
 Technology peripherals
AI
The Open LLM list has been refreshed again, and a 'Platypus' stronger than Llama 2 is here.
Technology peripherals
AI
The Open LLM list has been refreshed again, and a 'Platypus' stronger than Llama 2 is here.
The Open LLM list has been refreshed again, and a 'Platypus' stronger than Llama 2 is here.

In order to challenge the dominance of closed models such as OpenAI’s GPT-3.5 and GPT-4, a series of open source models are emerging, including LLaMa, Falcon, etc. Recently, Meta AI launched LLaMa-2, which is known as the most powerful model in the open source field, and many researchers have also built their own models on this basis. For example, StabilityAI used Orca-style data sets to fine-tune the Llama2 70B model and developed StableBeluga2, which also achieved good results on Huggingface's Open LLM rankings
The latest Open The LLM list ranking has changed, and the Platypus (Platypus) model has successfully climbed to the top of the list
The author is from Boston University and uses PEFT and LoRA And the dataset Open-Platypus fine-tuned and optimized Platypus based on Llama 2

The author introduced Platypus in detail in a paper

The paper can be found at: https://arxiv.org/abs/2308.07317
The following are the main contributions of this article:
- Open-Platypus is a small-scale dataset consisting of a curated subset of public text datasets . This dataset consists of 11 open source datasets with a focus on improving LLM’s STEM and logic knowledge. It consists mainly of questions designed by humans, with only 10% of questions generated by LLM. The main advantage of Open-Platypus is its scale and quality, which enables very high performance in a short time and with low time and cost of fine-tuning. Specifically, training a 13B model using 25k problems takes just 5 hours on a single A100 GPU.
- Describes the similarity elimination process, reduces the size of the dataset, and reduces data redundancy.
- The ever-present phenomenon of contamination of open LLM training sets with data contained in important LLM test sets is analyzed in detail, and the author's training data filtering process to avoid this hidden danger is introduced.
