

Interviewer: How does MySQL implement ACID?
In the interview, the interviewer only needs to ask about the ACID of MySQL, and then he can immediately recite the eight-part essay (some people may not be able to answer it yet). What's even more disgusting is that some interviewers don't follow the routine and continue to ask, how does MySQL implement ACID?
I’m confused. To be honest, this question can persuade 95% of people.
Today, this article mainly discusses the implementation principle of ACID under the MySQL InnoDB engine. It does not elaborate too much on basic knowledge such as what a transaction is and the meaning of isolation level.
ACID
As a relational database, MySQL uses the most common InnoDB engine to ensure ACID.
(Atomicity)Atomicity: Transaction is the smallest execution unit and does not allow splitting. Atomicity ensures that actions are either fully completed or have no effect at all; (Consistency) Consistency: The data remains consistent before and after executing the transaction; (Isolation) Isolation: When accessing the database concurrently, a transaction will not be interfered by other transactions. (Durability) Durability: After a transaction is committed. Changes to data in the database are persistent, even if the database fails.
Isolation
Let’s talk about isolation first. The first is the four isolation levels.
| Isolation Level | Description |
|---|---|
| When a transaction has not been submitted, the changes it makes can be seen by other transactions | |
| After a transaction is submitted, the changes it makes can only be seen by other transactions. Will be seen by other transactions | |
| Repeatable Reading | In a transaction, the result of reading the same data is always the same, regardless of whether other transactions operate on the data and whether the transaction is committed. InnoDB default level. |
| Serialization | Transactions are executed serially. Each read requires a table-level shared lock. Reading and writing will block each other. The isolation level is the highest, sacrificing the system. Concurrency. |
Different isolation levels are designed to solve different problems. That is, dirty reads, phantom reads, and non-repeatable reads.
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | can appear | can appear | can appear |
| Read submission | Not allowed | Can occur | Can occur |
| Repeatable read | Not allowed | Not allowed | Can appear |
| Serialization | Not allowed | Not allowed | Not allowed |
So different isolation levels, how is isolation achieved, and why can different things not interfere with each other? The answer is Locks and MVCC.
Lock
Let’s talk about locks first. How many locks does MySQL have?
Granularity
In terms of granularity, it is table lock, page lock, and row lock. Table locks include intentional shared locks, intentional exclusive locks, self-increasing locks, etc. Row locks are implemented by each engine at the engine level. But not all engines support row locks. For example, the MyISAM engine does not support row locks.
Types of row locks
In InnoDB transactions, row locks are implemented by locking index entries on the index. This means that InnoDB uses row-level locks only when data is retrieved through index conditions, otherwise table locks are used. Row-level locks are also divided into two types: shared locks and exclusive locks, as well as intention shared locks and intention exclusive locks that need to be obtained before locking.
Shared lock: read lock, other transactions are allowed to add S lock, other transactions are not allowed to add X lock, that is, other transactions can only read but not write. select...lock in share modeLock.Exclusive lock: write lock, no other transactions are allowed to add S lock or X lock. insert, update, delete, for updateLock.
Row locks are added when needed, but they are not released immediately when they are no longer needed, but until the end of the transaction. Only then released. This is the two-phase lock protocol.
Implementation algorithm of row lock
Record Lock
The lock on a single row record will always lock the index record.
Gap Lock
Gap lock, think about the reason for phantom reading. In fact, row lock can only lock rows, but when inserting a new record, what needs to be updated is the "" between records. gap". So add gap lock to solve phantom reading.
Next-Key Lock
Gap Lock Record Lock, left open and closed.
Locks and Isolation
A general introduction to the lower lock can be seen. With locks, when a transaction is writing data, other transactions cannot obtain the write lock and cannot write data. This ensures the isolation between transactions to a certain extent. But as mentioned earlier, after adding a write lock, why can other transactions also read data? Isn’t it that the read lock cannot be obtained? ?
MVCC
As mentioned earlier, with the lock, the current transaction cannot modify the data without a write lock, but it can still be read, and when reading, even if the row of data has been modified and submitted by other transactions, You can still read the same value repeatedly. This is MVCC, multi-version concurrency control, Multi-Version Concurrency Control.
