
 Backend Development
Python Tutorial
Crawler|Python crawls pictures of girls from station B, motivation to learn!
Backend Development
Python Tutorial
Crawler|Python crawls pictures of girls from station B, motivation to learn!
Crawler|Python crawls pictures of girls from station B, motivation to learn!

##Directly open station B (bilibili) and search for' Miss Sister': ##Search for the first one title, we can find the corresponding XHR request. After careful analysis, we find that all the data exists in a json format data set, and our goal is resultList. ##This is a get request. The number of entries in the request includes page and keywordTwo entries, corresponding to the requested page number and keyword respectively. 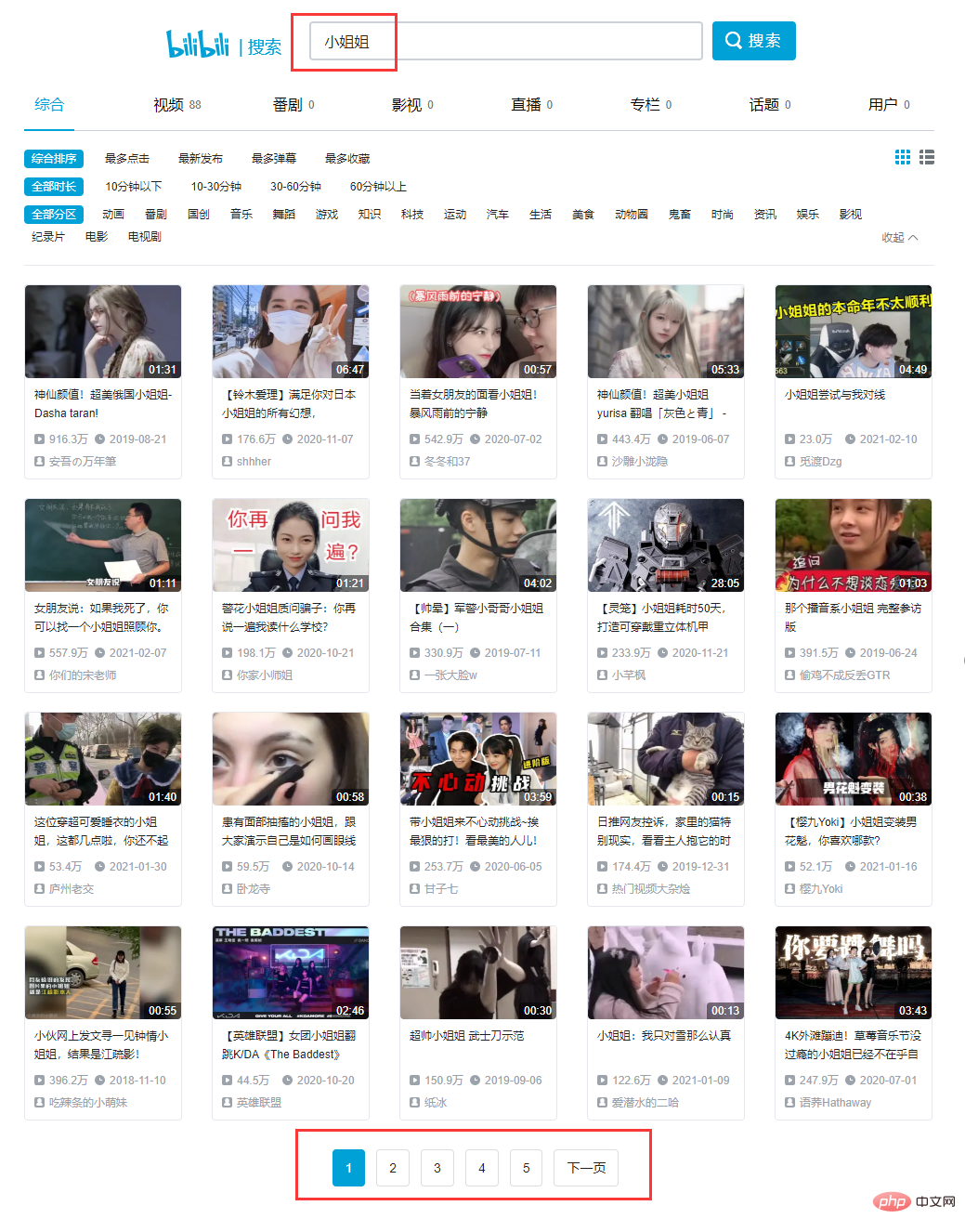
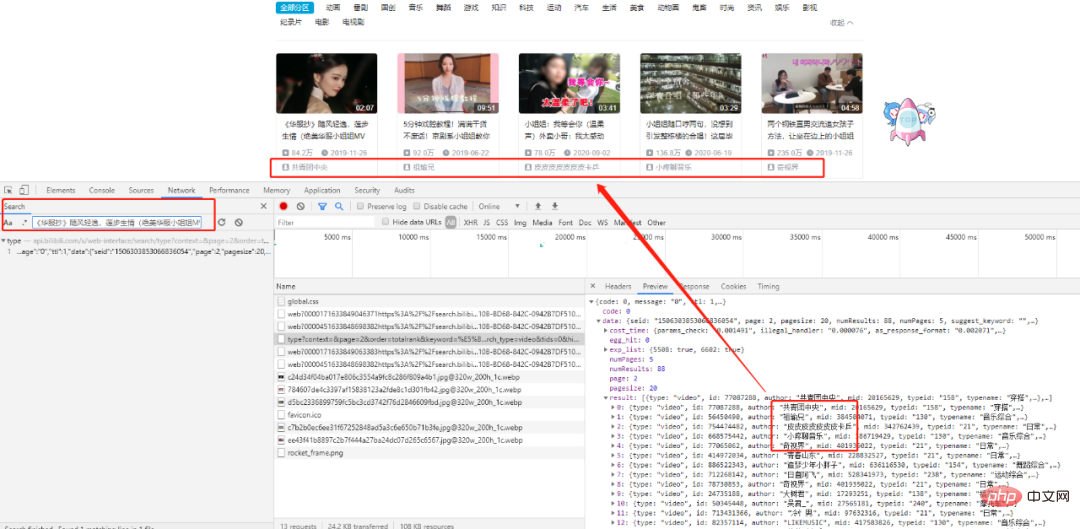
