
 Technology peripherals
It Industry
Famous: OpenAI releases web crawler tool GPTBot with 'identity mark'
Technology peripherals
It Industry
Famous: OpenAI releases web crawler tool GPTBot with 'identity mark'
Famous: OpenAI releases web crawler tool GPTBot with 'identity mark'

According to news from this site on August 8, OpenAI released its web crawler tool GPTBot yesterday. Officials claim that this GPTBot tool can use a transparent method to collect web page information on the basis of paying attention to copyright to train various AI models under OpenAI .
OpenAI stated that GPTBot uses a proprietary webpage UA to represent its crawler identity, and the complete UA string is (Mozilla / 5.0 AppleWebKit / 537.36 / KHTML, like Gecko; compatible; GPTBot / 1.0; https://openai.com/ gptbot), any website administrator is free to allow or prevent this crawler tool from collecting data.

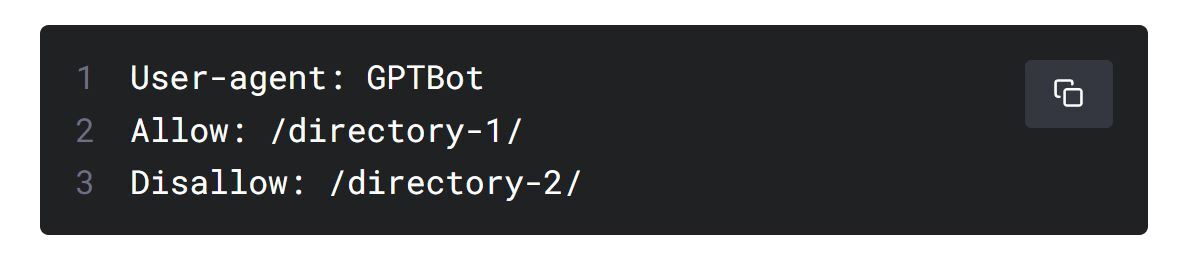
OpenAI claims that if the website administrator does not want to be crawled to collect information, the administrator can completely prohibit GPTBot from crawling information in the robots.txt file of the website server, or he can Determine GPTBot to crawl the specified information on the website.
OpenAI has been criticized by the industry for being accused of privacy violations. Now it has launched the GPTBot crawler tool. This can be seen as a response to external criticism and helps the industry establish crawler tools for AI training. Relevant benchmarks. According to reports, OpenAI recently registered the GPT-5 trademark, and this GPTBot crawler tool is also expected to provide support for GPT-5 related model training
The external jump links (such as hyperlinks, QR code, password, etc.) are only used to provide more information and save screening time. The results are for reference only. Please note that all articles carry this advertising statement
The above is the detailed content of Famous: OpenAI releases web crawler tool GPTBot with 'identity mark'. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 A new programming paradigm, when Spring Boot meets OpenAI
Feb 01, 2024 pm 09:18 PM
A new programming paradigm, when Spring Boot meets OpenAI
Feb 01, 2024 pm 09:18 PM
In 2023, AI technology has become a hot topic and has a huge impact on various industries, especially in the programming field. People are increasingly aware of the importance of AI technology, and the Spring community is no exception. With the continuous advancement of GenAI (General Artificial Intelligence) technology, it has become crucial and urgent to simplify the creation of applications with AI functions. Against this background, "SpringAI" emerged, aiming to simplify the process of developing AI functional applications, making it simple and intuitive and avoiding unnecessary complexity. Through "SpringAI", developers can more easily build applications with AI functions, making them easier to use and operate.
