
 Java
JavaInterview questions
It is recommended to collect 100 Linux interview questions with answers
Java
JavaInterview questions
It is recommended to collect 100 Linux interview questions with answers
It is recommended to collect 100 Linux interview questions with answers
This article has a total of more than 30,000 words, covering Linux overview, disk, directory, file, security, syntax level, actual combat, file management commands, document editing commands, disk management commands, network Dismantling of communication commands, system management commands, backup compression commands, etc.Linux Knowledge points.
Directory of this article:
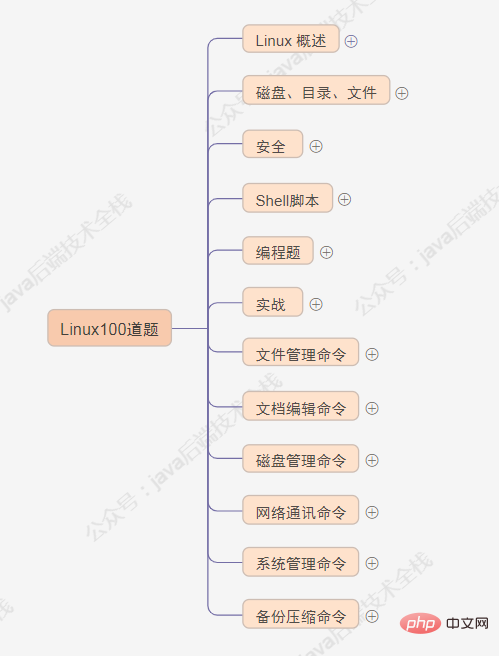
##1. Overview of Linux

What is Linux
Linux is a set of Unix-like operating systems that are free to use and freely disseminated. A multi-user, multi-tasking, multi-threading and multi-CPU operating system based on POSIX and Unix. It can run major Unix software tools, applications and network protocols. It supports 32-bit and 64-bit hardware. Linux inherits the design philosophy of Unix with the network as the core, and is a multi-user network operating system with stable performance.
Back-end technology core knowledge summary series:
## PS: If you have never learned Linux, you can download this tutorial:
地址 https://pan.baidu.com/s/1O_Gj9qnyuGm2xHcX5ouS0g 密码:ptge
Linux and Unix are both powerful operating systems and widely used server operating systems. They have many similarities. Some people even mistakenly believe that Unix and Linux operating systems are the same, however, that is not the case, here are the differences between the two.
- Open source
Cross-platform performance
Linux operating system has good cross-platform performance and can run on a variety of hardware platforms; Unix operating system has better cross-platform performance Weak, most need to be used with hardware.
Visual interface
In addition to command line operations, Linux also has a form management system; Unix is only a command line system.
Hardware Environment
Linux operating system has lower hardware requirements and the installation method is easier to master; Unix has stricter hardware requirements and is difficult to install larger.
User Group
Linux has a wide user group, which can be used by both individuals and enterprises; Unix has a narrower user group, mostly security It is used by large enterprises with high performance requirements, such as banks, telecommunications departments, etc., or by Unix hardware manufacturers, such as Sun, etc.
Compared with the Unix operating system, the Linux operating system is more popular among computer enthusiasts. The main reason is that the Linux operating system has all the functions of the Unix operating system and can implement all Unix functions on ordinary PC computers. Features, open source and free features, easier to popularize and use!
What is the Linux kernel?
The core of the Linux system is the kernel. The kernel controls all hardware and software on a computer system, allocating hardware when necessary and executing software as needed.
System memory management Application management Hardware device management File System Management
What are the basic components of Linux?
Just like any other typical operating system, Linux has all these components: kernel, shell and GUI, system utilities and applications. What makes Linux more advantageous than other operating systems is that every aspect comes with additional features, and all code is free to download.
Let’s talk about the Linux architecture
From a large perspective, the Linux architecture can be divided into two parts: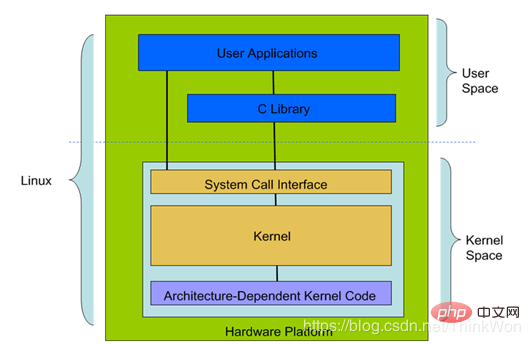 User Space (
User Space (User Space): User space also includes user applications (User Applications) and C library (C Library ).
Kernel Space (Kernel Space): Kernel space also includes system call interface (System Call Interface), kernel (Kernel), and platform Architecture-Dependent Kernel Code.
- Modern CPU implements different working modes. In different modes, the instructions that the CPU can execute and the registers it accesses are different.
- Linux from the perspective of the CPU, in order to protect the security of the kernel, the system is divided into two parts.
The main differences between BASH and DOS consoles lie in 3 aspects:
BASH commands are case-sensitive, while DOS commands are not; Under BASH,/ characteris the directory separator, \ serves as the escape character. UnderDOS, / is used as the command parameter separator and \ is the directory separatorOS follows the convention in naming files, which is an 8-character file name Followed by a dot, the extension is 3 characters. BASHdoes not follow such a convention.
Linux startup process?
1. The host performs power-on self-test and loads BIOS hardware information. 2. Read the boot file (GRUB, LILO) of MBR. 3. Boot the Linux kernel. 4. Run the first process init (the process number is always 1). 5. Enter the corresponding run level. 6. Run the terminal and enter your username and password.
What is the default run level of Linux system?
Shut down. Standalone user mode. Multi-user mode for character interface (network not supported). Multi-user mode for character interface. Not allocated for use. Multi-user mode for graphical interface. Restart.
What inter-process communication method does Linux use?
Pipe, stream pipe (s_pipe), named pipe (FIFO) Signal (signal) Message Queue Shared Memory Semaphore Socket
What system log files does Linux have?
The more important thing is the /var/log/messageslog file.
This log file is a summary of many process log files, from which any intrusion attempts or successful intrusions can be seen. In addition, if there is a centralized collection of ELK logs in your system, it will also be collected.
Is it helpful to install multiple desktop environments on a Linux system?
Usually, a desktop environment such as KDE or Gnome is enough to run without problems. Although the system allows switching from one environment to another, this is a priority for the user. Some programs work in one environment but not in another, so it can also be considered a factor in choosing which environment to use.
What is swap space?
Swap space is a certain space used by Linux to temporarily save some concurrently running programs. This happens when the RAM does not have enough memory to hold all the programs being executed.
What is the root account
The root account is like a system administrator account, allowing you to have full control over the system. Here you can create and maintain user accounts, assigning different permissions to each account. This is the default account every time you install Linux.
What is LILO?
LILO is the boot loader for Linux. It is mainly used to load the Linux operating system into main memory so that it can start running.
What is BASH?
BASH is the abbreviation of Bourne Again SHell. It was written by Steve Bourne as a replacement for the original Bourne Shell (represented by /bin/sh). It combines all the features of the original version of Bourne Shell, plus additional features to make it even easier to use. Since then, it has been adapted as the default shell on most systems running Linux.
What is CLI?
Command-line interface (English**: command-line interface**, abbreviation]: CLI) was the most widely used user interface before the popularity of graphical user interfaces. It usually does not Supports mouse, the user inputs instructions through the keyboard, and the computer executes the instructions after receiving them. Some people also call it Character User Interface (CUI). It is generally believed that the command line interface (CLI) is not as user-friendly as the graphical user interface (GUI). Because command line interface software usually requires the user to memorize the operating commands, however, due to its own characteristics, the command line interface saves computer system resources compared to the graphical user interface. Under the premise of memorizing the commands, using the command line interface is often faster than using the graphical user interface. Therefore, operating systems with graphical user interfaces retain optional command line interfaces.
What is GUI?
Graphical User Interface (Graphical User Interface, GUI for short, also known as graphical user interface) refers to a computer operation user interface displayed graphically. A graphical user interface is an interface display format for human-computer communication that allows users to use input devices such as a mouse to manipulate icons or menu options on the screen to select commands, call files, start programs, or perform other daily tasks. Graphical user interfaces have many advantages over character interfaces that use the keyboard to enter text or character commands to complete routine tasks.
What are the advantages of open source?
Open source allows you to distribute software (including source code) for free to anyone who is interested. People can then add features and even debug and correct errors in the source code. They can even make it run better and then freely redistribute the source code with these enhancements again. This ultimately benefits everyone in the community.
What is the importance of the GNU project?
This so-called free software movement offers several advantages, such as the freedom to run programs and the freedom to learn and modify them to suit your needs. It also allows you to redistribute copies of the software to others, as well as freely improve the software and release it to the public.