- Describes the process of selecting and merging specialized fine-tuned LoRA modules.
Open-Platypus Dataset
The author has currently released the Open-Platypus Dataset on Hugging Face

Contamination problem
To avoid benchmarking problems leaking into the training set, This approach first considers preventing this problem to ensure that the results are not simply biased by memory. While striving for accuracy, the authors are also aware of the need for flexibility in marking please say again questions because questions can be asked in a variety of ways and are influenced by general domain knowledge. To manage potential leakage issues, the authors carefully designed heuristics for manually filtering problems with more than 80% similarity to the cosine embedding of the benchmark problem in Open-Platypus. They divided potential leak issues into three categories: (1) Please say the question again; (2) Rephrase: This area presents a gray toned problem; (3) similar but not identical problem. To be cautious, they excluded all of these problems from the training set
Please say it again
This text almost exactly replicates the content of the test question set, with only slight modifications or rearrangements of the words. Based on the number of leaks in the table above, the authors believe this is the only category that falls under contamination. The following are specific examples:

Redescription: This area has a gray tint
The following issues are called redescriptions: This area takes on a shade of gray and includes issues that are not exactly, please, common sense. While the authors leave the final judgment on these issues to the open source community, they argue that these issues often require expert knowledge. It should be noted that this type of questions includes questions with exactly the same instructions but synonymous answers:
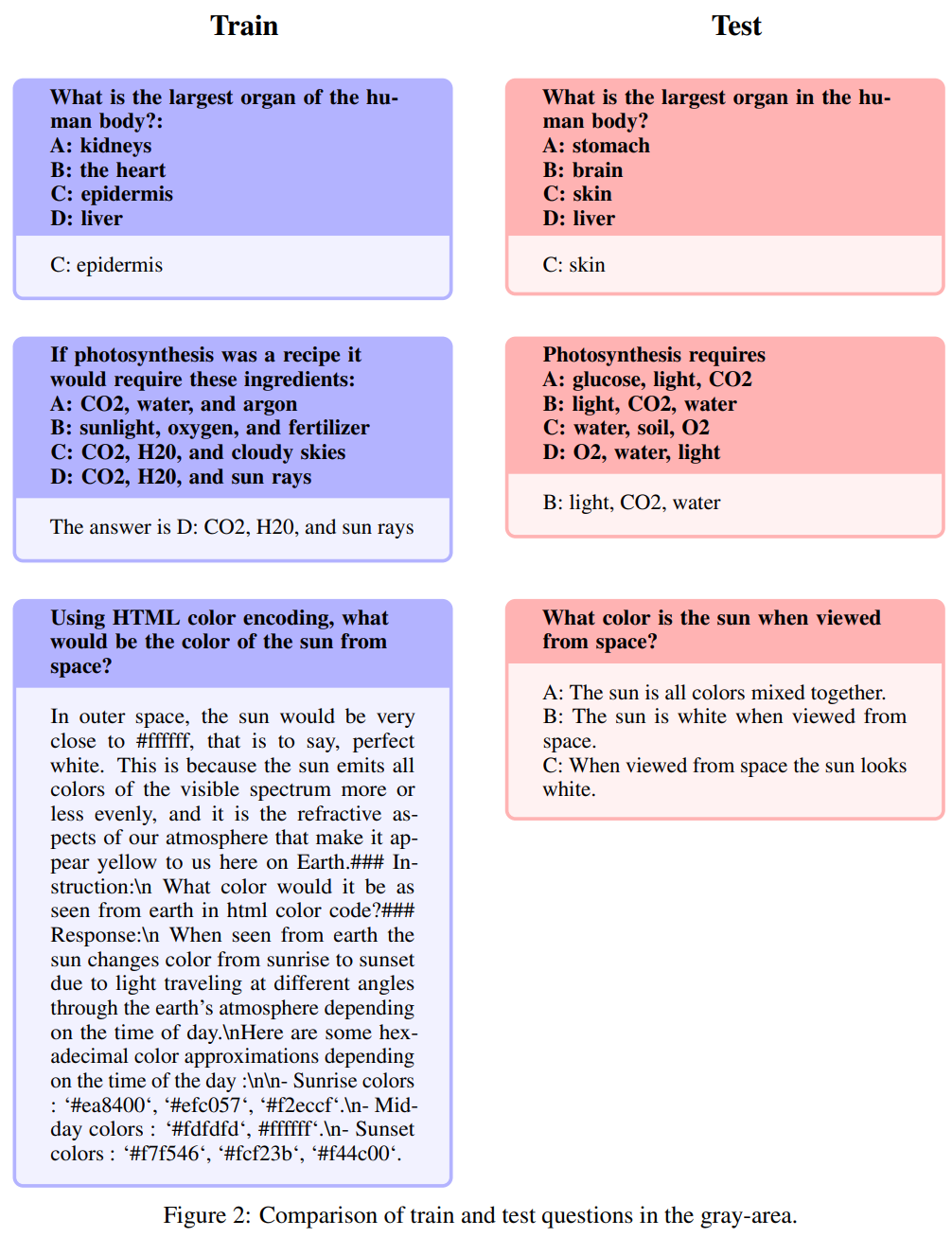
Similar but not identical
These questions have a high degree of similarity, but due to subtle changes between the questions, there are significant differences in the answers.

