
 Java
JavaInterview questions
Last week, I had an interview with XX Insurance and it was cool! ! !
Java
JavaInterview questions
Last week, I had an interview with XX Insurance and it was cool! ! !
Last week, I had an interview with XX Insurance and it was cool! ! !
Last week, a friend in the group went to Ping An Insurance for an interview. The result was a bit regretful, which is quite a pity, but I hope you will not be discouraged. As you said, the problems encountered during the interview , basically all of them can be solved by memorizing the test questions, so please work hard!
In addition, if you have any questions, please feel free to come to me to discuss and make progress together.
Without going too far, let’s get into the topic. Here are the technical interview questions and reference answers compiled by this student.
What are the thread-safe classes in Java?
Vector, Hashtable, StringBuffer. They all add synchronization locks to their methods to achieve thread safety.
In addition, there are all collection classes under the JUC package
ArrayBlockingQueue, ConcurrentHashMap, ConcurrentLinkedQueue, ConcurrentLinkedDeque, etc., these are also thread-safe.
Fortunately, this is the end of the answer, and the interviewer didn't ask any more questions, otherwise I really wouldn't be able to answer these questions under JUC.
How many ways can Java create objects?
#This question is relatively simple. It can be said that the last 123 should be no problem.
Java provides the following four ways to create objects:
new creates a new object Through reflection mechanism Using clone mechanism Through the serialization mechanism
What are the common methods of Object?
#The answer to this question was not very good. At that time, I only remembered toString, equals, hashCode, wait, notify, and notifyAll. Didn't think of anything else. The interviewer kept nodding, giving the impression that it should be fine.
java.lang.Object
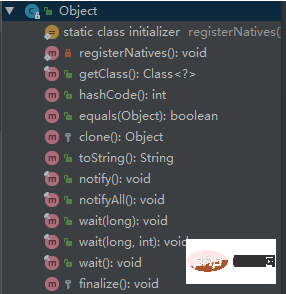
The following is the meaning of the corresponding method.
clone method
Protected method to implement shallow copy of the object. This method can only be called if the Cloneable interface is implemented. Otherwise, a CloneNotSupportedException exception will be thrown. Deep copy is also required. Implement Cloneable, and if its member variables are reference types, you also need to implement Cloneable, and then rewrite the clone method.
finalize method
This method is related to the garbage collector. The last step to determine whether an object can be recycled is to determine whether this method has been overridden.
equals method
This method is used very frequently. Generally equals and == are different, but in Object they are the same. Subclasses generally override this method.
hashCode method
This method is used for hash search. Rewriting the equals method generally requires rewriting the hashCode method. This method is used in some programs with hash functions. Used in Collection.
Generally must satisfy obj1.equals(obj2)==true. It can be concluded that obj1.hashCode()==obj2.hashCode(), but equal hashCode does not necessarily satisfy equals. However, in order to improve efficiency, the above two conditions should be made as close to equivalent as possible.
The default for JDK 1.6 and 1.7 is to return a random number; The default for JDK 1.8 is to use three determined values of a random number related to the current thread. Marsaglia's xorshift scheme is a random number obtained by the random number algorithm.
wait method
Used with synchronized, the wait method is to make the current thread wait for the lock of the object. The current thread must be the owner of the object. , that is, has the lock of the object. The wait() method waits until it acquires the lock or is interrupted. wait(long timeout) sets a timeout interval and returns if the lock is not obtained within the specified time.
After calling this method, the current thread enters sleep state until the following events occur.
Other threads called the object's notify method; Other threads called the object's notifyAll method; Other threads called interrupt to interrupt the thread; The time interval is up.
The thread can be scheduled at this time. If it is interrupted, an InterruptedException exception will be thrown.
notify method
is used in conjunction with synchronized. This method wakes up a thread in the waiting queue on the object (threads in the synchronized queue It is for threads that preempt the CPU, and the threads in the waiting queue refer to threads waiting to be awakened).
notifyAll method
Used with synchronized, this method wakes up all threads waiting in the queue on this object.
