

Should I use Redis or Zookeeper for distributed locks?
Distributed locks are usually implemented in the following ways:
Database Cache (For example: Redis) Zookeeper etcd
Actual In development, Redis and Zookeeper are most commonly used, so this article will only talk about these two.
Before discussing this issue, let us first look at a business scenario:
System A is an e-commerce system. It is currently deployed on a machine. There is a user in the system. Order interface, but users must check the inventory before placing an order to ensure that the inventory is sufficient before placing an order for the user.
Since the system has a certain degree of concurrency, the inventory of the goods will be saved in Redis in advance. When the user places an order, the inventory of Redis will be updated. .
The system architecture at this time is as follows:
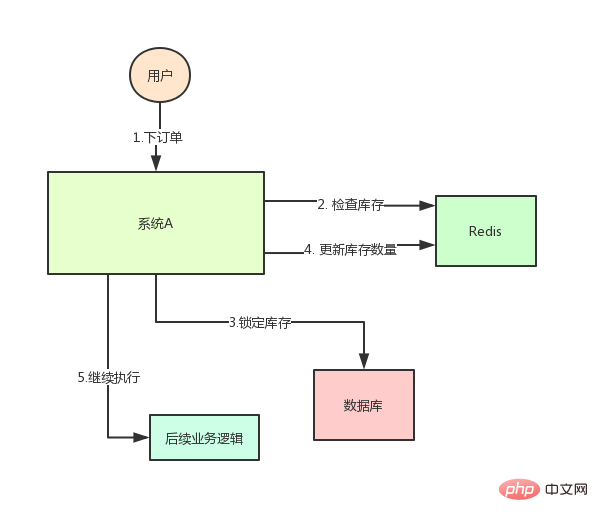
But this will produce a problem: If at a certain moment, the The inventory of a certain product is 1. At this time, two requests come at the same time. One of the requests is executed to step 3 in the above figure, and the inventory of the database is updated to 0, but step 4 has not been executed yet.
The other request reaches step 2 and finds that the inventory is still 1, so it continues to step 3.
The result is that 2 items are sold, but in fact there is only 1 item in stock.
Obviously something is wrong! This is a typical inventory oversold problem
At this point, we can easily think of a solution: use a lock to lock steps 2, 3, and 4, so that after they are completed, another thread can come in to execute step 2. step.
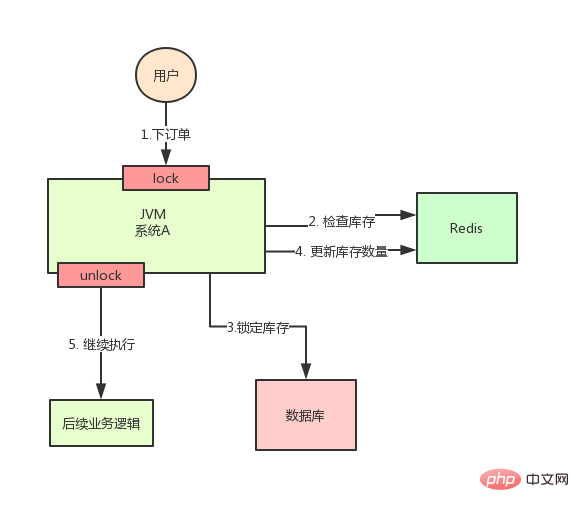
According to the above figure, when executing step 2, use synchronized or ReentrantLock provided by Java to lock, and then release the lock after step 4 is executed.
In this way, the three steps 2, 3, and 4 are "locked", and multiple threads can only be executed serially.
