

#Unsplash is a free high-quality photo website. They are all real photography photos. The photo resolution is also very large. It is very good for designer friends. The material is also very useful for some illustration copywriting friends, and it also works well as wallpaper. The corresponding function code has been encapsulated into an exe tool. I hope it will be helpful to you. The code tool acquisition method is attached at the end of the article.
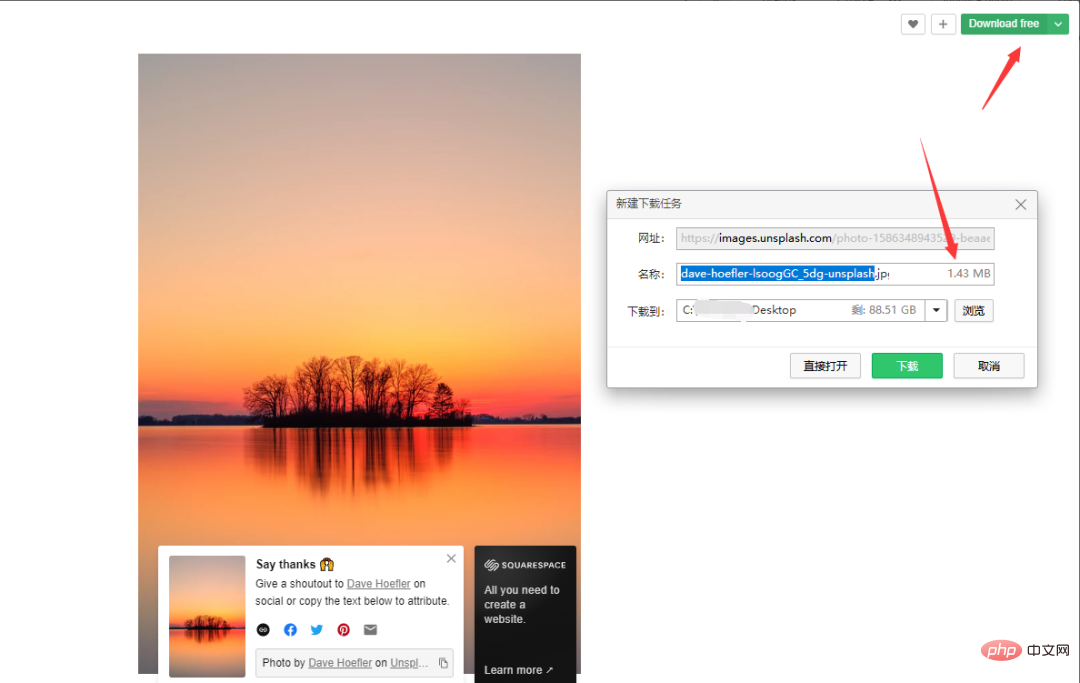
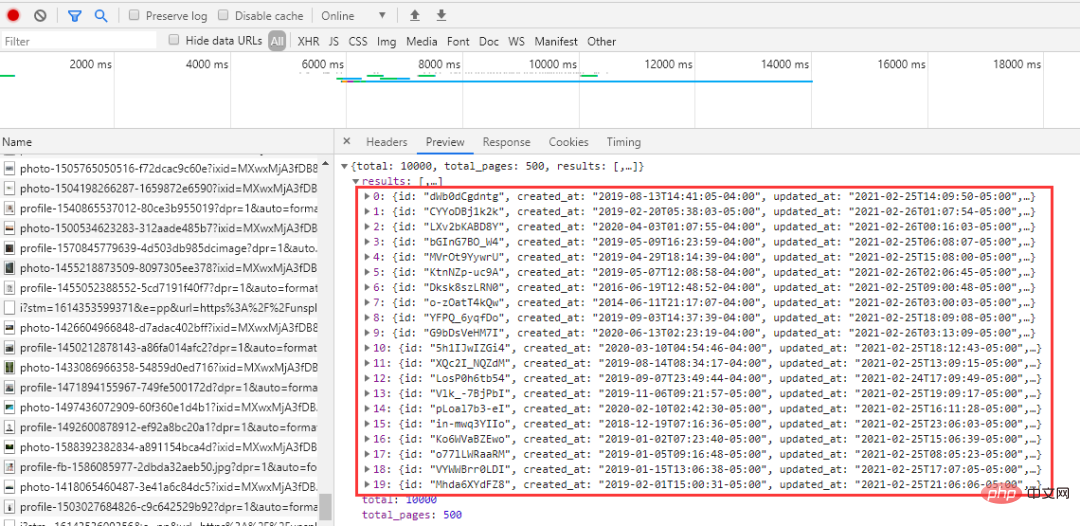
##Code: #Let’s take a look at the manual download process first. Note that you do not right-click the image to save as. The image obtained by right-clicking the save method is compressed at a certain ratio, and the clarity will be reduced a lot. Take Nature as an example, click Download free and select the download path. The image size is 1.43M. . Let’s take a look at a few URLs: The above links are only page parameters are different, and they are increasing in sequence, which is relatively friendly. Just traverse them in sequence when requesting. The page number problem has been solved. Next, analyze the link of each picture: fake_useragent:代理 Try not to crawl frequently to avoid affecting the network order! The picture is a high-definition picture from the external network. The crawling speed depends on the network and is generally not too fast. You can build a proxy pool to crawl faster. 

