
 Technology peripherals
AI
Build an LLM application: Leveraging the vector search capabilities of Azure Cognitive Services
Technology peripherals
AI
Build an LLM application: Leveraging the vector search capabilities of Azure Cognitive Services
Build an LLM application: Leveraging the vector search capabilities of Azure Cognitive Services

Author | Simon Bisson
curator | Ethan
Microsoft’s cognitive search API now offers vector search as a service for use with large language models in Azure OpenAI and more.
Tools such as Semantic Core, TypeChat and LangChain make it possible to build applications around generative AI technologies such as Azure OpenAI. This is because they allow constraints to be imposed on the underlying large language model (LLM), which can be used as a tool for building and running natural language interfaces
Essentially, an LLM is a tool for navigating a semantic space , where a deep neural network can predict the next syllable in a chain of tokens starting from the initial cue. If the prompt is open-ended, the LLM may exceed its input scope and produce something that seems reasonable but is actually complete nonsense.
Just as we tend to trust the output of search engines, we also tend to trust the output of LLM because we view them as another aspect of familiar technology. But training large language models using trusted data from sites like Wikipedia, Stack Overflow, and Reddit doesn't convey an understanding of the content; it simply gives the ability to generate text that follows the same patterns as the text in those sources. . Sometimes the output may be correct, but other times it may be wrong.
How do we avoid errors and meaningless output from large language models and ensure that our users get accurate and reasonable answers to their queries?
1. Limit large models with semantic memory constraints
What we need to do is limit LLM to ensure that it only generates text from smaller data sets. This is where Microsoft's new LLM-based development stack comes in. It provides the necessary tools to control your model and prevent it from generating errors
You can force a specific output format by using tools like TypeChat, or use orchestration pipelines like Semantic Kernel to handle other possible information source, thereby effectively "rooting" the model in the known semantic space, thus constraining the LLM. Here, LLM can do what it does well, summarize the constructed prompt and generate text based on that prompt, without overshooting (or at least significantly reducing the likelihood of overshooting).
What Microsoft calls "semantic memory" is the basis of the last method. Semantic memory uses vector search to provide hints that can be used to provide the factual output of the LLM. The vector database manages the context of the initial prompt, the vector search looks for stored data that matches the initial user query, and the LLM generates the text based on that data. See this approach in action in Bing Chat, which uses Bing's native vector search tools to build answers derived from its search database
Semantic memory enables vector databases and vector searches to be provided based on LLM means of application. You can choose to use one of the growing number of open source vector databases, or add vector indexes to your familiar SQL and NoSQL databases. One new product that looks particularly useful extends Azure Cognitive Search, adding a vector index to your data and providing a new API for querying that index
2. Adding vector indexes to Azure Cognitive Search
Azure Cognitive Search is built on Microsoft's own search tools. It provides a combination of familiar Lucene queries and its own natural language query tools. Azure Cognitive Search is a software-as-a-service platform that can host private data and access content using Cognitive Services APIs. Recently, Microsoft also added support for building and using vector indexes, which allows you to use similarity searches to rank relevant results in your data and use them in AI-based applications. This makes Azure Cognitive Search ideal for Azure-hosted LLM applications built with Semantic Kernel and Azure OpenAI, and Semantic Kernel plugins for Cognitive Search for C# and Python are also available
with other Azure Like services, Azure Cognitive Search is a managed service that works with other Azure services. It allows you to index and search across various Azure storage services, hosting text, images, audio and video. Data is stored in multiple regions, providing high availability and reducing latency and response times. Additionally, for enterprise applications, you can use Microsoft Entra ID (the new name for Azure Active Directory) to control access to private data
3. Generate and store embedding vectors for content
Required Note that Azure Cognitive Search is a "bring your own embedding vector" service. Cognitive Search won't generate the vector embeddings you need, so you need to use Azure OpenAI or the OpenAI embedding API to create embeddings for your content. This may require chunking large files to ensure you stay within the service's token limits. When needed, be prepared to create new tables to index vector data
In Azure Cognitive Search, vector search uses a nearest neighbor model to return a user-selected number of documents that are similar to the original query. This process calls vector indexing by using the vector embedding of the original query and returns similar vector and index content from the database ready for use by the LLM prompt
Microsoft uses this vector store as part of the Retrieval Augmented Generation (RAG) design pattern for Azure Machine Learning and in conjunction with its prompt flow tool. RAG leverages vector indexing in cognitive search to build the context that forms the basis of LLM prompts. This gives you a low-code way to build and use vector indexes, such as setting the number of similar documents returned by a query
4, Getting started with vector search in Azure Cognitive Search
Usage Azure Cognitive Search makes vector queries very easy. Start by creating resources for Azure OpenAI and Cognitive Search in the same region. This will allow you to load the search index with embeds with minimal latency. You need to call the Azure OpenAI API and Cognitive Search API to load the index, so it's a good idea to make sure your code can respond to any possible rate limits in the service for you by adding code that manages retries. When you use the service API, you should use asynchronous calls to generate embeds and load indexes.