What is the relationship between the hashCode method and the equals method?
It seems a bit like a serial attack. When I asked this question, I felt that the interviewer was a little bit confused. I doubt my foundation, but I can still answer this question.
If a.equals(b) returns "true", then the hashCode() of a and b must be equal.
If a.equals(b) returns "false", then the hashCode() of a and b may be equal or not.
The role of hashcode
#It’s really a series of questions, one after another, the answers are not ideal, but they are also relevant.
JavaThere are two types of collections, one is List and the other is Set. The former is orderly and repeatable, while the latter is disordered and not repeatable. How to determine whether the element already exists when we insert it into the set? We can use the equals method. But if there are too many elements, this method will be more full.
So someone invented the hash algorithm to improve the efficiency of finding elements in the collection. This method divides the collection into several storage areas. A hash code can be calculated for each object. The hash codes can be grouped. Each group corresponds to a certain storage area. The object can be determined based on the hash code of an object. The area where it should be stored. The
hashCode method can be understood this way: it returns a value calculated based on the memory address of the object. In this way, when a new element is added to the collection, the hashCode method of this element is first called, and the physical location where it should be placed can be immediately located. If there is no element at this position, it can be stored directly at this position without any comparison; if there is already an element at this position, call its equals method to compare with the new element. If they are the same, they will not be stored. , if not the same, hash other addresses. In this way, the number of actual calls to the equals method is greatly reduced, almost only once or twice.
Talk about the automatic assembly principle of Spring Boot
This problem is also because I wrote
Spring Booton my resume , so it’s normal to be asked, but I read some before the interview and my answer was okay. The interviewer said that’s pretty much what it meant.
There is a very key annotation in Spring Boot @SpringBootApplication, which can be equivalent to
- @SpringBootConfiguration
- @EnableAutoConfiguration
- @ComponentScan
@EnableAutoConfiguration is the key (enable automatic configuration). Internally, the information of the META-INF/spring.factories file is actually loaded, and then filtered out with EnableAutoConfiguration is the key data and is loaded into the IOC container to realize the automatic configuration function!
What are the isolation levels of database transactions?
#This kind of question requires memorizing eight-part essays, and there are a lot of them on the Internet.
There are 4 isolation levels for database transactions, from low to high they are Read uncommitted, Read committed, Repeatable read , Serializable.
Uncommitted read ( READ UNCOMMITTED): Under this isolation level, other transactions can see some modifications that have not been committed by this transaction, thus causing dirty read problems (read Fetched the uncommitted part of other transactions, and then the transaction was rolled back);Read Committed ( READ COMMITTED): Other transactions can only read Get the committed part of this transaction. This isolation level has a non-repeatable read problem. The results obtained after two reads in the same transaction are actually different because another transaction modified the data;"-
Repeatable read ( REPEATABLE READ). The repeatable read isolation level solves the above problem of non-repeatable read, but there is still a new problem, which is phantom reading. When you read the data row with id>10, a read lock is added to all the rows involved. At this time, a transaction newly inserts a piece of data with id=11. Because it is newly inserted, the above will not be triggered. lock exclusion, then when you perform the next query of this transaction, you will find a piece of data with id=11, but the last query operation did not obtain it, and there will be a primary key conflict problem when inserting again; Serializable ( SERIALIZABLE). This is the highest isolation level and can solve all the problems mentioned above, because it forces all operations to be executed serially. This will lead to a rapid decline in concurrency performance, so it is not very commonly used.
Talk about your understanding of indexes in MySQL
This question is okay, just say as much as you know. It depends on everyone's preparation. I was well prepared at the time. I feel that the answer is OK, so I answered the advantages and disadvantages of the index together.
Index is a data structure that enables Mysql to obtain data efficiently. To put it more generally, a database index is like the table of contents at the front of a book, which can speed up database queries.