import time
import random
import json
import requests
from fake_useragent import UserAgent
ua = UserAgent(verify_ssl=False)
headers = {'User-Agent': ua.random}def getpicurls(i,headers):
picurls = []
url = 'https://unsplash.com/napi/search/photos?query=nature&per_page=20&page={}&xp=feedback-loop-v2%3Aexperiment'.format(i)
r = requests.get(url, headers=headers, timeout=5)
time.sleep(random.uniform(3.1, 4.5))
r.raise_for_status()
r.encoding = r.apparent_encoding
allinfo = json.loads(r.text)
results = allinfo['results']
for result in results:
href = result['urls']['full']
picurls.append(href)
return picurlsdef getpic(count,url):
r = requests.get(url, headers=headers, timeout=5)
with open('pictures/{}.jpg'.format(count), 'wb') as f:
f.write(r.content)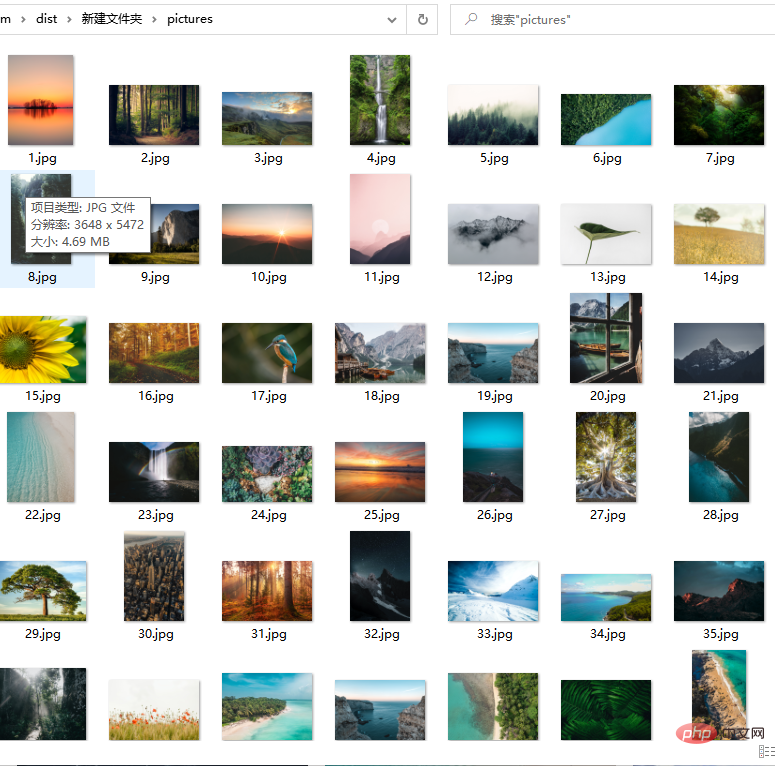
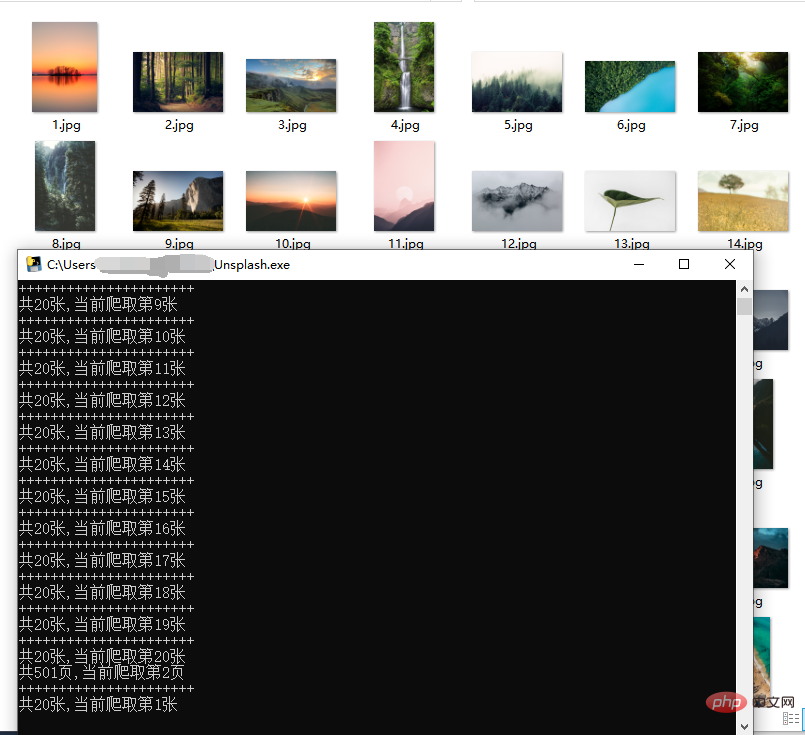
The above is the detailed content of Crawler | Batch download of HD wallpapers (source code + tools included). For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