Vectors are stored in search indexes as vector fields, where vectors are floating point numbers with dimensions. These vectors are mapped through a hierarchical navigable small-world neighborhood graph that sorts vectors into neighborhoods of similar vectors, speeding up the actual process of searching for vector indexes.
After defining the index schema for vector search, you can load data into the index for cognitive search. Note that data may be associated with multiple vectors. For example, if you use cognitive search to host company documents, you might have a separate vector for key document metadata terms and document content. The dataset must be stored as a JSON document, which simplifies the process of using the results to assemble prompt context. The index does not need to contain the source document as it supports using the most common Azure storage options
Before running the query, you need to first call the embedded model of your choice with the query body. This returns a multidimensional vector that you can use to search the index of your choice. When calling the vector search API, specify the target vector index, the desired number of matches, and the relevant text fields in the index. Choosing the appropriate similarity measure can be very helpful for queries, the most commonly used of which is the cosine metric
5. Beyond simple text vectors
Azure Cognitive Search’s vector capabilities go beyond just matching text . Cognitive Search can be used with multilingual embeddings to support document searches across multiple languages. You can also use more complex APIs. For example, you can mix Bing semantic search tools in Hybrid Search to provide more accurate results, thereby improving the quality of output from LLM-powered applications.
Microsoft is rapidly productizing the tools and technology it used to build its own GPT-4-based Bing search engine and various Copilots. Orchestration engines like Semantic Kernel and Azure AI Studio’s prompt flow are core to Microsoft’s approach to working with large language models. Now that those foundations have been laid, we're seeing the company roll out more of the necessary enabling technology. Vector search and vector indexing are key to providing accurate responses. By building familiar tools to deliver these services, Microsoft will help us minimize the cost and learning curve
The above is the detailed content of Build an LLM application: Leveraging the vector search capabilities of Azure Cognitive Services. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

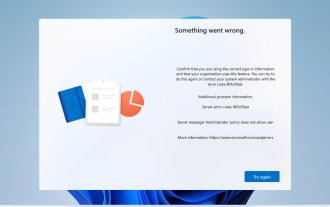 Error code 801c03ed: How to fix it on Windows 11
Oct 04, 2023 pm 06:05 PM
Error code 801c03ed: How to fix it on Windows 11
Oct 04, 2023 pm 06:05 PM
Error 801c03ed is usually accompanied by the following message: Administrator policy does not allow this user to join the device. This error message will prevent you from installing Windows and joining a network, thereby preventing you from using your computer, so it is important to resolve this issue as soon as possible. What is error code 801c03ed? This is a Windows installation error that occurs due to the following reason: Azure setup does not allow new users to join. Device objects are not enabled on Azure. Hardware hash failure in Azure panel. How to fix error code 03c11ed on Windows 801? 1. Check Intune settings Log in to Azure portal. Navigate to Devices and select Device Settings. Change "Users can
 Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Translator | Bugatti Review | Chonglou This article describes how to use the GroqLPU inference engine to generate ultra-fast responses in JanAI and VSCode. Everyone is working on building better large language models (LLMs), such as Groq focusing on the infrastructure side of AI. Rapid response from these large models is key to ensuring that these large models respond more quickly. This tutorial will introduce the GroqLPU parsing engine and how to access it locally on your laptop using the API and JanAI. This article will also integrate it into VSCode to help us generate code, refactor code, enter documentation and generate test units. This article will create our own artificial intelligence programming assistant for free. Introduction to GroqLPU inference engine Groq
 Caltech Chinese use AI to subvert mathematical proofs! Speed up 5 times shocked Tao Zhexuan, 80% of mathematical steps are fully automated
Apr 23, 2024 pm 03:01 PM
Caltech Chinese use AI to subvert mathematical proofs! Speed up 5 times shocked Tao Zhexuan, 80% of mathematical steps are fully automated
Apr 23, 2024 pm 03:01 PM
LeanCopilot, this formal mathematics tool that has been praised by many mathematicians such as Terence Tao, has evolved again? Just now, Caltech professor Anima Anandkumar announced that the team released an expanded version of the LeanCopilot paper and updated the code base. Image paper address: https://arxiv.org/pdf/2404.12534.pdf The latest experiments show that this Copilot tool can automate more than 80% of the mathematical proof steps! This record is 2.3 times better than the previous baseline aesop. And, as before, it's open source under the MIT license. In the picture, he is Song Peiyang, a Chinese boy. He is
 From 'human + RPA' to 'human + generative AI + RPA', how does LLM affect RPA human-computer interaction?
