastructures in many enterprises and organizations. For a distributed system to function properly, it needs to be coordinated and managed. In this regard, ZooKeeper and Curator are two tools worth using. ZooKeeper is a very popular distributed coordination service that can help us coordinate the status and data between nodes in a cluster. Curator is an encapsulation of ZooKeeper
 Should I use Redis or Zookeeper for distributed locks?
Aug 22, 2023 pm 03:48 PM
Should I use Redis or Zookeeper for distributed locks?
Aug 22, 2023 pm 03:48 PM
The implementation methods of distributed locks usually include: database, cache (such as Redis), Zookeeper, etcd. In actual development, Redis and Zookeeper are most commonly used, so this article will only talk about these two.
 How to use PHP's Zookeeper extension?
Jun 02, 2023 pm 09:01 PM
How to use PHP's Zookeeper extension?
Jun 02, 2023 pm 09:01 PM
PHP is a very popular programming language that is widely used in web applications and server-side development. Zookeeper is a distributed coordination service used to manage, coordinate and monitor distributed applications and services. Using Zookeeper in PHP applications can improve the performance and reliability of your application. This article will introduce how to use the Zookeeper extension for PHP. 1. Install the Zookeeper extension. To use the Zookeeper extension, you need to install Zookeeper.
 Using ZooKeeper to implement service registration and discovery in Beego
Jun 22, 2023 am 08:21 AM
Using ZooKeeper to implement service registration and discovery in Beego
Jun 22, 2023 am 08:21 AM
In the microservice architecture, service registration and discovery is a very important issue. To solve this problem, we can use ZooKeeper as a service registration center. In this article, we will introduce how to use ZooKeeper in the Beego framework to implement service registration and discovery. 1. Introduction to ZooKeeper ZooKeeper is a distributed, open source distributed coordination service. It is one of the sub-projects of Apache Hadoop. The main role of ZooKeeper
![[Recommended collection] Soul torture! Zookeeper's 31-shot cannon](https://img.php.cn/upload/article/202308/28/2023082816453271532.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) [Recommended collection] Soul torture! Zookeeper's 31-shot cannon
Aug 28, 2023 pm 04:45 PM
[Recommended collection] Soul torture! Zookeeper's 31-shot cannon
Aug 28, 2023 pm 04:45 PM
ZooKeeper is an open source distributed coordination service. It is a software that provides consistency services for distributed applications. Distributed applications can implement tasks such as data publishing/subscription, load balancing, naming service, distributed coordination/notification, cluster management, Master election, distributed locks and Distributed queues and other functions.
 ZooKeeper comparison of Redis implementation of distributed locks
Jun 20, 2023 pm 03:19 PM
ZooKeeper comparison of Redis implementation of distributed locks
Jun 20, 2023 pm 03:19 PM
With the rapid development of Internet technology, distributed systems have been widely used in modern applications, especially in large Internet companies. However, in a distributed system, it is very difficult to maintain consistency between nodes, so the distributed lock mechanism has become one of the foundations to solve this problem. In the implementation of distributed locks, Redis and ZooKeeper are both popular tools. This article will compare and analyze them. Redis implements distributed locks Redis is an open source memory data storage
 How to integrate Dubbo zookeeper in SpringBoot
May 17, 2023 pm 02:16 PM
How to integrate Dubbo zookeeper in SpringBoot
May 17, 2023 pm 02:16 PM
dockerpullzookeeperdockerrun --namezk01-p2181:2181--restartalways-d2e30cac00aca indicates that zookeeper has successfully started Zookeeper and Dubbo • ZooKeeperZooKeeper is a distributed, open source distributed application coordination service. It is a software that provides consistent services for distributed applications. The functions provided include: configuration maintenance, domain name services, distributed synchronization, group services, etc. DubboDubbo is Alibaba's open source distributed service framework. Its biggest feature is that it is structured in a layered manner.