Advantages
Can ensure the uniqueness of each row of data in the database table Can greatly speed up the indexing of data Accelerate the connection between tables, especially in achieving referential integrity of data When using grouping and When sorting clauses are used for data retrieval, it can also significantly reduce the time of grouping and sorting in queries. By using indexes, optimization hiders can be used during time queries to improve System performance
Disadvantages
-
Creating and maintaining indexes takes time, and this time increases as the amount of data increases Indexes need to occupy physical space. In addition to the data space occupied by the data table, each index also occupies a certain amount of physical space. If a clustered index needs to be established, the space required will be even greater. Large When the data in the table is added, deleted, or modified, the index must be dynamically maintained, which reduces the maintenance speed of integers
What SQL optimization methods are you familiar with?
This part was learned from reading "Essential MySQL Database Knowledge for Java Programmers" in Brother Tian's Knowledge Planet. It is only part of it, because Brother Tian has compiled a lot, right? Come on, my brother has a bad memory.
1. Do not use select *
2 in query statements. Minimize subqueries and use related queries (left join, right join, inner join) instead
3. Reduce the use of IN or NOT IN, use exists, not exists or related query statements instead of
4. Try to use union or union all instead of or query (when confirming that there is no duplicate data or there is no need to eliminate duplicate data, union all will be better)
5. Try to avoid using != or <> operators in the where clause, otherwise the engine will give up using the index and perform a full table scan.
6. Try to avoid judging the null value of the field in the where clause, otherwise the engine will give up using the index and perform a full table scan, such as: select id from t where num is null can be on num Set the default value 0, make sure there is no null value in the num column in the table, and then query like this: select id from t where num=0
How is a SQL query executed in MySQL?
NND, I like to ask about MySQL so much, this question really confused me. After talking nonsense, the interviewer became a little impatient. When I came back, I went to Tian Ge's Knowledge Planet and looked through it. Sure enough, it was almost the same interview question again. I blamed myself for not being ready.
For example, the following SQL statement (SQL given by the interviewer on the spot):
select 字段1,字段2 from 表 where id=996
Get the link, use Use the connector to MySQL. Query cache, the key is the SQL statement, and the value is the query result. If found, it will be returned directly. It is not recommended to use secondary cache. The query cache has been deleted in MySQL 8.0 version, which means that this function does not exist after MySQL 8.0 version. Analyzer, divided into lexical analysis and syntax analysis. This stage just does some SQL parsing and syntax verification. So general grammatical errors are at this stage. Optimizer determines which index to use when there are multiple indexes in the table; or when there are multiple table associations in a statement (join) , determine the connection order of each table. Executor uses the analyzer to let SQL know what you want to do, and the optimizer to know how to do it, so it starts executing the statement. When executing the statement, you must also determine whether you have this permission. If you don't have permission, you will directly return an error indicating that you don't have permission. If you have permission, open the table and use the interface provided by the engine to get the first row of the table according to the engine definition of the table. , determine whether the id is equal to 1. If so, return directly; if it does not continue to call the engine interface to go to the next row, repeat the same judgment until the last row of the table is fetched, and finally return.
I was wondering, what does 996 mean? Is your company 996? Just say it casually
What is the difference between heap and stack in JVM?
#This is okay. If you are familiar with JVM knowledge, you can answer it. The explanation of the JVM runtime data area organized by Brother Tian is very nice.
The essential difference between the two is that the stack is private to the thread, while the heap is shared by the thread.
The stack is a runtime unit, representing logic. A stack corresponds to a thread, containing basic data types and references to objects in the heap. The area is continuous and has no fragments;
The heap is storage Units represent data and can be shared by multiple stacks (including basic data types, references and reference objects in members). The area is not continuous and will be fragmented.
1) Different functions
Stack memory is used to store local variables and method calls, while heap memory is used to store objects in Java. Whether it is member variables, local variables, or class variables, the objects they point to are stored in heap memory.