But the good times did not last long, the concurrency of the entire system soared, and one machine could no longer handle it. Now we need to add a machine, as shown below:
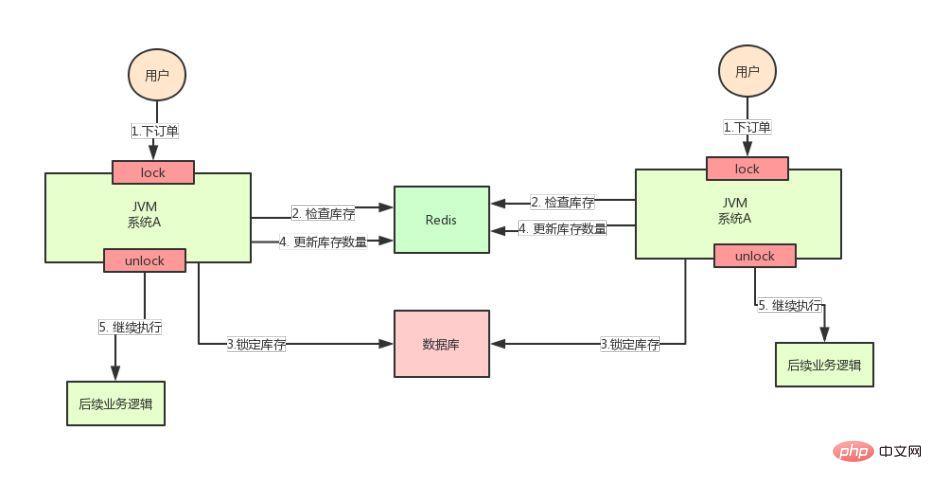
After adding the machine, the system becomes as shown in the picture above, my God!
Assuming that the requests from two users arrive at the same time, but fall on different machines, can these two requests be executed at the same time, or will the inventory oversold problem occur.
why? Because the two A systems in the picture above run in two different JVMs, the locks they add are only valid for threads in their own JVMs, and are invalid for threads in other JVMs.
Therefore, the problem here is: the native lock mechanism provided by Java fails in a multi-machine deployment scenario
This is because the locks added by the two machines are not the same lock (two locks in different JVMs).
Then, as long as we ensure that the locks added by the two machines are the same, won’t the problem be solved?
At this point, it’s time for distributed locks to make their grand appearance. The idea of distributed locks is:
Provide a global and unique way to acquire locks in the entire system. "Thing", and then when each system needs to lock, it will ask this "thing" to get a lock, so that different systems can consider it to be the same lock.
As for this "thing", it can be Redis, Zookeeper, or a database.
The text description is not very intuitive, let’s look at the picture below:
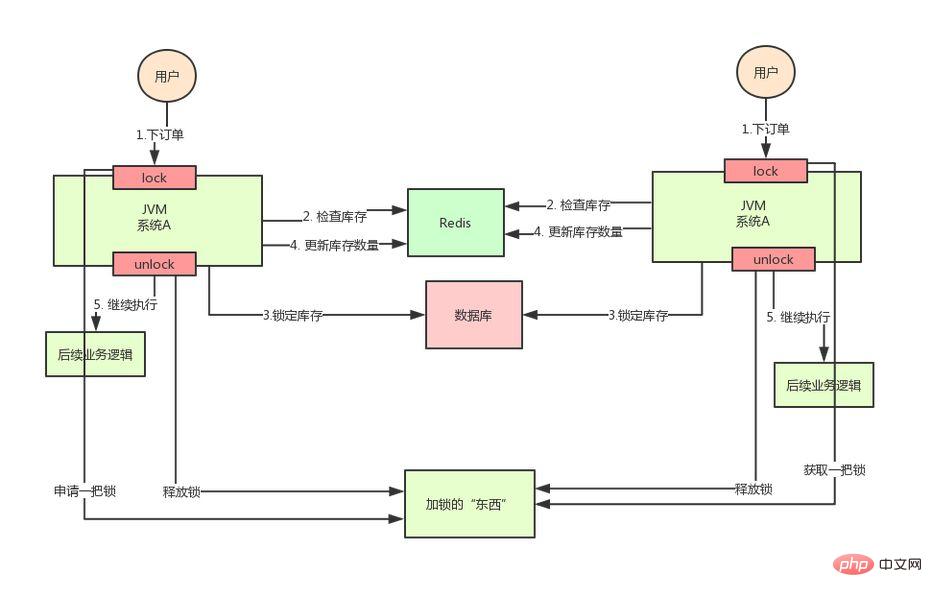
Through the above analysis, we know that the inventory oversold scenario works in the distributed deployment system In this case, using Java's native lock mechanism cannot guarantee thread safety, so we need to use a distributed lock solution.