2. Disk, directory, file
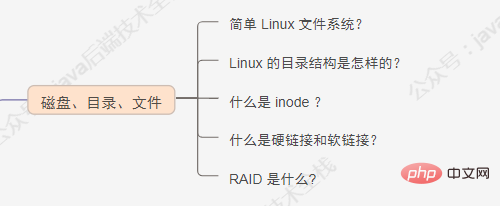
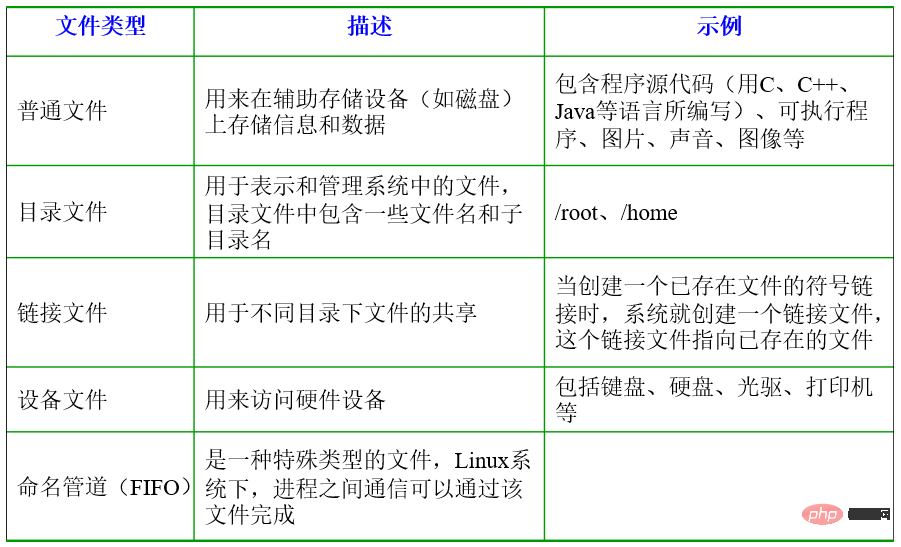
In the Linux operating system, all resources managed by the operating system, such as network interface cards, disk drives, printers, input and output devices, ordinary files or directories are regarded as a file. In other words, there is an important concept in the Linux system: everything is a file. In fact, this is a manifestation of the Unix philosophy, and Linux was rewritten from Unix, so this concept has been passed down. In Unix systems, all resources are regarded as files, including hardware devices. The UNIX system treats each piece of hardware as a file, usually called a device file, so that users can access the hardware by reading and writing files. Linux supports 5 file types, as shown in the figure below:
 img
imgThis question is generally not asked. More is needed to know for actual use. The Linux file system has a distinct structure, like an inverted tree, with the root directory at the top:
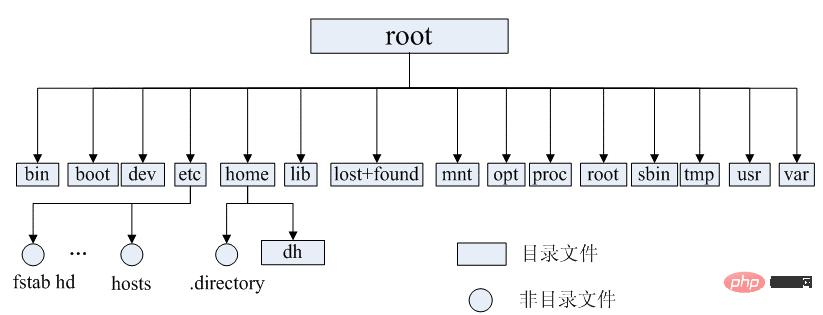 ##Common directory description:
##Common directory description:
/bin: stores binary executable files (ls, cat, mkdir, etc.), commonly used commands are generally here; /etc : Stores system management and configuration files; /home: The root directory where all user files are stored, which is the basis of the user's home directory. For example, the home directory of user user is /home/user. Can be represented by ~user; /usr: used to store system applications/opt: the location where additional installed optional application packages are placed. Under normal circumstances, we can install tomcat, etc. here; /proc: virtual file system directory, which is the mapping of system memory. You can directly access this directory to obtain system information; /root: the home directory of the super user (system administrator) (privileged class o); /sbin: Stores binary executable files, which can only be accessed by root. Stored here are system-level management commands and programs used by system administrators. Such as ifconfig, etc.; /dev: used to store device files; /mnt: the installation point where the system administrator installs the temporary file system , the system provides this directory to allow users to temporarily mount other file systems; /boot: stores various files used during system boot; **/lib **: Stores library files related to system operation; /tmp: Used to store various temporary files, which are public temporary files Storage point; /var: used to store files that need to change data during operation. It is also an overflow area for some large files, such as log files of various services (system startup logs etc.) etc.; /lost found: This directory is usually empty. The system shuts down abnormally and leaves a "homeless" file (what is it called under Windows. chk )right here.
What is an inode?
Generally speaking, inode will not be asked in interviews. But inode is an important concept and is the basis for understanding the Unix/Linux file system and hard disk storage. To understand inode, we must start with file storage. Files are stored on the hard disk, and the smallest storage unit of the hard disk is called "sector" (Sector). Each sector stores 512 bytes (equivalent to 0.5KB). When the operating system reads the hard disk, it does not read it sector by sector, which is too inefficient. Instead, it reads multiple sectors continuously at one time, that is, it reads one "block" at a time. This "block" consisting of multiple sectors is the smallest unit of file access. The most common size of "block" is 4KB, that is, eight consecutive sectors form a block.File data is stored in "blocks", so obviously we must also find a place to store the meta-information of the file, such as the creator of the file, the creation date of the file, the size of the file, etc. This area that stores file metainformation is called inode, which is translated into Chinese as "index node". Each file has a corresponding inode, which contains some information related to the file. Briefly describe the working process of the Linux file system to convert the logical structure and physical structure of the file through the i-node? Generally speaking, interviewers are unlikely to ask this question. Linux converts the logical structure and physical structure of the file through the inode node table. · The inode node is a 64-byte long table. The table contains file-related information, including important information such as file size, file owner, file access permission method, and file type. . The most important content in the inode node table is the disk address table. There are 13 block numbers in the disk address table, and the file will read the corresponding blocks in the order in which the block numbers appear in the disk address table. · The Linux file system connects the inode node and the file name. When the file needs to be read, the file system searches for the entry corresponding to the file name in the current directory table, thereby obtaining the corresponding file The inode node number is used to connect the scattered physical blocks of the file into the logical structure of the file through the disk address table of the inode node.
What are hard links and soft links?
1) Hard link Since files under Linux identify files by index nodes (inodes), a hard link can be thought of as a pointer, a pointer to the file index node, and the system does not reallocate the inode for it. Each time a hard link is added, the number of links to the file is increased by 1. Disadvantages: 1) Links cannot be established between files in different file systems; 2) Only super users can create hard links for directories. 2) Soft link Soft links overcome the shortcomings of hard links and do not have any file system restrictions. Any user can create a symbolic link pointing to a directory. As a result, it is now more widely used, has greater flexibility, and can even link files across different machines and different networks.
Shortcomings: Because the link file contains the path information of the original file, when the original file is moved from one directory to another directory and the link file is accessed again, the system cannot find it, and hard links do not have this The disadvantage is that you can move it however you want; it also requires the system to allocate additional space for creating new index nodes and saving the path of the original file. In actual scenarios, soft links are basically used. The summary of the differences is as follows: · Hard links cannot cross partitions, but software links can cross partitions. · A hard link points to an inode node, while a soft link creates a new inode node. · Deleting a hard link file will not delete the original file. Deleting a soft link file will delete the original file.
We have compiled a summary series of core knowledge of back-end technology
What is RAID?
RAID stands for Redundant Array of Independent Disks. The basic idea is to combine multiple relatively cheap hard drives into a hard drive array group, so that the performance can reach or even exceed that of an expensive, expensive hard drive. Huge capacity hard drive. RAID is usually used on server computers, using identical hard drives to form a logical sector, so the operating system will only treat it as one hard drive. RAID is divided into different levels, and each level makes different trade-offs in data reliability and read and write performance. In actual applications, you can choose different RAID solutions according to your actual needs. Of course, because many companies use cloud services, it is difficult for everyone to come into contact with the concept of RAID. It is more likely to be the concept of ordinary cloud disks and SSD cloud disks.
3. Safety

1. Add ordinary user login, prohibit root user login, and change the SSH port number. Modifying the SSH port is not necessarily absolute. Of course, if it is going to be exposed to the Internet, it is recommended to change it. 2. The server uses a key to log in, and password login is prohibited. 3. Turn on the firewall, turn off SElinux, and set corresponding firewall rules according to business needs. 4. Install fail2ban, a software that prevents SSH brute force attacks. 5. Set to allow only the company's office network export IP to log in to the server (depending on the company's actual needs). 6. Modify the number of historical command records to 10. 7. Only servers that need it are allowed to access the external network, and all others are prohibited. 8. Provide software-level protection.
