
 Technology peripherals
AI
New backbone of lightweight visual network: efficient Fourier operator token mixer
Technology peripherals
AI
New backbone of lightweight visual network: efficient Fourier operator token mixer
New backbone of lightweight visual network: efficient Fourier operator token mixer

1. Background
Over the years, three vision backbone networks, Transformer, Large-kernel CNN, and MLP, have achieved great success in a wide range of computer vision tasks. , This is mainly due to their ability to efficiently fuse information on a global scale
Transformer, CNN and MLP are the three mainstream neural networks currently, and they use different ways to implement them. Global scope Token fusion. In the Transformer network, the self-attention mechanism uses the correlation of query-key pairs as the weight of Token fusion. CNN achieves similar performance to Transformer by expanding the size of the convolution kernel. MLP implements another powerful paradigm between all tokens through full connectivity. Although these methods are effective, they have high computational complexity (O(N^2)) and are difficult to deploy on devices with limited storage and computing capabilities, thus limiting the application scope of many models
2. AFF Token Mixer: lightweight, global, adaptive
In order to solve the computationally expensive problem, researchers developed a method called adaptive Fu Efficient global token fusion algorithm of Adaptive Fourier Filter (AFF). This algorithm uses Fourier transform to convert the Token set into the frequency domain, and learns a filter mask capable of adaptive content in the frequency domain to perform adaptive filtering operations on the Token set converted into the frequency domain space
Adaptive Frequency Filters: Efficient Global Token Mixers

##Click this link to access the original text: https://arxiv .org/abs/2307.14008
According to the frequency domain convolution theorem, the mathematical equivalent operation of AFF Token Mixer is a convolution operation performed in the original domain, which is equivalent to the Fourier Hadamard product operation in the domain. This means that AFF Token Mixer can achieve content-adaptive global token fusion by using a dynamic convolution kernel in the original domain, whose spatial resolution is the same as the size of the token set (as shown in the right subfigure of the figure below)