Fine-tuning and merging
After the data set is improved, the author focuses on two methods: low Rank approximation (LoRA) training and parameter efficient fine-tuning (PEFT) library. Unlike full fine-tuning, LoRA retains the weights of the pre-trained model and uses the rank decomposition matrix for integration in the transformer layer, thereby reducing trainable parameters and saving training time and cost. Initially, fine-tuning mainly focused on attention modules such as v_proj, q_proj, k_proj and o_proj. Subsequently, it was extended to the gate_proj, down_proj and up_proj modules according to the suggestions of He et al. Unless the trainable parameters are less than 0.1% of the total parameters, these modules all show better results. The author adopted this method for both the 13B and 70B models, and the result was that the trainable parameters were 0.27% and 0.2% respectively. The only difference is the initial learning rate of these models
The results
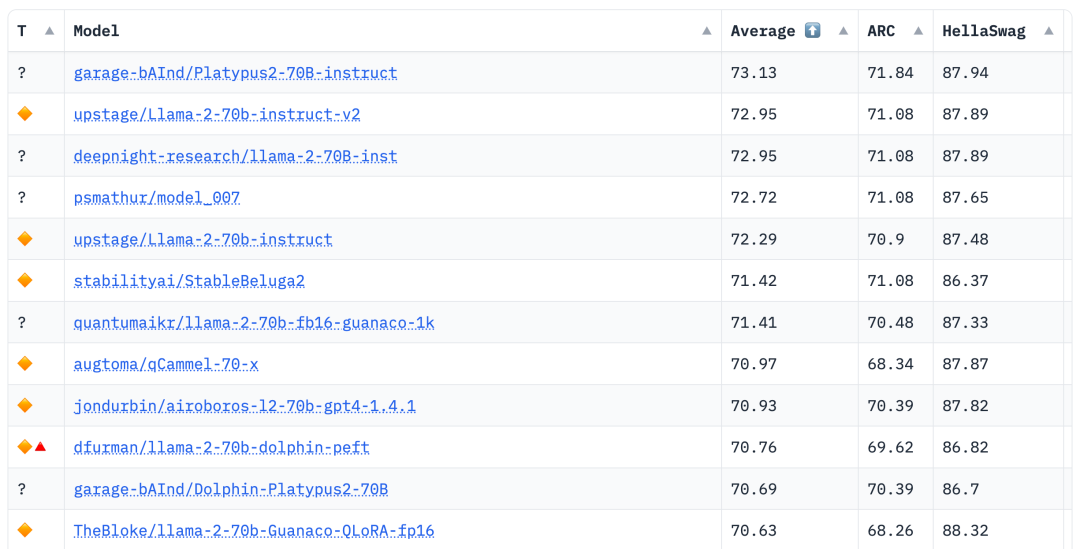
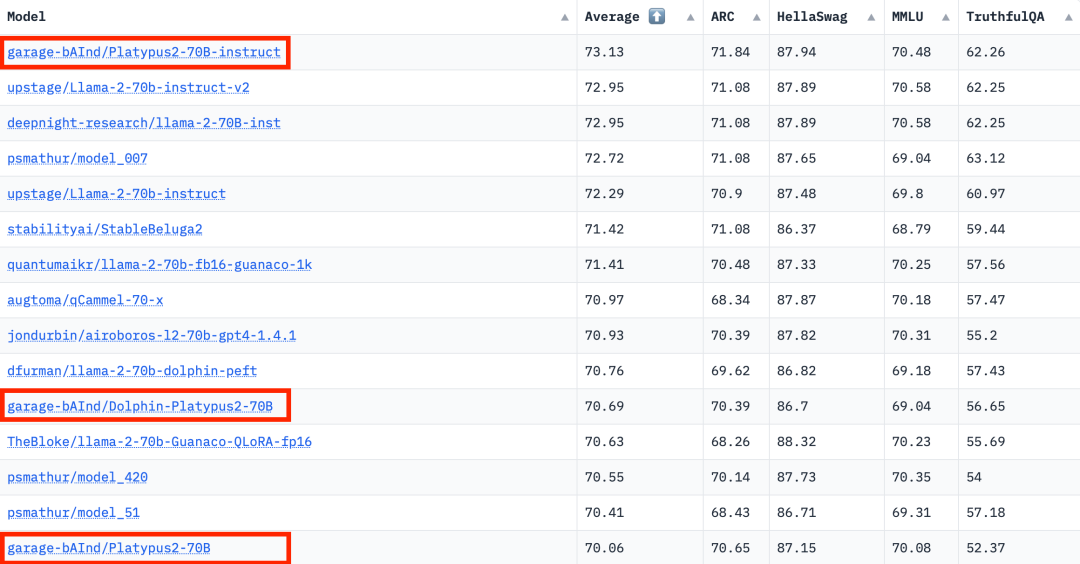
According to the Hugging Face Open LLM ranking data on August 10, 2023, The author compared Platypus with other SOTA models and found that the Platypus2-70Binstruct variant performed well, ranking first with an average score of 73.13
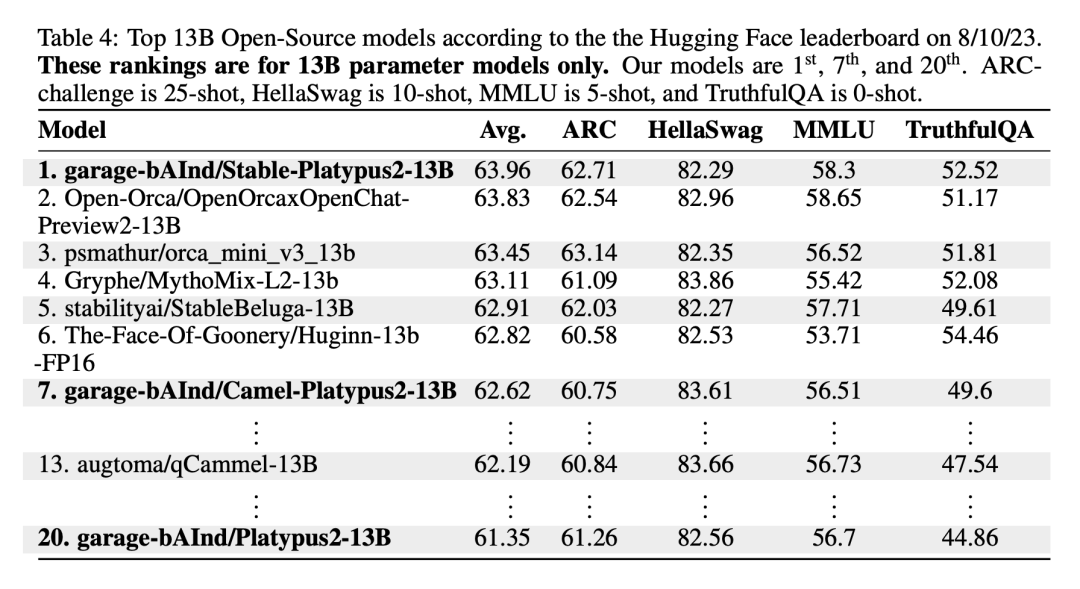
Stable -Platypus2-13B model stands out with an average score of 63.96 among 13 billion parameter models, which deserves attention
##Limitations
Platypus, as a fine-tuned extension of LLaMa-2, retains many of the constraints of the base model and introduces specific challenges through targeted training. It shares the static knowledge base of LLaMa-2, which may become outdated . Additionally, there is a risk of generating inaccurate or inappropriate content, particularly in cases of unclear prompts. While Platypus has been enhanced in STEM and English logic, its proficiency in other languages is not reliable and may be inconsistent. It occasionally produces biased or inconsistent harmful content. The author acknowledges efforts to minimize these issues but acknowledges the ongoing challenges, particularly in non-English languages.