Set the nginx_wafmodule to preventSQLinjection.Start the Web service as user www, and change the owner and group of the website directory towww
CC attacks are mainly used to attack pages, simulating multiple users to continuously access your pages, thereby exhausting your system resources. A DDOS attack, also known as a distributed denial-of-service attack in Chinese, refers to the use of server technology to unite multiple computers as an attack platform to launch
DDOS attacks against one or more targets. An attack is to occupy a large amount of network resources through a large number of legitimate requests to achieve the purpose of paralyzing the network. How to prevent CC attacks and DDOS attacks? To prevent CC and DDOS attacks, you can only use hardware firewalls to clean the traffic and introduce the attack traffic into the black hole. For traffic cleaning, you mainly need to buy the anti-attack service from the ISP service provider. The computer room usually has spare traffic, so we usually buy the service. After all, the attack will not last for a long time.
Due to the uneven level and experience of programmers, most programmers do not judge the legality of user input data when writing code. The application has security risks. The user can submit a database query code and obtain some data he wants to know based on the results returned by the program. This is the so-called SQL injection.
SQL注入,是从正常的 WWW端口访问,而且表面看起来跟一般的 Web 页面访问没什么区别,如果管理员没查看日志的习惯,可能被入侵很长时间都不会发觉。如何过滤与预防?数据库网页端注入这种,可以考虑使用 nginx_waf做过滤与预防。
四、Shell脚本

Shell 脚本是什么?
一个 Shell 脚本是一个文本文件,包含一个或多个命令。作为系统管理员,我们经常需要使用多个命令来完成一项任务,我们可以添加这些所有命令在一个文本文件(Shell 脚本)来完成这些日常工作任务。- 什么是默认登录 Shell ?在 Linux 操作系统,"/bin/bash"是默认登录Shell,是在创建用户时分配的。
使用 chsh 命令可以改变默认的 Shell 。示例如下所示:
## chsh <用户名> -s <新shell> ## chsh ThinkWon -s /bin/sh
-在 Shell 脚本中,如何写入注释?注释可以用来描述一个脚本可以做什么和它是如何工作的。每一行注释以 # 开头。例子如下:
#!/bin/bash ## This is a command echo “I am logged in as $USER”
可以在 Shell 脚本中使用哪些类型的变量?
在 Shell 脚本,我们可以使用两种类型的变量:系统定义变量:系统变量是由系统系统自己创建的。这些变量通常由大写字母组成,可以通过 set 命令查看。用户定义变量:用户变量由系统用户来生成和定义,变量的值可以通过命令 "echo $<变量名>" 查看。
Shell脚本中 $? 标记的用途是什么?
在写一个 Shell 脚本时,如果你想要检查前一命令是否执行成功,在 if 条件中使用 $? 可以来检查前一命令的结束状态。· 如果结束状态是 0 ,说明前一个命令执行成功。例如:
root@localhost:~## ls /usr/bin/shar
/usr/bin/shar
root@localhost:~## echo $?
0· 如果结束状态不是0,说明命令执行失败。例如:
root@localhost:~## ls /usr/bin/share
ls: cannot access /usr/bin/share: No such file or directory
root@localhost:~## echo $?
2Bourne Shell(bash) 中有哪些特殊的变量?
下面的表列出了 Bourne Shell 为命令行设置的特殊变量。
内建变量 解释 $0 命令行中的脚本名字 $1 第一个命令行参数 $2 第二个命令行参数 ….. ……. $9 第九个命令行参数 $## 命令行参数的数量 $* 所有命令行参数,以空格隔开
如何取消变量或取消变量赋值?
unset 命令用于取消变量或取消变量赋值。语法如下所示:
## unset <变量名>
Shell 脚本中 if 语法如何嵌套?
if [ 条件 ] then 命令1 命令2 ….. else if [ 条件 ] then 命令1 命令2 …. else 命令1 命令2 ….. fi fi
在 Shell 脚本中如何比较两个数字?
在 if-then 中使用测试命令( -gt 等)来比较两个数字。例如:
#!/bin/bash x=10 y=20 if [ $x -gt $y ] then echo “x is greater than y” else echo “y is greater than x” fi
Shell 脚本中 case 语句的语法?
基础语法如下:
case 变量 in 值1) 命令1 命令2 ….. 最后命令 !! 值2) 命令1 命令2 …… 最后命令 ;; esac
Shell 脚本中 for 循环语法?
基础语法如下:
for 变量 in 循环列表 do 命令1 命令2 …. 最后命令 done
Shell脚本中 while 循环语法?
· 如同for 循环,while循环只要条件成立就重复它的命令块。· 不同于 for循环,while 循环会不断迭代,直到它的条件不为真。
基础语法:
while [ 条件 ] do 命令… done
do-while 语句的基本格式?
do-while语句类似于 while 语句,但检查条件语句之前先执行命令(LCTT译注:意即至少执行一次。)。下面是用do-while语句的语法:
do
{
命令
} while (条件)Shell 脚本中 break 命令的作用?
break 命令一个简单的用途是退出执行中的循环。我们可以在 while 和 until 循环中使用 break 命令跳出循环。
Shell 脚本中 continue 命令的作用?
continue 命令不同于 break 命令,它只跳出当前循环的迭代,而不是整个循环。continue 命令很多时候是很有用的,例如错误发生,但我们依然希望继续执行大循环的时候。
如何使脚本可执行?
使用 chmod 命令来使脚本可执行。例子如下:chmod a+x myscript.sh。
#!/bin/bash 的作用?
#!/bin/bash 是 Shell 脚本的第一行,称为释伴(shebang)行。
这里 # 符号叫做 hash ,而 ! 叫做 bang。
它的意思是命令通过 /bin/bash 来执行。如何调试 Shell脚本?
使用-x数(sh -x myscript.sh)可以调试 Shell脚本。另一个种方法是使用 -nv 参数(sh -nv myscript.sh)。
如何将标准输出和错误输出同时重定向到同一位置?
方法一:2>&1 (如## ls /usr/share/doc > out.txt 2>&1) 。方法二:&> (如## ls /usr/share/doc &> out.txt) 。
在 Shell 脚本中,如何测试文件?
test 命令可以用来测试文件。基础用法如下表格:
Test 用法 -d 文件名 如果文件存在并且是目录,返回true -e 文件名 如果文件存在,返回true -f 文件名 如果文件存在并且是普通文件,返回true -r 文件名 如果文件存在并可读,返回true -s 文件名 如果文件存在并且不为空,返回true -w 文件名 如果文件存在并可写,返回true -x 文件名 如果文件存在并可执行,返回true
在 Shell 脚本如何定义函数呢?
函数是拥有名字的代码块。当我们定义代码块,我们就可以在我们的脚本调用函数名字,该块就会被执行。示例如下所示:
$ diskusage () { df -h ; }
译注:下面是我给的shell函数语法,原文没有
[ function ] 函数名 [()]
{
命令;
[return int;]
}如何让 Shell 就脚本得到来自终端的输入?
read 命令可以读取来自终端(使用键盘)的数据。read 命令得到用户的输入并置于你给出的变量中。例子如下:
## vi /tmp/test.sh #!/bin/bash echo ‘Please enter your name’ read name echo “My Name is $name” ## ./test.sh Please enter your name ThinkWon My Name is ThinkWon
如何执行算术运算?