It is well known that dynamic convolution is computationally expensive, especially when using dynamic convolution kernels with large spatial resolution. This cost seems to be too high for efficient/lightweight network design. It's unacceptable. However, the AFF Token Mixer proposed in this article can simultaneously meet the above requirements in an equivalent implementation with low power consumption, reducing the complexity from O (N^2) to O (N log N), thereby significantly improving computing efficiency
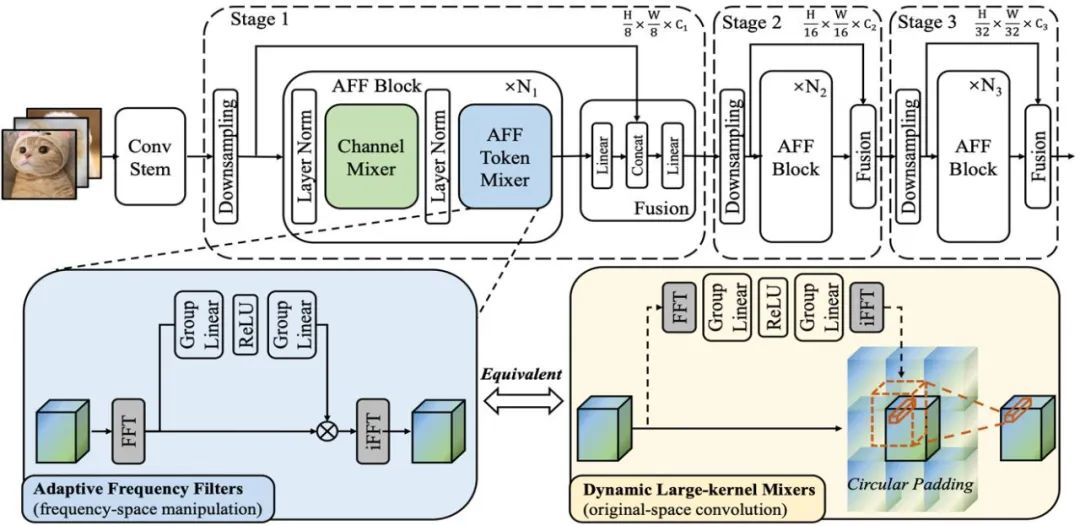
Schematic diagram 1: shows the structure of the AFF module and AFFNet network
3. AFFNet: lightweight New backbone of level visual network
By using AFF Token Mixer as the main neural network operation operator, researchers successfully constructed a lightweight neural network called AFFNet. Rich experimental results show that AFF Token Mixer achieves an excellent balance of accuracy and efficiency in a wide range of visual tasks, including visual semantic recognition and dense prediction tasks
4. Experimental results
Researchers evaluated the performance of AFF Token Mixer and AFFNet on multiple tasks such as visual semantic recognition, segmentation, and detection, and compared them with the most advanced lightweight visual backbone in the current research field. The network was compared. Experimental results show that the model design performs well in a wide range of visual tasks, confirming the potential of AFF Token Mixer as a new generation of lightweight and efficient token fusion operator
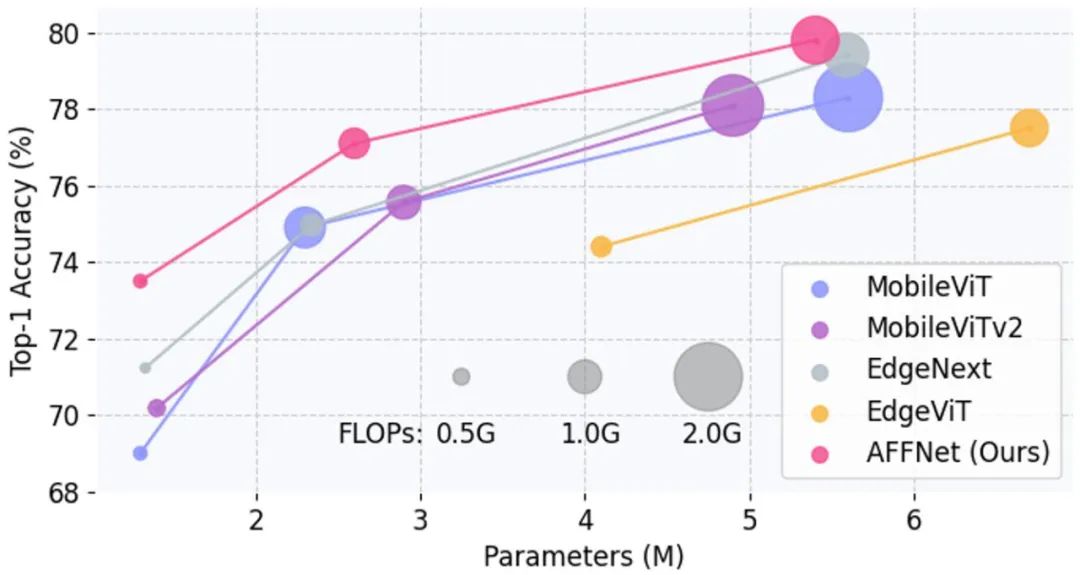
Compared with SOTA, Figure 2 shows the Acc-Param and Acc-FLOPs curves on the ImageNet-1K data set
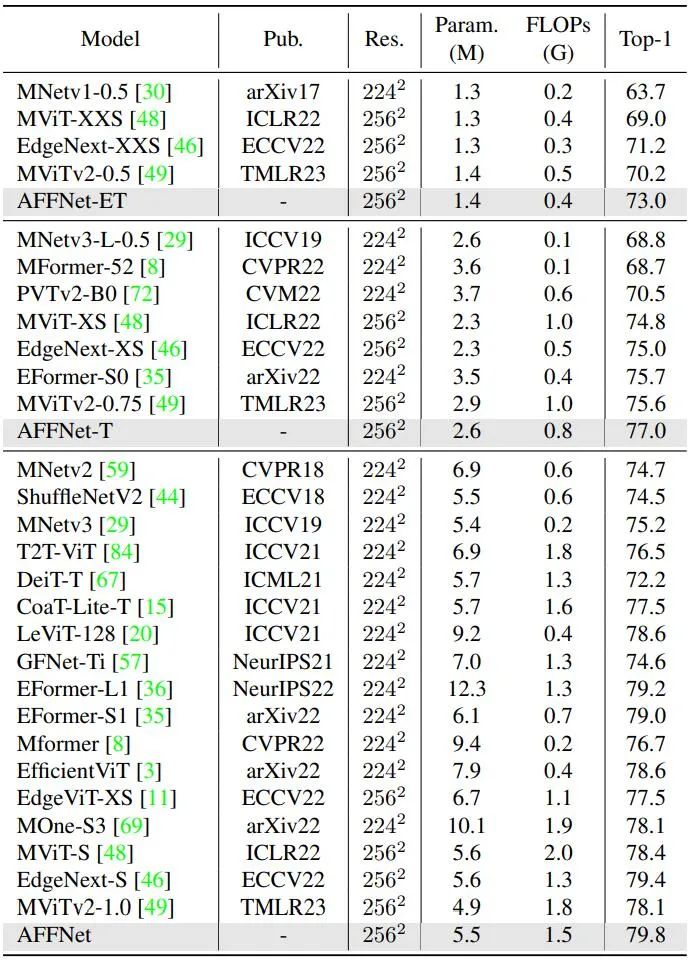
Compare the results of state-of-the-art methods with the ImageNet-1K dataset, see Table 1
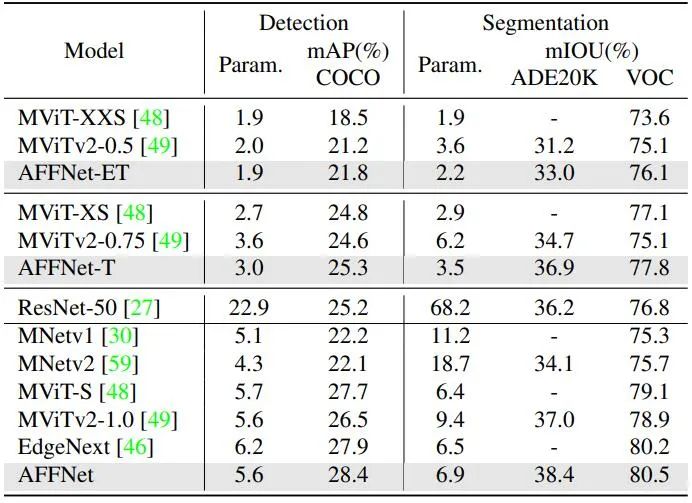
Table 2 shows the results of the visual detection and segmentation tasks with the Comparison of advanced technologies
5. Conclusion
This study proves that the frequency domain transformation in the latent space plays an important role in global adaptive token fusion and is an efficient and A low-power equivalent implementation. It provides new research ideas for the design of Token fusion operators in neural networks, and provides new development space for deploying neural network models on edge devices, especially when storage and computing capabilities are limited