So, how to implement distributed locks? Then read on!
Implementing distributed locks based on Redis
The above analyzes why distributed locks should be used, here we come Let’s look specifically at how distributed locks should be handled when implemented.
The most common solution is to use Redis for distributed locks
The idea of using Redis for distributed locks is roughly this: set a value in redis to indicate that the lock is added, and then delete the key when the lock is released.
The specific code is as follows:
// 获取锁
// NX是指如果key不存在就成功,key存在返回false,PX可以指定过期时间
SET anyLock unique_value NX PX 30000
// 释放锁:通过执行一段lua脚本
// 释放锁涉及到两条指令,这两条指令不是原子性的
// 需要用到redis的lua脚本支持特性,redis执行lua脚本是原子性的
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
endThere are several important points in this method:
Be sure to use SET key value NX PX milliseconds command
If not used, set the value first and then set the expiration time. This is not an atomic operation and may crash before setting the expiration time, which will cause a deadlock (the key exists permanently)
The value must be unique
This is because when unlocking, it is necessary to verify that the value is consistent with the locked value before deleting the key.
This avoids a situation: Suppose A acquires the lock and the expiration time is 30s. After 35s, the lock has been automatically released. A goes to release the lock, but B may acquire the lock at this time. Client A cannot delete B's lock.
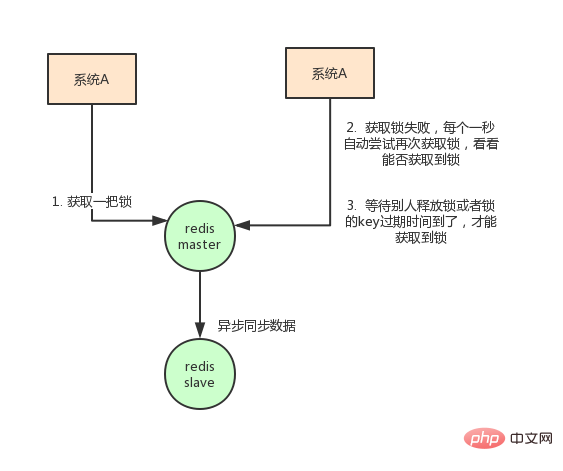
In addition to considering how the client implements distributed locks, you also need to consider the deployment of redis.
Redis has 3 deployment methods:
Single-machine mode master-slave sentinel election mode redis cluster mode
The disadvantage of using redis for distributed locks is that if you use stand-alone deployment mode, there will be a single point of problem, as long as redis fails. Locking it won't work.
Adopt the master-slave mode. When locking, only one node is locked. Even if high availability is achieved through sentinel, if the master node fails and a master-slave switch occurs, it may occur. Lost lock problem.
