

redis study notes-list principle
list Basic functions
Chart from: https://www.cnblogs.com/amyzhu/p/13466311.html
Singly linked list
Before learning the list implementation of redis, let’s first take a look at how to implement a singly linked list:
Each one The nodes have a backward pointer (reference) pointing to the next node, the last node points to NULL to indicate the end, and there is a Head (head) pointer pointing to the first node to indicate the start.
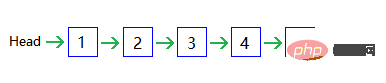
##Similar to this, although new creation and deletion only require O(1) , but the search requires O(n) time; the reverse search is not possible, and you need to start from the beginning if you miss it.
Add a node:
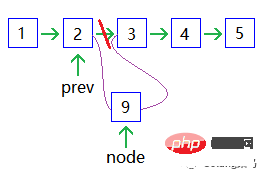
Delete a node:
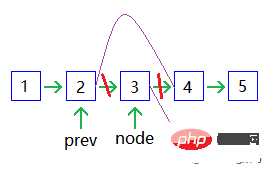
##Doubly linked list
Doubly linked list, also called doubly linked list, is a type of linked list. Each data node has two pointers, pointing to the direct successor and direct predecessor respectively. Therefore, starting from any node in the doubly linked list, you can easily access its predecessor nodes and successor nodes.

Features:
Every time you insert or delete When selecting a certain node, four node references need to be processed instead of two. It is more difficult to implement
Compared with a one-way linked list, it will inevitably occupy memory The space is larger.
You can traverse from the beginning to the end, and you can traverse from the end to the beginning
This seems to solve the problem of redis being able to traverse both before and after.
Then let’s take a look at how redis’s linked list is processed:
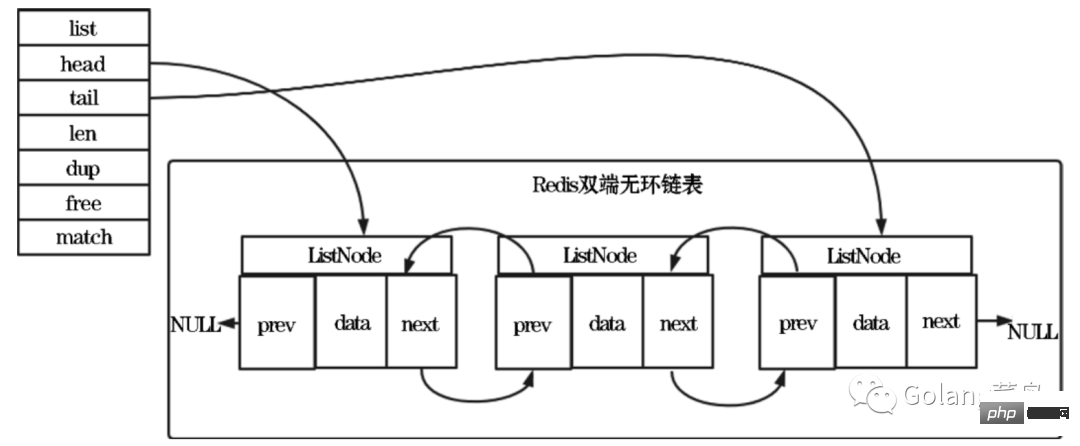
Let’s take a look at its structure definition source code
ListNode:
1 2 3 4 5 6 7 8 9 |
|
List:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
Characteristics of redis linked list:
Bidirectional acyclic: linked list nodes have predecessor and successor pointers to obtain a node's The time complexity of the predecessor and successor nodes is O(1). The predecessor pointer of the head node and the successor pointer of the tail node both point to NULL, and access to the linked list ends with NULL.
Length counter: The time complexity of obtaining the number of nodes through the len attribute of the List structure is O(1).
Since list still has a problem of discontinuous memory allocation and memory fragmentation, is there a way to optimize their memory?
redis Compressed List
ZipList is not a basic data structure, but a data storage structure designed by Redis itself. It is somewhat similar to an array, storing data through a continuous memory space.
Different from an array, it allows the stored list elements to occupy different memory spaces. When it comes to the word compression, the first thing that everyone may think of is saving memory. The reason why this storage structure saves memory is that it is compared to arrays.