The above is the detailed content of New backbone of lightweight visual network: efficient Fourier operator token mixer. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 CUDA's universal matrix multiplication: from entry to proficiency!
Mar 25, 2024 pm 12:30 PM
CUDA's universal matrix multiplication: from entry to proficiency!
Mar 25, 2024 pm 12:30 PM
General Matrix Multiplication (GEMM) is a vital part of many applications and algorithms, and is also one of the important indicators for evaluating computer hardware performance. In-depth research and optimization of the implementation of GEMM can help us better understand high-performance computing and the relationship between software and hardware systems. In computer science, effective optimization of GEMM can increase computing speed and save resources, which is crucial to improving the overall performance of a computer system. An in-depth understanding of the working principle and optimization method of GEMM will help us better utilize the potential of modern computing hardware and provide more efficient solutions for various complex computing tasks. By optimizing the performance of GEMM
 How to calculate addition, subtraction, multiplication and division in word document
Mar 19, 2024 pm 08:13 PM
How to calculate addition, subtraction, multiplication and division in word document
Mar 19, 2024 pm 08:13 PM
WORD is a powerful word processor. We can use word to edit various texts. In Excel tables, we have mastered the calculation methods of addition, subtraction and multipliers. So if we need to calculate the addition of numerical values in Word tables, How to subtract the multiplier? Can I only use a calculator to calculate it? The answer is of course no, WORD can also do it. Today I will teach you how to use formulas to calculate basic operations such as addition, subtraction, multiplication and division in tables in Word documents. Let's learn together. So, today let me demonstrate in detail how to calculate addition, subtraction, multiplication and division in a WORD document? Step 1: Open a WORD, click [Table] under [Insert] on the toolbar, and insert a table in the drop-down menu.