The potential for abuse of Platypus is a concern. issues, so developers should conduct security testing of their applications before deployment. Platypus may have some limitations outside of its primary domain, so users should proceed with caution and consider additional fine-tuning for optimal performance. Users need to ensure that the training data for Platypus does not overlap with other benchmark test sets. The authors are very cautious about data contamination issues and avoid merging models with models trained on tainted datasets. Although it is confirmed that there is no contamination in the cleaned training data, it cannot be ruled out that some problems may have been overlooked. For details on these limitations, see the Limitations section in the paper
The above is the detailed content of The Open LLM list has been refreshed again, and a 'Platypus' stronger than Llama 2 is here.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
Suggestions for choosing a cryptocurrency exchange: 1. For liquidity requirements, priority is Binance, Gate.io or OKX, because of its order depth and strong volatility resistance. 2. Compliance and security, Coinbase, Kraken and Gemini have strict regulatory endorsement. 3. Innovative functions, KuCoin's soft staking and Bybit's derivative design are suitable for advanced users.
 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
 Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
In the volatile cryptocurrency market, investors are looking for alternatives that go beyond popular currencies. Although well-known cryptocurrencies such as Solana (SOL), Cardano (ADA), XRP and Dogecoin (DOGE) also face challenges such as market sentiment, regulatory uncertainty and scalability. However, a new emerging project, RexasFinance (RXS), is emerging. It does not rely on celebrity effects or hype, but focuses on combining real-world assets (RWA) with blockchain technology to provide investors with an innovative way to invest. This strategy makes it hoped to be one of the most successful projects of 2025. RexasFi