有两种方法来执行算术运算:
1. Use the 要求:· 删除所有空行。· 一行中,如果包含 一般来讲,桌面用户首选 Ubuntu ;服务器首选 RHEL 或 CentOS ,两者中首选 CentOS 。根据具体要求: · 安全性要求较高,则选择 Debian 或者 FreeBSD 。· 需要使用数据库高级服务和电子邮件网络应用的用户可以选择 SUSE 。· 想要新技术新功能可以选择 Feddora ,Feddora 是 RHEL 和 CentOS 的一个测试版和预发布版本。·【重点】根据现有状况,绝大多数互联网公司选择 CentOS 。现在比较常用的是 6 系列,现在市场占有大概一半左右。另外的原因是 CentOS 更侧重服务器领域,并且无版权约束。 CentOS 7 系列,也慢慢使用的会比较多了。 - 有哪些方面的因素会导致网站网站访问慢?1、服务器出口带宽不够用,本身服务器购买的出口带宽比较小。一旦并发量大的话,就会造成分给每个用户的出口带宽就小,访问速度自然就会慢。跨运营商网络导致带宽缩减。例如,公司网站放在电信的网络上,那么客户这边对接是长城宽带或联通,这也可能导致带宽的缩减。 2、服务器负载过大,导致响应不过来 可以从两个方面入手分析:分析系统负载,使用 w 命令或者 uptime 命令查看系统负载。如果负载很高,则使用 top 命令查看 CPU ,MEM 等占用情况,要么是 CPU 繁忙,要么是内存不够。 如果这二者都正常,再去使用 sar 命令分析网卡流量,分析是不是遭到了攻击。一旦分析出问题的原因,采取对应的措施解决,如决定要不要杀死一些进程,或者禁止一些访问等。 3、数据库瓶颈
如果慢查询比较多。那么就要开发人员或 DBA 协助进行 SQL 语句的优化。如果数据库响应慢,考虑可以加一个数据库缓存,如 Redis 等。然后,也可以搭建 MySQL 主从,一台 MySQL 服务器负责写,其他几台从数据库负责读。4、网站开发代码没有优化好
例如 SQL 语句没有优化,导致数据库读写相当耗时。- 针对网站访问慢,怎么去排查?1、首先要确定是用户端还是服务端的问题。当接到用户反馈访问慢,那边自己立即访问网站看看,如果自己这边访问快,基本断定是用户端问题,就需要耐心跟客户解释,协助客户解决问题。不要上来就看服务端的问题。一定要从源头开始,逐步逐步往下。2、如果访问也慢,那么可以利用浏览器的调试功能,看看加载那一项数据消耗时间过多,是图片加载慢,还是某些数据加载慢。3、针对服务器负载情况。查看服务器硬件(网络、CPU、内存)的消耗情况。如果是购买的云主机,比如阿里云,可以登录阿里云平台提供各方面的监控,比如 CPU、内存、带宽的使用情况。4、如果发现硬件资源消耗都不高,那么就需要通过查日志,比如看看 MySQL慢查询的日志,看看是不是某条 SQL 语句查询慢,导致网站访问慢。 - 怎么去解决?1、如果是出口带宽问题,那么久申请加大出口带宽。2、如果慢查询比较多,那么就要开发人员或 DBA 协助进行 SQL 语句的优化。3、如果数据库响应慢,考虑可以加一个数据库缓存,如 Redis 等等。然后也可以搭建MySQL 主从,一台 MySQL 服务器负责写,其他几台从数据库负责读。4、申请购买 CDN 服务,加载用户的访问。5、如果访问还比较慢,那就需要从整体架构上进行优化咯。做到专角色专用,多台服务器提供同一个服务。 1、Disabling daemons (关闭 daemons)。2、Shutting down the GUI (关闭 GUI)。3、Changing kernel parameters (改变内核参数)。4、Kernel parameters (内核参数)。5、Tuning the processor subsystem (处理器子系统调优)。6、Tuning the memory subsystem (内存子系统调优)。7、Tuning the file system (文件系统子系统调优)。8、Tuning the network subsystem(网络子系统调优)。 cat 命令用于连接文件并打印到标准输出设备上。cat 主要有三大功能:1.一次显示整个文件: 2.从键盘创建一个文件: 只能创建新文件,不能编辑已有文件。3.将几个文件合并为一个文件: -b 对非空输出行号
-n 输出所有行号 - 实例: (1)把 log2012.log 的文件内容加上行号后输入 log2013.log 这个文件里 (2)把 log2012.log 和 log2013.log 的文件内容加上行号(空白行不加)之后将内容附加到 log.log 里 (3)使用 here doc 生成新文件 (4)反向列示 第一列共有 10 个位置,第一个字符指定了文件类型。在通常意义上,一个目录也是一个文件。如果第一个字符是横线,表示是一个非目录的文件。如果是 d,表示是一个目录。从第二个字符开始到第十个 9 个字符,3 个字符一组,分别表示了 3 组用户对文件或者目录的权限。权限字符用横线代表空许可,r 代表只读,w 代表写,x 代表可执行。 常用参数: 权限范围: 权限代号: - 实例:(1)增加文件 t.log 所有用户可执行权限 (2)撤销原来所有的权限,然后使拥有者具有可读权限,并输出处理信息 (3)给 file 的属主分配读、写、执行(7)的权限,给file的所在组分配读、执行(5)的权限,给其他用户分配执行(1)的权限 (4)将 test 目录及其子目录所有文件添加可读权限 chown 将指定文件的拥有者改为指定的用户或组,用户可以是用户名或者用户 ID;组可以是组名或者组 ID;文件是以空格分开的要改变权限的文件列表,支持通配符。 - 实例: (1)改变拥有者和群组 并显示改变信息 (2)改变文件群组 (3)改变文件夹及子文件目录属主及属组为 mail 将源文件复制至目标文件,或将多个源文件复制至目标目录。注意:命令行复制,如果目标文件已经存在会提示是否覆盖,而在 shell 脚本中,如果不加 -i 参数,则不会提示,而是直接覆盖! - 实例:(1)复制 a.txt 到 test 目录下,保持原文件时间,如果原文件存在提示是否覆盖。 (2)为 a.txt 建议一个链接(快捷方式) 用于在文件树中查找文件,并作出相应的处理。命令格式: 命令参数: 命令选项: - 实例: (1)查找 48 小时内修改过的文件 (2)在当前目录查找 以 .log 结尾的文件。. 代表当前目录 (3)查找 /opt 目录下 权限为 777 的文件 (4)查找大于 1K 的文件 (5)查找等于 1000 字符的文件 -exec 参数后面跟的是 command 命令,它的终止是以 ; 为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。{} 花括号代表前面find查找出来的文件名。 head 用来显示档案的开头至标准输出中,默认 head 命令打印其相应文件的开头 10 行。 常用参数: 实例:(1)显示 1.log 文件中前 20 行 (2)显示 1.log 文件前 20 字节 (3)显示 t.log最后 10 行 less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动,而且 less 在查看之前不会加载整个文件。 常用命令参数: 实例: (1)ps 查看进程信息并通过 less 分页显示 (2)查看多个文件 可以使用 n 查看下一个,使用 p 查看前一个。 功能是为文件在另外一个位置建立一个同步的链接,当在不同目录需要该问题时,就不需要为每一个目录创建同样的文件,通过 ln 创建的链接(link)减少磁盘占用量。链接分类:软件链接及硬链接
软链接: 1.软链接,以路径的形式存在。类似于Windows操作系统中的快捷方式
2.软链接可以 跨文件系统 ,硬链接不可以
3.软链接可以对一个不存在的文件名进行链接
4.软链接可以对目录进行链接 硬链接: 1.硬链接,以文件副本的形式存在。但不占用实际空间。2.不允许给目录创建硬链接
3.硬链接只有在同一个文件系统中才能创建
需要注意:第一:ln命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化;第二:ln的链接又分软链接和硬链接两种,软链接就是ln –s 源文件 目标文件,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间,硬链接 ln 源文件 目标文件,没有参数-s, 它会在你选定的位置上生成一个和源文件大小相同的文件,无论是软链接还是硬链接,文件都保持同步变化。第三:ln指令用在链接文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,且最后的目的地并非是一个已存在的目录,则会出现错误信息。 常用参数: 实例: (1)给文件创建软链接,并显示操作信息 (2)给文件创建硬链接,并显示操作信息 (3)给目录创建软链接 实例:(1)查找和 (2)搜索 (3)查找 功能类似于 常用操作命令: 实例: (1)显示文件中从第3行起的内容 (2)在所列出文件目录详细信息,借助管道使每次显示 5 行 按空格显示下 5 行。 移动文件或修改文件名,根据第二参数类型(如目录,则移动文件;如为文件则重命令该文件)。当第二个参数为目录时,第一个参数可以是多个以空格分隔的文件或目录,然后移动第一个参数指定的多个文件到第二个参数指定的目录中。实例:(1)将文件 test.log 重命名为 (2)将文件 log1.txt,log2.txt,log3.txt 移动到根的 test3 目录中 (3)将文件 file1 改名为 file2,如果 file2 已经存在,则询问是否覆盖 (4)移动当前文件夹下的所有文件到上一级目录 删除一个目录中的一个或多个文件或目录,如果没有使用 实例: (1)删除任何 .log 文件,删除前逐一询问确认: (2)删除 test 子目录及子目录中所有档案删除,并且不用一一确认: (3)删除以 用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。常用参数: (1)循环读取逐渐增加的文件内容 后台运行:可使用 (查看日志) 参数说明:a 改变档案的读取时间记录。m 改变档案的修改时间记录。c 假如目的档案不存在,不会建立新的档案。与 --no-create 的效果一样。