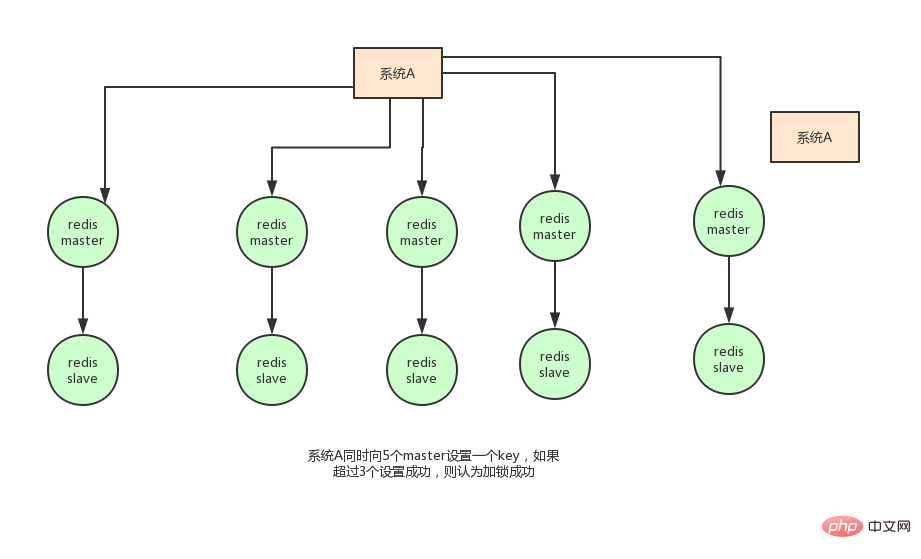
Based on the above considerations, in fact, the author of redis also considered this issue. He proposed a RedLock algorithm. The meaning of this algorithm is roughly like this:
Assume that the deployment mode of redis is redis cluster has a total of 5 master nodes. Obtain a lock through the following steps:
获取当前时间戳,单位是毫秒 轮流尝试在每个master节点上创建锁,过期时间设置较短,一般就几十毫秒 尝试在大多数节点上建立一个锁,比如5个节点就要求是3个节点(n / 2 +1) 客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了 要是锁建立失败了,那么就依次删除这个锁 只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁
但是这样的这种算法还是颇具争议的,可能还会存在不少的问题,无法保证加锁的过程一定正确。
另一种方式:Redisson
此外,实现Redis的分布式锁,除了自己基于redis client原生api来实现之外,还可以使用开源框架:Redission
Redisson是一个企业级的开源Redis Client,也提供了分布式锁的支持。我也非常推荐大家使用,为什么呢?
回想一下上面说的,如果自己写代码来通过redis设置一个值,是通过下面这个命令设置的。
SET anyLock unique_value NX PX 30000
这里设置的超时时间是30s,假如我超过30s都还没有完成业务逻辑的情况下,key会过期,其他线程有可能会获取到锁。
这样一来的话,第一个线程还没执行完业务逻辑,第二个线程进来了也会出现线程安全问题。所以我们还需要额外的去维护这个过期时间,太麻烦了~
我们来看看redisson是怎么实现的?先感受一下使用redission的爽:
Config config = new Config();
config.useClusterServers()
.addNodeAddress("redis://192.168.31.101:7001")
.addNodeAddress("redis://192.168.31.101:7002")
.addNodeAddress("redis://192.168.31.101:7003")
.addNodeAddress("redis://192.168.31.102:7001")
.addNodeAddress("redis://192.168.31.102:7002")
.addNodeAddress("redis://192.168.31.102:7003");
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("anyLock");
lock.lock();
lock.unlock();就是这么简单,我们只需要通过它的api中的lock和unlock即可完成分布式锁,他帮我们考虑了很多细节:
redisson所有指令都通过lua脚本执行,redis支持lua脚本原子性执行
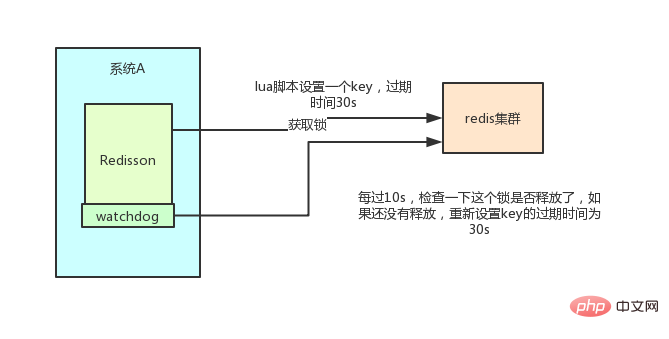
redisson设置一个key的默认过期时间为30s,如果某个客户端持有一个锁超过了30s怎么办?