We all know that arrays require the storage space of each element to be the same size. If we want to store strings of different lengths, we must use the storage space occupied by the string with the maximum length. As the size of the storage space for each element of the string array (if it is 50 bytes).
Therefore, part of the storage space will be wasted when storing a string less than 50 bytes in character value.
The advantage of array is that it occupies a continuous space and can make good use of the CPU cache to quickly access data.
If you want to retain this advantage of the array and save storage space, then we can compress the array:
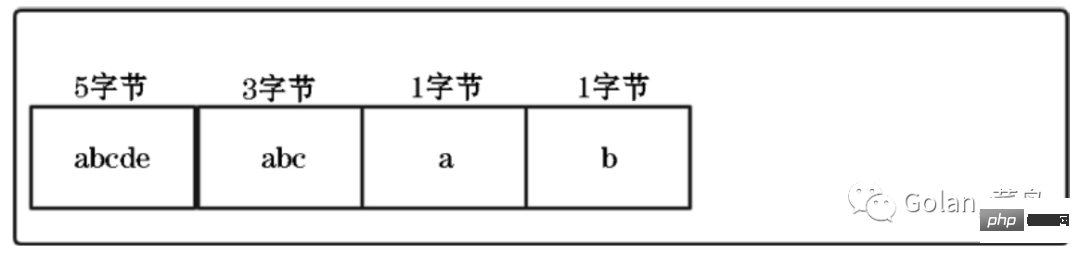
However, there is a problem. When traversing the compressed list, we do not know the memory size occupied by each element, so we cannot calculate the specific starting position of the next element.
But then I thought about it, if we could have the length of each element before accessing it, wouldn't this problem be solved?

Next let’s look at how Redis combines them by implementing ZipList to retain the advantages of arrays and save memory.
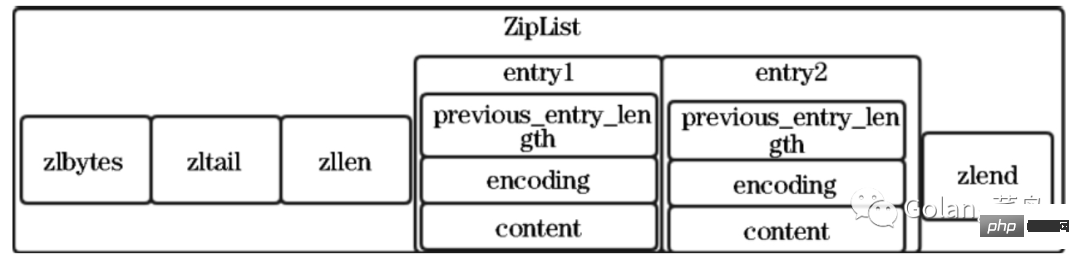
zlbytes:压缩列表的字节长度,是uint32_t类型,占4字节,因此压缩列表最多有232-1字节,可以通过该值计算zlend的位置,也可以在内存重新分配的时候使用。
zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量,是uint32_t类型,占4字节,可以通过该值快速定位到列表尾元素的位置。
zllen:压缩列表元素的个数,是uint16_t类型,占2字节,表示最多存储的元素个数为216-1=65 535,如果需要计算总数量,则需要遍历整个压缩列表。
entryx:压缩列表存储的元素,既可以是字节数组,也可以是整数,长度不限。
zlend:压缩列表的结尾,是uint8_t类型,占1字节,恒为0xFF。
previous_entry_length:表示前一个元素的字节长度,占1字节或者5字节,当前元素的长度小于254时用1字节,大于等于254时用5字节,previous_entry_length 字段的第一个字节固定是0xFE,后面的4字节才是真正的前一个元素的长度。
encoding:表示元素当前的编码,有整数或者字节数。为了节省内存,encoding字段长度可变。
content:表示当前元素的内容。
ZipList变量的读取和赋值都是通过宏来实现的,代码片段如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
对此,可以通过定义的结构体和对应的操作定义知道大概 redis 设计 压缩list 的思路;
这种方式虽然节约了空间,但是会存在每次插入和创建存在内存重新分配的问题。
quicklist
quicklist是Redis 3.2中新引入的数据结构,能够在时间效率和空间效率间实现较好的折中。Redis中对quciklist的注释为A doubly linked list of ziplists。顾名思义,quicklist是一个双向链表,链表中的每个节点是一个ziplist结构。quicklist可以看成是用双向链表将若干小型的ziplist连接到一起组成的一种数据结构。
当ziplist节点个数过多,quicklist退化为双向链表,一个极端的情况就是每个ziplist节点只包含一个entry,即只有一个元素。当ziplist元素个数过少时,quicklist可退化为ziplist,一种极端的情况就是quicklist中只有一个ziplist节点。
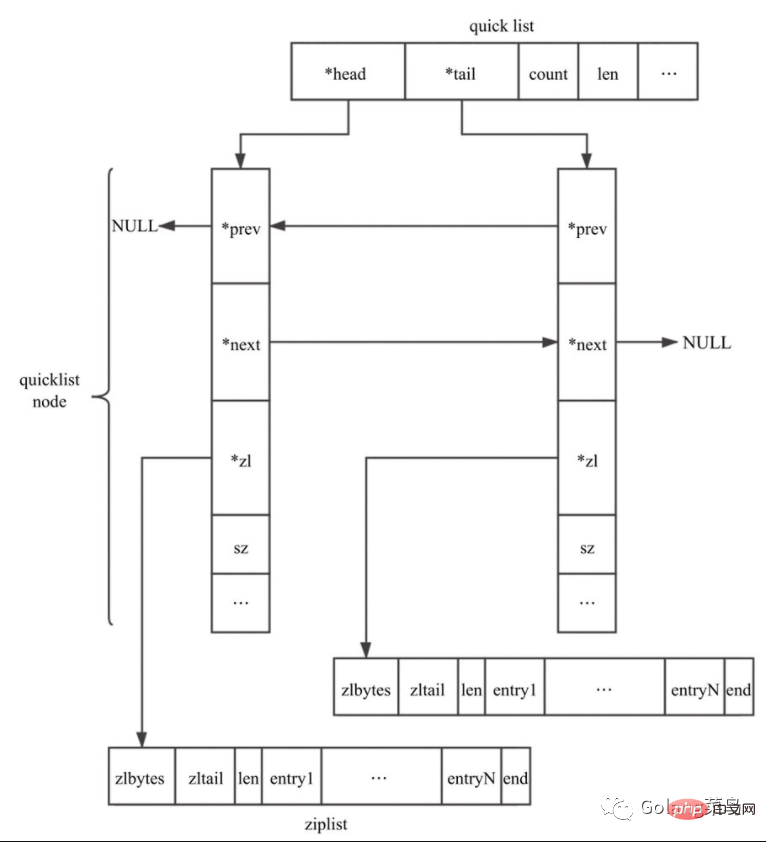
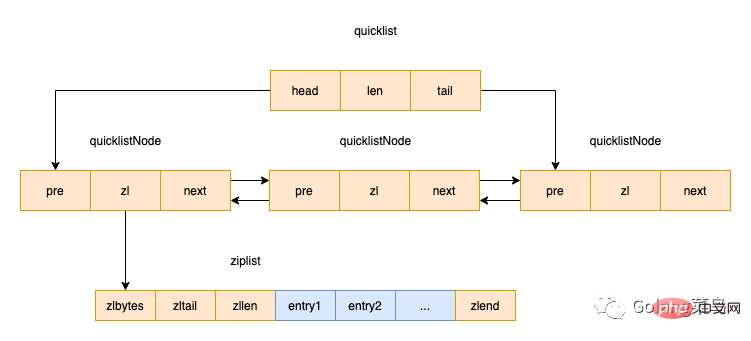
quicklist 结构定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
quicklistNode定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 |
|