 Choosing the embedding model that best fits your data: A comparison test of OpenAI and open source multi-language embeddings
Feb 26, 2024 pm 06:10 PM
Choosing the embedding model that best fits your data: A comparison test of OpenAI and open source multi-language embeddings
Feb 26, 2024 pm 06:10 PM
OpenAI recently announced the launch of their latest generation embedding model embeddingv3, which they claim is the most performant embedding model with higher multi-language performance. This batch of models is divided into two types: the smaller text-embeddings-3-small and the more powerful and larger text-embeddings-3-large. Little information is disclosed about how these models are designed and trained, and the models are only accessible through paid APIs. So there have been many open source embedding models. But how do these open source models compare with the OpenAI closed source model? This article will empirically compare the performance of these new models with open source models. We plan to create a data
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 Rust-based Zed editor has been open sourced, with built-in support for OpenAI and GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Rust-based Zed editor has been open sourced, with built-in support for OpenAI and GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Author丨Compiled by TimAnderson丨Produced by Noah|51CTO Technology Stack (WeChat ID: blog51cto) The Zed editor project is still in the pre-release stage and has been open sourced under AGPL, GPL and Apache licenses. The editor features high performance and multiple AI-assisted options, but is currently only available on the Mac platform. Nathan Sobo explained in a post that in the Zed project's code base on GitHub, the editor part is licensed under the GPL, the server-side components are licensed under the AGPL, and the GPUI (GPU Accelerated User) The interface) part adopts the Apache2.0 license. GPUI is a product developed by the Zed team
 Don't wait for OpenAI, wait for Open-Sora to be fully open source
Mar 18, 2024 pm 08:40 PM
Don't wait for OpenAI, wait for Open-Sora to be fully open source
Mar 18, 2024 pm 08:40 PM
Not long ago, OpenAISora quickly became popular with its amazing video generation effects. It stood out among the crowd of literary video models and became the focus of global attention. Following the launch of the Sora training inference reproduction process with a 46% cost reduction 2 weeks ago, the Colossal-AI team has fully open sourced the world's first Sora-like architecture video generation model "Open-Sora1.0", covering the entire training process, including data processing, all training details and model weights, and join hands with global AI enthusiasts to promote a new era of video creation. For a sneak peek, let’s take a look at a video of a bustling city generated by the “Open-Sora1.0” model released by the Colossal-AI team. Open-Sora1.0
 Microsoft, OpenAI plan to invest $100 million in humanoid robots! Netizens are calling Musk
Feb 01, 2024 am 11:18 AM
Microsoft, OpenAI plan to invest $100 million in humanoid robots! Netizens are calling Musk
Feb 01, 2024 am 11:18 AM
Microsoft and OpenAI were revealed to be investing large sums of money into a humanoid robot startup at the beginning of the year. Among them, Microsoft plans to invest US$95 million, and OpenAI will invest US$5 million. According to Bloomberg, the company is expected to raise a total of US$500 million in this round, and its pre-money valuation may reach US$1.9 billion. What attracts them? Let’s take a look at this company’s robotics achievements first. This robot is all silver and black, and its appearance resembles the image of a robot in a Hollywood science fiction blockbuster: Now, he is putting a coffee capsule into the coffee machine: If it is not placed correctly, it will adjust itself without any human remote control: However, After a while, a cup of coffee can be taken away and enjoyed: Do you have any family members who have recognized it? Yes, this robot was created some time ago.
 The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!
Apr 15, 2024 am 09:01 AM
The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!
Apr 15, 2024 am 09:01 AM
Ollama is a super practical tool that allows you to easily run open source models such as Llama2, Mistral, and Gemma locally. In this article, I will introduce how to use Ollama to vectorize text. If you have not installed Ollama locally, you can read this article. In this article we will use the nomic-embed-text[2] model. It is a text encoder that outperforms OpenAI text-embedding-ada-002 and text-embedding-3-small on short context and long context tasks. Start the nomic-embed-text service when you have successfully installed o
 Sudden! OpenAI fires Ilya ally for suspected information leakage
Apr 15, 2024 am 09:01 AM
Sudden! OpenAI fires Ilya ally for suspected information leakage
Apr 15, 2024 am 09:01 AM
Sudden! OpenAI fired people, the reason: suspected information leakage. One is Leopold Aschenbrenner, an ally of the missing chief scientist Ilya and a core member of the Superalignment team. The other person is not simple either. He is Pavel Izmailov, a researcher on the LLM inference team, who also worked on the super alignment team. It's unclear exactly what information the two men leaked. After the news was exposed, many netizens expressed "quite shocked": I saw Aschenbrenner's post not long ago and felt that he was on the rise in his career. I didn't expect such a change. Some netizens in the picture think: OpenAI lost Aschenbrenner, I