# 第一页
'https://api.bilibili.com/x/web-interface/search/all/v2?context=&page=1&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&tids=0&highlight=1&single_column=0'
# 第二页
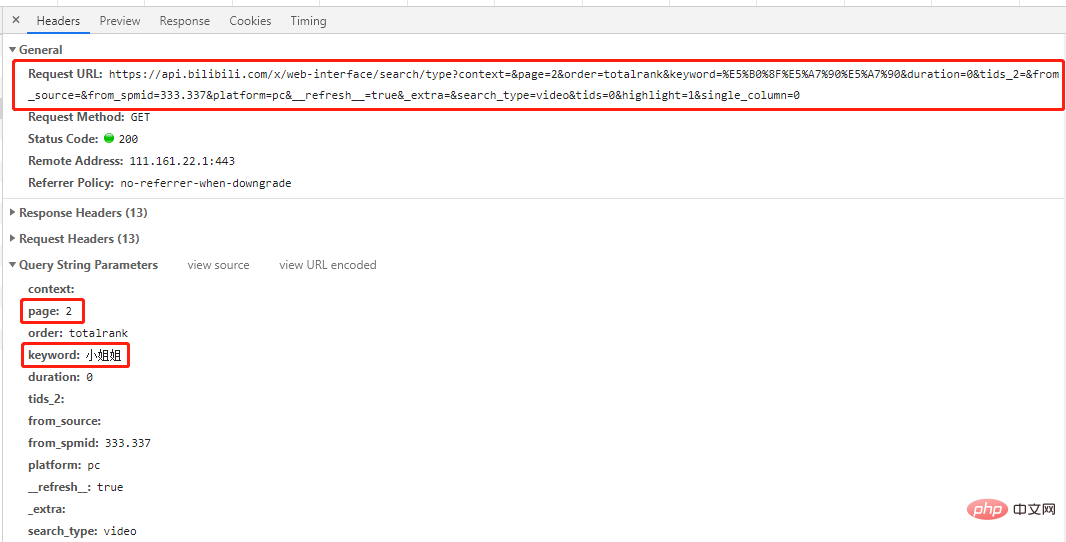
'https://api.bilibili.com/x/web-interface/search/type?context=&page=2&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0'
# 第三页
'https://api.bilibili.com/x/web-interface/search/type?context=&page=3&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0'
You can see that except for the first page, the other page URLsonly have different page parameters, then let’s try it Also use the URLs of other pages to request the first page, and you will find that the desired results can also be obtained (try it yourself).
in conclusion: All page URLs differ only in the page parameter, and the rest are the same.