redis为了节省内存空间,会将quicklist的节点用LZF压缩后存储,但这里不是全部压缩,可以配置compress的值,compress为0表示所有节点都不压缩,否则就表示从两端开始有多少个节点不压缩;compress如果是1,表示从两端开始,有1个节点不做LZF压缩。compress默认是0(不压缩),具体可以根据你们业务实际使用场景去配置。
redis 的配置文件可以配置该参数
list-compress-depth 0
| ##Commands | Description |
|---|---|
| #BLPOP key1,key2,... timeout | Remove and get the first element of the list, if the list has no elements it will block The list waits until it times out or the element is popped. |
| ##Move out and Get the | last element of the list. If there is no element in the list, the list will be blocked until the wait times out or a pop-up element is found. |
| BRPOPLPUSH source destination timeout | pop from list A value that inserts the popped element into another list and returns it; if the list has no elements, the list will be blocked until the wait times out or a popupable element is found. |
| LIndex key index | 通过索引获取列表中的元素 |
| Linsert key before/after pivot value | 在列表的元素前或者后插入元素 |
| LLEN key | 获取列表长度 |
| LPOP key | 移出并获取列表的第一个元素 |
| ##LPUSH key value1,value2,… | will One or more values are inserted into the head of the list |
| LPUSHX key value | Insert a value into the head of an existing list |
| ##LRANGE key srart stop | Get the elements within the specified range of the list |
| Set the value of a list element by index | |
| Pruning a list means that only the elements within the specified range are retained in the list, and the elements that are not within the specified range are deleted. The index starts from 0, and the range is inclusive. | |
| RPOP key | remove listThe last element, the return value is the removed element |
| RPOPPUSH source destination | Remove the last element of the list and replace The element is added to another list and returns |
| RPUSH key value1 value2 …… | Add one or more values to the end of the list |
| ##RPUSHX key value | Add a value to an already existing list |
| ##Value | ##Meaning |
|---|---|
| ##Special value means no compression | |
| ##There is 1 on each end of the quicklist The nodes are not compressed, the middle nodes are compressed | 2 |
| There are 2 nodes at both ends of the quicklist that are not compressed, and the nodes in the middle are compressed | n |
| There are n nodes at both ends of the quicklist that are not compressed, and the nodes in the middle are compressed |
There is also a fill field, which means the maximum capacity of each quicknode node , different values have different meanings, the default is -2, of course it can also be configured to other values;