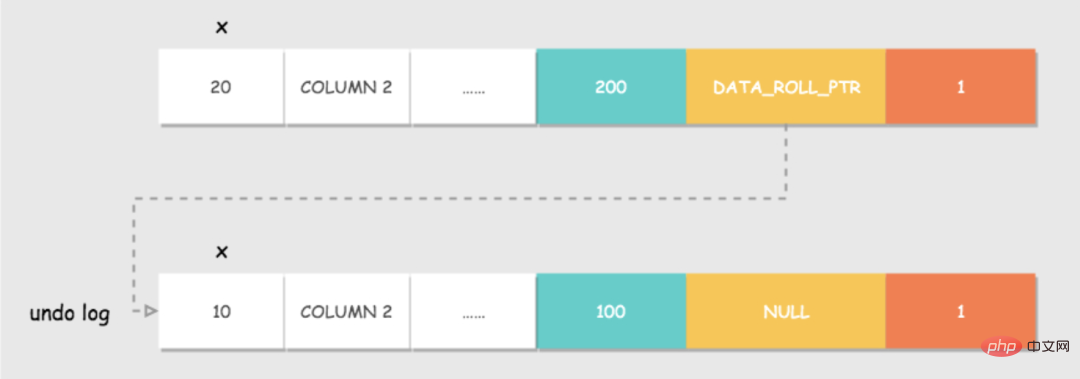
Version chain
The storage format of row records in Innodb has some additional fields: DATA_TRX_ID and DATA_ROLL_PTR.
DATA_TRX_ID: Data row version number. Used to identify the transaction ID that recently modified the record of this row. DATA_ROLL_PTR: Pointer to the rollback segment of the row. All old versions recorded in this line are organized in the form of a linked list in undo log.
#undo log: Record the log before the data is modified, which will be discussed in detail later.

trx_ids: Collection of active (uncommitted) transaction version numbers in the current system. low_limit_id: "The current system's maximum transaction version number 1" when creating the current read view. up_limit_id: "The system is in active transactionminimum version number" when creating the current read view -
creator_trx_id: Create the transaction version number of the current read view;
Start query
Now start the query, a select comes over, and a row of data is found.
DATA_TRX_ID
##DATA_TRX_ID >= low_limit_id:Indicates that the data is generated after the current read view is created, and the data is not displayed . - What to do if it is not displayed? Find the historical version from the undo log according to
DATA_ROLL_PTR , if not found, it will be empty. ##up_limit_id
RR level phantom reading
With locks and MVCC, transaction isolation Sex is resolved. Let me expand here. Does the default RR level solve phantom reading? Phantom reading usually targets INSERT, and non-repeatability targets UPDATE.
| Thing 1 | Thing 2 |
|---|---|
| begin | |
| - | insert into dept(name) values("A") |
| - | commit |
| update dept set name="B" | |
| commit |
We expected it to be
id name 1 A 2 B
actually it was
id name 1 B 2 B
In fact, the isolation level of MySQL repeatable read does not completely solve the problem of phantom reading, but solves it. Phantom reading problem when reading data. There is still a phantom read problem for modification operations, which means that MVCC is not thorough in solving phantom reads.
Atomicity
Let’s talk about atomicity. As mentioned earlier, undo log rolls back the log. Isolation MVCC actually relies on it to achieve, as does atomicity. The key to achieving atomicity is to be able to undo all successfully executed SQL statements when the transaction is rolled back.
When a transaction modifies the database, InnoDB will generate the corresponding undo log; if the transaction execution fails or rollback is called, causing the transaction to be rolled back, the information in the undo log can be used to roll back the data to How it looked before modification. Undo log is a logical log, which records information related to SQL execution. When a rollback occurs, InnoDB will do the opposite of the previous work based on the contents of the undo log:
For each insert, delete will be executed during rollback; For each delete, insert will be executed during rollback; For each update, an opposite update will be executed during rollback to change the data back.
Take the update operation as an example: when a transaction executes an update, the undo log generated will contain the primary key of the modified row (so as to know which rows have been modified) and which columns have been modified. , the values of these columns before and after modification and other information, you can use this information to restore the data to the state before the update during rollback.
Persistence
Innnodb has many logs, and persistence relies on redo log.
How to run a SQL update statement
Persistence is definitely related to writing. WAL technology is often mentioned in MySQL. The full name of WAL is Write-Ahead Logging. Its key point is to write first. log, and then write to disk. Just like doing business in a small shop, there is a pink board and an account book. When guests come, write on the pink board first, and then write down the account book when you are not busy.
redo log
redo log is this pink board. When a record needs to be updated, the InnoDB engine will first write the record to the redo log (and update the memory). At this time, the update is completed. At the appropriate time, this operation record is updated to the disk, and this update is often done when the system is relatively idle, just like what the shopkeeper does after closing.
redo log has two characteristics:
Fixed size, cyclic writing crash-safe
There are two stages for redo log: commit and prepare If you do not use "two-phase commit", the state of the database may be inconsistent with the state of the library restored using its log. Well, let's go here first and look at the other one.
Buffer Pool
InnoDB also provides a cache. The Buffer Pool contains the mapping of some data pages on the disk as a buffer for accessing the database:
When reading data, it will be read from the Buffer Pool first. If it is not in the Buffer Pool, it will be read from the disk and then put into the Buffer Pool; -
When writing data to the database, it will be written to the Buffer Pool first, and the modified data in the Buffer Pool will be regularly refreshed to the disk.