f 不使用,是为了与其他 unix 系统的相容性而保留。r 使用参考档的时间记录,与 --file 的效果一样。d 设定时间与日期,可以使用各种不同的格式。t 设定档案的时间记录,格式与 date 指令相同。–no-create 不会建立新档案。–help 列出指令格式。–version 列出版本讯息。 实例 使用指令"touch"修改文件"testfile"的时间属性为当前系统时间,输入如下命令: 首先,使用ls命令查看testfile文件的属性,如下所示: 执行指令"touch"修改文件属性以后,并再次查看该文件的时间属性,如下所示: 使用指令"touch"时,如果指定的文件不存在,则将创建一个新的空白文件。例如,在当前目录下,使用该指令创建一个空白文件"file",输入如下命令: Vim是从 vi 发展出来的一个文本编辑器。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。 打开文件并跳到第 10 行: 基本上 实例: (1)查找 locate 程序相关文件 (2)查找 locate 的源码文件 (3)查找 lcoate 的帮助文件 在 linux 要查找某个文件,但不知道放在哪里了,可以使用下面的一些命令来搜索: which 是在 PATH 就是指定的路径中,搜索某个系统命令的位置,并返回第一个搜索结果。使用 which 命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。 常用参数: 实例: (1)查看 ls 命令是否存在,执行哪个 (2)查看 which 3)查看 cd 查看当前 PATH 配置: 或使用 env 查看所有环境变量及对应值 强大的文本搜索命令,grep( 常用参数: grep 的规则表达式: 实例:(1)查找指定进程 (2)查找指定进程个数 (3)从文件中读取关键词 (4)从文件夹中递归查找以grep开头的行,并只列出文件 (5)查找非x开关的行内容 (6)显示包含 ed 或者 at 字符的内容行 wc(word count)功能为统计指定的文件中字节数、字数、行数,并将统计结果输出
命令格式: 命令参数: 实例:(1)查找文件的 行数 单词数 字节数 文件名 结果: (2)统计输出结果的行数 cd(changeDirectory) 命令语法: 说明:切换当前目录至 dirName。实例:(1)进入要目录 (2)进入 “home” 目录 (3)进入上一次工作路径 (4)把上个命令的参数作为cd参数使用。 显示磁盘空间使用情况。获取硬盘被占用了多少空间,目前还剩下多少空间等信息,如果没有文件名被指定,则所有当前被挂载的文件系统的可用空间将被显示。默认情况下,磁盘空间将以 1KB 为单位进行显示,除非环境变量 实例:(1)显示磁盘使用情况 (2)以易读方式列出所有文件系统及其类型 du 命令也是查看使用空间的,但是与 常用参数: 实例:(1)以易读方式显示文件夹内及子文件夹大小 (2)以易读方式显示文件夹内所有文件大小 (3)显示几个文件或目录各自占用磁盘空间的大小,还统计它们的总和 (4)输出当前目录下各个子目录所使用的空间 就是 list 的缩写,通过 ls 命令不仅可以查看 linux 文件夹包含的文件,而且可以查看文件权限(包括目录、文件夹、文件权限)查看目录信息等等。常用参数搭配: 实例:(1) 按易读方式按时间反序排序,并显示文件详细信息 (2) 按大小反序显示文件详细信息 (3)列出当前目录中所有以"t"开头的目录的详细内容 (4) 列出文件绝对路径(不包含隐藏文件) (5) 列出文件绝对路径(包含隐藏文件) mkdir 命令用于创建文件夹。可用选项:-m: 对新建目录设置存取权限,也可以用 chmod 命令设置;
-p: 可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不在的目录,即一次可以建立多个目录。实例:(1)当前工作目录下创建名为 t的文件夹 (2)在 tmp 目录下创建路径为 test/t1/t 的目录,若不存在,则创建: pwd 命令用于查看当前工作目录路径。实例:(1)查看当前路径 (2)查看软链接的实际路径 从一个目录中删除一个或多个子目录项,删除某目录时也必须具有对其父目录的写权限。注意:不能删除非空目录
实例:(1)当 parent 子目录被删除后使它也成为空目录的话,则顺便一并删除: ifconfig 用于查看和配置 Linux 系统的网络接口。查看所有网络接口及其状态: iptables ,是一个配置 Linux 内核防火墙的命令行工具。功能非常强大,对于我们开发来说,主要掌握如何开放端口即可。例如: 把来源 IP 为 192.168.1.101 访问本机 80 端口的包直接拒绝: 开启 80 端口,因为web对外都是这个端口 另外,要注意使用 Linux netstat命令用于显示网络状态。利用 语法 参数说明: -a或–all 显示所有连线中的Socket。-A<网络类型>或–<网络类型> 列出该网络类型连线中的相关地址。-c或–continuous 持续列出网络状态。-C或–cache 显示路由器配置的快取信息。-e或–extend 显示网络其他相关信息。-F或–fib 显示FIB。-g或–groups 显示多重广播功能群组组员名单。-h或–help 在线帮助。-i或–interfaces 显示网络界面信息表单。-l或–listening 显示监控中的服务器的Socket。-M或–masquerade 显示伪装的网络连线。-n或–numeric 直接使用IP地址,而不通过域名服务器。-N或–netlink或–symbolic 显示网络硬件外围设备的符号连接名称。-o或–timers 显示计时器。-p或–programs 显示正在使用Socket的程序识别码和程序名称。-r或–route 显示Routing Table。-s或–statistice 显示网络工作信息统计表。-t或–tcp 显示TCP传输协议的连线状况。-u或–udp 显示UDP传输协议的连线状况。-v或–verbose 显示指令执行过程。-V或–version 显示版本信息。-w或–raw 显示RAW传输协议的连线状况。-x或–unix 此参数的效果和指定"-A unix"参数相同。–ip或–inet 此参数的效果和指定"-A inet"参数相同。实例
如何查看系统都开启了哪些端口? 如何查看网络连接状况? 如何统计系统当前进程连接数?输入命令 严格来说,这个题目考验的是对 awk 的使用。首先,使用 Linux ping命令用于检测主机。执行ping指令会使用ICMP传输协议,发出要求回应的信息,若远端主机的网络功能没有问题,就会回应该信息,因而得知该主机运作正常。 指定接收包的次数 Linux telnet命令用于远端登入。执行telnet指令开启终端机阶段作业,并登入远端主机。语法 参数说明:-8 允许使用8位字符资料,包括输入与输出。-a 尝试自动登入远端系统。-b<主机别名> 使用别名指定远端主机名称。-c 不读取用户专属目录里的.telnetrc文件。-d 启动排错模式。-e<脱离字符> 设置脱离字符。-E 滤除脱离字符。-f 此参数的效果和指定"-F"参数相同。-F 使用Kerberos V5认证时,加上此参数可把本地主机的认证数据上传到远端主机。-k<域名> 使用Kerberos认证时,加上此参数让远端主机采用指定的领域名,而非该主机的域名。-K 不自动登入远端主机。-l<用户名称> 指定要登入远端主机的用户名称。-L 允许输出8位字符资料。-n<记录文件> 指定文件记录相关信息。-r 使用类似rlogin指令的用户界面。-S<服务类型> 设置telnet连线所需的IP TOS信息。-x 假设主机有支持数据加密的功能,就使用它。-X<认证形态> 关闭指定的认证形态。 实例
登录远程主机 显示或设定系统的日期与时间。命令参数: 实例:(1)显示下一天 (2)-d参数使用 显示系统内存使用情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。命令参数: 实例:(1)显示内存使用情况 (2)以总和的形式显示内存的使用信息 (3)周期性查询内存使用情况 发送指定的信号到相应进程。不指定型号将发送SIGTERM(15)终止指定进程。如果任无法终止该程序可用"-KILL" 参数,其发送的信号为SIGKILL(9) ,将强制结束进程,使用ps命令或者jobs 命令可以查看进程号。root用户将影响用户的进程,非root用户只能影响自己的进程。 常用参数: 实例:(1)先使用ps查找进程pro1,然后用kill杀掉 ps(process status),用来查看当前运行的进程状态,一次性查看,如果需要动态连续结果使用 top
linux上进程有5种状态:
\1. 运行(正在运行或在运行队列中等待)
\2. 中断(休眠中, 受阻, 在等待某个条件的形成或接受到信号)
\3. 不可中断(收到信号不唤醒和不可运行, 进程必须等待直到有中断发生)
\4. 僵死(进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放)
\5. 停止(进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行运行)
ps 工具标识进程的5种状态码: 命令参数: 实例:(1)显示当前所有进程环境变量及进程间关系 (2)显示当前所有进程 (3)与grep联用查找某进程 (4)找出与 cron 与 syslog 这两个服务有关的 PID 号码 Linux rpm 命令用于管理套件。rpm(redhat package manager) 原本是 Red Hat Linux 发行版专门用来管理 Linux 各项套件的程序,由于它遵循 GPL 规则且功能强大方便,因而广受欢迎。逐渐受到其他发行版的采用。RPM 套件管理方式的出现,让 Linux 易于安装,升级,间接提升了 Linux 的适用度。 显示当前系统正在执行的进程的相关信息,包括进程 ID、内存占用率、CPU 占用率等
常用参数: 实例: 前五行是当前系统情况整体的统计信息区。第一行,任务队列信息,同 uptime 命令的执行结果,具体参数说明情况如下: 14:06:23 — 当前系统时间
up 70 days, 16:44 — 系统已经运行了70天16小时44分钟(在这期间系统没有重启过的吆!)
