

Spring Boot implements MySQL read-write separation technology
How to achieve read-write separation, Spring Boot project, the database is MySQL, and the persistence layer uses MyBatis.
In fact, it is very simple to implement this. First think about a question:
In a high-concurrency scenario, everything about the database What optimization methods are there?
The following implementation methods are commonly used: read-write separation, caching, master-slave architecture cluster, sub-database and sub-table, etc.
In Internet applications, most of the scenarios involve more reading and less writing. Two libraries are set up, the main library and the reading library.
The main library is responsible for writing, and the slave library is mainly responsible for reading. A reading library cluster can be established to reduce read and write conflicts and relieve database load by isolating the read and write functions on the data source. , the purpose of protecting the database. In actual use, any part involving writing is directly switched to the main library, and the reading part is directly switched to the reading library. This is a typical read-write separation technology.
This article will focus on the separation of reading and writing and explore how to achieve it.
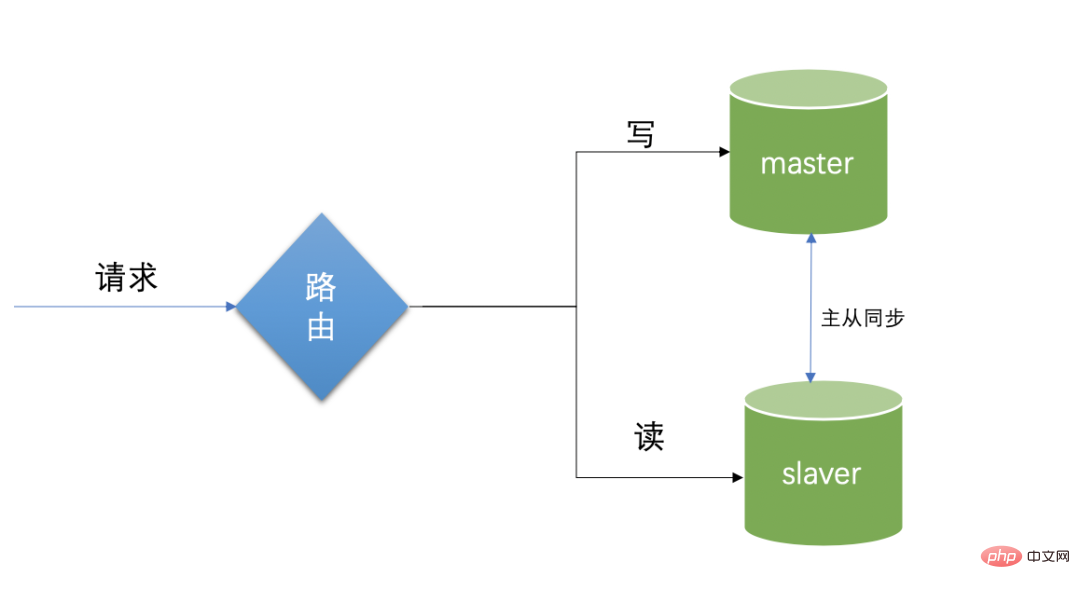
Limitations of master-slave synchronization: This is divided into master database and slave database. The master database and slave database maintain the same database structure. The master database Responsible for writing. When writing data, the data will be automatically synchronized to the slave database. The slave database is responsible for reading. When a read request comes, the data is read directly from the reading database, and the master database will automatically copy the data to the slave database. However, this blog does not introduce this part of the configuration knowledge, because it is more focused on operation and maintenance work.
There is a problem involved here:
The delay problem of master-slave replication. When writing to the main database, a read request suddenly comes, and the data is still there. Without complete synchronization, there will be situations where the read requested data cannot be read or the data read is less than the original value. The simplest specific solution is to temporarily point the read request to the main library, but at the same time it also loses part of the meaning of master-slave separation. That is to say, in the strict sense of data consistency scenarios, read-write separation is not completely suitable. Pay attention to the timeliness of updates as a shortcoming of the use of read-write separation.