redisson中有一个
watchdog的概念,翻译过来就是看门狗,它会在你获取锁之后,每隔10秒帮你把key的超时时间设为30s这样的话,就算一直持有锁也不会出现key过期了,其他线程获取到锁的问题了。
redisson的“看门狗”逻辑保证了没有死锁发生。
(如果机器宕机了,看门狗也就没了。此时就不会延长key的过期时间,到了30s之后就会自动过期了,其他线程可以获取到锁)
这里稍微贴出来其实现代码:
// 加锁逻辑
private <T> RFuture<Long> tryAcquireAsync(long leaseTime, TimeUnit unit, final long threadId) {
if (leaseTime != -1) {
return tryLockInnerAsync(leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
// 调用一段lua脚本,设置一些key、过期时间
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(), TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
ttlRemainingFuture.addListener(new FutureListener<Long>() {
@Override
public void operationComplete(Future<Long> future) throws Exception {
if (!future.isSuccess()) {
return;
}
Long ttlRemaining = future.getNow();
// lock acquired
if (ttlRemaining == null) {
// 看门狗逻辑
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
// 看门狗最终会调用了这里
private void scheduleExpirationRenewal(final long threadId) {
if (expirationRenewalMap.containsKey(getEntryName())) {
return;
}
// 这个任务会延迟10s执行
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
// 这个操作会将key的过期时间重新设置为30s
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
expirationRenewalMap.remove(getEntryName());
if (!future.isSuccess()) {
log.error("Can't update lock " + getName() + " expiration", future.cause());
return;
}
if (future.getNow()) {
// reschedule itself
// 通过递归调用本方法,无限循环延长过期时间
scheduleExpirationRenewal(threadId);
}
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(getEntryName(), new ExpirationEntry(threadId, task)) != null) {
task.cancel();
}
}另外,redisson还提供了对redlock算法的支持,
它的用法也很简单:
RedissonClient redisson = Redisson.create(config);
RLock lock1 = redisson.getFairLock("lock1");
RLock lock2 = redisson.getFairLock("lock2");
RLock lock3 = redisson.getFairLock("lock3");
RedissonRedLock multiLock = new RedissonRedLock(lock1, lock2, lock3);
multiLock.lock();
multiLock.unlock();小结:
本节分析了使用Redis作为分布式锁的具体落地方案,以及其一些局限性,然后介绍了一个Redis的客户端框架redisson。这也是我推荐大家使用的,比自己写代码实现会少care很多细节。
基于zookeeper实现分布式锁
常见的分布式锁实现方案里面,除了使用redis来实现之外,使用zookeeper也可以实现分布式锁。
在介绍zookeeper(下文用zk代替)实现分布式锁的机制之前,先粗略介绍一下zk是什么东西:
Zookeeper是一种提供配置管理、分布式协同以及命名的中心化服务。
zk的模型是这样的:zk包含一系列的节点,叫做znode,就好像文件系统一样每个znode表示一个目录,然后znode有一些特性:
Ordered node: If there is currently a parent node named
/lock, we can create a child node under this parent node;zookeeper Provides an optional ordering feature. For example, we can create a child node "/lock/node-" and specify the order. Then zookeeper will automatically add an integer serial number based on the current number of child nodes when generating child nodes
In other words, if it is the first child node created, the generated child node is
/lock/node-0000000000, and the next node is/lock/node-0000000001,And so on.Temporary node: The client can create a temporary node. Zookeeper will automatically delete the node after the session ends or the session times out.