2 users — 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。第二行,Tasks — 任务(进程),具体信息说明如下:系统现在共有206个进程,其中处于运行中的有1个,205个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。第三行,cpu状态信息,具体属性说明如下: 备注:在这里CPU的使用比率和windows概念不同,需要理解linux系统用户空间和内核空间的相关知识!第四行,内存状态,具体信息如下: 第五行,swap交换分区信息,具体信息说明如下: 第六行,空行。第七行以下:各进程(任务)的状态监控,项目列信息说明如下: top 交互命令 yum( Yellow dog Updater, Modified)是一个在Fedora和RedHat以及SUSE中的Shell前端软件包管理器。基於RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软体包,无须繁琐地一次次下载、安装。yum提供了查找、安装、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记。1.列出所有可更新的软件清单命令:yum check-update
2.更新所有软件命令:yum update
3.仅安装指定的软件命令:yum install 创建 *.bz2 压缩文件: 创建一个 *.gz 的压缩文件: 用来压缩和解压文件。tar 本身不具有压缩功能,只具有打包功能,有关压缩及解压是调用其它的功能来完成。弄清两个概念:打包和压缩。打包是指将一大堆文件或目录变成一个总的文件;压缩则是将一个大的文件通过一些压缩算法变成一个小文件
常用参数: 有关 gzip 及 bzip2 压缩: 实例:(1)将文件全部打包成 tar 包 (2)将 /etc 下的所有文件及目录打包到指定目录,并使用 gz 压缩 (3)查看刚打包的文件内容(一定加z,因为是使用 gzip 压缩的) (4)要压缩打包 /home, /etc ,但不要 /home/dmtsaiexpr command: ## expr 5 2.2. Use a dollar sign and square brackets (五、编程题

判断一文件是不是字符设备文件,如果是将其拷贝到 /dev 目录下?
#!/bin/bash
read -p "Input file name: " FILENAME
if [ -c "$FILENAME" ];then
cp $FILENAME /dev
fi
添加一个新组为 class1 ,然后添加属于这个组的 30 个用户,用户名的形式为 stdxx ,其中 xx 从 01 到 30 ?
#!/bin/bash
groupadd class1
for((i=1;i<31;i++))
do
if [ $i -le 10 ];then
useradd -g class1 std0$i
else
useradd -g class1 std$i
fi
done编写 Shell 程序,实现自动删除 50 个账号的功能,账号名为stud1 至 stud50 ?
#!/bin/bash
for((i=1;i<51;i++))
do
userdel -r stud$i
done写一个 sed 命令,修改 /tmp/input.txt 文件的内容?
“11111”,则在“11111”前面插入“AAA”,在“11111”后面插入 “BBB” 。比如:将内容为 0000111112222 的一行改为 0000AAA11111BBB2222 。[root@~]## cat -n /tmp/input.txt
1 000011111222
2
3 000011111222222
4 11111000000222
5
6
7 111111111111122222222222
8 2211111111
9 112222222
10 1122
11
## 删除所有空行命令
[root@~]## sed '/^$/d' /tmp/input.txt
000011111222
000011111222222
11111000000222
111111111111122222222222
2211111111
112222222
1122
## 插入指定的字符
[root@~]## sed 's#\(11111\)#AAA\1BBB#g' /tmp/input.txt
0000AAA11111BBB222
0000AAA11111BBB222222
AAA11111BBB000000222
AAA11111BBBAAA11111BBB11122222222222
22AAA11111BBB111
112222222
1122六、实战

如何选择 Linux 操作系统版本?
如何规划一台 Linux 主机,步骤是怎样
请问当用户反馈网站访问慢,如何处理?
Linux 性能调优都有哪几种方法?
七、文件管理命令

熟悉cat 命令吗
cat filename
cat > filename
cat file1 file2 > file
cat -n log2012.log log2013.log
cat -b log2012.log log2013.log log.log
cat >log.txt <<EOF
>Hello
>World
>PWD=$(pwd)
>EOF
ls -l log.txt
cat log.txt
Hello
World
PWD=/opt/soft/test
tac log.txt
PWD=/opt/soft/test
World
Hello
chmod 命令是用来干什么的?
Linux/Unix 的文件调用权限分为三级 : 文件拥有者、群组、其他。利用 chmod 可以控制文件如何被他人所调用。用于改变 linux 系统文件或目录的访问权限。用它控制文件或目录的访问权限。该命令有两种用法。一种是包含字母和操作符表达式的文字设定法;另一种是包含数字的数字设定法。每一文件或目录的访问权限都有三组,每组用三位表示,分别为文件属主的读、写和执行权限;与属主同组的用户的读、写和执行权限;系统中其他用户的读、写和执行权限。可使用 ls -l test.txt 查找。以文件 log2012.log 为例:-rw-r--r-- 1 root root 296K 11-13 06:03 log2012.log
-c 当发生改变时,报告处理信息
-R 处理指定目录以及其子目录下所有文件
u :目录或者文件的当前的用户
g :目录或者文件的当前的群组
o :除了目录或者文件的当前用户或群组之外的用户或者群组
a :所有的用户及群组
r :读权限,用数字4表示
w :写权限,用数字2表示
x :执行权限,用数字1表示
- :删除权限,用数字0表示
s :特殊权限
chmod a+x t.log
chmod u=r t.log -c
chmod 751 t.log -c(或者:chmod u=rwx,g=rx,o=x t.log -c)
chmod u+r,g+r,o+r -R text/ -c
chown 命令 有用过吗
-c 显示更改的部分的信息
-R 处理指定目录及子目录
chown -c mail:mail log2012.log
chown -c :mail t.log
chown -cR mail: test/
熟悉cp 命令吗
-i 提示
-r 复制目录及目录内所有项目
-a 复制的文件与原文件时间一样
cp -ai a.txt test
cp -s a.txt link_a.txt
find 命令
find pathname -options [-print -exec -ok ...]
pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
-print:find命令将匹配的文件输出到标准输出。
-exec:find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为'command' { } \;,注意{ }和\;之间的空格。
-ok:和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。-name 按照文件名查找文件
-perm 按文件权限查找文件
-user 按文件属主查找文件
-group 按照文件所属的组来查找文件。
-type 查找某一类型的文件,诸如:
b - 块设备文件
d - 目录
c - 字符设备文件
l - 符号链接文件
p - 管道文件
f - 普通文件
find -atime -2
find ./ -name '*.log'
find /opt -perm 777
find -size +1000c
find -size +1000c
head 命令
find -size +1000c
head 1.log -n 20
head -c 20 log2014.log
head -n -10 t.log
less 命令
-i 忽略搜索时的大小写
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-s 显示连续空行为一行
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)
-x <数字> 将“tab”键显示为规定的数字空格
b 向后翻一页
d 向后翻半页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页
[pagedown]:向下翻动一页
[pageup]:向上翻动一页
ps -aux | less -N
less 1.log 2.log
ln 命令
-b 删除,覆盖以前建立的链接
-s 软链接(符号链接)
-v 显示详细处理过程
ln -sv source.log link.log
ln -v source.log link1.log
ln -sv /opt/soft/test/test3 /opt/soft/test/test5
locate 命令
locate 通过搜寻系统内建文档数据库达到快速找到档案,数据库由 updatedb 程序来更新,updatedb 是由 cron daemon 周期性调用的。默认情况下 locate 命令在搜寻数据库时比由整个由硬盘资料来搜寻资料来得快,但较差劲的是 locate所找到的档案若是最近才建立或 刚更名的,可能会找不到,在内定值中,updatedb 每天会跑一次,可以由修改 crontab 来更新设定值 (etc/crontab)。locate 与 find 命令相似,可以使用如 *、?等进行正则匹配查找
常用参数:-l num(要显示的行数)
-f 将特定的档案系统排除在外,如将proc排除在外
-r 使用正则运算式做为寻找条件
pwd相关的所有文件(文件名中包含 pwd)locate pwd
etc 目录下所有以 sh 开头的文件locate /etc/sh
/var 目录下,以 reason 结尾的文件locate -r '^/var.*reason$'(其中.表示一个字符,*表示任务多个;.*表示任意多个字符)
more 命令
cat, more 会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示。命令参数:+n 从笫 n 行开始显示
-n 定义屏幕大小为n行
+/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示
-c 从顶部清屏,然后显示
-d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能
-l 忽略Ctrl+l(换页)字符
-p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似
-s 把连续的多个空行显示为一行
-u 把文件内容中的下画线去掉
Enter 向下 n 行,需要定义。默认为 1 行
Ctrl+F 向下滚动一屏
空格键 向下滚动一屏
Ctrl+B 返回上一屏
= 输出当前行的行号
:f 输出文件名和当前行的行号
V 调用vi编辑器
!命令 调用Shell,并执行命令
q 退出more
more +3 text.txt
ls -l | more -5
mv 命令
test1.txtmv test.log test1.txt
mv llog1.txt log2.txt log3.txt /test3
mv -i log1.txt log2.txt
mv * ../
rm 命令
-r 选项,则 rm 不会删除目录。如果使用 rm 来删除文件,通常仍可以将该文件恢复原状。rm [选项] 文件…
rm -i *.log
rm -rf test
-f 开头的文件rm -- -f*
tail 命令
-f 循环读取(常用于查看递增的日志文件)
-n<行数> 显示行数(从后向前)
ping 127.0.0.1 > ping.log &
jobs -l查看,也可使用 fg 将其移到前台运行。tail -f ping.log
touch 命令
Linux touch命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。ls -l可以显示档案的时间记录。语法touch [-acfm][-d<日期时间>][-r<参考文件或目录>] [-t<日期时间>][--help][--version][文件或目录…]
$ touch testfile #修改文件的时间属性
$ ls -l testfile #查看文件的时间属性
#原来文件的修改时间为16:09
-rw-r--r-- 1 hdd hdd 55 2011-08-22 16:09 testfile
$ touch testfile #修改文件时间属性为当前系统时间
$ ls -l testfile #查看文件的时间属性
#修改后文件的时间属性为当前系统时间
-rw-r--r-- 1 hdd hdd 55 2011-08-22 19:53 testfile
$ touch file #创建一个名为“file”的新的空白文件
vim 命令
vim +10 filename.txt。打开文件跳到第一个匹配的行:vim +/search-term filename.txt。以只读模式打开文件:vim -R /etc/passwd 。vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode)。简单的说,我们可以将这三个模式想成底下的图标来表示:whereis 命令
whereis命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s)。如果省略参数,则返回所有信息。whereis及 locate 都是基于系统内建的数据库进行搜索,因此效率很高,而find则是遍历硬盘查找文件。常用参数:-b 定位可执行文件。
-m 定位帮助文件。
-s 定位源代码文件。
-u 搜索默认路径下除可执行文件、源代码文件、帮助文件以外的其它文件。
whereis locate
whereis -s locate
whereis -m locate
which 命令
which 查看可执行文件的位置。
whereis 查看文件的位置。
locate 配合数据库查看文件位置。
find 实际搜寻硬盘查询文件名称。
-n 指定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名。
which ls
which which
which cd(显示不存在,因为 cd 是内建命令,而 which 查找显示是 PATH 中的命令)
echo $PATH
八、文档编辑命令

grep 命令
Global Regular Expression Print) 全局正则表达式搜索。grep 的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。命令格式:grep [option] pattern file|dir
-A n --after-context显示匹配字符后n行
-B n --before-context显示匹配字符前n行
-C n --context 显示匹配字符前后n行
-c --count 计算符合样式的列数
-i 忽略大小写
-l 只列出文件内容符合指定的样式的文件名称
-f 从文件中读取关键词
-n 显示匹配内容的所在文件中行数
-R 递归查找文件夹
^ #锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ #锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
. #匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) #标记匹配字符,如'\(love\)',love被标记为1。
\< #锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> #锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。ps -ef | grep svn
ps -ef | grep svn -c
cat test1.txt | grep -f key.log
grep -lR '^grep' /tmp
grep '^[^x]' test.txt
grep -E 'ed|at' test.txt
wc 命令
wc [option] file..
-c 统计字节数
-l 统计行数
-m 统计字符数
-w 统计词数,一个字被定义为由空白、跳格或换行字符分隔的字符串
wc text.txt
7 8 70 test.txt
cat test.txt | wc -l
九、磁盘管理命令
cd 命令
cd [目录名]
cd /
cd ~
cd -
cd !$
df 命令
POSIXLY_CORRECT 被指定,那样将以512字节为单位进行显示:-a 全部文件系统列表
-h 以方便阅读的方式显示信息
-i 显示inode信息
-k 区块为1024字节
-l 只显示本地磁盘
-T 列出文件系统类型
df -l
df -haT
du 命令
df命令不同的是 Linux du命令是对文件和目录磁盘使用的空间的查看:命令格式:du [选项] [文件]
-a 显示目录中所有文件大小
-k 以KB为单位显示文件大小
-m 以MB为单位显示文件大小
-g 以GB为单位显示文件大小
-h 以易读方式显示文件大小
-s 仅显示总计
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和
du -h scf/
du -ah scf/
du -hc test/ scf/
du -hc --max-depth=1 scf/
ls命令
ls -a 列出目录所有文件,包含以.开始的隐藏文件
ls -A 列出除.及..的其它文件
ls -r 反序排列
ls -t 以文件修改时间排序
ls -S 以文件大小排序
ls -h 以易读大小显示
ls -l 除了文件名之外,还将文件的权限、所有者、文件大小等信息详细列出来
ls -lhrt
ls -lhrt
ls -l t*
ls | sed "s:^:`pwd`/:"
find $pwd -maxdepth 1 | xargs ls -ld
mkdir 命令
mkdir t
mkdir -p /tmp/test/t1/t
pwd 命令
pwd
pwd -P
rmdir 命令
rmdir -p parent/child/child11
十、网络通讯命令
ifconfig 命令
ifconfig -a 。使用 up 和 down 命令启动或停止某个接口:ifconfig eth0 up和 ifconfig eth0 down 。iptables 命令
iptables -I INPUT -s 192.168.1.101 -p tcp --dport 80 -j REJECT 。iptables -A INPUT -p tcp --dport 80 -j ACCEP
iptables save 命令,进行保存。否则,服务器重启后,配置的规则将丢失。netstat 命令
netstat指令可让你得知整个Linux系统的网络情况。netstat [-acCeFghilMnNoprstuvVwx][-A<网络类型>][--ip]
[root@centos6 ~ 13:20 #55]# netstat -lnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1035/sshd
tcp 0 0 :::22 :::* LISTEN 1035/sshd
udp 0 0 0.0.0.0:68 0.0.0.0:* 931/dhclient
Active UNIX domain sockets (only servers)
Proto RefCnt Flags Type State I-Node PID/Program name Path
unix 2 [ ACC ] STREAM LISTENING 6825 1/init @/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 8429 1003/dbus-daemon /var/run/dbus/system_bus_socket
[root@centos6 ~ 13:22 #58]# netstat -an
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 192.168.147.130:22 192.168.147.1:23893 ESTABLISHED
tcp 0 0 :::22 :::* LISTEN
udp 0 0 0.0.0.0:68 0.0.0.0:*
netstat -an | grep ESTABLISHED | wc -l。输出结果 177 。一共有 177 连接数。用 netstat 命令配合其他命令,按照源 IP 统计所有到 80 端口的 ESTABLISHED 状态链接的个数?netstat -an|grep ESTABLISHED 命令。结果如下:tcp 0 0 120.27.146.122:80 113.65.18.33:62721 ESTABLISHED
tcp 0 0 120.27.146.122:80 27.43.83.115:47148 ESTABLISHED
tcp 0 0 120.27.146.122:58838 106.39.162.96:443 ESTABLISHED
tcp 0 0 120.27.146.122:52304 203.208.40.121:443 ESTABLISHED
tcp 0 0 120.27.146.122:33194 203.208.40.122:443 ESTABLISHED
tcp 0 0 120.27.146.122:53758 101.37.183.144:443 ESTABLISHED
tcp 0 0 120.27.146.122:27017 23.105.193.30:50556 ESTABLISHED
ping 命令
ping -c 2 www.baidu.com
telnet 命令
telnet
[-8acdEfFKLrx][-b<主机别名>][-e<脱离字符>][-k<域名>][-l<用户名称>][-n<记录文件>][-S<服务类型>][-X<认证形态>][主机名称或IP地址<通信端口>]
# 登录IP为 192.168.0.5 的远程主机
telnet 192.168.0.5
十一、系统管理命令

date命令
-d<字符串> 显示字符串所指的日期与时间。字符串前后必须加上双引号。