Okay, this part is just for understanding. Next, let’s look at how to achieve read and write separation through Java code:
Note: This project needs to introduce the following dependencies: Spring Boot, spring-aop, spring-jdbc, aspectjweaver, etc.
Program Yuan: Only 30 days, what should I do? Prepare?
1: Configuration of master-slave data source
We need to configure the master-slave database, master-slave Database configuration is generally written in the configuration file. Through the @ConfigurationProperties annotation, the properties in the configuration file (generally named: application.Properties) can be mapped to specific class properties, so that the written values can be read and injected into the specific code configuration. , in accordance with the principle that custom is greater than agreement, we all mark the main library as master and the slave library as slave.
This project uses Alibaba's druid database connection pool and uses the build builder mode to create DataSource objects. DataSource is the data source abstracted at the code level. Then you need to configure sessionFactory, sqlTemplate, transaction manager, etc.
/**
* 主从配置
*/
@Configuration
@MapperScan(basePackages = "com.wyq.mysqlreadwriteseparate.mapper", sqlSessionTemplateRef = "sqlTemplate")
public class DataSourceConfig {
/**
* 主库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource master() {
return DruidDataSourceBuilder.create().build();
}
/**
* 从库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaver() {
return DruidDataSourceBuilder.create().build();
}
/**
* 实例化数据源路由
*/
@Bean
public DataSourceRouter dynamicDB(@Qualifier("master") DataSource masterDataSource,
@Autowired(required = false) @Qualifier("slaver") DataSource slaveDataSource) {
DataSourceRouter dynamicDataSource = new DataSourceRouter();
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceEnum.MASTER.getDataSourceName(), masterDataSource);
if (slaveDataSource != null) {
targetDataSources.put(DataSourceEnum.SLAVE.getDataSourceName(), slaveDataSource);
}
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(masterDataSource);
return dynamicDataSource;
}
/**
* 配置sessionFactory
* @param dynamicDataSource
* @return
* @throws Exception
*/
@Bean
public SqlSessionFactory sessionFactory(@Qualifier("dynamicDB") DataSource dynamicDataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setMapperLocations(
new PathMatchingResourcePatternResolver().getResources("classpath*:mapper/*Mapper.xml"));
bean.setDataSource(dynamicDataSource);
return bean.getObject();
}
/**
* 创建sqlTemplate
* @param sqlSessionFactory
* @return
*/
@Bean
public SqlSessionTemplate sqlTemplate(@Qualifier("sessionFactory") SqlSessionFactory sqlSessionFactory) {
return new SqlSessionTemplate(sqlSessionFactory);
}
/**
* 事务配置
*
* @param dynamicDataSource
* @return
*/
@Bean(name = "dataSourceTx")
public DataSourceTransactionManager dataSourceTransactionManager(@Qualifier("dynamicDB") DataSource dynamicDataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(dynamicDataSource);
return dataSourceTransactionManager;
}
}2: Configuration of data source routing
Routing is very important in master-slave separation, basically The core of read-write switching. Spring provides AbstractRoutingDataSource to select the current data source according to user-defined rules. Its function is to set the data source used before executing the query, implement dynamic routing data source, and execute it before each database query operation. The abstract method determineCurrentLookupKey() determines which data source to use.
In order to have a global data source manager, we need to introduce the DataSourceContextHolder database context manager, which can be understood as a global variable and can be accessed at any time (see detailed introduction below). Its main function is Save the current data source.