Event monitoring: When reading data, we can set event monitoring on the node at the same time. When the node data or structure changes, zookeeper will notify the client. Currently zookeeper has the following four events:
- ##Node creation
- Node deletion
- Node data modification
- Child node change
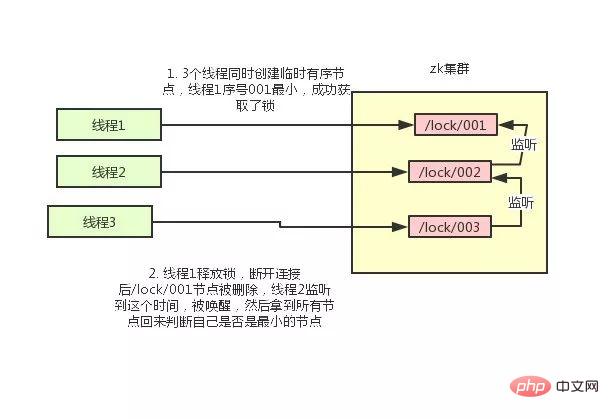
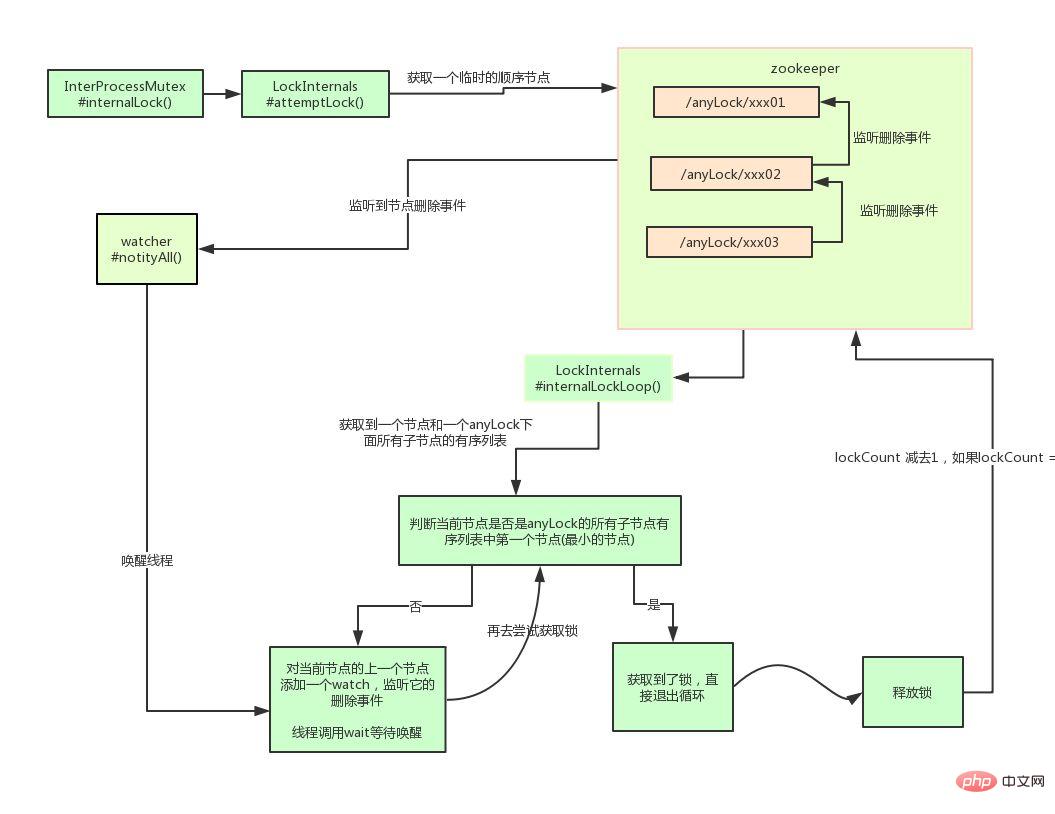
Use zk's temporary nodes and ordered nodes, Each thread acquires a lock by creating a temporary ordered node in zk, such as in the /lock/ directory. After successfully creating the node, obtain all temporary nodes in the /lock directory, and then determine whether the node created by the current thread is the node with the smallest serial number of all nodes. #If the node created by the current thread is the node with the smallest sequence number of all nodes, the lock acquisition is considered successful. #If the node created by the current thread is not the node with the smallest serial number of all nodes, add an event listener to the node before the node serial number. 比如当前线程获取到的节点序号为
/lock/003,然后所有的节点列表为[/lock/001,/lock/002,/lock/003],则对/lock/002这个节点添加一个事件监听器。
如果锁释放了,会唤醒下一个序号的节点,然后重新执行第3步,判断是否自己的节点序号是最小。
比如/lock/001释放了,/lock/002监听到时间,此时节点集合为[/lock/002,/lock/003],则/lock/002为最小序号节点,获取到锁。
整个过程如下:
具体的实现思路就是这样,至于代码怎么写,这里比较复杂就不贴出来了。
Curator介绍
Curator是一个zookeeper的开源客户端,也提供了分布式锁的实现。
他的使用方式也比较简单:
InterProcessMutex interProcessMutex = new InterProcessMutex(client,"/anyLock"); interProcessMutex.acquire(); interProcessMutex.release();
其实现分布式锁的核心源码如下:
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{
boolean haveTheLock = false;
boolean doDelete = false;
try {
if ( revocable.get() != null ) {
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ) {
// 获取当前所有节点排序后的集合
List<String> children = getSortedChildren();
// 获取当前节点的名称
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
// 判断当前节点是否是最小的节点
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() ) {
// 获取到锁
haveTheLock = true;
} else {
// 没获取到锁,对当前节点的上一个节点注册一个监听器
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this){
Stat stat = client.checkExists().usingWatcher(watcher).forPath(previousSequencePath);
if ( stat != null ){
if ( millisToWait != null ){
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 ){
doDelete = true; // timed out - delete our node
break;
}
wait(millisToWait);
}else{
wait();
}
}
}
// else it may have been deleted (i.e. lock released). Try to acquire again
}
}
}
catch ( Exception e ) {
doDelete = true;
throw e;
} finally{
if ( doDelete ){
deleteOurPath(ourPath);
}
}
return haveTheLock;
}其实curator实现分布式锁的底层原理和上面分析的是差不多的。这里我们用一张图详细描述其原理:
小结:
本节介绍了Zookeeperr实现分布式锁的方案以及zk的开源客户端的基本使用,简要的介绍了其实现原理。
Comparison of the advantages and disadvantages of the two schemes
After learning the two distributed lock implementation schemes, this section needs to be discussed What are the respective advantages and disadvantages of redis and zk implementation solutions.
As for the distributed lock of redis, it has the following shortcomings:
The way it obtains the lock is simple and crude. If it cannot obtain the lock, it will continue to try to obtain the lock. Compare consumption performance. In addition, the design positioning of redis determines that its data is not strongly consistent. In some extreme cases, problems may occur. The lock model is not robust enough Even if the redlock algorithm is used to implement it, in some complex scenarios, there is no guarantee that its implementation will be 100% problem-free. For a discussion about redlock, see How to do distributed locking redis distributed lock actually requires you to constantly try to acquire the lock, which consumes performance.
But on the other hand, using redis to implement distributed locks is very common in many enterprises, and in most cases you will not encounter the so-called "extremely complex scenarios"
So using redis as a distributed lock is also a good solution. The most important point is that redis has high performance and can support high-concurrency acquisition and release lock operations.
For zk distributed locks:
zookeeper's natural design positioning is distributed coordination and strong consistency. The lock model is robust, easy to use, and suitable for distributed locks. If the lock cannot be obtained, you only need to add a listener. There is no need to poll all the time, and the performance consumption is small.
But zk also has its shortcomings: if there are more clients frequently applying for locks and releasing locks, the pressure on the zk cluster will be greater.
Summary:
In summary, both redis and zookeeper have their advantages and disadvantages. We can use these issues as reference factors when making technology selection.
The above is the detailed content of Should I use Redis or Zookeeper for distributed locks?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Using ZooKeeper for distributed lock processing in Java API development
Jun 17, 2023 pm 10:36 PM
Using ZooKeeper for distributed lock processing in Java API development
Jun 17, 2023 pm 10:36 PM
As modern applications continue to evolve and the need for high availability and concurrency grows, distributed system architectures are becoming more common. In a distributed system, multiple processes or nodes run at the same time and complete tasks together, and synchronization between processes becomes particularly important. Since many nodes in a distributed environment can access shared resources at the same time, how to deal with concurrency and synchronization issues has become an important task in a distributed system. In this regard, ZooKeeper has become a very popular solution. ZooKee
 Using ZooKeeper and Curator for distributed coordination and management in Beego
Jun 22, 2023 pm 09:27 PM
Using ZooKeeper and Curator for distributed coordination and management in Beego
Jun 22, 2023 pm 09:27 PM
With the rapid development of the Internet, distributed systems have become one of the infrastructures in many enterprises and organizations. For a distributed system to function properly, it needs to be coordinated and managed. In this regard, ZooKeeper and Curator are two tools worth using. ZooKeeper is a very popular distributed coordination service that can help us coordinate the status and data between nodes in a cluster. Curator is an encapsulation of ZooKeeper
 How to use PHP's Zookeeper extension?