 A deep dive into models, data, and frameworks: an exhaustive 54-page review of efficient large language models
Jan 14, 2024 pm 07:48 PM
A deep dive into models, data, and frameworks: an exhaustive 54-page review of efficient large language models
Jan 14, 2024 pm 07:48 PM
Large-scale language models (LLMs) have demonstrated compelling capabilities in many important tasks, including natural language understanding, language generation, and complex reasoning, and have had a profound impact on society. However, these outstanding capabilities require significant training resources (shown in the left image) and long inference times (shown in the right image). Therefore, researchers need to develop effective technical means to solve their efficiency problems. In addition, as can be seen from the right side of the figure, some efficient LLMs (LanguageModels) such as Mistral-7B have been successfully used in the design and deployment of LLMs. These efficient LLMs can significantly reduce inference memory while maintaining similar accuracy to LLaMA1-33B
 How to count the number of elements in a list using Python's count() function
Nov 18, 2023 pm 02:53 PM
How to count the number of elements in a list using Python's count() function
Nov 18, 2023 pm 02:53 PM
How to use Python's count() function to calculate the number of an element in a list requires specific code examples. As a powerful and easy-to-learn programming language, Python provides many built-in functions to handle different data structures. One of them is the count() function, which can be used to count the number of elements in a list. In this article, we will explain how to use the count() function in detail and provide specific code examples. The count() function is a built-in function of Python, used to calculate a certain
 Count the number of occurrences of a substring recursively in Java
Sep 17, 2023 pm 07:49 PM
Count the number of occurrences of a substring recursively in Java
Sep 17, 2023 pm 07:49 PM
Given two strings str_1 and str_2. The goal is to count the number of occurrences of substring str2 in string str1 using a recursive procedure. A recursive function is a function that calls itself within its definition. If str1 is "Iknowthatyouknowthatiknow" and str2 is "know" the number of occurrences is -3. Let us understand through examples. For example, input str1="TPisTPareTPamTP", str2="TP"; output Countofoccurrencesofasubstringrecursi
 How to use the Math.Pow function in C# to calculate the power of a specified number
Nov 18, 2023 am 11:32 AM
How to use the Math.Pow function in C# to calculate the power of a specified number
Nov 18, 2023 am 11:32 AM
In C#, there is a Math class library, which contains many mathematical functions. These include the function Math.Pow, which calculates powers, which can help us calculate the power of a specified number. The usage of the Math.Pow function is very simple, you only need to specify the base and exponent. The syntax is as follows: Math.Pow(base,exponent); where base represents the base and exponent represents the exponent. This function returns a double type result, that is, the power calculation result. Let's
 Crushing H100, Nvidia's next-generation GPU is revealed! The first 3nm multi-chip module design, unveiled in 2024
Sep 30, 2023 pm 12:49 PM
Crushing H100, Nvidia's next-generation GPU is revealed! The first 3nm multi-chip module design, unveiled in 2024
Sep 30, 2023 pm 12:49 PM
3nm process, performance surpasses H100! Recently, foreign media DigiTimes broke the news that Nvidia is developing the next-generation GPU, the B100, code-named "Blackwell". It is said that as a product for artificial intelligence (AI) and high-performance computing (HPC) applications, the B100 will use TSMC's 3nm process process, as well as more complex multi-chip module (MCM) design, and will appear in the fourth quarter of 2024. For Nvidia, which monopolizes more than 80% of the artificial intelligence GPU market, it can use the B100 to strike while the iron is hot and further attack challengers such as AMD and Intel in this wave of AI deployment. According to NVIDIA estimates, by 2027, the output value of this field is expected to reach approximately
 The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document
Sep 25, 2023 pm 04:49 PM
The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document
Sep 25, 2023 pm 04:49 PM
The most comprehensive review of multimodal large models is here! Written by 7 Chinese researchers at Microsoft, it has 119 pages. It starts from two types of multi-modal large model research directions that have been completed and are still at the forefront, and comprehensively summarizes five specific research topics: visual understanding and visual generation. The multi-modal large-model multi-modal agent supported by the unified visual model LLM focuses on a phenomenon: the multi-modal basic model has moved from specialized to universal. Ps. This is why the author directly drew an image of Doraemon at the beginning of the paper. Who should read this review (report)? In the original words of Microsoft: As long as you are interested in learning the basic knowledge and latest progress of multi-modal basic models, whether you are a professional researcher or a student, this content is very suitable for you to come together.