public class DataSourceRouter extends AbstractRoutingDataSource {
/**
* 最终的determineCurrentLookupKey返回的是从DataSourceContextHolder中拿到的,因此在动态切换数据源的时候注解
* 应该给DataSourceContextHolder设值
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.get();
}
}三:数据源上下文环境
数据源上下文保存器,便于程序中可以随时取到当前的数据源,它主要利用 ThreadLocal 封装,因为 ThreadLocal 是线程隔离的,天然具有线程安全的优势。这里暴露了 set 和 get、clear 方法,set 方法用于赋值当前的数据源名,get 方法用于获取当前的数据源名称,clear 方法用于清除 ThreadLocal 中的内容,因为 ThreadLocal 的 key 是 weakReference 是有内存泄漏风险的,通过 remove 方法防止内存泄漏。
/**
* 利用ThreadLocal封装的保存数据源上线的上下文context
*/
public class DataSourceContextHolder {
private static final ThreadLocal<String> context = new ThreadLocal<>();
/**
* 赋值
*
* @param datasourceType
*/
public static void set(String datasourceType) {
context.set(datasourceType);
}
/**
* 获取值
* @return
*/
public static String get() {
return context.get();
}
public static void clear() {
context.remove();
}
}四:切换注解和 Aop 配置
首先我们来定义一个@DataSourceSwitcher 注解,拥有两个属性
① 当前的数据源② 是否清除当前的数据源,并且只能放在方法上,(不可以放在类上,也没必要放在类上,因为我们在进行数据源切换的时候肯定是方法操作),该注解的主要作用就是进行数据源的切换,在 dao 层进行操作数据库的时候,可以在方法上注明表示的是当前使用哪个数据源。
@DataSourceSwitcher 注解的定义:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface DataSourceSwitcher {
/**
* 默认数据源
* @return
*/
DataSourceEnum value() default DataSourceEnum.MASTER;
/**
* 清除
* @return
*/
boolean clear() default true;
}DataSourceAop配置:
为了赋予@DataSourceSwitcher 注解能够切换数据源的能力,我们需要使用 AOP,然后使用@Aroud 注解找到方法上有@DataSourceSwitcher.class 的方法,然后取注解上配置的数据源的值,设置到 DataSourceContextHolder 中,就实现了将当前方法上配置的数据源注入到全局作用域当中。
@Slf4j
@Aspect
@Order(value = 1)
@Component
public class DataSourceContextAop {
@Around("@annotation(com.wyq.mysqlreadwriteseparate.annotation.DataSourceSwitcher)")
public Object setDynamicDataSource(ProceedingJoinPoint pjp) throws Throwable {
boolean clear = false;
try {
Method method = this.getMethod(pjp);
DataSourceSwitcher dataSourceSwitcher = method.getAnnotation(DataSourceSwitcher.class);
clear = dataSourceSwitcher.clear();
DataSourceContextHolder.set(dataSourceSwitcher.value().getDataSourceName());
log.info("数据源切换至:{}", dataSourceSwitcher.value().getDataSourceName());
return pjp.proceed();
} finally {
if (clear) {
DataSourceContextHolder.clear();
}
}
}
private Method getMethod(JoinPoint pjp) {
MethodSignature signature = (MethodSignature) pjp.getSignature();
return signature.getMethod();
}
}五:用法以及测试
在配置好了读写分离之后,就可以在代码中使用了,一般而言我们使用在 service 层或者 dao 层,在需要查询的方法上添加@DataSourceSwitcher(DataSourceEnum.SLAVE),它表示该方法下所有的操作都走的是读库。在需要 update 或者 insert 的时候使用@DataSourceSwitcher(DataSourceEnum.MASTER)表示接下来将会走写库。
其实还有一种更为自动的写法,可以根据方法的前缀来配置 AOP 自动切换数据源,比如 update、insert、fresh 等前缀的方法名一律自动设置为写库。select、get、query 等前缀的方法名一律配置为读库,这是一种更为自动的配置写法。缺点就是方法名需要按照 aop 配置的严格来定义,否则就会失效。
@Service
public class OrderService {
@Resource
private OrderMapper orderMapper;
/**
* 读操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.SLAVE)
public List<Order> getOrder(String orderId) {