2), different sharing
Stack memory is private to threads. Heap memory is common to all threads.
3), different exception errors
If there is insufficient stack memory or heap memory, an exception will be thrown.
Insufficient stack space: java.lang.StackOverFlowError.
Insufficient heap space: java.lang.OutOfMemoryError.
4), space size
The space size of the stack is much smaller than that of the heap.
Are you familiar with the class loading mechanism?
These are just memorized interview questions
JVM class loading is divided into 5 processes: loading, verification, preparation , parsing, initializing, using, and uninstalling, as shown in the figure below:
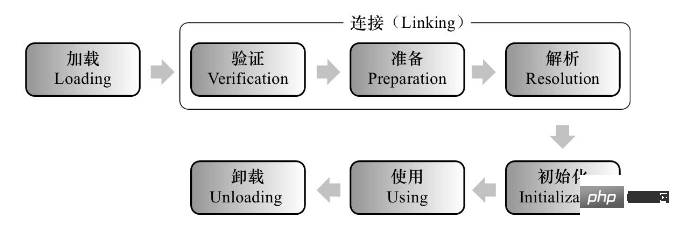
Let’s take a look at the specific actions of the five processes of loading, verification, preparation, parsing, and initialization.
Loading
Loading is mainly to load the binary words in the .class file (not necessarily .class. It can be a ZIP package, obtained from the network) Throttling is read into the JVM. During the loading phase, the JVM needs to complete three things: 1) Obtain the binary byte stream of the class through the fully qualified name of the class; 2) Convert the static storage structure represented by the byte stream into the runtime data structure of the method area; 3) Generate a java.lang.Class object of this class in memory as an access entry for various data of this class in the method area.
Connection
Verification
Verification is the first step in the connection phase, mainly to ensure loading The incoming byte stream conforms to JVM specifications. The verification phase will complete the following four stages of verification actions: 1) File format verification 2) Metadata verification (whether it complies with the Java language specification) 3) Bytecode verification (to confirm that the program semantics are legal and logical) 4) Symbol reference verification ( Ensure that the next step of parsing can be executed normally)
Preparation
Mainly allocate memory for static variables in the method area and set the default initial value.
Parsing
is the process by which the virtual machine replaces symbol references in the constant pool with direct references.
initialization
The initialization phase is the last step in the class loading process. It mainly actively assigns values to class variables according to the assignment statements in the program. Note: 1) When there is a parent class and the parent class is initialized, initialize the parent class first; 2) Then perform the subclass initialization statement.
What are the conditions that can trigger Full GC?
# It's a bit jumpy. I thought I would ask about garbage collection algorithms and the like, but I ended up asking here. I wasn't ready for this, so I just said two things casually, and I obviously felt that the interviewer was very dissatisfied. Hey, that's it, go back and prepare well.
Usually there are 5 scenarios that trigger Full GC:
(1) When calling System.gc, the system recommends executing Full GC , but it is not necessary to execute
(2) Insufficient space in the old generation
(3) Method to remove insufficient space
(4) Enter the old generation after passing Minor GC Average size of > available memory in old generation
(5) When copying from Eden area, From Space area to To Space area, the object size is larger than the available memory of To Space, then the object is transferred to the old generation, and the available memory of the old generation is smaller than the object size. That is, when the old generation cannot store objects from the new generation to the old generation, Full GC will be triggered.
The online system CPU is so high, what should I do?
The answer to this question is not very satisfactory. I know that Brother Tian has compiled a document, but I haven’t seen where to go home. After reading it on the way, I found that this is also an interview question that can be memorized. I actually didn't answer it. Go back and work harder. The interviewer came and said: OK, our interview will end here today. I will report to HR here. You wait here.
After a while, the beautiful HR came over with a smile, (I thought the problem was not serious), but it turned out...
Are you "YY, the interviewer has given feedback on the interview situation. We will take it into consideration again. You go back first. We will call you to inform you of the results later."