Jun 05, 2023 pm 12:30 PM
From 'human + RPA' to 'human + generative AI + RPA', how does LLM affect RPA human-computer interaction?
Jun 05, 2023 pm 12:30 PM
Image source@visualchinesewen|Wang Jiwei From "human + RPA" to "human + generative AI + RPA", how does LLM affect RPA human-computer interaction? From another perspective, how does LLM affect RPA from the perspective of human-computer interaction? RPA, which affects human-computer interaction in program development and process automation, will now also be changed by LLM? How does LLM affect human-computer interaction? How does generative AI change RPA human-computer interaction? Learn more about it in one article: The era of large models is coming, and generative AI based on LLM is rapidly transforming RPA human-computer interaction; generative AI redefines human-computer interaction, and LLM is affecting the changes in RPA software architecture. If you ask what contribution RPA has to program development and automation, one of the answers is that it has changed human-computer interaction (HCI, h
 Plaud launches NotePin AI wearable recorder for $169
Aug 29, 2024 pm 02:37 PM
Plaud launches NotePin AI wearable recorder for $169
Aug 29, 2024 pm 02:37 PM
Plaud, the company behind the Plaud Note AI Voice Recorder (available on Amazon for $159), has announced a new product. Dubbed the NotePin, the device is described as an AI memory capsule, and like the Humane AI Pin, this is wearable. The NotePin is
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 GraphRAG enhanced for knowledge graph retrieval (implemented based on Neo4j code)
Jun 12, 2024 am 10:32 AM
GraphRAG enhanced for knowledge graph retrieval (implemented based on Neo4j code)
Jun 12, 2024 am 10:32 AM
Graph Retrieval Enhanced Generation (GraphRAG) is gradually becoming popular and has become a powerful complement to traditional vector search methods. This method takes advantage of the structural characteristics of graph databases to organize data in the form of nodes and relationships, thereby enhancing the depth and contextual relevance of retrieved information. Graphs have natural advantages in representing and storing diverse and interrelated information, and can easily capture complex relationships and properties between different data types. Vector databases are unable to handle this type of structured information, and they focus more on processing unstructured data represented by high-dimensional vectors. In RAG applications, combining structured graph data and unstructured text vector search allows us to enjoy the advantages of both at the same time, which is what this article will discuss. structure
 Visualize FAISS vector space and adjust RAG parameters to improve result accuracy
Mar 01, 2024 pm 09:16 PM
Visualize FAISS vector space and adjust RAG parameters to improve result accuracy
Mar 01, 2024 pm 09:16 PM
As the performance of open source large-scale language models continues to improve, performance in writing and analyzing code, recommendations, text summarization, and question-answering (QA) pairs has all improved. But when it comes to QA, LLM often falls short on issues related to untrained data, and many internal documents are kept within the company to ensure compliance, trade secrets, or privacy. When these documents are queried, LLM can hallucinate and produce irrelevant, fabricated, or inconsistent content. One possible technique to handle this challenge is Retrieval Augmented Generation (RAG). It involves the process of enhancing responses by referencing authoritative knowledge bases beyond the training data source to improve the quality and accuracy of the generation. The RAG system includes a retrieval system for retrieving relevant document fragments from the corpus