return orderMapper.listOrders(orderId);
}
/**
* 写操作
*
* @param orderId
* @return
*/
@DataSourceSwitcher(DataSourceEnum.MASTER)
public List<Order> insertOrder(Long orderId) {
Order order = new Order();
order.setOrderId(orderId);
return orderMapper.saveOrder(order);
}
}六:总结
还是画张图来简单总结一下:
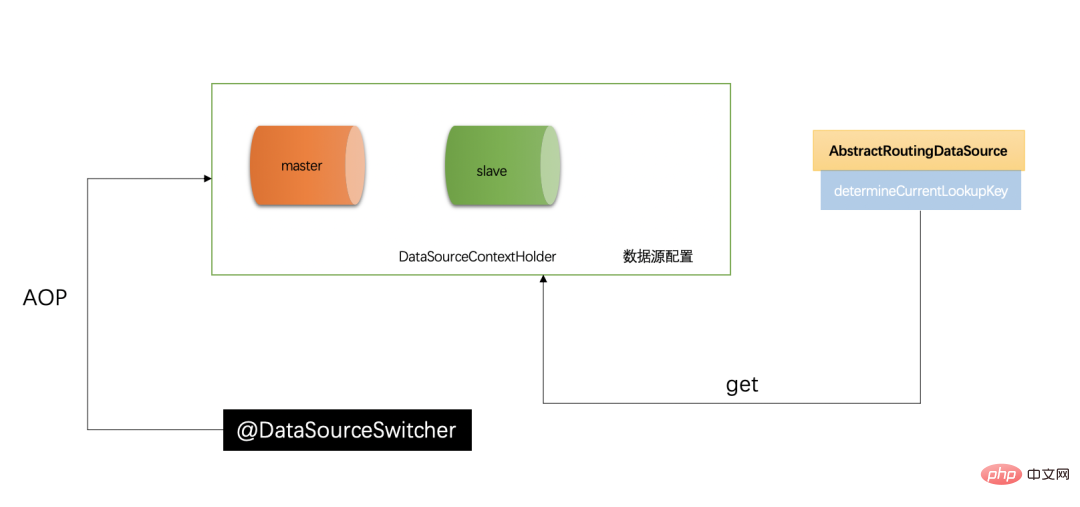
This article introduces how to achieve database read-write separation. Note that the core point of read-write separation is data routing. You need to inherit AbstractRoutingDataSource and overwrite its determineCurrentLookupKey. ()method. At the same time, you need to pay attention to the global context manager DataSourceContextHolder, which is the main class that saves the data source context and is also the data source value found in the routing method. It is equivalent to a transfer station for data sources, and combined with the bottom layer of jdbc-Template to create and manage data sources, transactions, etc., our database read-write separation is perfectly realized.
The above is the detailed content of Spring Boot implements MySQL read-write separation technology. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 How to create navicat premium
Apr 09, 2025 am 07:09 AM
How to create navicat premium
Apr 09, 2025 am 07:09 AM
Create a database using Navicat Premium: Connect to the database server and enter the connection parameters. Right-click on the server and select Create Database. Enter the name of the new database and the specified character set and collation. Connect to the new database and create the table in the Object Browser. Right-click on the table and select Insert Data to insert the data.
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
You can create a new MySQL connection in Navicat by following the steps: Open the application and select New Connection (Ctrl N). Select "MySQL" as the connection type. Enter the hostname/IP address, port, username, and password. (Optional) Configure advanced options. Save the connection and enter the connection name.
 How to recover data after SQL deletes rows
Apr 09, 2025 pm 12:21 PM
How to recover data after SQL deletes rows
Apr 09, 2025 pm 12:21 PM
Recovering deleted rows directly from the database is usually impossible unless there is a backup or transaction rollback mechanism. Key point: Transaction rollback: Execute ROLLBACK before the transaction is committed to recover data. Backup: Regular backup of the database can be used to quickly restore data. Database snapshot: You can create a read-only copy of the database and restore the data after the data is deleted accidentally. Use DELETE statement with caution: Check the conditions carefully to avoid accidentally deleting data. Use the WHERE clause: explicitly specify the data to be deleted. Use the test environment: Test before performing a DELETE operation.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