# 导包 import re import time import json import random import requests from fake_useragent import UserAgent
2.2 获取页面信息
# 获取页面信息
def get_datas(url,headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = chardet.detect(r.content)['encoding']
datas = json.loads(r.text)
return datas# 获取图片链接信息
def get_hrefs(datas):
titles,hrefs = [],[]
for data in datas['data']['result']:
# 标题
title = data['title']
# 时长
duration = data['duration']
# 播放量
video_review =data['video_review']
# 发布时间
date_rls = data['pubdate']
pubdate = time.strftime('%Y-%m-%d %H:%M', time.localtime(date_rls))
# 作者
author = data['author']
# 图片链接
link_pic = data['pic']
href_pic = 'https:' + link_pic
titles.append(title)
hrefs.append(href_pic)
return titles, hrefs代码解析了视频标题,时长,播放量,发布时间,作者,图片链接等参数,这里我们只取标题和图片链接,其他参数可根据需要自行增,删。
# 保存图片
def download_jpg(titles, hrefs):
path = "D:/B站小姐姐/"
if not os.path.exists(path):
os.mkdir(path)
for i in range(len(hrefs)):
title_t = titles[i].replace('/','').replace(',','').replace('?','')
title_t = title_t.replace(' ','').replace('|','').replace('。','')
filename = '{}{}.jpg'.format(path,title_t)
with open(filename, 'wb') as f:
req = requests.get(url=hrefs[i], headers=headers)
f.write(req.content)
time.sleep(random.uniform(1.5,3.4))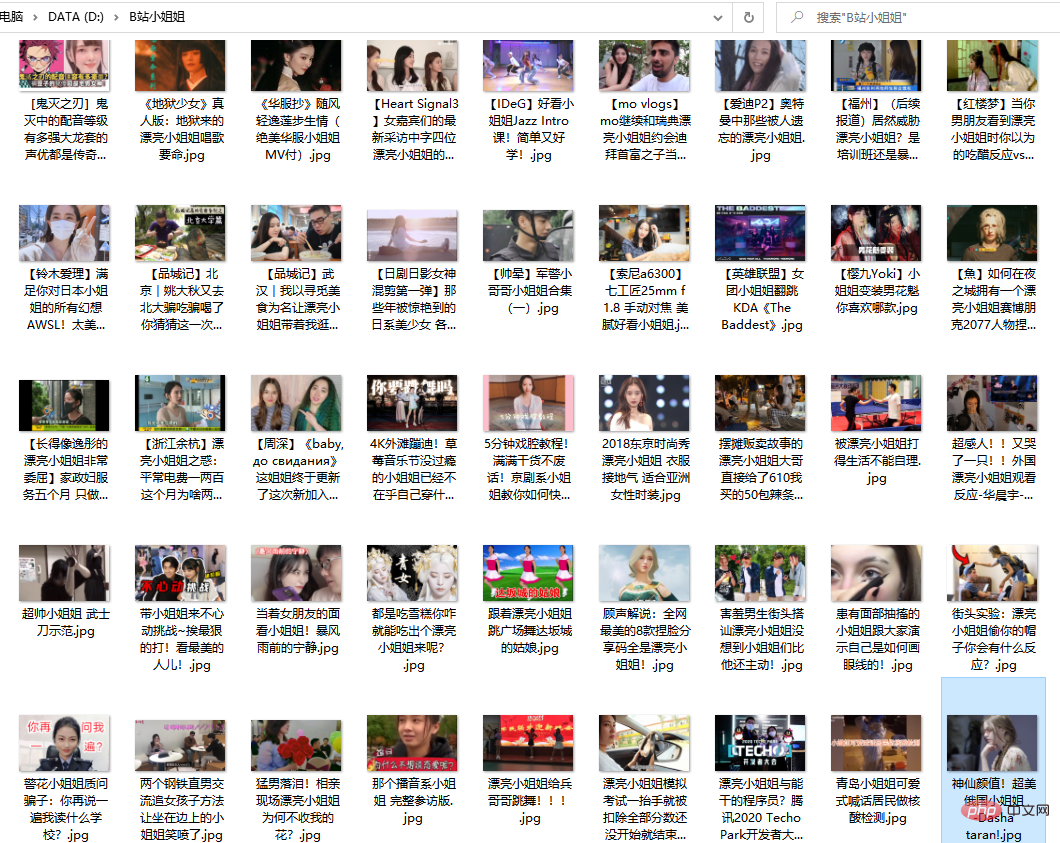
The above is the detailed content of Crawler|Python crawls pictures of girls from station B, motivation to learn!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to use Debian Apache logs to improve website performance
Apr 12, 2025 pm 11:36 PM
How to use Debian Apache logs to improve website performance
Apr 12, 2025 pm 11:36 PM
This article will explain how to improve website performance by analyzing Apache logs under the Debian system. 1. Log Analysis Basics Apache log records the detailed information of all HTTP requests, including IP address, timestamp, request URL, HTTP method and response code. In Debian systems, these logs are usually located in the /var/log/apache2/access.log and /var/log/apache2/error.log directories. Understanding the log structure is the first step in effective analysis. 2. Log analysis tool You can use a variety of tools to analyze Apache logs: Command line tools: grep, awk, sed and other command line tools.