-s<字符串> 根据字符串来设置日期与时间。字符串前后必须加上双引号。
-u 显示GMT。
%H 小时(00-23)
%I 小时(00-12)
%M 分钟(以00-59来表示)
%s 总秒数。起算时间为1970-01-01 00:00:00 UTC。
%S 秒(以本地的惯用法来表示)
%a 星期的缩写。
%A 星期的完整名称。
%d 日期(以01-31来表示)。
%D 日期(含年月日)。
%m 月份(以01-12来表示)。
%y 年份(以00-99来表示)。
%Y 年份(以四位数来表示)。
date +%Y%m%d --date="+1 day" //显示下一天的日期
date -d "nov 22" 今年的 11 月 22 日是星期三
date -d '2 weeks' 2周后的日期
date -d 'next monday' (下周一的日期)
date -d next-day +%Y%m%d(明天的日期)或者:date -d tomorrow +%Y%m%d
date -d last-day +%Y%m%d(昨天的日期) 或者:date -d yesterday +%Y%m%d
date -d last-month +%Y%m(上个月是几月)
date -d next-month +%Y%m(下个月是几月)
free 命令
-b 以Byte显示内存使用情况
-k 以kb为单位显示内存使用情况
-m 以mb为单位显示内存使用情况
-g 以gb为单位显示内存使用情况
-s<间隔秒数> 持续显示内存
-t 显示内存使用总合
free
free -k
free -m
free -t
free -s 10
kill 命令
-l 信号,若果不加信号的编号参数,则使用“-l”参数会列出全部的信号名称
-a 当处理当前进程时,不限制命令名和进程号的对应关系
-p 指定kill 命令只打印相关进程的进程号,而不发送任何信号
-s 指定发送信号
-u 指定用户
kill -9 $(ps -ef | grep pro1)
ps 命令
D 不可中断 uninterruptible sleep (usually IO)
R 运行 runnable (on run queue)
S 中断 sleeping
T 停止 traced or stopped
Z 僵死 a defunct (”zombie”) process
-A 显示所有进程
a 显示所有进程
-a 显示同一终端下所有进程
c 显示进程真实名称
e 显示环境变量
f 显示进程间的关系
r 显示当前终端运行的进程
-aux 显示所有包含其它使用的进程
ps -ef
ps -A
ps -aux | grep apache
ps aux | grep '(cron|syslog)'
rpm 命令
# 查看系统自带jdk
rpm -qa | grep jdk
# 删除系统自带jdk
rpm -e --nodeps 查看jdk显示的数据
# 安装jdk
rpm -ivh jdk-7u80-linux-x64.rpm
top 命令
-c 显示完整的进程命令
-s 保密模式
-p <进程号> 指定进程显示
-n <次数>循环显示次数
top - 14:06:23 up 70 days, 16:44, 2 users, load average: 1.25, 1.32, 1.35
Tasks: 206 total, 1 running, 205 sleeping, 0 stopped, 0 zombie
Cpu(s): 5.9%us, 3.4%sy, 0.0%ni, 90.4%id, 0.0%wa, 0.0%hi, 0.2%si, 0.0%st
Mem: 32949016k total, 14411180k used, 18537836k free, 169884k buffers
Swap: 32764556k total, 0k used, 32764556k free, 3612636k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28894 root 22 0 1501m 405m 10m S 52.2 1.3 2534:16 java
5.9%us — 用户空间占用CPU的百分比。
3.4% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
90.4% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.2% si — 软中断(Software Interrupts)占用CPU的百分比
32949016k total — 物理内存总量(32GB)
14411180k used — 使用中的内存总量(14GB)
18537836k free — 空闲内存总量(18GB)
169884k buffers — 缓存的内存量 (169M)
32764556k total — 交换区总量(32GB)
0k used — 使用的交换区总量(0K)
32764556k free — 空闲交换区总量(32GB)
3612636k cached — 缓冲的交换区总量(3.6GB)
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
h 显示top交互命令帮助信息
c 切换显示命令名称和完整命令行
m 以内存使用率排序
P 根据CPU使用百分比大小进行排序
T 根据时间/累计时间进行排序
W 将当前设置写入~/.toprc文件中
o或者O 改变显示项目的顺序
yum 命令
[root@www ~]# yum install pam-devel
十二、备份压缩命令
bzip2 命令
bzip2 test.txt 。解压 *.bz2 文件:bzip2 -d test.txt.bz2。gzip 命令
gzip test.txt 。解压 *.gz 文件:gzip -d test.txt.gz。显示压缩的比率:gzip -l *.gz 。tar 命令
-c 建立新的压缩文件
-f 指定压缩文件
-r 添加文件到已经压缩文件包中
-u 添加改了和现有的文件到压缩包中
-x 从压缩包中抽取文件
-t 显示压缩文件中的内容
-z 支持gzip压缩
-j 支持bzip2压缩
-Z 支持compress解压文件
-v 显示操作过程
gzip 实例:压缩 gzip fileName .tar.gz 和.tgz 解压:gunzip filename.gz 或 gzip -d filename.gz
对应:tar zcvf filename.tar.gz tar zxvf filename.tar.gz
bz2实例:压缩 bzip2 -z filename .tar.bz2 解压:bunzip filename.bz2或bzip -d filename.bz2
对应:tar jcvf filename.tar.gz 解压:tar jxvf filename.tar.bz2tar -cvf log.tar 1.log,2.log 或tar -cvf log.*
tar -zcvf /tmp/etc.tar.gz /etc
tar -ztvf /tmp/etc.tar.gz
tar --exclude /home/dmtsai -zcvf myfile.tar.gz /home/* /etc
unzip 命令
解压*.zip 文件:unzip test.zip查看 *.zip 文件的内容:unzip -l jasper.zip
Summary
This article has a total of 12 modules. For work, the most important ones are Shell and the last six modules. module.
Okay, that’s the end of today’s sharing. I hope these 100 Linux interview questions can help you get offers.
The above is the detailed content of It is recommended to collect 100 Linux interview questions with answers. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Interviewer: Spring Aop common annotations and execution sequence
Aug 15, 2023 pm 04:32 PM
Interviewer: Spring Aop common annotations and execution sequence
Aug 15, 2023 pm 04:32 PM
You must know Spring, so let’s talk about the order of all notifications of Aop. How does Spring Boot or Spring Boot 2 affect the execution order of aop? Tell us about the pitfalls you encountered in AOP?
 Interview with a certain group: If you encounter OOM online, how should you troubleshoot it? How to solve? What options?
Aug 23, 2023 pm 02:34 PM
Interview with a certain group: If you encounter OOM online, how should you troubleshoot it? How to solve? What options?
Aug 23, 2023 pm 02:34 PM
OOM means that there is a vulnerability in the program, which may be caused by the code or JVM parameter configuration. This article talks to readers about how to troubleshoot when a Java process triggers OOM.
 Ele.me's written test questions seem simple, but it stumps a lot of people
Aug 24, 2023 pm 03:29 PM
Ele.me's written test questions seem simple, but it stumps a lot of people
Aug 24, 2023 pm 03:29 PM
Don’t underestimate the written examination questions of many companies. There are pitfalls and you can fall into them accidentally. When you encounter this kind of written test question about cycles, I suggest you think calmly and take it step by step.
 Novices can also compete with BAT interviewers: CAS
Aug 24, 2023 pm 03:09 PM
Novices can also compete with BAT interviewers: CAS
Aug 24, 2023 pm 03:09 PM
The extra chapter of the Java concurrent programming series, C A S (Compare and swap), is still in an easy-to-understand style with pictures and texts, allowing readers to have a crazy conversation with the interviewer.
 Last week, I had an interview with XX Insurance and it was cool! ! !
Aug 25, 2023 pm 03:44 PM
Last week, I had an interview with XX Insurance and it was cool! ! !
Aug 25, 2023 pm 03:44 PM
Last week, a friend in the group went for an interview with Ping An Insurance. The result was a bit regretful, which is quite a pity, but I hope you don’t get discouraged. As you said, basically all the questions encountered in the interview can be solved by memorizing the interview questions. It’s solved, so please work hard!
 5 String interview questions, less than 10% of people can answer them all correctly! (with answer)
Aug 23, 2023 pm 02:49 PM
5 String interview questions, less than 10% of people can answer them all correctly! (with answer)
Aug 23, 2023 pm 02:49 PM
This article will take a look at 5 interview questions about the Java String class. I have personally experienced several of these five questions during the interview process. This article will help you understand why the answers to these questions are like this.

 Meituan interview: Please handwrite a quick schedule, I was shocked!
Aug 24, 2023 pm 03:20 PM
Meituan interview: Please handwrite a quick schedule, I was shocked!
Aug 24, 2023 pm 03:20 PM
Quick sort was proposed by C. A. R. Hoare in 1962. Its basic idea is to divide the data to be sorted into two independent parts through one sorting. All the data in one part is smaller than all the data in the other part, and then use this method to quickly separate the two parts of the data. Sorting, the entire sorting process can be performed [recursively], so that the entire data becomes an ordered sequence.