The use of Buffer Pool greatly improves the efficiency of reading and writing data, but it also brings new problems: if MySQL goes down, the modified data in the Buffer Pool has not been refreshed at this time. to the disk will result in data loss, and the durability of the transaction cannot be guaranteed.
So I added redo log. When the data is modified, in addition to modifying the data in the Buffer Pool, the operation will also be recorded in the redo log;
When the transaction is submitted, the fsync interface will be called to flush the redo log.
If MySQL goes down, you can read the data in the redo log and restore the database when restarting.
The redo log uses WAL (Write-ahead logging, write-ahead log). All modifications are first written to the log and then updated to the Buffer Pool, ensuring that the data will not be lost due to MySQL downtime, thus Durability requirements are met. And there are two advantages to doing this:
Brushing dirty pages is random IO, redo log sequential IO Brushing dirty pages is based on Page, and the entire modification on a Page must be written ;The redo log only contains what really needs to be written, reducing invalid IO.
binlog
Speaking of this, you may wonder that there is also a bin log that is also used for write operations and is used for data recovery. What is the difference?
Level: redo log is unique to the innoDB engine, and the server layer is called binlog (archive log) Content: redolog is a physical log, recording "in "What modifications have been made on a certain data page"; binlog is a logical log, which is the original logic of the statement, such as "Add 1 to the c field of the row with ID=2" Write : redolog writes in a loop and has many writing opportunities, binlog is appended and written when the transaction is committed
binlog and redo log
For the statement update T set c=c 1 where ID=2;
The executor first looks for the engine to get the line ID=2. ID is the primary key and can be found directly using tree search. If the data page where the row with ID = 2 is located is in the memory, it will be returned directly to the executor; otherwise, it needs to be read into the memory from the disk first and then returned. The executor gets the row data given by the engine, adds 1, N 1 to this value, gets a new row of data, and then calls the engine interface to write this new row of data. The engine updates this new row of data into the memory and records the update operation into the redo log. At this time, the redo log is in the prepare state. Then inform the executor that the execution is completed and the transaction can be submitted at any time. The executor generates the binlog of this operation and writes the binlog to disk. The executor calls the engine's commit transaction interface, and the engine changes the redo log just written to the commit state, and the update is completed
Why write redo log first?
Redo first and then bin: binlog is lost, one update is missing, and it is still 0 after recovery. First bin and then redo: There is one more transaction, and it is 1 after recovery.
Consistency
Consistency is the ultimate goal pursued by the transaction. The atomicity and durability mentioned in the previous question Security and isolation are actually to ensure the consistency of the database state. Of course, the above are all guarantees at the database level, and the implementation of consistency also requires guarantees at the application level.
That is, your business. For example, the purchase operation only deducts the user's balance without reducing the inventory. It is definitely impossible to ensure that the status is consistent.
Summary
We are all familiar with MySQL, and we also know what ACID is, but how is MySQL’s ACID implemented?
Sometimes, just like you know that there are undo log and redo log, but you may not know why there are them. When you know the purpose of the design, it will become clearer.
The above is the detailed content of Interviewer: How does MySQL implement ACID?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1393
1393
 52
37
110
52
37
110

 Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Perfect Number in Java. Here we discuss the Definition, How to check Perfect number in Java?, examples with code implementation.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Guide to Weka in Java. Here we discuss the Introduction, how to use weka java, the type of platform, and advantages with examples.
 Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Smith Number in Java. Here we discuss the Definition, How to check smith number in Java? example with code implementation.
 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
 TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
Guide to TimeStamp to Date in Java. Here we also discuss the introduction and how to convert timestamp to date in java along with examples.
 Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Capsules are three-dimensional geometric figures, composed of a cylinder and a hemisphere at both ends. The volume of the capsule can be calculated by adding the volume of the cylinder and the volume of the hemisphere at both ends. This tutorial will discuss how to calculate the volume of a given capsule in Java using different methods. Capsule volume formula The formula for capsule volume is as follows: Capsule volume = Cylindrical volume Volume Two hemisphere volume in, r: The radius of the hemisphere. h: The height of the cylinder (excluding the hemisphere). Example 1 enter Radius = 5 units Height = 10 units Output Volume = 1570.8 cubic units explain Calculate volume using formula: Volume = π × r2 × h (4
 Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Java is a popular programming language that can be learned by both beginners and experienced developers. This tutorial starts with basic concepts and progresses through advanced topics. After installing the Java Development Kit, you can practice programming by creating a simple "Hello, World!" program. After you understand the code, use the command prompt to compile and run the program, and "Hello, World!" will be output on the console. Learning Java starts your programming journey, and as your mastery deepens, you can create more complex applications.