##list-max-ziplist-size -2- When the value is a positive number, it indicates the length of the ziplist on the quicklistNode node. For example, when this value is 5, the ziplist of each quicklistNode node contains at most 5 data items
- When the value is a negative number, Indicates that the length of the ziplist on the quicklistNode node is limited according to the number of bytes. The optional values are -1 to -5.
| Value | Meaning |
|---|---|
| -1 | ziplist node maximum The maximum number of ziplist nodes is 4kb |
| ##-2 | 8kb |
| -3 | ziplist node maximum is 16kb |
| ##-4 | |
| -5 | ##The maximum ziplist node size is 64kb |
Why is there configuration provided?
#The shorter the ziplist, the more memory fragments will occur, affecting storage efficiency. When a ziplist only stores one element, the quicklist degenerates into a doubly linked list.
The longer the ziplist, the more difficult it is to allocate a large continuous memory space for the ziplist. The larger the value, the more small blocks of memory space will be wasted. When the quicklist has only one node and all elements are stored in a ziplist, the quicklist degenerates into a ziplist.
Conclusion
Although we do not fully understand its source code, we can also familiarize ourselves with a design idea of redis through this article. And know how it is optimized step by step. Let's get a general idea of performance.
The above is the detailed content of redis study notes-list principle. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 How to view all keys in redis
Apr 10, 2025 pm 07:15 PM
How to view all keys in redis
Apr 10, 2025 pm 07:15 PM
To view all keys in Redis, there are three ways: use the KEYS command to return all keys that match the specified pattern; use the SCAN command to iterate over the keys and return a set of keys; use the INFO command to get the total number of keys.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to start the server with redis
Apr 10, 2025 pm 08:12 PM
How to start the server with redis
Apr 10, 2025 pm 08:12 PM
The steps to start a Redis server include: Install Redis according to the operating system. Start the Redis service via redis-server (Linux/macOS) or redis-server.exe (Windows). Use the redis-cli ping (Linux/macOS) or redis-cli.exe ping (Windows) command to check the service status. Use a Redis client, such as redis-cli, Python, or Node.js, to access the server.