 Python: Games, GUIs, and More
Apr 13, 2025 am 12:14 AM
Python: Games, GUIs, and More
Apr 13, 2025 am 12:14 AM
Python excels in gaming and GUI development. 1) Game development uses Pygame, providing drawing, audio and other functions, which are suitable for creating 2D games. 2) GUI development can choose Tkinter or PyQt. Tkinter is simple and easy to use, PyQt has rich functions and is suitable for professional development.
 PHP and Python: Comparing Two Popular Programming Languages
Apr 14, 2025 am 12:13 AM
PHP and Python: Comparing Two Popular Programming Languages
Apr 14, 2025 am 12:13 AM
PHP and Python each have their own advantages, and choose according to project requirements. 1.PHP is suitable for web development, especially for rapid development and maintenance of websites. 2. Python is suitable for data science, machine learning and artificial intelligence, with concise syntax and suitable for beginners.
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 The role of Debian Sniffer in DDoS attack detection
Apr 12, 2025 pm 10:42 PM
The role of Debian Sniffer in DDoS attack detection
Apr 12, 2025 pm 10:42 PM
This article discusses the DDoS attack detection method. Although no direct application case of "DebianSniffer" was found, the following methods can be used for DDoS attack detection: Effective DDoS attack detection technology: Detection based on traffic analysis: identifying DDoS attacks by monitoring abnormal patterns of network traffic, such as sudden traffic growth, surge in connections on specific ports, etc. This can be achieved using a variety of tools, including but not limited to professional network monitoring systems and custom scripts. For example, Python scripts combined with pyshark and colorama libraries can monitor network traffic in real time and issue alerts. Detection based on statistical analysis: By analyzing statistical characteristics of network traffic, such as data
 Python and Time: Making the Most of Your Study Time
Apr 14, 2025 am 12:02 AM
Python and Time: Making the Most of Your Study Time
Apr 14, 2025 am 12:02 AM
To maximize the efficiency of learning Python in a limited time, you can use Python's datetime, time, and schedule modules. 1. The datetime module is used to record and plan learning time. 2. The time module helps to set study and rest time. 3. The schedule module automatically arranges weekly learning tasks.
 Nginx SSL Certificate Update Debian Tutorial
Apr 13, 2025 am 07:21 AM
Nginx SSL Certificate Update Debian Tutorial
Apr 13, 2025 am 07:21 AM
This article will guide you on how to update your NginxSSL certificate on your Debian system. Step 1: Install Certbot First, make sure your system has certbot and python3-certbot-nginx packages installed. If not installed, please execute the following command: sudoapt-getupdatesudoapt-getinstallcertbotpython3-certbot-nginx Step 2: Obtain and configure the certificate Use the certbot command to obtain the Let'sEncrypt certificate and configure Nginx: sudocertbot--nginx Follow the prompts to select
 How to configure HTTPS server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
How to configure HTTPS server in Debian OpenSSL
Apr 13, 2025 am 11:03 AM
Configuring an HTTPS server on a Debian system involves several steps, including installing the necessary software, generating an SSL certificate, and configuring a web server (such as Apache or Nginx) to use an SSL certificate. Here is a basic guide, assuming you are using an ApacheWeb server. 1. Install the necessary software First, make sure your system is up to date and install Apache and OpenSSL: sudoaptupdatesudoaptupgradesudoaptinsta