(⊙o⊙)..., more than n days passed, and there was no news. It was really cool.
The conventional operation is:
1. top oder by with P: 1040 // First find axLoad(pid) sorted by process load
2. top - Hp process PID: 1073 // Find the relevant load thread PID
3. printf "0x%x\n" Thread PID: 0x431 // Convert the thread PID to hexadecimal to prepare for later searching for jstack logs
4. jstack process PID | vim/hex thread PID - // For example: jstack 1040|vim /0x431 -
Summary
The whole interview process was relatively easy, and the interviewer was pretty good. I just blamed myself for not being prepared. As someone who has been working for two years, I have never seen some of the questions, but the questions asked by the interviewer seemed to be similar. You can achieve what you have prepared (memorize the interview questions), and it does not have to be experienced personally.
The above is the detailed content of Last week, I had an interview with XX Insurance and it was cool! ! !. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1379
1379
 52
52

 Interviewer: Spring Aop common annotations and execution sequence
Aug 15, 2023 pm 04:32 PM
Interviewer: Spring Aop common annotations and execution sequence
Aug 15, 2023 pm 04:32 PM
You must know Spring, so let’s talk about the order of all notifications of Aop. How does Spring Boot or Spring Boot 2 affect the execution order of aop? Tell us about the pitfalls you encountered in AOP?
 Interview with a certain group: If you encounter OOM online, how should you troubleshoot it? How to solve? What options?
Aug 23, 2023 pm 02:34 PM
Interview with a certain group: If you encounter OOM online, how should you troubleshoot it? How to solve? What options?
Aug 23, 2023 pm 02:34 PM
OOM means that there is a vulnerability in the program, which may be caused by the code or JVM parameter configuration. This article talks to readers about how to troubleshoot when a Java process triggers OOM.
 Novices can also compete with BAT interviewers: CAS
Aug 24, 2023 pm 03:09 PM
Novices can also compete with BAT interviewers: CAS
Aug 24, 2023 pm 03:09 PM
The extra chapter of the Java concurrent programming series, C A S (Compare and swap), is still in an easy-to-understand style with pictures and texts, allowing readers to have a crazy conversation with the interviewer.
 Ele.me's written test questions seem simple, but it stumps a lot of people
Aug 24, 2023 pm 03:29 PM
Ele.me's written test questions seem simple, but it stumps a lot of people
Aug 24, 2023 pm 03:29 PM
Don’t underestimate the written examination questions of many companies. There are pitfalls and you can fall into them accidentally. When you encounter this kind of written test question about cycles, I suggest you think calmly and take it step by step.
 Last week, I had an interview with XX Insurance and it was cool! ! !
Aug 25, 2023 pm 03:44 PM
Last week, I had an interview with XX Insurance and it was cool! ! !
Aug 25, 2023 pm 03:44 PM
Last week, a friend in the group went for an interview with Ping An Insurance. The result was a bit regretful, which is quite a pity, but I hope you don’t get discouraged. As you said, basically all the questions encountered in the interview can be solved by memorizing the interview questions. It’s solved, so please work hard!
 5 String interview questions, less than 10% of people can answer them all correctly! (with answer)
Aug 23, 2023 pm 02:49 PM
5 String interview questions, less than 10% of people can answer them all correctly! (with answer)
Aug 23, 2023 pm 02:49 PM
This article will take a look at 5 interview questions about the Java String class. I have personally experienced several of these five questions during the interview process. This article will help you understand why the answers to these questions are like this.
 It is recommended to collect 100 Linux interview questions with answers
Aug 23, 2023 pm 02:37 PM
It is recommended to collect 100 Linux interview questions with answers
Aug 23, 2023 pm 02:37 PM
This article has a total of more than 30,000 words, covering Linux overview, disk, directory, file, security, syntax level, practical combat, file management commands, document editing commands, disk management commands, network communication commands, system management commands, backup compression commands, etc. Dismantling Linux knowledge points.