Jun 02, 2023 pm 09:01 PM
How to use PHP's Zookeeper extension?
Jun 02, 2023 pm 09:01 PM
PHP is a very popular programming language that is widely used in web applications and server-side development. Zookeeper is a distributed coordination service used to manage, coordinate and monitor distributed applications and services. Using Zookeeper in PHP applications can improve the performance and reliability of your application. This article will introduce how to use the Zookeeper extension for PHP. 1. Install the Zookeeper extension. To use the Zookeeper extension, you need to install Zookeeper.
 Should I use Redis or Zookeeper for distributed locks?
Aug 22, 2023 pm 03:48 PM
Should I use Redis or Zookeeper for distributed locks?
Aug 22, 2023 pm 03:48 PM
The implementation methods of distributed locks usually include: database, cache (such as Redis), Zookeeper, etcd. In actual development, Redis and Zookeeper are most commonly used, so this article will only talk about these two.
 Using ZooKeeper to implement service registration and discovery in Beego
Jun 22, 2023 am 08:21 AM
Using ZooKeeper to implement service registration and discovery in Beego
Jun 22, 2023 am 08:21 AM
In the microservice architecture, service registration and discovery is a very important issue. To solve this problem, we can use ZooKeeper as a service registration center. In this article, we will introduce how to use ZooKeeper in the Beego framework to implement service registration and discovery. 1. Introduction to ZooKeeper ZooKeeper is a distributed, open source distributed coordination service. It is one of the sub-projects of Apache Hadoop. The main role of ZooKeeper
![[Recommended collection] Soul torture! Zookeeper's 31-shot cannon](https://img.php.cn/upload/article/202308/28/2023082816453271532.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) [Recommended collection] Soul torture! Zookeeper's 31-shot cannon
Aug 28, 2023 pm 04:45 PM
[Recommended collection] Soul torture! Zookeeper's 31-shot cannon
Aug 28, 2023 pm 04:45 PM
ZooKeeper is an open source distributed coordination service. It is a software that provides consistency services for distributed applications. Distributed applications can implement tasks such as data publishing/subscription, load balancing, naming service, distributed coordination/notification, cluster management, Master election, distributed locks and Distributed queues and other functions.
 ZooKeeper comparison of Redis implementation of distributed locks
Jun 20, 2023 pm 03:19 PM
ZooKeeper comparison of Redis implementation of distributed locks
Jun 20, 2023 pm 03:19 PM
With the rapid development of Internet technology, distributed systems have been widely used in modern applications, especially in large Internet companies. However, in a distributed system, it is very difficult to maintain consistency between nodes, so the distributed lock mechanism has become one of the foundations to solve this problem. In the implementation of distributed locks, Redis and ZooKeeper are both popular tools. This article will compare and analyze them. Redis implements distributed locks Redis is an open source memory data storage
 How to integrate Dubbo zookeeper in SpringBoot
May 17, 2023 pm 02:16 PM
How to integrate Dubbo zookeeper in SpringBoot
May 17, 2023 pm 02:16 PM
dockerpullzookeeperdockerrun --namezk01-p2181:2181--restartalways-d2e30cac00aca indicates that zookeeper has successfully started Zookeeper and Dubbo • ZooKeeperZooKeeper is a distributed, open source distributed application coordination service. It is a software that provides consistent services for distributed applications. The functions provided include: configuration maintenance, domain name services, distributed synchronization, group services, etc. DubboDubbo is Alibaba's open source distributed service framework. Its biggest feature is that it is structured in a layered manner.
